DeepSeek V3:AI 模型的游戏规则改变者(附教程)
DeepSeek V3:AI 模型的游戏规则改变者(附教程)
DeepSeek V3:AI 模型的游戏规则改变者 什么是DeepSeek V3? DeepSeek
DeepSeek V3:AI 模型的游戏规则改变者

什么是DeepSeek V3?
DeepSeek V3是一款具有革命性的混合专家(MoE)模型,总参数达6710亿,每个标记激活370亿参数 。MoE方法允许多个专门模型(即“专家”)在门控网络下协同工作,门控网络为每个输入选择最佳“专家”。这实现了高效推理和具有成本效益的训练。
关键的架构创新包括:
- 多头潜在注意力机制:增强聚焦和处理能力。
- DeepSeek MoE架构:有助于进行可扩展且经济高效的训练。
- 辅助无损失负载均衡:确保稳定的性能,将性能下降降至最低。
下面用简单的方式理解一下。
混合专家(MoE)
MoE是一种让大型AI模型更高效的巧妙方法。
- 工作原理:它不是为每个任务激活大型AI模型的所有部分,而只使用最相关的部分。可以将其想象成一群专家(比如不同领域的专业人士),对于每个问题,只有合适的专家参与其中。
- 作用:节省计算能力,因为无需激活整个模型;能使模型规模非常大(拥有众多“专家”),同时仍保持快速高效。
多头潜在注意力机制(MLA)
MLA是一种聚焦于重要信息部分的技术。
- 工作原理:想象阅读一本书时,你能同时快速聚焦多个关键词或观点,而不是逐字阅读。MLA让模型能够查看输入数据中的多个“重要点”(头),以便更好地理解数据。
- 作用:通过识别和处理输入中最关键的部分,使模型更加准确;帮助模型更快地理解复杂信息。
总结来说,MoE通过仅激活每个任务所需的“专家”来提高模型效率,MLA则通过让模型同时关注多个重要细节来增进理解。

模型总参数为6710亿,每个标记激活370亿参数。
参数
参数就像是机器学习模型中的“旋钮”或设置,模型在训练期间会对其进行调整,以学习如何执行任务。参数越多,意味着模型规模越大,能够学习到更复杂的模式。
- 6710亿总参数:这意味着整个模型拥有6710亿个参数,数量非常庞大!可以说该模型拥有一个具备强大学习能力的“超级大脑”。
- 每个标记激活370亿参数:模型并非同时使用全部6710亿个参数。对于每个输入片段(一个“标记”,比如一个单词或单词的一部分),它仅使用与理解该特定标记最相关的370亿个参数。
- 重要性:如果模型为每个标记都使用全部6710亿个参数,将需要大量的计算能力和时间。通过为每个标记仅激活370亿个参数,模型在节省时间和资源的同时仍能给出高质量的结果。
高效的训练和成本效益
DeepSeek V3的训练过程不仅强大,而且成本非常经济,具体如下:
- 训练规模:在14.8万亿高质量标记上进行预训练。
- 时间效率:DeepSeek - V3的完整训练仅需278.8万个H800 GPU小时。
- 成本效率:总训练成本仅为560万美元,仅是类似规模模型所需成本的一小部分。
基准测试性能
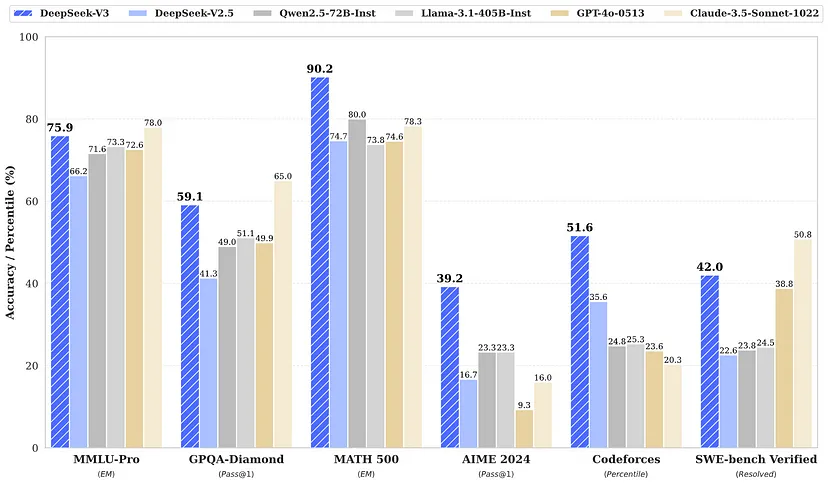
DeepSeek V3在多个基准测试中接受了广泛测试,包括:
- 通用问答、数学、代码和软件基准测试:始终优于GPT - 4和Claude 3.5等竞争对手。
- 模型基准测试:展现出卓越的通用性和精确性。
使DeepSeek V3脱颖而出的特性
- 强化学习和微调:该模型支持广泛的定制,以适应特定的用例。
- 知识蒸馏:融入了来自DeepSeek R1的推理能力和反思模式。
- 推测解码:通过多标记预测(MTP)实现更快的推理。
- API兼容性:完全与OpenAI兼容,可实现无缝集成。
实际操作测试
DeepSeek V3在现实世界中的性能展示了其在各种任务中的通用性:
- 自然语言理解:能够以细致入微的推理回应伦理困境和复杂问题;处理棘手或模糊的问题时,保持专业性和准确性。
- 多语言能力:能够在多种语言之间进行无缝翻译,并考虑到文化敏感性;对语言的细微差别掌握出色。
- 数学和逻辑:能够逐步解决复杂问题,展现出清晰的推理和精确性。
- 编码和查询优化:能够编写优化的C++程序和SQL查询,并详细解释逻辑;为代码优化和最佳实践提供详细的理由。
DeepSeek V3不仅仅是一个AI模型,它证明了创新如何让强大的技术变得更易获取、更经济实惠。无论你是希望增强应用程序,还是探索新的AI可能性,DeepSeek V3都是值得关注的工具。
程序员为什么要学大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)