保姆级手把手教程部署国产 AI 「DeepSeek」
1.安装 Ollama 免费开源在本地轻松运行和部署大型语言模型的工具,并且支持 macOS、Linux 和 Windows,以及 Docker 容器化部署。我们还可以通过 Modelfile 修改模型参数,或基于现有模型微调。打开官网之后,点击Download进入下载页面:点击Download按钮,进入选择系统界面,根据你的系统选择,我这里用的是windows:使用 Ollama 建议你的电脑有
1.安装 Ollama 免费开源在本地轻松运行和部署大型语言模型的工具,并且支持 macOS、Linux 和 Windows,以及 Docker 容器化部署。我们还可以通过 Modelfile 修改模型参数,或基于现有模型微调。
- 官方网站:
https://ollama.com
打开官网之后,点击Download进入下载页面:
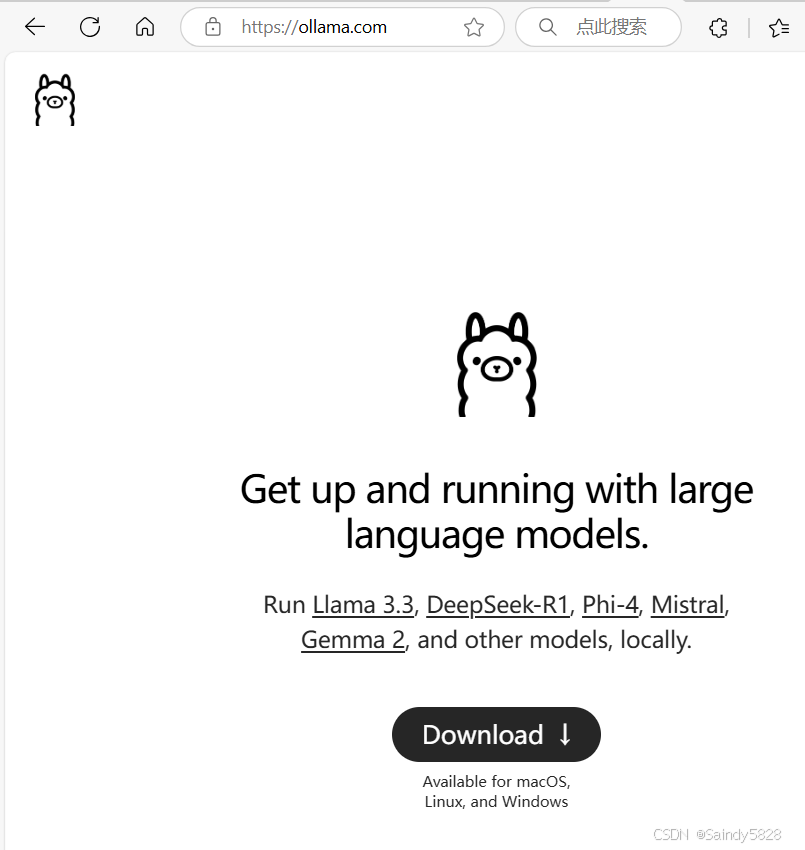
点击Download按钮,进入选择系统界面,根据你的系统选择,我这里用的是windows:
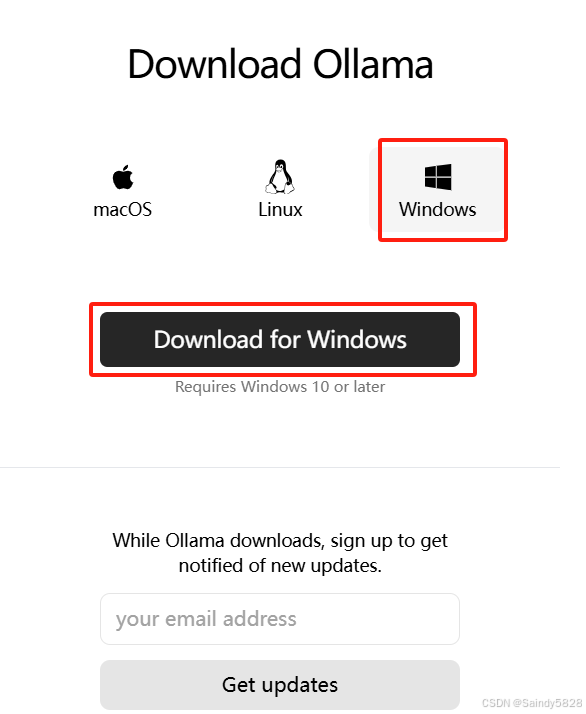
使用 Ollama 建议你的电脑有 8GB 内存以上(我这里用的7B 模型),下载完毕直接双击运行安装即可。
