从老外视角来仰慕DeepSeek V3的强大
去年,DeepSeek LLM 以其令人印象深刻的670亿参数,在英文和中文理解方面,经过精心训练的2万亿个token的庞大数据集引起了轰动。DeepSeek 通过开源其7B/67B基础和聊天模型,为研究合作树立了新的基准,深入植根于AI社区。现在,如果我告诉你有一个拥有6850亿参数的AI,它在AI领域的几乎所有模型中表现优异,并且是开源的,听起来是不是很吸引人?DeepSeek 通过发布 De
去年,DeepSeek LLM 以其令人印象深刻的670亿参数,在英文和中文理解方面,经过精心训练的2万亿个token的庞大数据集引起了轰动。DeepSeek 通过开源其7B/67B基础和聊天模型,为研究合作树立了新的基准,深入植根于AI社区。现在,如果我告诉你有一个拥有6850亿参数的AI,它在AI领域的几乎所有模型中表现优异,并且是开源的,听起来是不是很吸引人?DeepSeek 通过发布 DeepSeek V3 迈出了巨大的一步,由中国实验室开发的DeepSeek,将AI创新的界限推向了更远。这是一个强大的Mixture-of-Experts (MoE)语言模型,总共有6710亿参数,每个token激活37亿。
令人印象深刻的部分是——它的训练成本仅为550万美元!
DeepSeek V3在宽松的许可证下发布,使开发者能够下载、修改并将模型集成到各种应用中,包括商业应用。它的多功能性涵盖了一系列基于文本的任务,如编码、翻译以及从描述性提示生成文章或电子邮件,使其成为开发者和企业的强大工具。
此外,DeepSeek V3在几个关键领域超越了公开可用和封闭的AI模型。在Codeforces的竞技编程中,DeepSeek V3超越了包括Meta的Llama 3.1 405B、OpenAI的GPT-4o和阿里巴巴的Qwen 2.5 72B在内的竞争对手。该模型还在Aider Polyglot测试中表现出色(排行榜上位列第二),展示了无与伦比的生成新代码并与现有项目无缝集成的能力。
迄今为止最大的飞跃:
- 每秒60个token(比V2快3倍!)
- 增强能力
- API兼容性保持不变
- 完全开源的模型和论文
DeepSeek V3:庞大的开源6850亿参数
你知道吗,拥有6850亿参数(6710亿主模型权重和140亿多token预测(MTP)模块权重)的DeepSeek V3可以记住你在2017年喝了多少啤酒吗?令人印象深刻,对吧?此外,根据创建者的说法,他们花费了550万美元来训练DeepSeek V3,如果我们与OpenAI相比——OpenAI的CEO Sam Altman提到GPT-4的训练成本超过1亿美元。这种鲜明对比突出了DeepSeek V3的显著成本效率,以一小部分的费用实现了尖端性能,使其成为AI领域的游戏规则改变者。
同时,DeepSeek-V3看起来在2.8M GPU小时(约11倍少于使用30.8M GPU小时的Llama 3 405B)的计算量上更强。
DeepSeek(中国AI公司)今天用一个前沿级LLM的开放权重发布让它看起来很容易,这个LLM在开玩笑的预算(2048个GPU运行2个月,600万美元)上训练。
作为参考,这种能力的水平应该需要接近16K个GPU的集群,确实效率高
