DeepSeek-R1同款算法!强化学习2025发论文的核心思路
最近DeepSeek-R1系列犹如一记炸雷响彻整个AI圈,功能比肩ChatGPT-o1还是开源,用过之后大家纷纷宣布退订20刀乐(hh)。而DeepSeek-R1最关键的创新其实已经发布了,就是LLM算法GRPO(还有多阶段训练策略)。这个在RL领域的创新为学术界和工业界提供了重要的思路,尤其在等方面。同时,它也为未来RL的研究指明了方向——,啊对,还有开源(doge)。为方便刚入门RL的小白以及
最近DeepSeek-R1系列犹如一记炸雷响彻整个AI圈,功能比肩ChatGPT-o1还是开源,用过之后大家纷纷宣布退订20刀乐(hh)。
而DeepSeek-R1最关键的创新其实已经发布了,就是LLM强化学习算法GRPO(还有多阶段训练策略)。这个在RL领域的创新为学术界和工业界提供了重要的思路,尤其在复杂任务训练范式、算法效率优化以及RL与模型架构协同设计等方面。同时,它也为未来RL的研究指明了方向——以工程落地为导向,追求算法简洁性、训练高效性、任务普适性,啊对,还有开源(doge)。
为方便刚入门RL的小白以及想要进一步创新的同学了解前沿,我整理了100篇强化学习相关的新论文,主要涉及RL与其他技术协同,以及它自身改进等方面,代码开源的都放上了,觉得有用不妨点个赞支持下~
全部论文+开源代码需要的同学看文末