 双击运行
双击运行
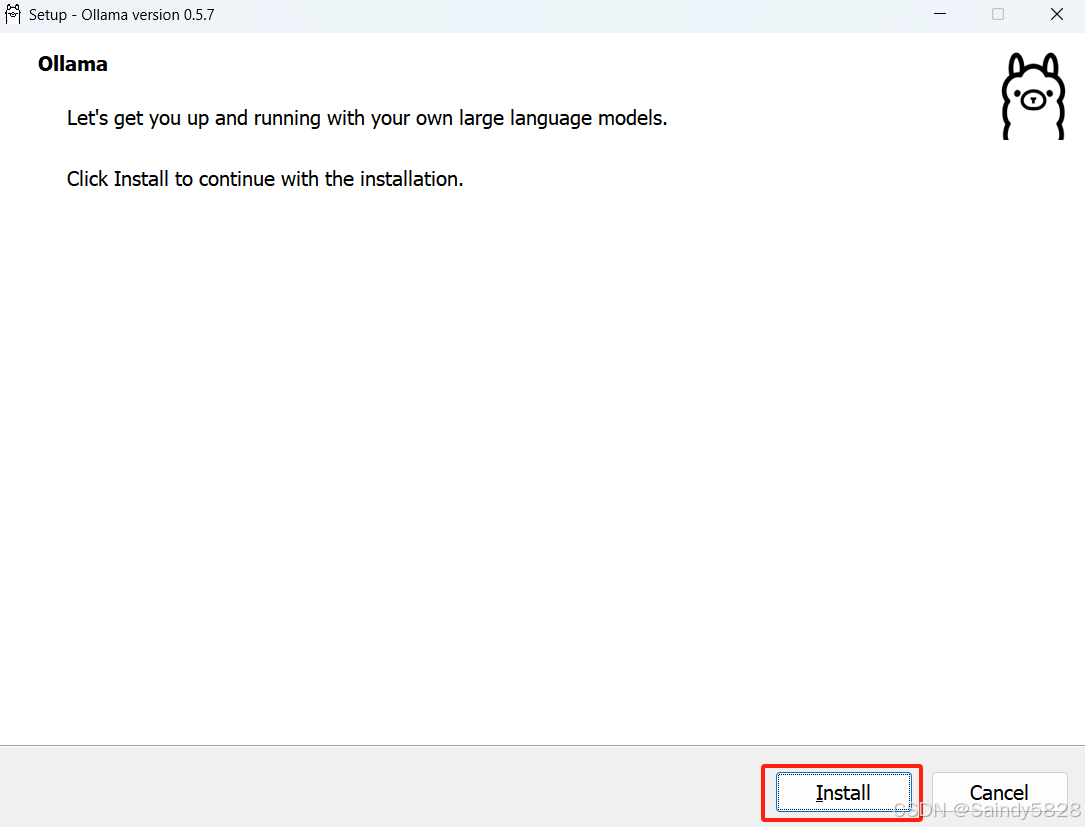
点击Install按钮进行安装,友情提醒:安装也是默认C盘的,请确保C盘有足够的容量。
安装完之后,在任务栏里有出现这样图标,即表示安装成功:![]()
2.安装使用 DeepSeek-R1 模型
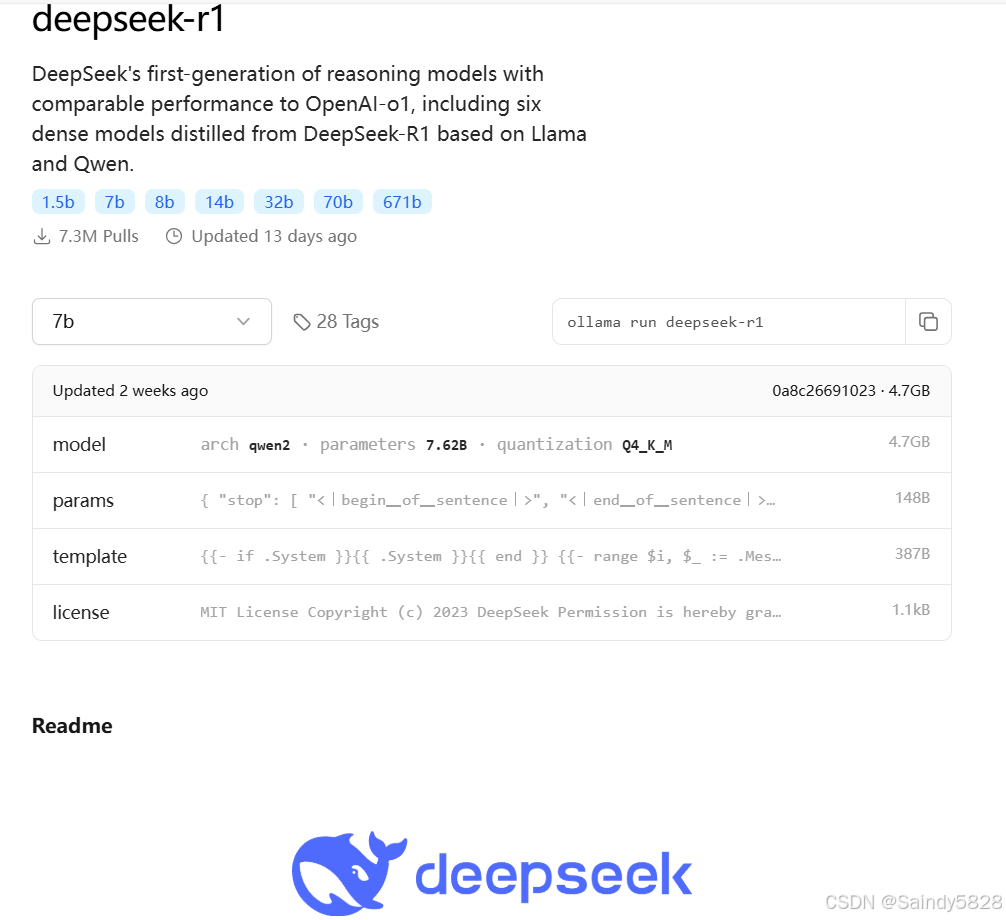
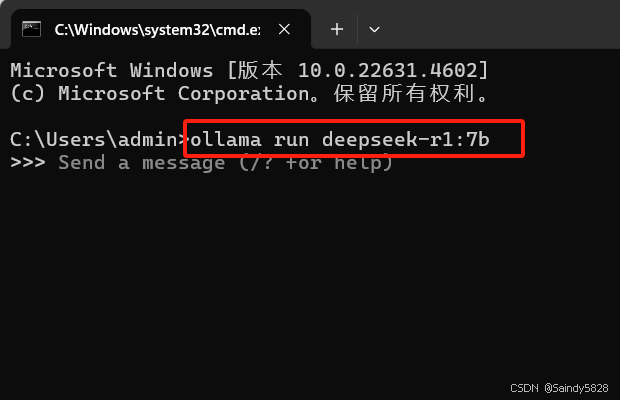
