利用移动云电脑本地运行Deepseek-r1模型-超详细操作过程
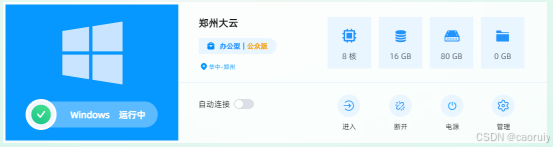
在移动云云电脑中安装Deepseek目前你可以在移动云电脑公众版、行业型(GPU型)云电脑中,利用Ollama来本地部署Deekseek R1模型,开启本地大模型使用之旅。
目录
在移动云云电脑中安装Deepseek
目前你可以在移动云电脑公众版、行业型(GPU型)云电脑中,利用Ollama来本地部署Deekseek R1模型,开启本地大模型使用之旅。
本地部署 DeepSeek R1
安装ollama
访问 Ollama 官方地址:https://ollama.com/download,下载Ollama。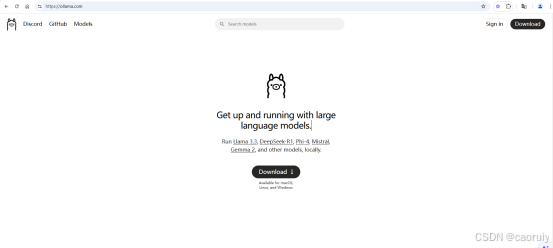