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning
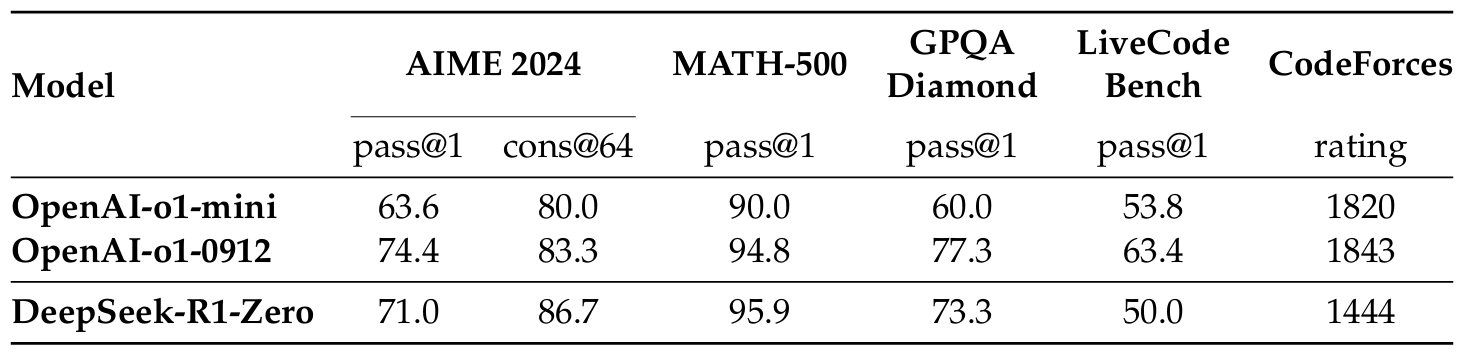
方法:本文研究通过纯强化学习提升大型语言模型推理能力,提出DeepSeek-R1-Zero和DeepSeek-R1两种模型,依托多阶段训练和冷启动数据,显著提高数学、编码等推理任务表现,并通过蒸馏技术将推理能力传递至小型模型,从而填补现有研究在纯RL应用于推理领域的空白。
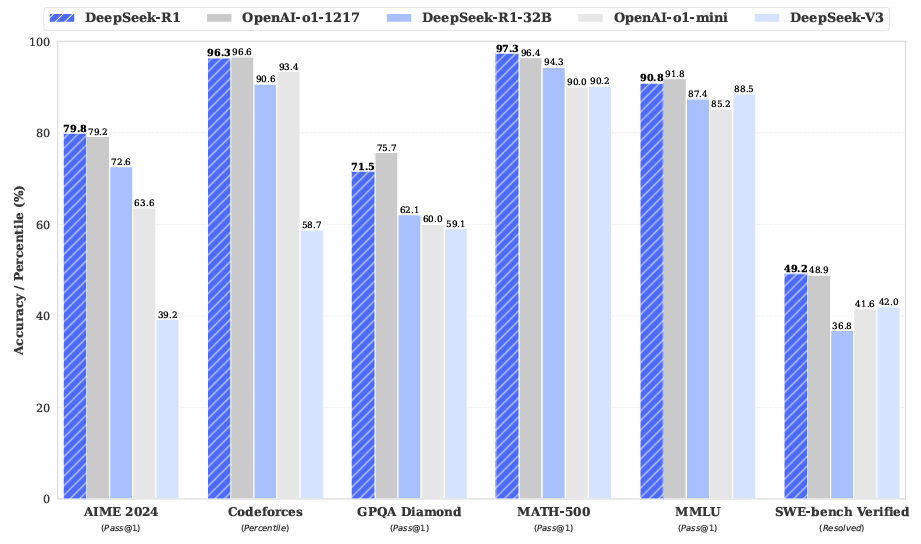
创新点:
-
DeepSeek-R1-Zero首次应用纯强化学习(RL)直接训练基础模型,而不依赖于监督微调(SFT),实现了卓越的推理能力。
-
大模型的推理模式可以成功蒸馏至小模型中,且其性能优于在小模型上直接应用RL发现的推理模式。
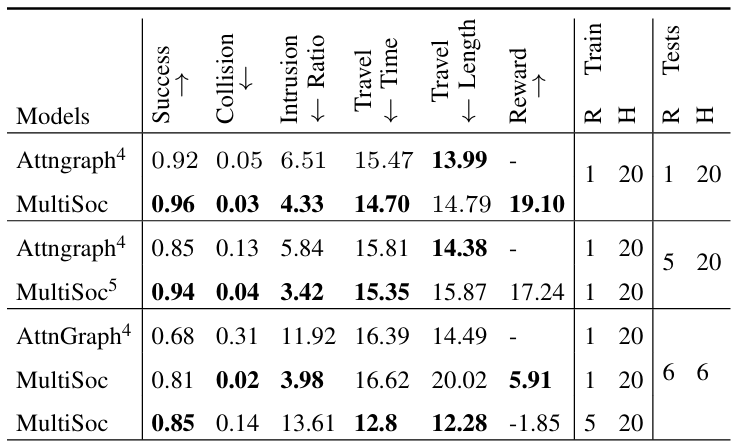
Attention Graph for Multi-Robot Social Navigation with Deep Reinforcement Learning
方法:论文介绍了一个名为MultiSoc的新方法,它结合了强化学习和注意力机制来学习多智能体系统中的社交意识导航策略,展示了其在多智能体隐式协调及处理多种人类行为策略方面的优越性,同时引入可定制的邻域密度元参数,以适应不同的导航需求。