一句话简单教程:在终端输入命令:ollama run deepseek-r1:7b, 然后等待模型下载即可。
保姆级手把手教程:
点击开始,输入终端,在终端右键,以管理员身份运行
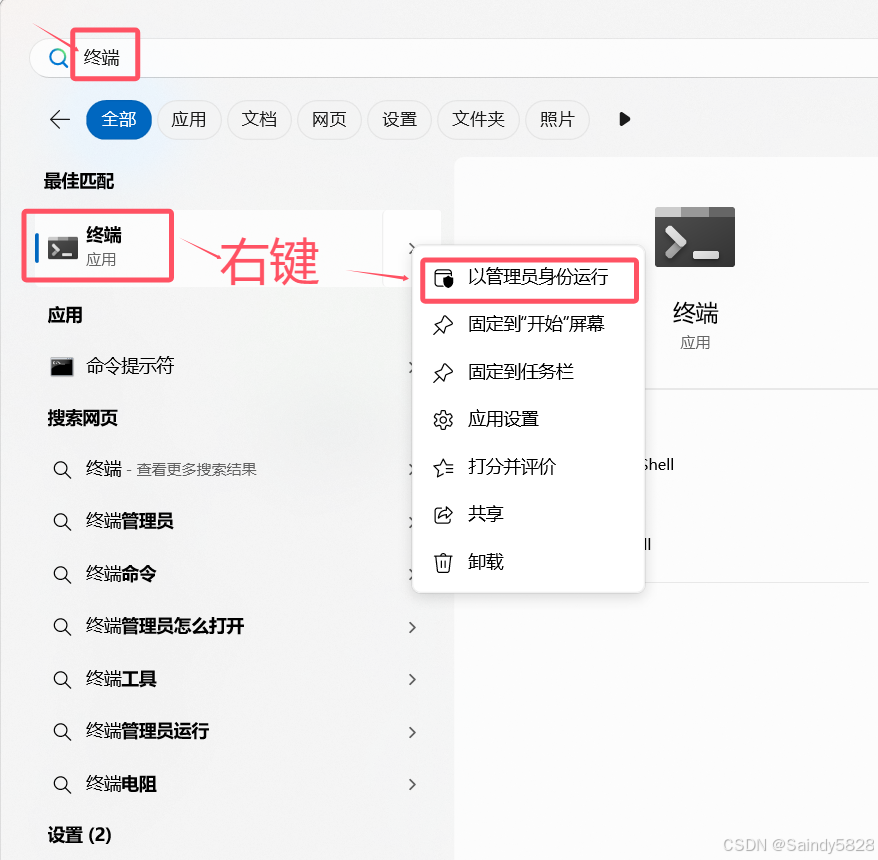
复制以下命令:ollama run deepseek-r1:7b ,回车:
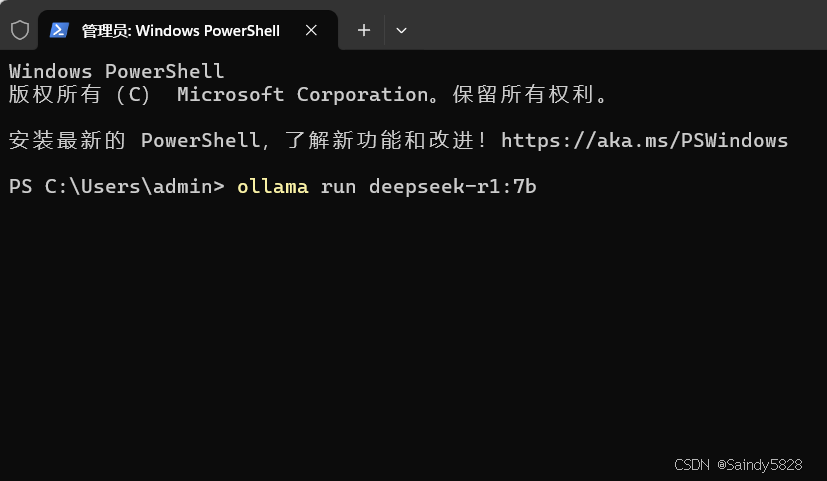
等待下载安装中:
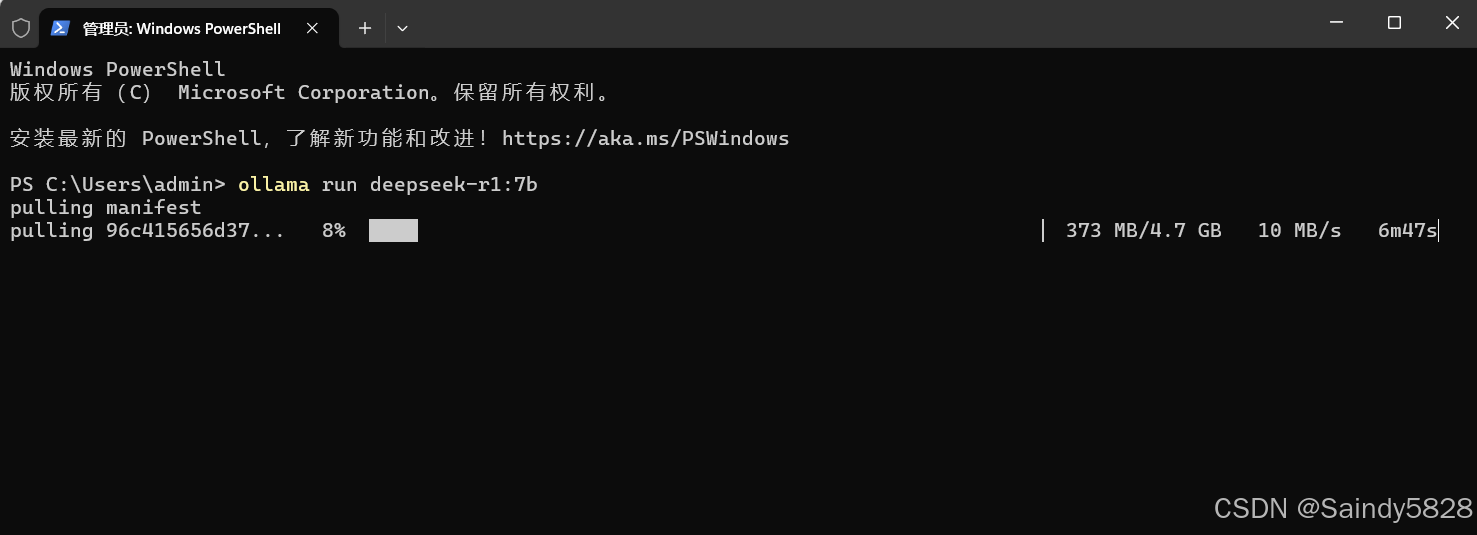
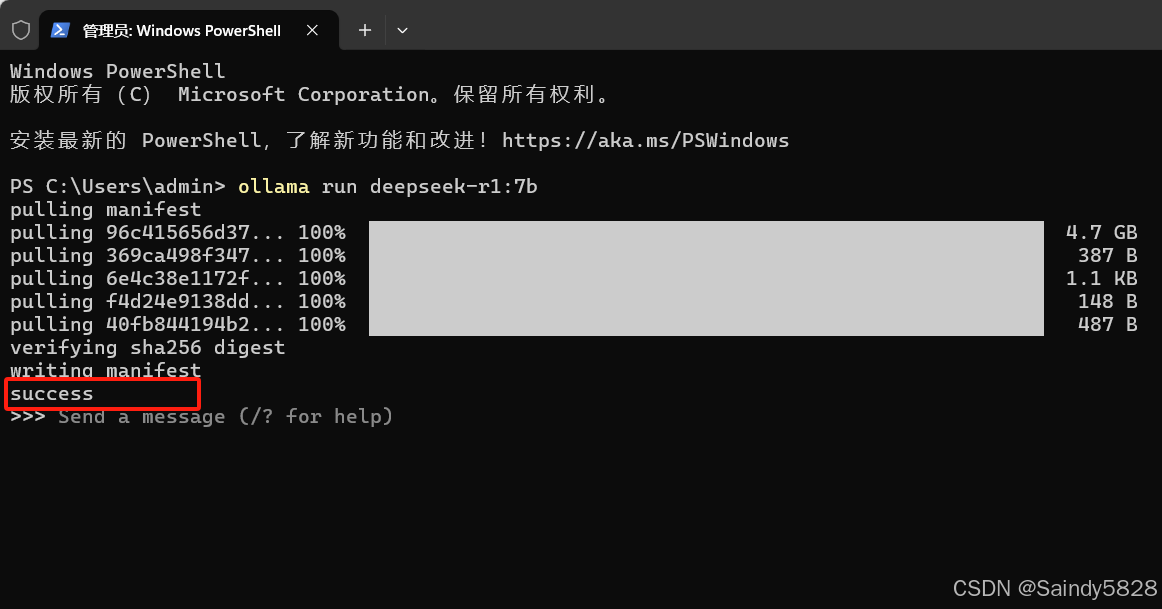
