DeepSeek Janus-Pro 简介
DeepSeek Janus-Pro 是由中国团队 DeepSeek 开发的一款开源多模态大模型,旨在统一图像理解与生成任务,通过创新的架构设计和训练策略显著提升了多模态任务的性能。Janus-Pro 通过解耦架构平衡理解与生成任务,结合高效训练策略与轻量化设计,成为多模态领域的突破性模型。其开源特性与广泛适用性,使其在学术研究与商业落地中均具潜力,未来或推动多模态技术向更灵活、低成本的方向发展。
DeepSeek Janus-Pro 是由中国团队 DeepSeek 开发的一款开源多模态大模型,旨在统一图像理解与生成任务,通过创新的架构设计和训练策略显著提升了多模态任务的性能。
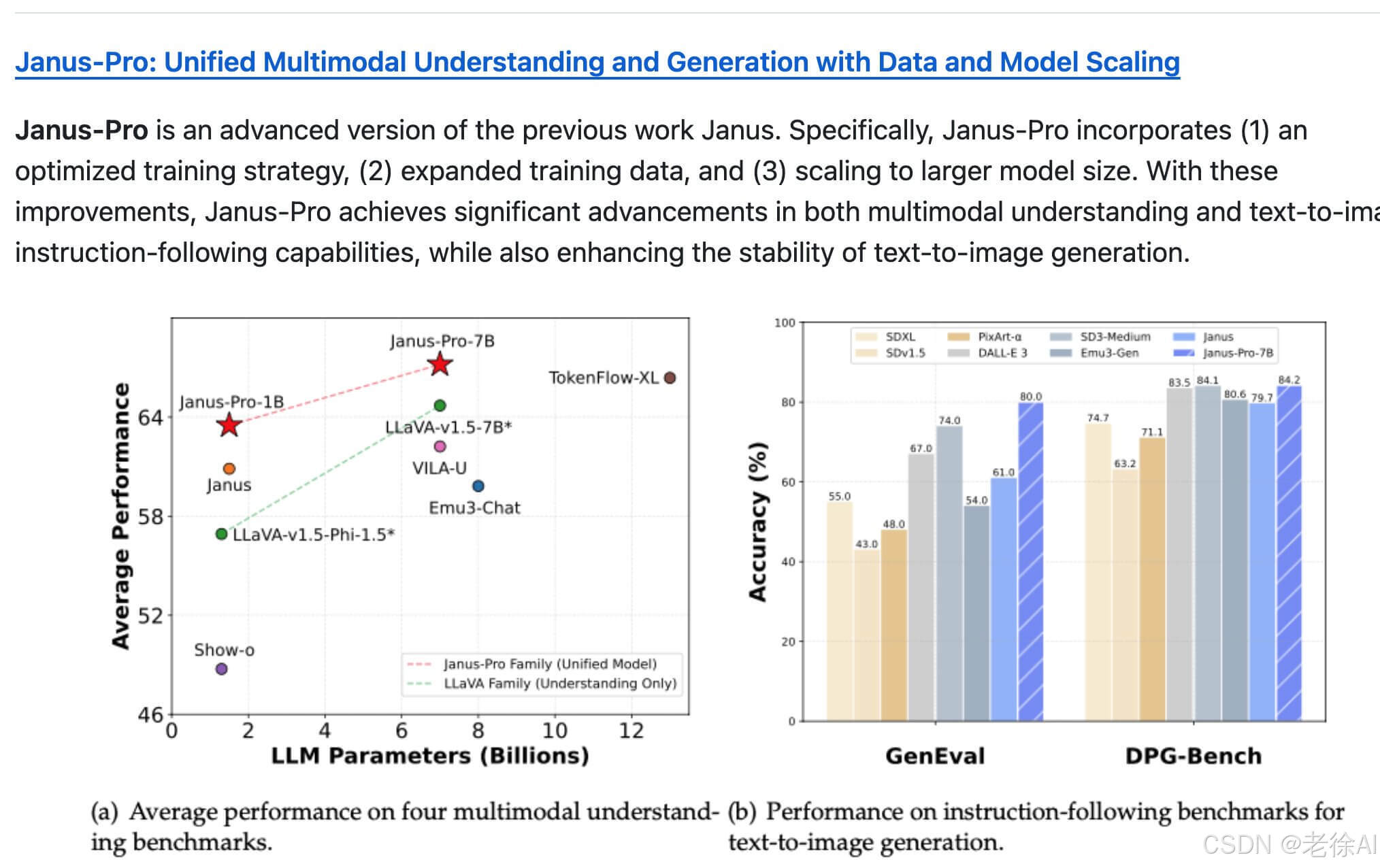
DeepSeek Janus Pro 在 DPG-Bench 达到 84.2% 准确率,GenEval 达到 80.0%,树立 AI 图像生成新标准。
现在可以在线免费体验一下 Janus-Pro 的性能,看看是不是很强大!
