解读DeepSeekMath中的RL策略!GRPO:改进PPO增强推理能力
作者:Plunck原文:https://zhuanlan.zhihu.com/p/15677409107最近非常火爆,阅读技术报告之后感觉干货满满。这一代模型是DeepSeek之前多种技术的集大成者,包括DeepSeekv2[Arxiv]中使用过的注意力的改进。
作者:Plunck
原文:https://zhuanlan.zhihu.com/p/15677409107
最近DeepSeekv3非常火爆,阅读技术报告之后感觉干货满满。这一代模型是DeepSeek之前多种技术的集大成者,包括DeepSeekv2[Arxiv]中使用过的注意力的改进MLA(Multi-head Latent Attention)、FFN的MoE架构DeepSeekMoe,还提出了MoE架构的无需辅助损失函数(Auxiliary-loss-free)的专家负载均衡策略以及预测多个token(muliti-token prediction, MTP)的训练目标,在训练方面使用FP8混合精度训练(FP8 training)和降低流水线空泡的DualPipe调度算法,实现了千万美元训练世界一流模型的惊喜。读完以后觉得确实牛,但是我们做小生意的,用不到这些屠龙刀。
所幸在技术报告的post-training这一节看到DeepSeekv3的强化学习阶段没有用PPO(Proximal Policy Optimization),而是用到了DeepSeekMath[Arxiv]中提出的一种PPO的改进版本GRPO(Group Relative Policy Optimization),于是读了DeepSeekMath这篇论文,这篇文章写得也很好,实验比较丰富,提出了很多有意思的观点,值得认真学习。
Paper:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Abs:https://arxiv.org/pdf/2402.03300
代码:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdfGRPO(Group Relative Policy Optimization)是PPO的直接改进。
在人工智能发展历程中,数学推理一直是一个极具挑战性的领域。这不仅因为数学本身的抽象性和严谨性,更在于它要求模型具备复杂的逻辑推理能力和结构化思维。2024年2月发布的DeepSeek-Math是基于DeepSeek-Coder-Base-v1.5 7B继续预训练的模型,在继续预训练中使用了120B数学相关的token。在MATH基准测试中,它不借助任何外部工具就达到51.7%的成绩,接近Gemini-Ultra和GPT-4的水平。这一成就来源于两个方面的创新:
-
• 数据挖掘:研究团队开发了一个精心设计的数据筛选流程,充分挖掘了公开网络数据