根据你的网速,几分钟之后,就可以安装成功了,看到这个success即表示安装模型成功:
另外:需要注意的是支持可选模型规格参数。
PC 本地且推理能力较强推荐用 1.5b,7b,8b,14b 模型。你也可以通过添加参数的方式来下载其它模型
例如命令:ollama run deepseek - r1:8b。具体可以到 Ollama 网站的模型里面查看,https://ollama.com/search。
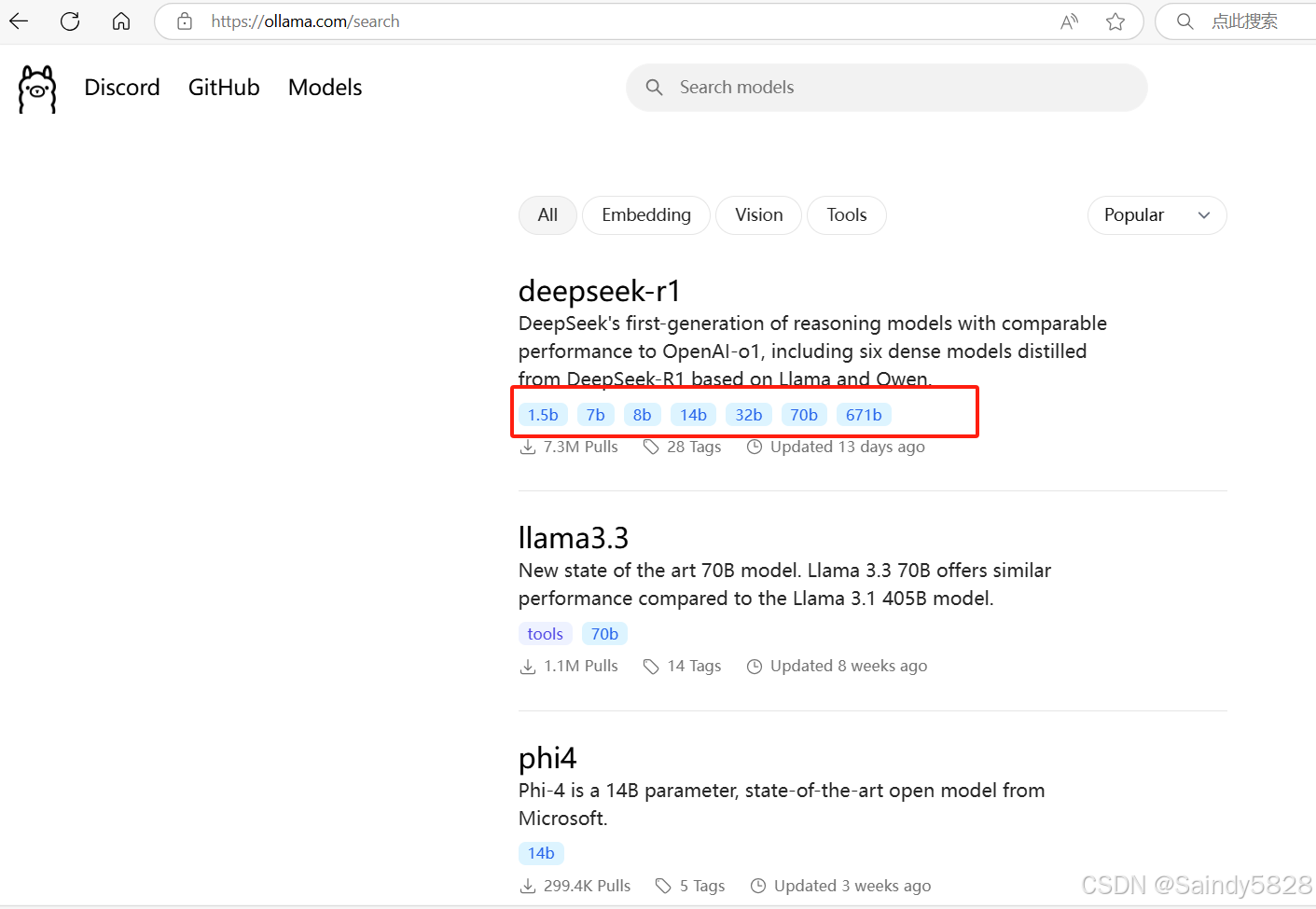
- 电脑配置有限:推荐使用 1.5B 或 7B 模型,可以在单张消费级显卡上运行。
