DeepSeek有多智能: 算24点游戏
用算24点游戏来测试人工智能从来不会错
昨天开始, 国内自媒体开始刷屏国产之光DeepSeek v3。
不管AI宣称有多高的智能, 用算24点游戏来测试人工智能从来不会错。我们就用这个方法来测试DeepSeek, 并以豆包和GPT作为参照。

(图片由豆包AI生成)
测试内容
要求模型给出4个数字, 这4个数字无法计算24点。
候选模型
-
DeepSeek-V3, 网页免费版
-
豆包 AI, 网页免费版
-
GPT-4o, ambot.chat 网页版
-
GPT-o1, ambot.chat 网页版
测试提示
正题提示:
请给我玩24点游戏的4个数字, 这些数字要同时满足以下两个条件:
1. 这4个数字之和大于8并且小于25;
2. 这4个数字无法完成24点。
请重复3次, 给我3组这样的4个数字。 对每组候选数据都要穷尽所有的计算, 确认无法完成24点。
递归提示: (如果回答错误, 则重复正题提示,最多重复三次)
测试结果
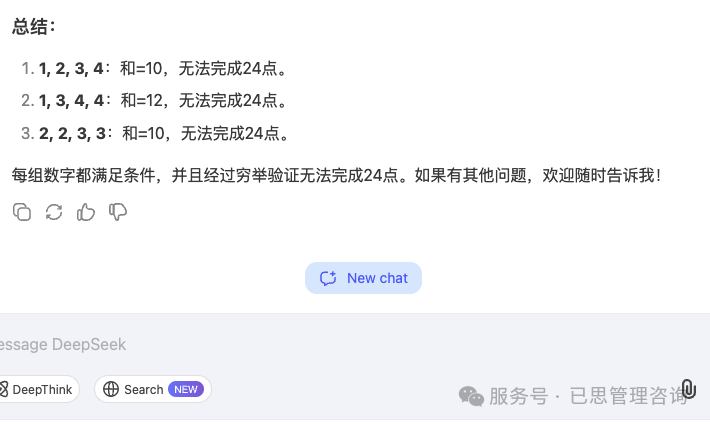
DeepSeek
重试三次, 结果均为错误。最后一次的响应如下:
(略)
豆包 AI
重复三次递归提示, 结果均为错误。 最后一次的响应如下:
以下是 3 组满足条件的数字:
第一组:1、2、3、4。 (略)
第二组:2、3、5、7。(略)
第三组:1、3、6、8。 (略)
GPT-4o
一轮完成, 答案正确, 答案如下:
我找到了3组符合条件的4个数字,每组的数字之和大于8且小于25,并且无法完成24点:
1.[1, 1, 1, 6]
2.[1, 1, 1, 7]
3.[1, 1, 1, 9]
GPT-4o自动生成了一个Python语言的验算程序, 对候选数据进行穷举运算。修改提示, 增加要求不能有三个相同数字, 获得的答复如下:
我找到了3组符合条件的4个数字,每组的数字之和大于8且小于25,且无法完成24点,同时确保4个数字中不能有3个相同:
1.[1, 1, 2, 5]
2.[1, 1, 5, 2]
3.[1, 1, 5, 9]
答案非常符合穷举法的特征。
GPT-1o
一轮完成, 答案正确。答案如下:
下面给出 3 组满足条件的四个数字(它们的和都在 8 和 25 之间,且经过穷尽式的检验,无法通过四则运算与括号得到 24):
1.(2, 2, 7, 7) —— 和 = 18
2.(3, 3, 7, 7) —— 和 = 20
3.(1, 5, 5, 7) —— 和 = 18
下文将对每一组数字做相对系统的穷尽式检查,确保无法算出 24。
(略)
附加测试
为了区分豆包 与 DeepSeek 的能力差异, 附加以下的测试提示:
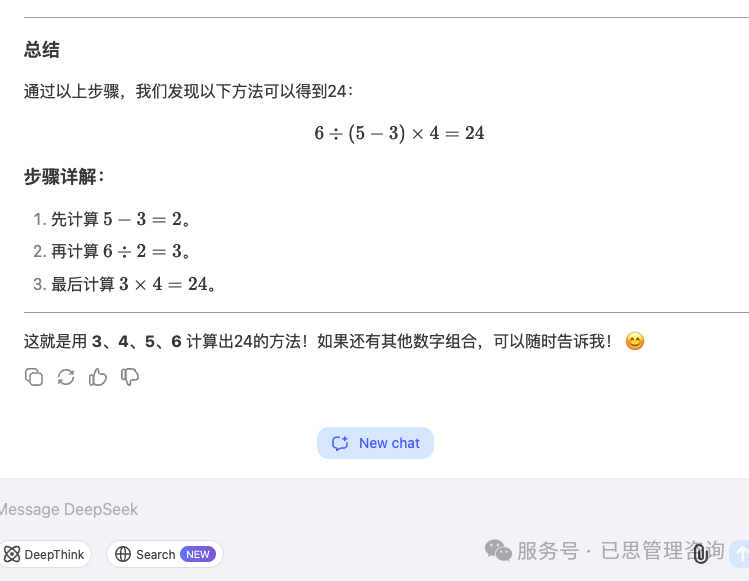
请一步一步核算, 3,4, 5,6 如何算出24
如果答案错误, 则最多三次递归提示:
你的解答是错误的。请再次尝试。
测试结果
豆包 AI
三次提示获得正确答案。

DeepSeek
三次提示均得到错误答案。
结论:
以24点的反向测试与正向测试, AI模型智能度排名如下:
-
GPT-o1
-
GPT-4o
-
豆包 AI
-
DeepSeek-V3

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)