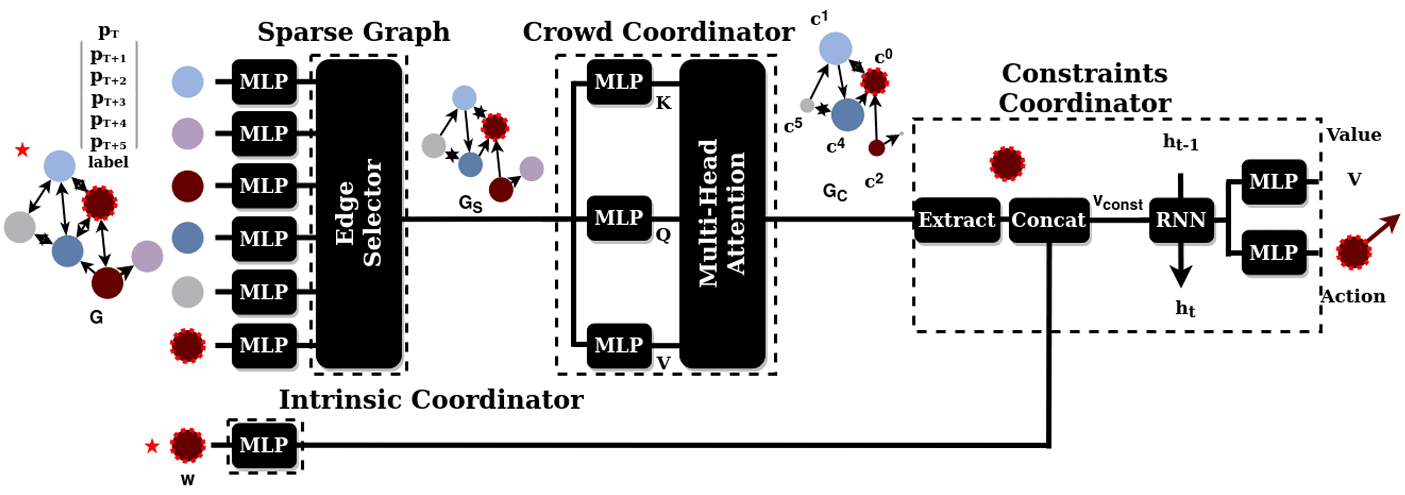
创新点:
-
MultiSoc 模型是第一个用于多机器人社会导航的基于图的交互模型。
-
MultiSoc 引入了一个可定制的元参数,用于调整每个机器人导航策略中需要考虑的邻域密度。
-
通过使用图神经网络和强化学习,MultiSoc 模型实现了在复杂人群导航中的多智能体隐式协调能力。
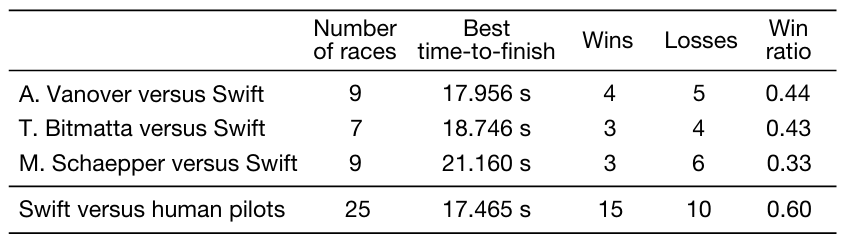
Champion-level drone racing using deep reinforcement learning
方法:Swift系统通过结合深度强化学习和卡尔曼滤波,在无人机竞速领域实现了突破性进展。它不仅在与人类冠军的直接对抗中多次获胜,还创下了比人类最佳成绩快半秒的最快比赛记录。
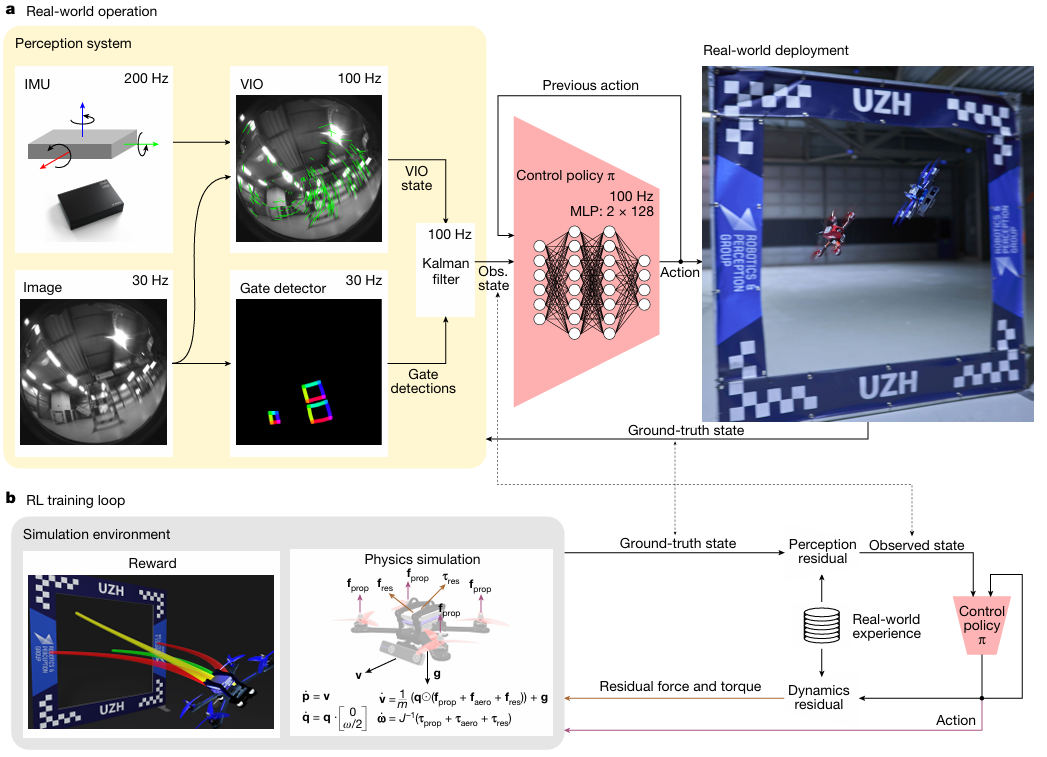
创新点:
-
提出了一种结合实证模型的创新方法,能够有效处理不同部署环境下的动态变化和观测噪声问题。
-
通过使用高斯过程和k近邻回归分别对感知残差和动态残差进行建模,作者能够在仿真中整合这些模型,并对竞速策略进行微调。
-