- 更高的性能:可以选择 14B 或 32B 模型,但需要多 GPU 配置。
- 高端计算环境:可以选择 70B 模型,需要多张高端 GPU 支持。
平时的使用:
如果安装之后,已经关闭了终端,可以在 ”开始“ -- 运行 --输入cmd
根据你之前安装的版本运行,例如,我的是7b,
以下是其它的几个模型运行的方式:
-
DeepSeek-R1-Distill-Qwen-1.5B
ollama run deepseek-r1:1.5bDeepSeek-R1-Distill-Qwen-7B
ollama run deepseek-r1:7bDeepSeek-R1-Distill-Llama-8B
ollama run deepseek-r1:8bDeepSeek-R1-Distill-Qwen-14B
ollama run deepseek-r1:14bDeepSeek-R1-Distill-Qwen-32B
ollama run deepseek-r1:32bDeepSeek-R1-Distill-Llama-70B
-
几个模型对比图:
-
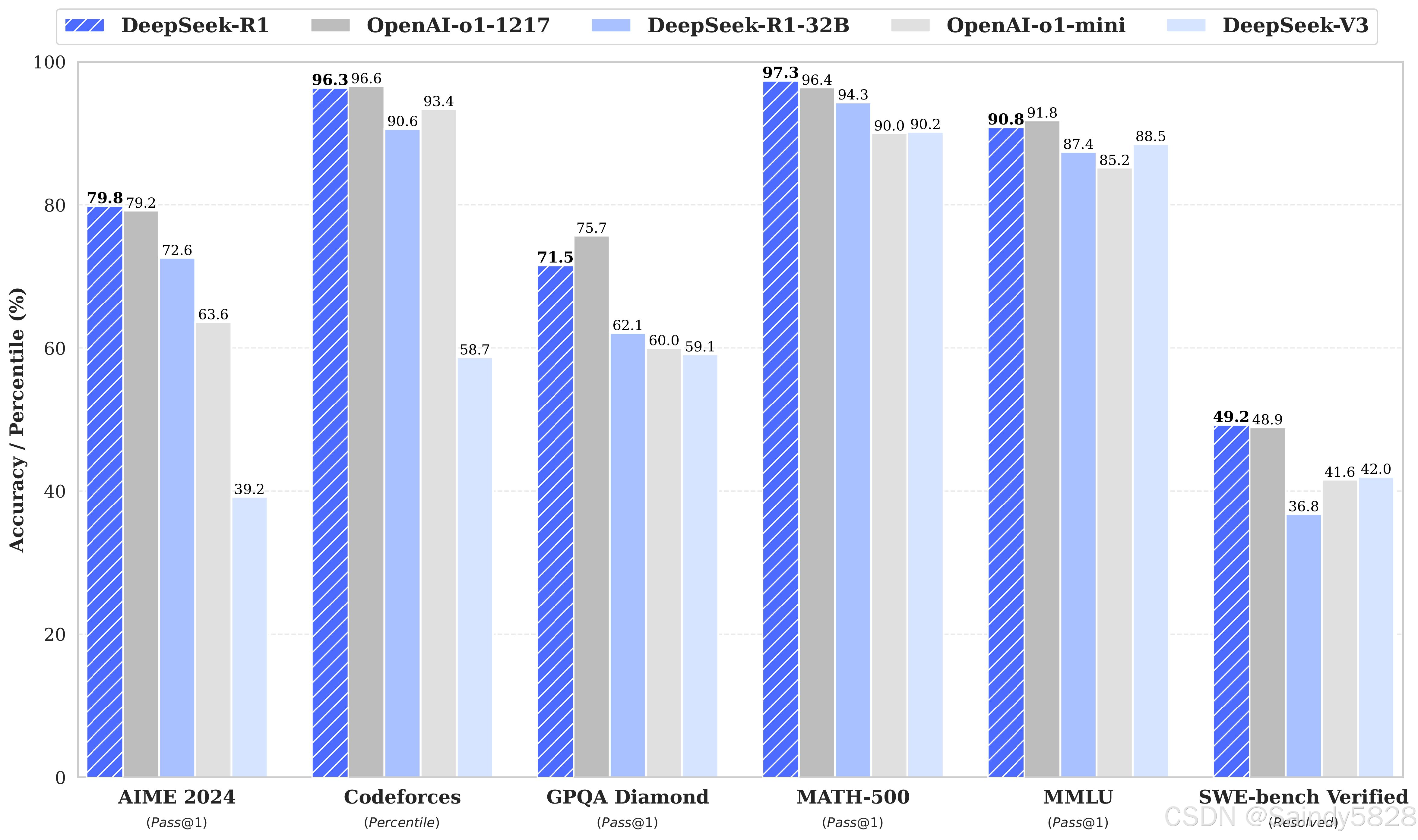
- 3、使用
安装完之后,其实就可以直接在终端使用了,在终端里输入问题提问就可以了,如:
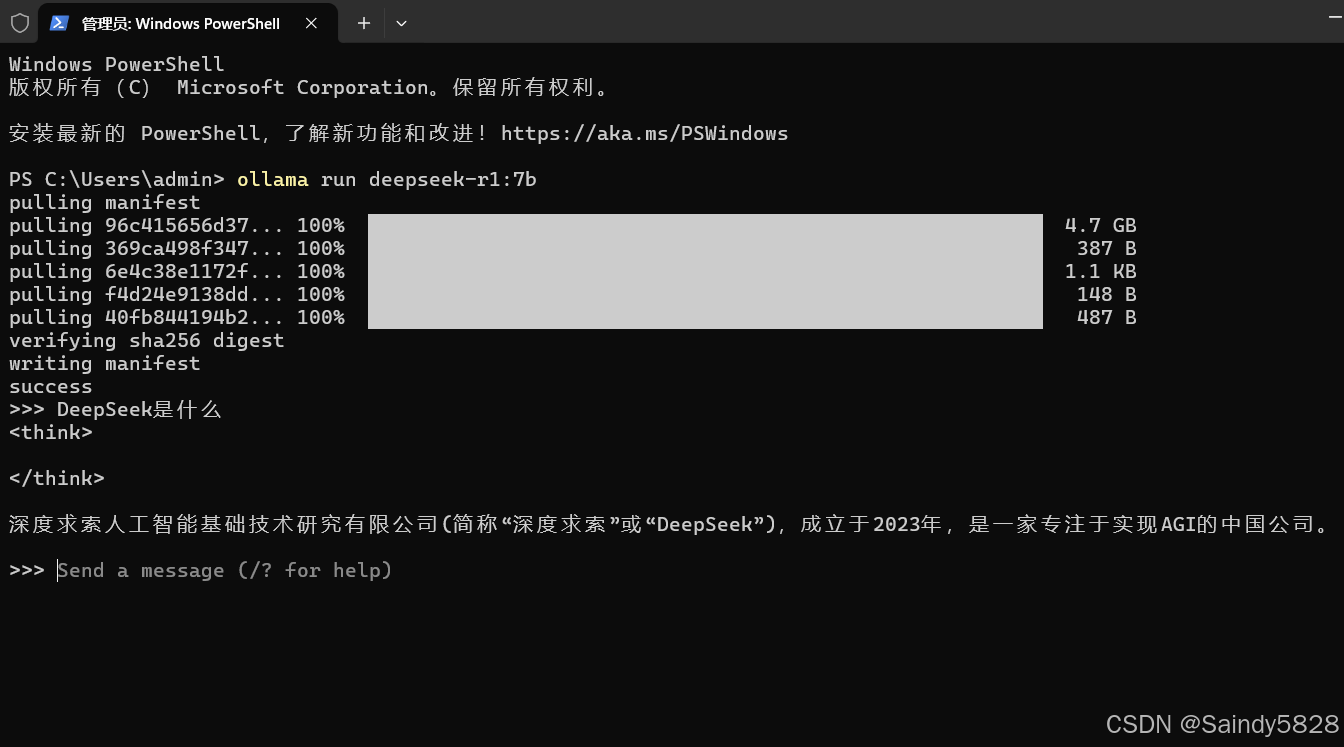
为了更加简单便捷的使用,可以安装ui界面:
安装UI界面
如果你不想在终端里面使用「DeepSeek」模型,也可以安装一个 Web UI 界面,比如「Web Assist」浏览器扩展插件,支持给本地 AI 模型提供网页界面。支持网络搜索功能、在侧边栏与 PDF 进行对话、与文档对话等功能。或者安装Open WebUI等其它各种方式,待后面有空再更新。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)