ollama提供了多种客户端可以选择,我们选择Windos客户端进行安装,点击页面上的“Download for Windows”进行下载安装。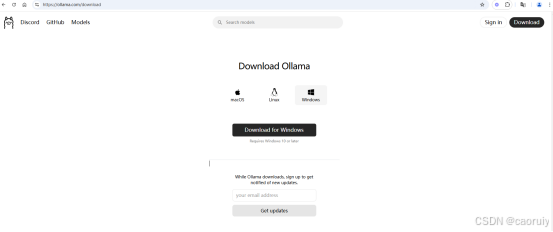
点击下一步直接安装安装包即可。
下载deepseek r1模型
ollama顶部菜单”Models”中提供了众多模型,我们找到“deepseek-r1”,通过命令行工具进行安装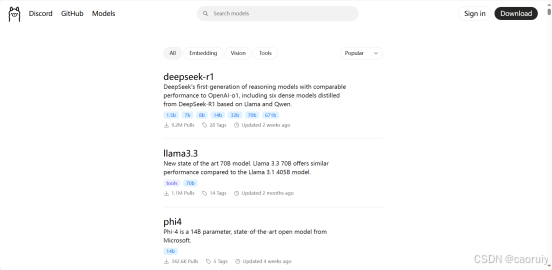
打开本地命令行工具,执行ollama run deepseek-r1(run命令执行安装+运行过程,本地存在模型时只会直接拉起模型),默认安装7B版本。
你也可以在页面上直接复制安装的命令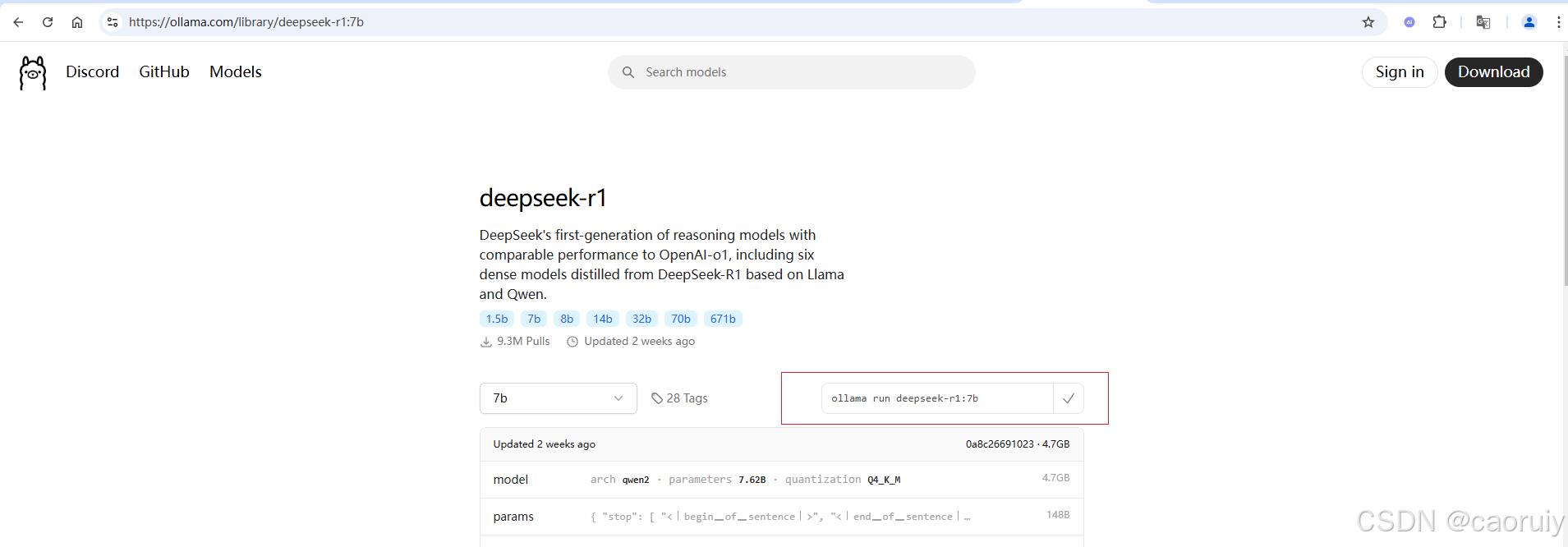
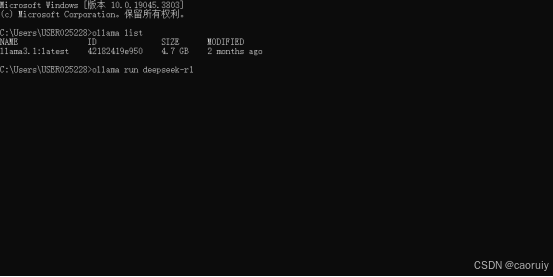
本地下载成功并成功运行,你可以在命令行中直接进行提问。
测试验证
大致效果如下,回复内容包括思考过程的显示,思考内容将显示在<think>中
