DeepSeek R1与李飞飞团队S1模型的深度对比分析
在推理阶段,通过控制模型生成的Token数量(如强制终止思考或插入“等待”指令),动态调整计算资源分配,迫使模型进行多次迭代推理以修正错误69。例如,当模型过早生成答案时,系统会追加“Wait”提示,延长思考时间11。:在AIME2024(79.89%)、MATH-500(97.32%)、CodeforcesElo(20分)等测试中,R1均显著优于S1和其他主流模型19。:两者可能互补——基座模型
DeepSeek R1与李飞飞团队S1模型的深度对比分析
引言
2025年初,AI推理领域的两大模型——DeepSeek R1与李飞飞团队的S1模型——引发了广泛关注。前者以强大的通用性和全自研技术链著称,后者则以极低训练成本(仅50美元)和特定场景下的高性能成为焦点。本文将从技术原理、性能表现、训练成本、应用场景、开源生态及伦理影响等多个维度,深入剖析两者的异同,并探讨其背后的行业意义。
一、技术原理:路径分化的底层逻辑
1. S1模型:监督微调与预算强制的结合
S1模型的核心技术路径基于监督微调(SFT)和知识蒸馏,其创新点在于**预算强制(Budget Forcing)**技术的引入:
-
数据集构建:团队从16个来源筛选59,029个问题,最终保留1,000个高难度、多样性、高质量样本(s1K数据集),并利用谷歌Gemini 2.0生成推理轨迹和答案28。这一过程本质上是将Gemini的推理能力通过数据蒸馏迁移至基座模型Qwen2.5-32B-Instruct10。
-
预算强制:在推理阶段,通过控制模型生成的Token数量(如强制终止思考或插入“等待”指令),动态调整计算资源分配,迫使模型进行多次迭代推理以修正错误69。例如,当模型过早生成答案时,系统会追加“Wait”提示,延长思考时间11。
-
低成本关键:依赖阿里云通义千问(Qwen)的预训练基座模型,仅需26分钟、16块H100 GPU完成微调,总成本不足50美元48。
2. DeepSeek R1:强化学习与长链推理的融合
DeepSeek R1的技术路线则以**强化学习(RL)和长链推理(Chain-of-Thought, CoT)**为核心:
-
强化学习框架:通过大规模RL训练,使模型在复杂任务中自主优化策略,无需依赖大量标注数据17。例如,在金融建模和工程计算场景中,R1通过多轮交互学习动态调整推理路径。
-
通用性设计:R1内置代码解释器,支持多语言混合编程,并在长上下文处理中保持稳定性79。其能力覆盖数学、编程、科学推理等多个领域,而不仅是特定题型。
-
全自研技术链:与S1不同,R1未依赖外部基座模型,从预训练到蒸馏均采用自主技术栈,确保迭代独立性911。
3. 共同点与本质差异
-
共同点:
两者均通过知识迁移提升推理能力(S1依赖Gemini生成数据,R1通过自蒸馏技术);均探索推理过程优化(S1的预算强制与R1的长链推理)18。 -
本质差异:
S1是**“微调+工程优化”的产物,强依赖于基座模型和外部数据源;而R1是“全栈自研+算法创新”**的成果,强调技术闭环和通用性49。
二、性能表现:特定场景与泛化能力的博弈
1. S1的局部突破
-
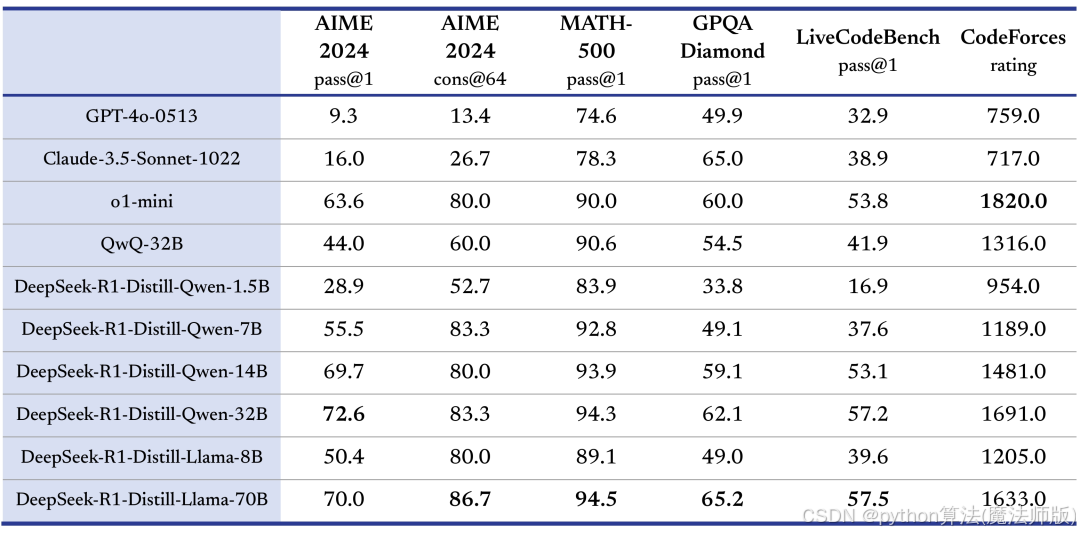
特定测试集优势:在MATH-500和AIME2024竞赛数学问题上,S1-32B的准确率比OpenAI o1-preview高出27%,接近Gemini 2.016。但这一表现仅限于筛选后的高难度题型,且未覆盖o1正式版和R1的广泛场景1011。
-
基座模型的限制:S1的数学能力主要继承自Qwen基座模型,其代码能力(如HUMANEVAL测试75%通过率)同样依赖Qwen的底层架构79。
2. R1的全面领先
-
