使用DeepSeek写一份爬取百度首页处热点话题标题的Python代码
点击上方“Python爬虫与数据挖掘”,进行关注回复“书籍”即可获赠Python从入门到进阶共10本电子书今日鸡汤寒雨连江夜入吴,平明送客楚山孤。大家好,我是Python进阶者。一、前言春节这几天DeepSeek杀疯了,如果你还没有听过DeepSeek,那你真的是太Out了,感觉唰唰唰起来吧。关于DeepSeek的使用和部署,很多公众号都有发布,这里就不再赘述了,如果你实在不会,又觉得自己搞定有些
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
寒雨连江夜入吴,平明送客楚山孤。
大家好,我是Python进阶者。
一、前言
春节这几天DeepSeek杀疯了,如果你还没有听过DeepSeek,那你真的是太Out了,感觉唰唰唰起来吧。
关于DeepSeek的使用和部署,很多公众号都有发布,这里就不再赘述了,如果你实在不会,又觉得自己搞定有些麻烦的话,文末添加我的好友,手把手教你,并提供给你软件。

二、关于DeepSeek
下面的内容其实也是问的DeepSeek自己,自问自答:DeepSeek 是由深度求索(DeepSeek)公司开发的一款专注于人工智能技术研究和应用的平台。深度求索是一家中国的人工智能公司,致力于推动自然语言处理(NLP)、机器学习、深度学习等领域的技术进步,并将其应用于实际场景中。
DeepSeek 的核心特点:
-
自然语言处理(NLP):
-
DeepSeek 在 NLP 领域表现出色,尤其是在中文文本处理和语义理解方面。
-
支持多种任务,如文本生成、情感分析、问答系统、机器翻译等。
大模型与深度学习:
-
DeepSeek 基于大规模深度学习模型,能够处理复杂的自然语言任务。
-
通过预训练和微调技术,模型能够适应多种场景和需求。
多模态融合:
-
DeepSeek 不仅局限于文本处理,还支持图像、语音等多模态数据的融合分析。
行业应用:
-
DeepSeek 的技术已广泛应用于多个行业,如金融、医疗、教育、客服等。
-
提供智能问答、知识图谱构建、自动化文档处理等解决方案。
开放与生态:
-
DeepSeek 致力于打造开放的生态,提供 API 接口和工具,方便开发者和企业快速集成其技术。
DeepSeek 的主要产品:
-
智能问答系统:
-
能够快速、准确地回答用户提出的问题,适用于客服、教育等领域。
文本生成与摘要:
-
支持自动生成高质量的文本内容,并提供文本摘要功能。
知识图谱构建:
-
通过分析大量文本数据,构建结构化的知识图谱。
情感分析与舆情监控:
-
分析文本中的情感倾向,并实时监控舆情动态。
DeepSeek 的技术优势:
-
中文处理能力强:针对中文语言特点进行了深度优化。
-
高效性与可扩展性:支持大规模数据处理和高并发场景。
-
持续学习与迭代:通过不断优化模型,提升性能和用户体验。
总结:
DeepSeek 是一家专注于人工智能技术研究与应用的公司,其产品和技术在自然语言处理、多模态融合等领域具有显著优势,同时通过开放的生态和行业应用,为企业和开发者提供了高效的智能化解决方案。如果你对 DeepSeek 的具体产品或技术感兴趣,可以访问其官方网站或联系其团队获取更多信息。

三、DeepSeek实战
这里我向DeepSeek提问了下:帮我写一份爬取百度首页处热点话题标题的Python代码,要求要保证能本地跑起来。
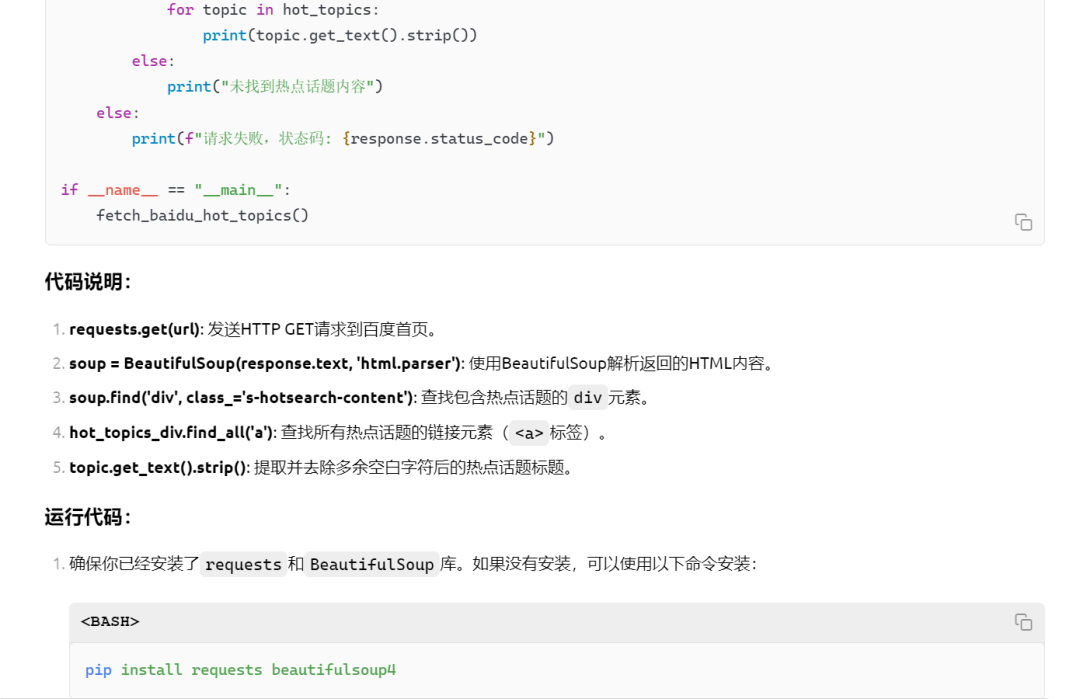