DeepSeek V3代表了AI架构和训练效率的巨大飞跃,推动了大规模语言模型的界限。这个开源模型不仅提供了最先进的性能,而且以显著的效率和可扩展性实现了这一点。以下是使DeepSeek V3成为杰出创新的因素:
1. 先进架构:多头潜在注意力和负载平衡
DeepSeek V3基于其前身DeepSeek V2的成熟框架,采用了多头潜在注意力(MLA)和尖端的DeepSeekMoE架构。这些创新确保了高效的推理和成本效益的训练。此外,DeepSeek V3采用了无辅助损失的负载平衡策略,消除了与负载平衡机制相关的典型性能权衡。
该模型还集成了一个多token预测(MTP)目标,增强了其同时预测多个token的能力。这不仅提高了性能,还使推测性解码成为可能,显著加快了推理速度。
2. 前所未有的规模和效率的预训练
DeepSeek V3在一个庞大的14.8万亿个多样化、高质量的token数据集上进行预训练(为了更好地理解,100万个token大约是750,000个单词),这个规模远远超过了其前身。这种预训练是使用革命性的FP8混合精度训练框架实现的,标志着FP8首次在超大规模模型中成功应用。结果包括:
-
无缝GPU利用率:通过算法、框架和硬件的共同设计,DeepSeek V3克服了跨节点MoE训练中的通信瓶颈,实现了几乎完全的计算通信重叠。
-
成本效益训练:仅用2.664M H800 GPU小时,DeepSeek V3就成为了最强的开源基础模型,为效率树立了新标准。后预训练阶段仅需要额外的0.1M GPU小时,使整个过程非常经济。
3. 后训练增强:知识蒸馏,掌握推理
DeepSeek V3集成了一个创新的知识蒸馏管道,利用DeepSeek R1系列模型的推理能力。这个管道将先进的验证和反思模式整合到模型中,显著提高了其推理性能。此外,输出风格和长度被精心控制,以确保跨任务的多功能性和一致性。
4. 无与伦比的性能和稳定性
广泛的评估证实,DeepSeek V3超越了所有开源模型,并与领先的封闭源AI系统竞争。尽管其规模和复杂性巨大,但整个训练过程异常稳定,在整个周期中没有不可恢复的损失峰值或回滚。
DeepSeek V3是创新和合作的力量的证明,为开发者和研究人员提供了一个强大、可扩展且成本效益的工具,以应对AI及其它领域的广泛挑战。其开源性质确保了可访问性,为编码、推理和多模态应用的突破铺平了道路。
在不同基准上评估DeepSeek V3

评估的基准
-
MMLU-Pro (Exact Match – EM): 衡量事实和多任务QA的准确性。
-
GPQA-Diamond (Pass@1): 评估精确QA性能,重点关注更困难的任务。
-
Math 500 (EM): 测试数学推理和问题解决能力。
-
AIME 2024 (Pass@1): 专注于高级数学竞赛问题。
-
Codeforces (Percentile): 衡量编程竞赛技能。
-
SWE-bench Verified (Resolved): 测试软件工程任务解决的准确性。
关键观察
- MMLU-Pro
-
DeepSeek-V3以75.9%的准确率领先,超越了其最接近的竞争对手,如**GPT-4-0513 (73.3%)和Claude-3.5 (72.6%)**。
-
这表明其在多任务事实QA方面的强大实力。
- GPQA-Diamond