-
• 强化学习:他们提出了群组相对策略优化(GRPO)算法,这是对经典PPO算法的创新改进,不仅增强了模型的数学推理能力,还优化了内存使用效率
数据挖掘
这一部分不是我们关注的重点,在此简要介绍一下。DeepSeekMath 的数据挖掘方法的核心思想是:从海量的 Common Crawl 数据中,迭代地、系统性地挖掘高质量的数学相关文本,并进行严格的去重和污染过滤。这种方法不仅适用于数学领域,也具有一定的通用性,可以应用于其他领域的数据挖掘。
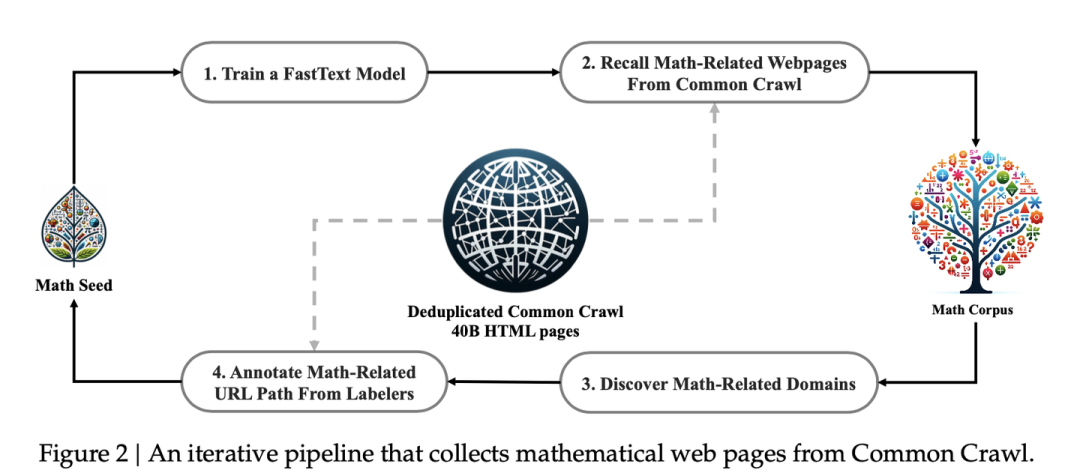
主要步骤:
1.种子语料 (Seed Corpus):选择高质量的数学文本集合作为初始种子。DeepSeekMath选择了OpenWebMath 作为种子语料,因为它是一个高质量的数学网页文本集合。
2.训练 FastText 模型:使用种子语料训练一个 FastText 模型。FastText 模型用于快速识别与种子语料相似的数学网页。
3.从 Common Crawl 中召回数学网页:使用训练好的 FastText 模型,从去重后的 Common Crawl 数据中召回数学相关的网页。使用基于 URL 的去重和近似去重技术,将 Common Crawl 数据量减少到 400 亿 HTML 网页。根据 FastText 模型预测的分数对召回的网页进行排序,并保留排名靠前的网页。通过预训练实验评估保留不同数据量(40B, 80B, 120B, 160B tokens)的效果,最终选择保留 40B tokens 作为第一轮迭代的数据。
4.迭代式数据收集:识别新的数学网页来源:将 Common Crawl 数据按照域名进行划分,计算每个域名下被收集的网页比例。人工标注:将收集比例超过 10% 的域名标记为数学相关域名,并人工标注这些域名下数学内容相关的 URL 路径。扩充种子语料:将这些 URL 路径下未被收集的网页添加到种子语料中,从而扩充种子语料的多样性。重复步骤 2-4:使用扩充后的种子语料重新训练 FastText 模型,并重复召回、筛选和扩充的过程。迭代终止:经过四轮迭代,收集到 3550 万个数学网页,共计 120B tokens。在第四轮迭代时,发现 98% 的数据已经在第三轮迭代中被收集,因此停止数据收集。
最终收集的数据集DeepSeekMath Corpus质量比较高,相较于其它数学相关的数据集MathPile、OpenWebMath和Proof-Pile-2,在此数据集上训练相同token数时,模型在所有基准上的提升速度都比较快,最终效果也更好。
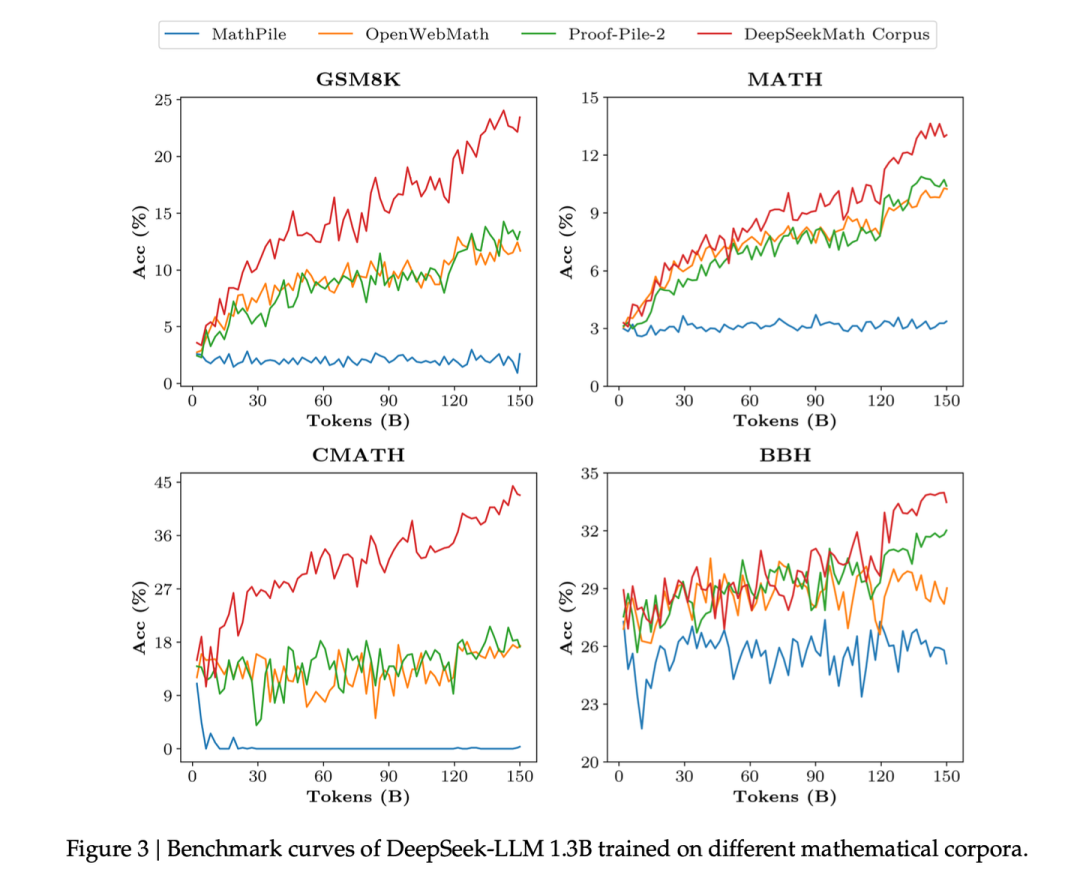
DeepSeekMath Corpus的学习速率更陡峭
下面我们重点介绍论文提出的新的强化学习算法:GRPO。
一、GRPO
1、PPO的缺点