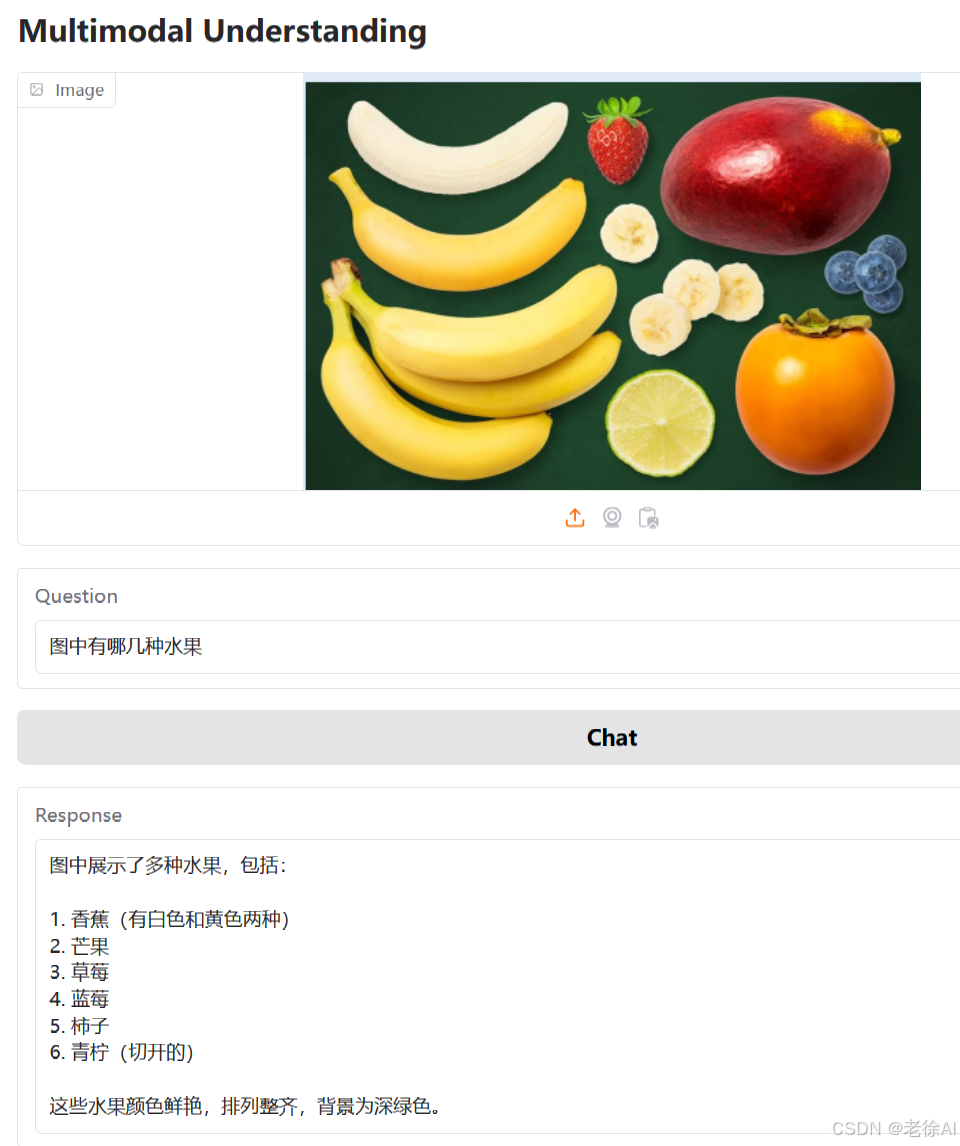
DeepSeek Janus Pro 通过创新的双路径架构和统一的 transformer 设计实现突破性能:
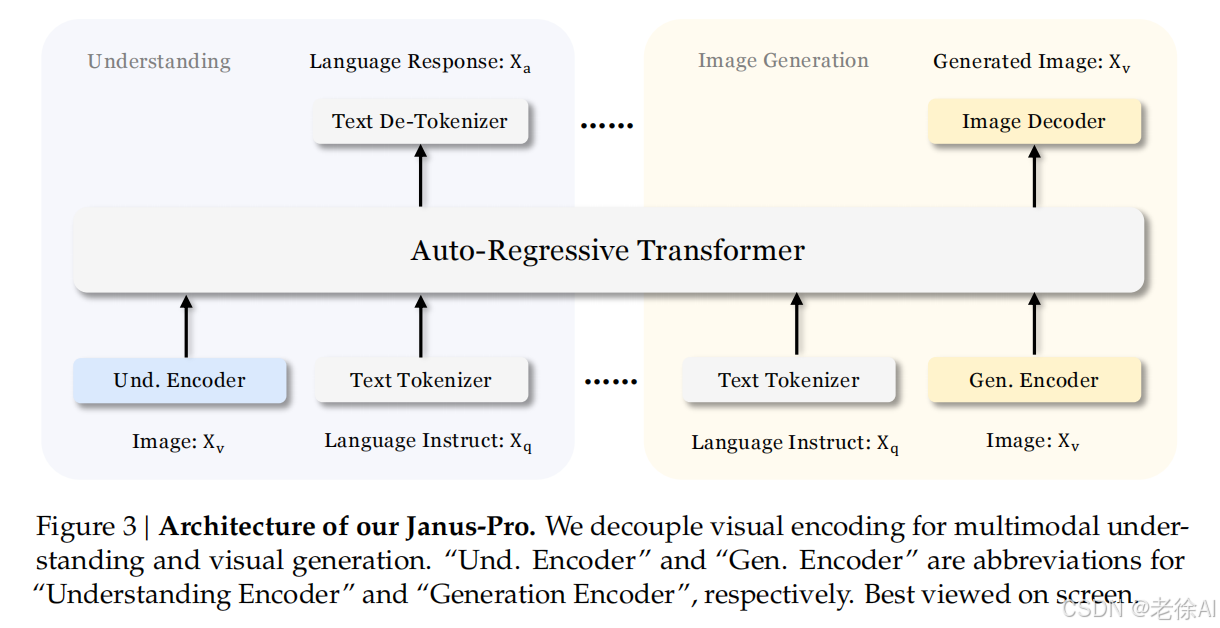
多模态AI和图像生成领域的行业领先能力:

1. 核心架构与技术亮点
-
解耦视觉编码:Janus-Pro 采用双路径视觉编码设计,分别处理多模态理解和生成任务:
-
理解路径:使用 SigLIP-L 编码器提取图像的高层语义特征(如物体类别、场景关系),适用于问答、分类等任务。
-
生成路径:采用 VQ tokenizer 将图像转换为离散 token 序列,关注细节纹理,支持文本到图像生成。
-
-
统一 Transformer 架构:两种任务的特征序列通过统一的 Transformer(基于 DeepSeek-LLM 7B 或 1.5B)处理,实现知识融合与任务协同,同时简化模型结构。
2. 训练策略优化
-
三阶段训练法:
-
基础特征学习:延长适配器与图像头部的训练时间,强化视觉特征提取能力。
-
多模态对齐:弃用 ImageNet,直接使用真实文生图数据,提升训练效率与生成质量。
-
数据配比调整:将多模态理解、纯文本、文生图数据比例从 7:3:10 调整为 5:1:4,并引入 7200 万条合成美学数据,加速收敛并提升生成稳定性。
-
-
扩展训练数据:新增图像字幕、表格图表等复杂场景数据,增强模型泛化能力。
3. 性能表现
-
多模态理解:在 MMBench 基准测试中得分 79.2,超越 LLaVA、MetaMorph 等模型。
-