-
再次,DeepSeek-V3以**59.1%**的高分领先,超越了其他如Claude-3.5 (49.9%)和Qwen2.5 (51.1%)。
-
展示了在高难度QA任务上的强大精确度。
- Math 500
-
以90.2%的准确率领先,远高于Claude-3.5 (80.0%)和GPT-4-0513 (78.3%)。
-
表明其在数学推理方面的能力非凡。
- AIME 2024
-
得分**39.2%**,远高于GPT-4-0513 (23.3%)和Claude-3.5 (16.0%)。
-
突出了其解决高级竞赛级数学问题的能力。
- Codeforces
-
达到51.6百分位,超越了GPT-4-0513 (35.6百分位)和其他模型。
-
反映了其在编程竞赛中的强能力。
- SWE-bench Verified
-
得分**42.0%**,与GPT-4-0513 (50.8%)竞争,优于Claude-3.5 (38.8%)。
-
显示了在软件工程问题解决方面的竞争力。
DeepSeek-V3的整体性能
-
一致性和优越性:DeepSeek-V3在所有主要基准测试中一致性地表现优异,除了SWE-bench Verified,GPT-4略胜一筹。
-
强项:其最强的领域是**mathematical problem-solving (MATH 500)和multi-task QA (MMLU-Pro)**。
-
超越前一版本:与DeepSeek-V2.5相比,DeepSeek-V3在**AIME 2024 (39.2% vs. 23.3%)和Codeforces (51.6% vs. 35.6%)**等方面有显著提升,显示出增强的推理和竞技编程技能。
这次评估突出了DeepSeek-V3在处理复杂推理、高级数学和竞技编程任务方面的卓越能力。
此外,这里是开放式生成评估:
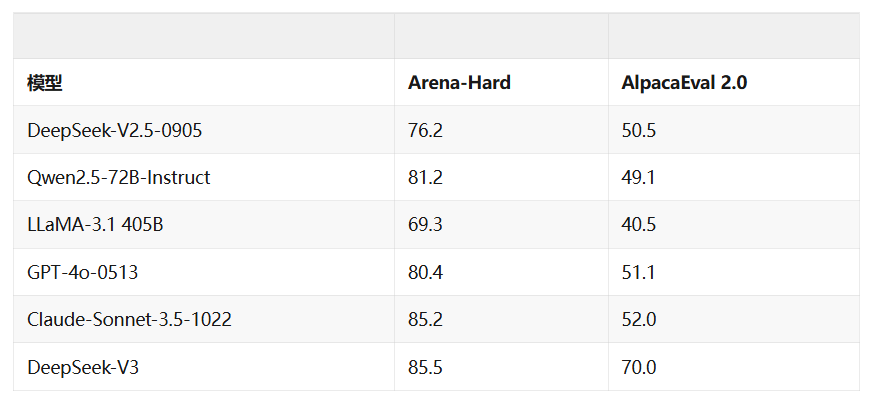
- Arena-Hard性能:
-
DeepSeek-V3以85.5的成绩位居第一,略高于Claude-Sonnet-3.5 (85.2),显著优于DeepSeek-V2.5 (76.2)。
-
这表明其在困难情境中生成全面、上下文感知响应的卓越能力。
- AlpacaEval 2.0性能:
-
DeepSeek-V3以70.0的成绩领先,远高于Claude-Sonnet-3.5 (52.0),是表现第二好的。
-
这表明在开放式输出的整体质量和用户偏好方面有显著提升,更好地符合用户期望。
- 与竞争对手的比较:
-
从V2.5到V3的飞跃是巨大的,表明在响应连贯性和用户偏好对齐方面有重大升级。
-
在两个基准上得分较低,突出了开放式生成能力的弱点。
-
在两个指标上都有竞争力,但没有匹配DeepSeek-V3以用户为中心的质量。
-
在Arena-Hard上表现合理,但在用户偏好上明显落后,表明与用户友好的响应风格对齐较弱。
-
**Qwen2.5 (Arena-Hard: 81.2, AlpacaEval: 49.1)**:
-
**GPT-4-0513 (Arena-Hard: 80.4, AlpacaEval: 51.1)**:
-
**LLaMA-3.1 (Arena-Hard: 69.3, AlpacaEval: 40.5)**:
-