图形化界面搭建
上面我们通过命令行可以对deepseek进行使用,下面我们借助AnythingLLM客户端来搭建我们自己的知识库。
安装AnythingLLM
首先安装好AnythingLLM客户端,我们通过官网下载客户端https://useanything.com/。

安装AnythingLLM
离线安装包
官网下载太慢,你可以点击此处下载:
hi,我正在使用云空间,给你分享了文件(共1项)AnythingLLMDesktop.exe文件下载地址链接:https://www.ecpan.cn/web/#/yunpanProxy?path=%2F%23%2Fdrive%2Foutside&data=9c5061c16e4e6aadd15d2c6065d20d99iq&isShare=1;有效期至:2030-03-31 23:59:59
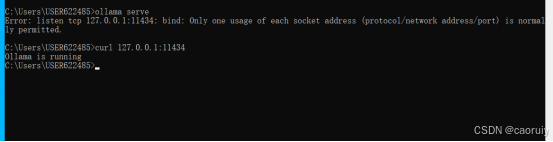
启动ollama
桌面双击AnythingLLM图标启动本地大模型。启动前,先启动ollama服务,ollama serve 启动服务, curl 127.0.0.1:port 显示Ollama is running,表示服务已经启动成功。
配置AnythingLLM
打开客户端,首页你可以选择“Get Started”来开始配置Ollama
选择ollama,模型选择deepseek-r1,此处我这边选中的是1.5b的模型。
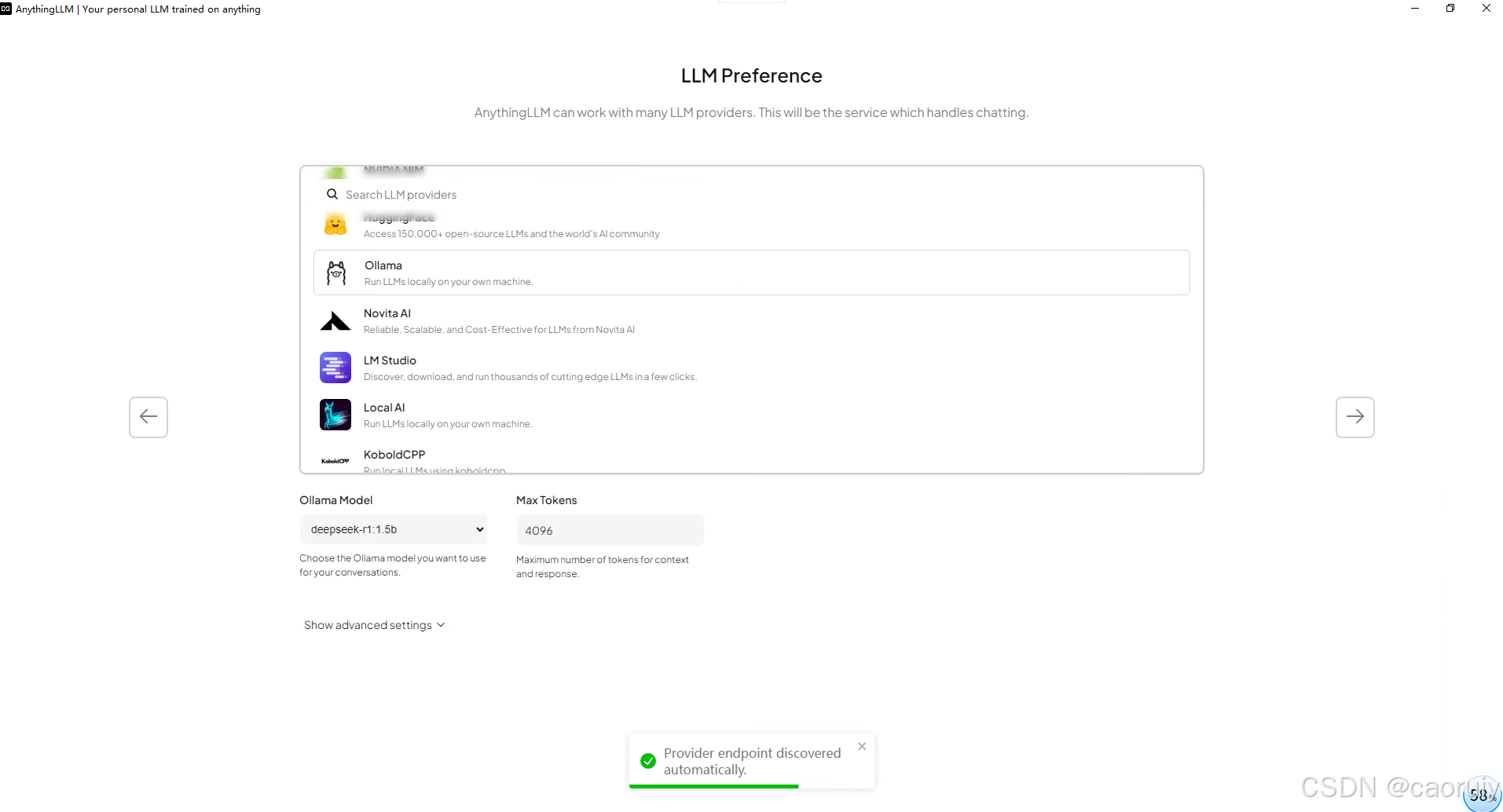
“下一步”,根据提示创建自己的工作区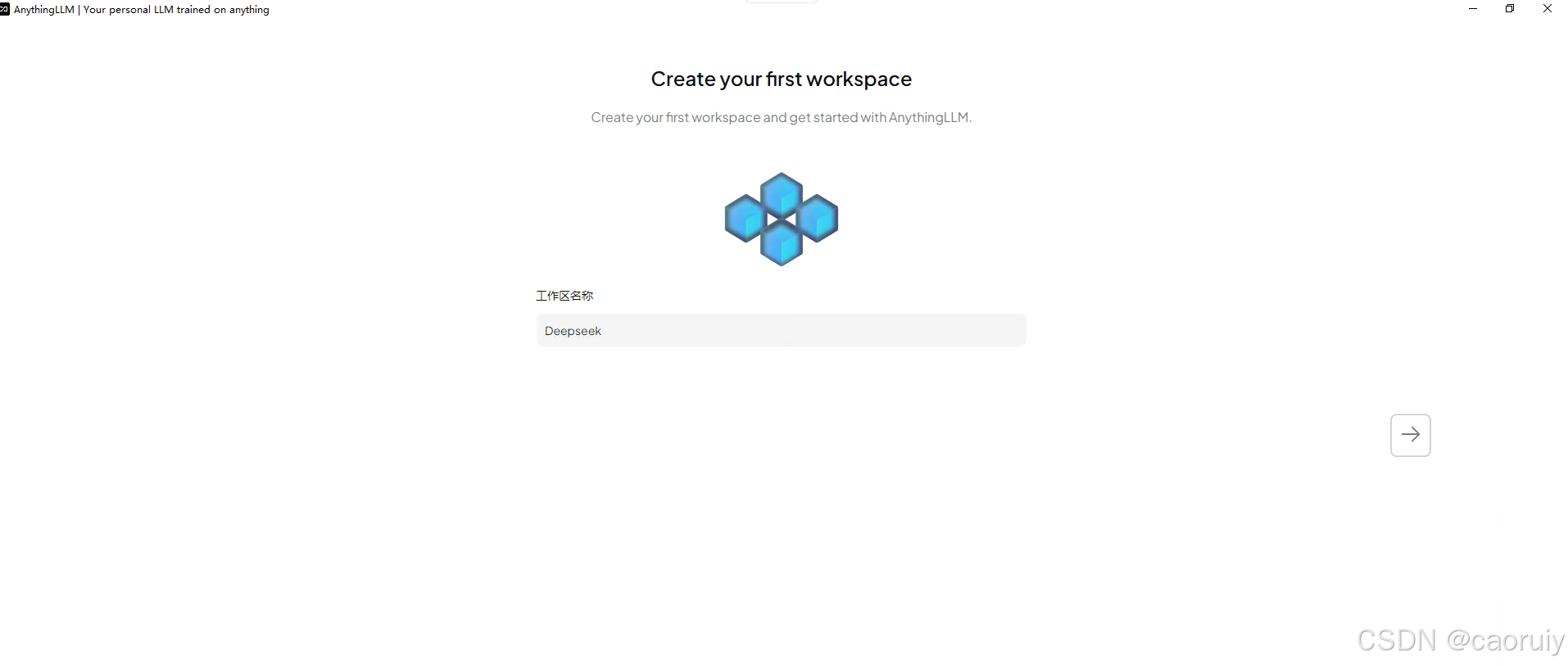
设置工作区使用的模型
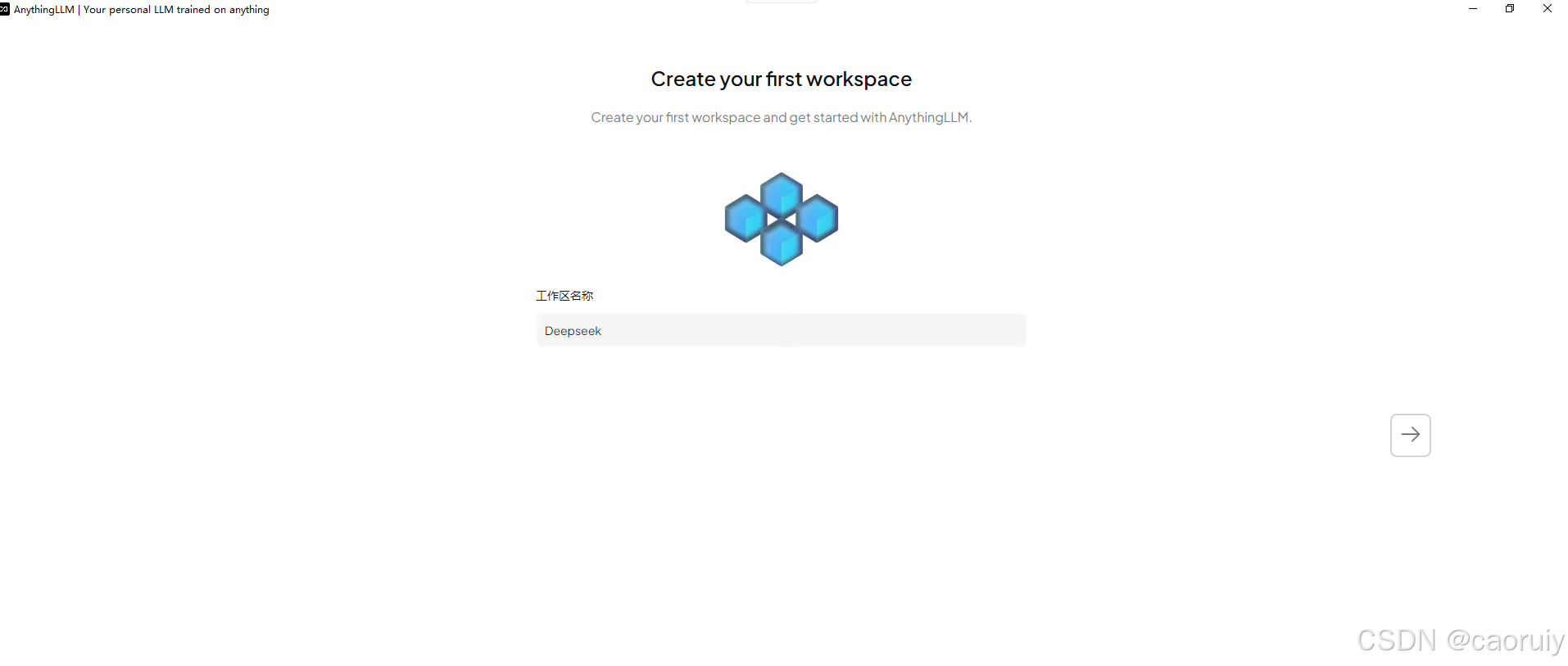
按照上述配置,你将创建一个你自己的workspace,你可以对工作区进行一些设置。最重要的是选择deepseek模型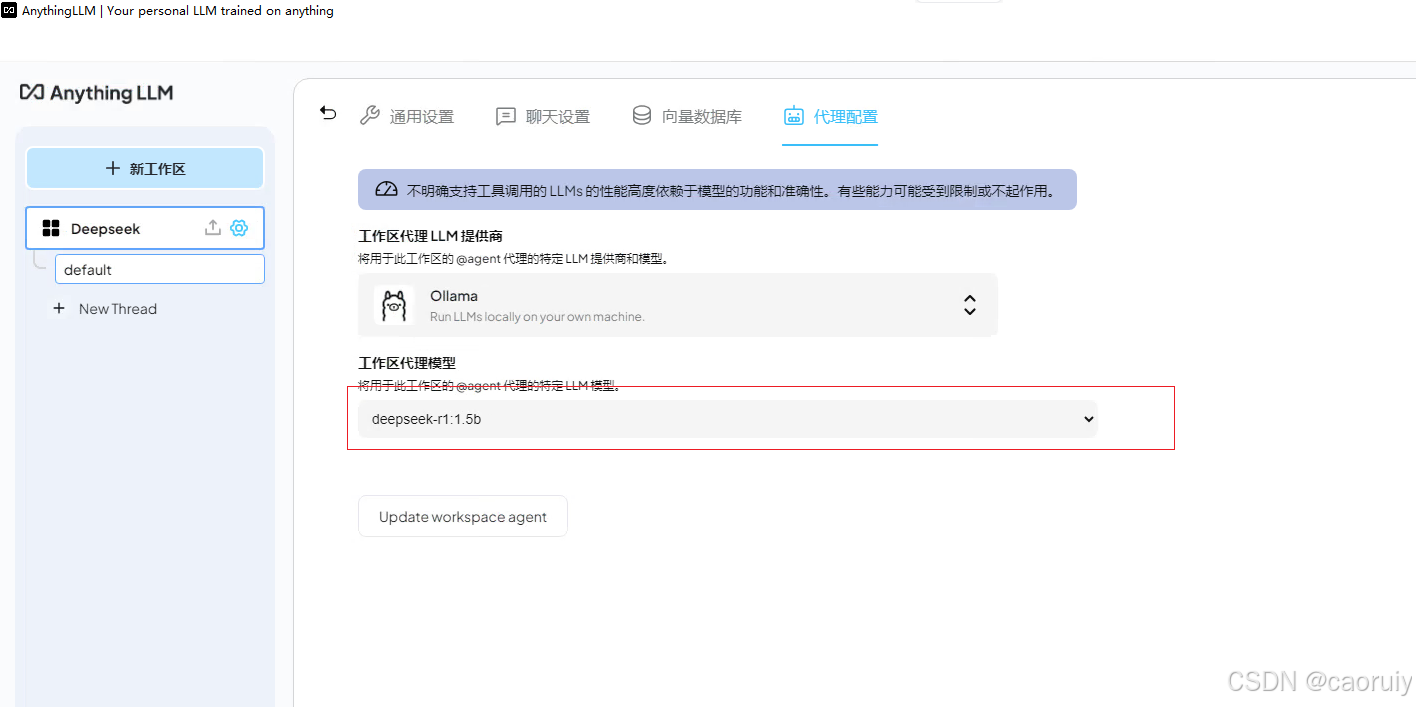
配置完成后,即可进行正常的问答了。

性能对比
对比不同云电脑规格下,7B大小的大模型占用性能:
在4Q8C16G GPU型云电脑中,模型回复过程中,CPU 占用50%左右,GPU 占用1.3%左右,内存使用10G左右。
在2Q4C8G GPU型云电脑中,模型回复过程中,CPU 占用57%左右,内存使用4.7G左右。
在8C16G CPU型云电脑中,模型回复过程中,CPU 占用50%左右,内存使用5G左右。

在16C32G CPU型云电脑中,模型回复过程中,CPU 占用55%左右,内存使用5G左右。
对比相同云电脑规格(8C16G)下,7B以及1.5B大小的大模型占用性能:
综上所述,本地部署deepseek不影响移动云电脑正常使用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)