下面是它的回答:要爬取百度首页热点话题的标题,可以使用Python的requests库来发送HTTP请求,并使用BeautifulSoup库来解析HTML页面。以下是一个示例代码,它可以在本地运行并提取百度首页热点话题的标题。
import requests
from bs4 import BeautifulSoup
def fetch_baidu_hot_topics():
# 百度首页URL
url = 'https://www.baidu.com'
# 发送HTTP GET请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 查找热点话题的标题
# 热点话题通常位于class为 's-hotsearch-content' 的div中
hot_topics_div = soup.find('div', class_='s-hotsearch-content')
if hot_topics_div:
# 提取所有热点话题的标题
hot_topics = hot_topics_div.find_all('a')
# 打印热点话题标题
for topic in hot_topics:
print(topic.get_text().strip())
else:
print("未找到热点话题内容")
else:
print(f"请求失败,状态码: {response.status_code}")
if __name__ == "__main__":
fetch_baidu_hot_topics()代码说明:
-
requests.get(url): 发送HTTP GET请求到百度首页。
-
soup = BeautifulSoup(response.text, 'html.parser'): 使用BeautifulSoup解析返回的HTML内容。
-
soup.find('div', class_='s-hotsearch-content'): 查找包含热点话题的
div元素。 -
hot_topics_div.find_all('a'): 查找所有热点话题的链接元素(
<a>标签)。 -
topic.get_text().strip(): 提取并去除多余空白字符后的热点话题标题。
运行代码:
-
确保你已经安装了
requests和BeautifulSoup库。如果没有安装,可以使用以下命令安装:pip install requests beautifulsoup4 -
将上述代码保存为一个Python文件(例如
fetch_baidu_hot_topics.py),然后在终端或命令行中运行:python fetch_baidu_hot_topics.py
注意事项:
-
百度首页的结构可能会发生变化,因此如果代码无法正常运行,可能需要根据最新的HTML结构调整查找元素的
class或标签。 -
该代码仅用于学习和测试目的,请遵守相关网站的使用条款和隐私政策。
大家好,我是Python进阶者。这篇文章主要介绍了下DeepSeek,基于DeepSeek,给了两个实战案例,大家也可以自己尝试下。
我这里默认的是使用deepseek-ai/DeepSeek-V3,大家也可以试试看别的,也惊喜哦!
DeepSeek超级火爆,我也建立了一个DeepSeek交流群,大家感兴趣的话,也可以后台加我v,pdcfighting2,我拉你一起进群学习交流。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)