**DeepSeek-V2.5 (Arena-Hard: 76.2, AlpacaEval: 50.5)**:
你还可以参阅这个以更好地理解评估:
Aider Polyglot基准结果
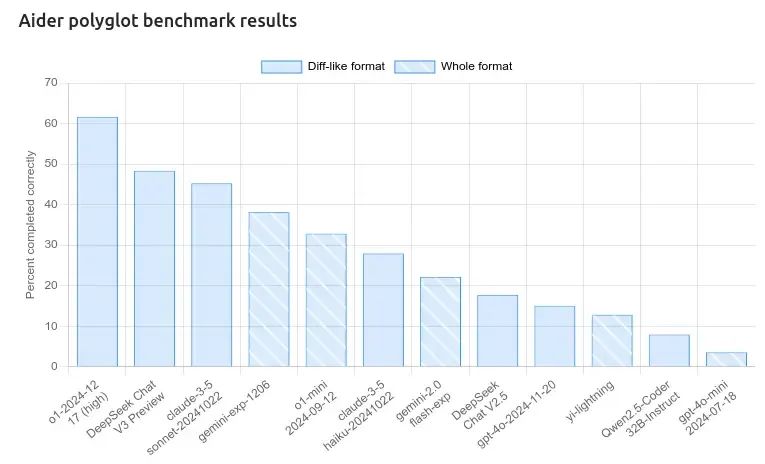
这里是Aider Polyglot基准结果,评估模型完成任务的能力。评估分为两种输出格式:
-
Diff-like格式(阴影条):输出类似于代码diffs或小更新的任务。
-
Whole格式(实心条):需要生成整个响应的任务。
关键观察
- 顶级表现者:
-
o1-2024-11-12 (Tingli)以近65%的准确率在整体格式中领先,显示出在任务中的表现卓越。
-
DeepSeek Chat V3预览和Claude-3.5 Sonnet-2024-1022紧随其后,得分在40-50%之间,在两种格式中都表现出坚实的任务完成能力。
- 中等表现者:
-
Gemini+exp-1206和Claude-3.5 Haiku-2024-1022在两种格式中得分适中,突出了平衡但平均的表现。
-
DeepSeek Chat V2.5和Flash-2.0处于中低范围,与领先模型相比,任务解决能力较弱。
- 较低表现者:
- y-lightning, Qwen2.5-Coder 32B-Instruct, 和GPT-4o-mini 2024-07-18得分最低,准确率低于10-15%。这表明在处理两种格式的任务上存在显著限制。
- 格式比较:
-
模型通常在整体格式中比Diff-like格式表现稍好,意味着完整响应生成比小的、增量变化处理得更好。
-
阴影条(Diff-like格式)一致低于整体格式的对应条,表明在这一特定能力上存在一致的差距。
DeepSeek Chat V3预览的位置:
-
在前三名表现者中排名。
-
在整体格式中得分约为50%,在Diff-like格式中稍低。
-
这表明在处理完整任务生成方面有很强的能力,但在Diff-like任务上还有改进的空间。
洞察:
-
基准突出了评估模型的多样化优势和弱点。
-
像o1-2024-11-12这样的模型在两种任务格式中都表现出色,而像DeepSeek Chat V3预览这样的模型主要在完整任务生成中表现出色。
-
较低表现者表明需要在细微和更广泛的任务处理能力上进行优化。
这最终反映了不同AI系统在完成基准任务时的多功能性和专业优势。
DeepSeek V3的聊天网站和API平台
- 你可以通过官方网站与DeepSeek-V3互动:DeepSeek Chat。
- 此外,他们在DeepSeek平台上提供了一个与OpenAI兼容的API:链接。
API的成本取决于token:

如何运行DeepSeek V3?
如果你不想使用聊天界面,而想直接与模型合作,有一个替代方案。模型DeepSeek-V3的所有权重都在Hugging Face上发布。你可以在那里访问SafeTensor文件。
模型大小和硬件要求:
首先,模型非常大,有6710亿参数,这使得在标准消费级硬件上运行变得具有挑战性。如果你的硬件不够强大,建议使用DeepSeek平台直接访问。等待Hugging Face Space如果有一个可用。
如何本地运行?