设计了四种不同的仿真环境来评估其方法的稳健性,涵盖从理想化动态到更准确的空气动力学模拟。
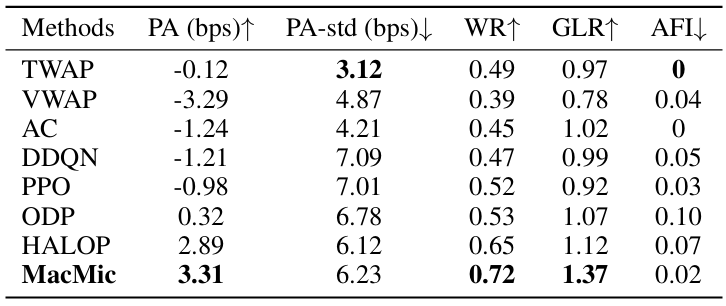
MacMic: Executing Iceberg Orders via Hierarchical Reinforcement Learning
方法:论文提出了一种名为MacMic的分层强化学习框架,通过将最优执行问题表述为分层马尔可夫决策过程(MDP),并在粗粒度的高层代理进行订单分割和细粒度的低层代理执行订单的双阶段框架中,采用有效的表示学习技术,实现对长时间段订单执行问题的解决。
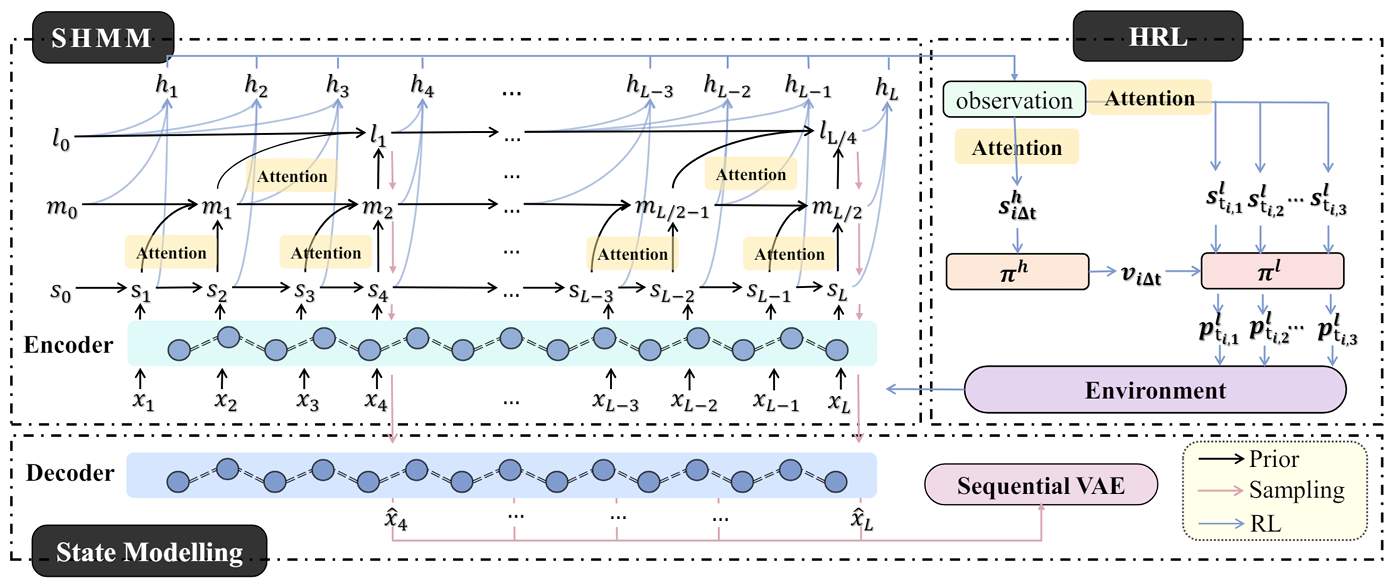
创新点:
-
创新性地将订单执行问题形式化为分层马尔可夫决策过程 (MDP),将复杂的长时间任务分解为两个更简单的阶段,每个阶段仅需做一维的价格或数量决策。
-
引入因果堆叠隐马尔可夫模型 (SHMM) 来提取多粒度的市场状态表示。
-
结合模仿学习技术,通过在高层策略训练中引入专家数据的引用,提升了探索效率。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“强化改进”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)