基准测试统治力:在AIME2024(79.89%)、MATH-500(97.32%)、CodeforcesElo(20分)等测试中,R1均显著优于S1和其他主流模型19。
-
泛化能力验证:R1在金融建模、工程计算等复杂任务中表现稳定,其长链推理能力可分解多步骤问题,而S1在非筛选数据集上的性能大幅下降711。
3. 性能对比的启示
-
数据质量 vs 数据规模:S1证明高质量小数据集(1K样本)可通过蒸馏实现局部突破,但R1验证了大规模RL训练对泛化能力的必要性810。
-
测试时扩展的潜力:S1的预算强制与R1的长链推理均属于测试时扩展技术,但前者依赖外部干预,后者内化为模型自主能力111。
三、训练成本与研发范式:效率革命的两种路径
1. S1:低成本微调的颠覆性尝试
-
成本结构:50美元仅覆盖16块H100 GPU的26分钟微调费用,未包含Qwen基座模型的预训练成本(估计超百万美元)410。
-
行业影响:为中小团队提供“轻量化研发”可能,例如上海交大LIMO团队仅用817个样本实现94.8%的MATH准确率,进一步挑战大模型对海量数据的依赖210。
2. R1:高投入下的技术壁垒
-
成本投入:采用大规模RL训练,总成本远超S1(如DeepSeek V3训练费用达557.6万美元),但换来技术自主性和通用能力29。
-
商业逻辑:R1通过API服务和模型蒸馏(如开源6个小模型)构建生态,而S1的开源策略更倾向于学术探索911。
3. 范式冲突与融合
-
效率与能力的权衡:S1代表“小数据+强工程”的极致效率,R1体现“大数据+全栈创新”的能力优先811。
-
未来趋势:两者可能互补——基座模型的低成本微调(如S1)结合RL的泛化优化(如R1),催生“混合式训练”新范式910。
四、开源生态与行业影响:技术民主化 vs 商业护城河
1. S1的开源激进主义
-
完全开源:论文、代码、数据均公开,推动社区复现与二次开发(如量化版s1-32B-GGUF)210。
-
基座依赖争议:S1的成功高度依赖Qwen模型,若基座闭源,其生态可持续性存疑48。
2. R1的生态护城河
-
部分开源策略:开源部分小模型吸引开发者,但保留核心技术的闭源优势911。
-
API商业化:通过低价API(如DeepSeek定价低于OpenAI)扩大市场份额,形成“开源引流+闭源盈利”模式911。
3. 行业格局重塑
-
中小团队机遇:S1式微调降低入门门槛,可能催生垂直领域低成本模型(如医疗、法律推理)210。
-
大厂防御策略:DeepSeek等企业需加速基座模型迭代(如Qwen衍生模型已达9万个),巩固技术壁垒911。
五、伦理与未来挑战:知识产权的灰色地带
1. S1的伦理争议
-
数据版权风险:s1K数据集部分源自Gemini生成内容,可能涉及谷歌的知识产权210。
-
基座模型贡献忽视:S1的成果被归功于微调创新,但Qwen的预训练投入未计入成本,引发“摘桃子”批评48。
2. R1的技术主权
-
全自研优势:避免外部依赖,减少版权纠纷(如OpenAI曾指控DeepSeek不当使用API数据)79。
-
伦理设计挑战:需平衡模型能力与滥用风险(如金融欺诈、自动化武器)11。
3. 未来监管方向
-
基座模型许可协议:或需强制要求微调模型注明基座来源及成本占比410。
-
蒸馏技术规范:明确知识蒸馏的数据使用边界,防止“黑箱复刻”侵害原创者权益28。
结论:技术多样性与生态共荣
DeepSeek R1与S1模型代表了AI推理领域的两种哲学:前者追求通用能力与技术闭环,后者探索极限成本与工程创新。两者的竞争本质是**“能力优先”与“效率革命”**的路线之争,但其共同推动了测试时扩展、小数据训练等核心技术进展。未来,行业可能走向“基座模型开源化+垂直场景微调”的混合生态,而伦理与知识产权框架的完善将成为可持续发展的关键。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)