如果你有足够的硬件,你可以使用DeepSeek-Infer演示、SGLang、LMDeploy、TensorRT-LLM、vLLM、AMD GPU、华为Ascend NPU在本地运行模型。
将模型转换为量化版本以减少内存需求,这对于低端系统特别有帮助。
以下是如何将FP8权重转换为BF16的方法:
如果你需要bf16的转换脚本
cd inference
python fp8_cast_bf16.py --input-fp8-hf-path /path/to/fp8_weights --output-bf16-hf-path /path/to/bf16_weights
使用DeepSeek-Infer演示的设置过程
Hugging Face的transformers库尚未直接支持该模型。要设置它,你需要:
克隆DeepSeek AI GitHub仓库:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
安装所需的依赖项:
cd DeepSeek-V3/inference
pip install -r requirements.txt
下载Hugging Face检查点并在本地运行模型。
参考这个:DeepSeek V3
建议:
-
如果你有强大的硬件,尝试在本地运行模型以充分探索其潜力。
-
否则,使用DeepSeek.com聊天界面或他们的API平台以获得无缝访问。
LLM DeepSeek插件
你还可以使用llm-deepseek插件访问模型:
# 第1步:安装llm包
!pip install llm
# 第2步:安装DeepSeek插件
!llm install llm-deepseek
# 第3步:设置DeepSeek API密钥
!llm keys set deepseek
# 提示时粘贴你的API密钥
# 第4步:运行DeepSeek聊天模型
!llm -m deepseek-chat 'five great names for a pet ocelot'
# 第5步:运行DeepSeek编码器模型
!llm -m deepseek-coder 'how to reverse a linked list in python'
DeepSeek V3实验
在DeepSeek平台上,你可以探索网络并进行深入推理以解决复杂问题,类似于OpenAI的方法。
以下是一些提示和输出:
第一个实验
提示:生成一个孩子和足球的SVG
输出:
Here’s a simple SVG representation of a kid playing with a football. You can
copy and paste this code into an HTML file or an SVG viewer to see the
image:
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 200 200" width="200"
height="200">
<!-- Kid's head -->
<circle cx="100" cy="70" r="20" fill="#FFCC99" />
<!-- Kid's body -->
<rect x="90" y="90" width="20" height="40" fill="#4CAF50" />
<!-- Kid's arms -->
<line x1="80" y1="100" x2="60" y2="110" stroke="#4CAF50" stroke-width="5" />
<line x1="120" y1="100" x2="140" y2="110" stroke="#4CAF50" stroke-width="5" />
<!-- Kid's legs -->
<line x1="95" y1="130" x2="85" y2="160" stroke="#4CAF50" stroke-width="5" />
<line x1="105" y1="130" x2="115" y2="160" stroke="#4CAF50" stroke-width="5" />
<!-- Football -->
<ellipse cx="140" cy="140" rx="10" ry="5" fill="#8B4513" />
<line x1="135" y1="140" x2="145" y2="140" stroke="#FFFFFF" stroke-width="2" />
<line x1="140" y1="137" x2="140" y2="143" stroke="#FFFFFF" stroke-width="2" />
</svg>
Explanation:
The kid is represented with simple shapes: a circle for the head, a rectangle
for the body, and lines for the arms and legs.
The football is an ellipse with two white lines to mimic the classic football
design.
You can adjust the colours, sizes, and positions to customize the image
further.
Let me know if you'd like to enhance or modify this!
第二个实验
提示:创建经典的贪吃蛇游戏
输出:
Creating the classic Snake game involves using HTML, CSS, and JavaScript
. Below is a simple implementation:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Snake Game</title>
<style>
body {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
background-color: #000;
}
canvas {
border: 1px solid #fff;
}
</style>
</head>
<body>
<canvas id="gameCanvas" width="400" height="400"></canvas>
<script src="snake.js"></script>
</body>
</html>
JavaScript (snake.js)
const canvas = document.getElementById("gameCanvas");
const ctx = canvas.getContext("2d");
const gridSize = 20;
const tileCount = canvas.width / gridSize;
let snake = [{ x: 10, y: 10 }];
let direction = { x: 0, y: 0 };
let food = { x: Math.floor(Math.random() * tileCount), y:
Math.floor(Math.random() * tileCount) };