图像生成:GenEval 测试得分 0.80,优于 DALL-E 3(0.67)和 Stable Diffusion 3(0.74),尤其在细节与审美质量上表现突出。
-
实际应用示例:
-
精准识别地标(如杭州西湖三潭印月)并解析文化内涵。
-
生成符合复杂指令的图像(如特定风格插画或场景设计)。
-
4. 模型规模与部署优势
-
提供高效部署的 1B 和 追求最高性能的 7B 两种参数量版本。7B 版本在性能提升显著的同时保持轻量化,支持浏览器端 WebGPU 运行。
-
分辨率限制:输入与生成图像分辨率为 384x384,虽影响部分细节,但模型通过高效架构设计在资源受限环境下仍保持高性能。
5. 应用场景
Janus Pro 在文本生成图像和多模态理解任务中表现出色。支持高质量图像生成、复杂场景渲染、准确的文本渲染和各种视觉理解任务,性能达到业界领先水平。
-
创意产业:广告设计、游戏场景生成、艺术创作。
-
教育与内容生成:个性化学习材料、社交媒体视觉内容、视觉故事板制作。
-
企业集成:如 GPTBots.ai 将其用于营销素材生成、产品设计原型等,提升效率与创意产出。
6. 开源与生态
-
开源协议:代码遵循 MIT 许可,模型需遵守 DeepSeek 协议,支持商业应用。
-
资源获取:
总结
Janus-Pro 通过解耦架构平衡理解与生成任务,结合高效训练策略与轻量化设计,成为多模态领域的突破性模型。其开源特性与广泛适用性,使其在学术研究与商业落地中均具潜力,未来或推动多模态技术向更灵活、低成本的方向发展。
如果觉得内容写的不错,就给 DeepSeek-R1 点个赞吧!你懂的 :)
老徐,2025/02/08

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)