let score = 0;
function gameLoop() {
update();
draw();
setTimeout(gameLoop, 100);
}
function update() {
const head = { x: snake[0].x + direction.x, y: snake[0].y + direction.y };
// Check for collision with walls or itself
if (head.x < 0 || head.x >= tileCount || head.y < 0 || head.y >= tileCount
|| snake.some(segment => segment.x === head.x && segment.y === head.y)) {
resetGame();
return;
}
snake.unshift(head);
// Check if snake eats the food
if (head.x === food.x && head.y === food.y) {
score++;
food = { x: Math.floor(Math.random() * tileCount), y:
Math.floor(Math.random() * tileCount) };
} else {
snake.pop();
}
}
function draw() {
// Clear the canvas
ctx.fillStyle = "#000";
ctx.fillRect(0, 0, canvas.width, canvas.height);
// Draw the snake
ctx.fillStyle = "#0F0";
snake.forEach(segment => ctx.fillRect(segment.x * gridSize, segment.y *
gridSize, gridSize, gridSize));
// Draw the food
ctx.fillStyle = "#F00";
ctx.fillRect(food.x * gridSize, food.y * gridSize, gridSize, gridSize);
// Draw the score
ctx.fillStyle = "#FFF";
ctx.font = "20px Arial";
ctx.fillText("Score: " + score, 10, 30);
}
function resetGame() {
snake = [{ x: 10, y: 10 }];
direction = { x: 0, y: 0 };
score = 0;
food = { x: Math.floor(Math.random() * tileCount), y:
Math.floor(Math.random() * tileCount) };
}
window.addEventListener("keydown", e => {
switch (e.key) {
case "ArrowUp":
if (direction.y === 0) direction = { x: 0, y: -1 };
break;
case "ArrowDown":
if (direction.y === 0) direction = { x: 0, y: 1 };
break;
case "ArrowLeft":
if (direction.x === 0) direction = { x: -1, y: 0 };
break;
case "ArrowRight":
if (direction.x === 0) direction = { x: 1, y: 0 };
break;
}
});
gameLoop();
How It Works:
Canvas Setup: The game is drawn on a <canvas> element.
Snake Movement: The snake is represented as an array of segments. The head
moves based on the direction, and the tail follows.
Food: A random position is generated for the food. When the snake eats the
food, it grows, and the score increases.
Collision Detection: The game checks if the snake collides with the walls or
itself, and resets if it does.
Controls: Arrow keys are used to change the snake's direction.
How to Run:
Save the HTML and JavaScript code into files (index.html and snake.js).
Open the index.html file in a browser.
Use the arrow keys to control the snake.
Let me know if you'd like to add more features or improve the game!
第三个实验
提示:如何克隆git仓库?
‼ DeepSeek聊天由V3提供动力,非常强大 ‼
这里有一个带有AI公司标志的MVP小行星游戏。完全用它在几分钟内构建!
Sonnet 3.5不再是王者👑了🤷♂️
Anthropic轮到你了!
🧵在评论中创建的工件pic.twitter.com/FCMZTb52fQ
— Ivan Fioravanti ᯅ (@ivanfioravanti) 2024年12月25日
所有输出都达到了标准,输出速度也相当令人印象深刻。此外,DeepSeek允许你向模型提出推理问题,使其成为一个多功能和高效的工具,用于复杂问题解决和深入分析。
我们将在即将发布的文章中提供这个模型的全面比较!
结论
DeepSeek V3作为大规模AI模型演变中的一个里程碑,结合了前所未有的规模和无与伦比的效率。凭借其创新的架构、成本效益的训练和令人印象深刻的6850亿参数,DeepSeek V3重新定义了AI领域的可能性。该模型在多样化的基准测试中表现出色,超越了开源和封闭源竞争对手,突出了其非凡的能力。
DeepSeek V3不仅在编码、推理和数学问题解决等任务中提供了最先进的性能,而且通过其开源可用性,使尖端AI民主化。开发者、研究人员和企业都可以利用其巨大的力量,得到一个促进创新和合作的宽松许可证的支持。
通过仅以550万美元的训练成本实现卓越成果,DeepSeek V3证明了可扩展性和效率可以共存,为AI开发的未来树立了新的标准。这次发布不仅是对DeepSeek的巨大飞跃,也是对整个AI社区的巨大飞跃,为机器学习、自然语言处理等领域的突破铺平了道路。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 17
17 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)