在SFT阶段后使用强化学习算法对LLM进行继续训练已经被证明对模型的数学能力提升非常有效。PPO 是一种 Actor-Critic 架构的强化学习算法,它被广泛应用于大型语言模型 (LLM) 的强化学习微调阶段。PPO 的核心思想是在保证策略更新幅度的前提下,尽可能地最大化策略的性能。它通过引入“信任区域”的概念,限制策略更新的幅度,从而避免策略更新过大导致性能下降。
具体来说,PPO通过最大化下面这个代理目标来优化模型:
其中, 和分别是当前和旧的策略模型, 是问题数据集 中的问题,是旧策略 生成的输出结果,是裁剪超参数,用于限制策略更新的幅度,是使用广义优势估计 (GAE) 方法,基于奖励和一个学习到的价值函数 进行计算得到的优势(Advantage),用于评估当前动作相对于平均水平的优劣。
在PPO中,价值函数 需要与策略模型一起训练,以正确评估策略模型变化过程中的状态价值变化,减轻奖励模型的过度优化。奖励函数的标准做法是OpenAI在 InstructGPT一文中采用的由奖励模型给出的奖励和 KL 散度惩罚项组成:,其中 是一个奖励模型, 是参考模型,也就是强化学习初始的SFT模型。
从PPO的优化过程分析,其存在如下缺点:
1.需要训练一个与策略模型大小相当的价值模型,这带来了巨大的内存和计算负担;
2.在 LLM 的上下文中,通常只有最后一个 token 会被奖励模型打分,这使得训练一个在每个 token 上都准确的价值函数变得困难。
2、推导GRPO
2.1 优化目标
为了解决上述问题,文章提出了Group Relative Policy Optimization (GRPO)。GRPO 避免了像 PPO 那样使用额外的价值函数近似,而是使用同一问题下多个采样输出的平均奖励作为基线。
对于每个问题 ,GRPO 从旧策略 中采样一组输出 。然后,通过最大化以下目标函数来优化策略模型:
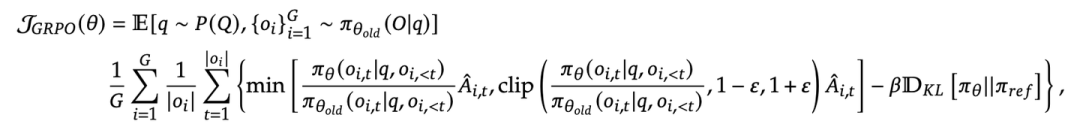
GRPO优化目标
: 表示对问题 从问题分布 P(Q) 中采样,以及输出组 从旧策略 中采样的期望。
: 当前策略模型在给定问题 和输出的之前 的条件下,生成当前 的概率。
: 旧策略模型在给定问题 q 和输出的之前 的条件下,生成当前的概率。
: 基于组内相对奖励计算的优势函数,将在后续2.2部分详细介绍。
: 裁剪超参数,用于限制策略更新的幅度。
: KL 散度惩罚项的系数。
: 当前策略 和参考策略之间的 KL 散度。
其中有一个细节是使用无偏estimator来计算,目的是减少KL散度计算的高方差。
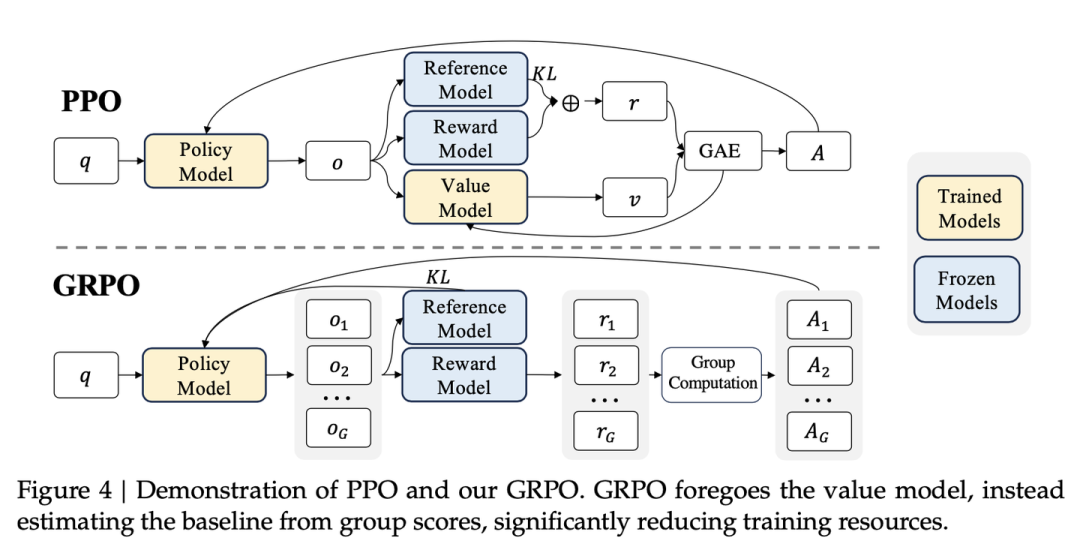
PPO vs GRPO
2.2 优势函数计算
GRPO没有Critic模型,利用组内相对奖励计算优势。对于每个问题,GRPO 从旧策略 中采样一组输出 ,使用奖励模型对这些输出进行评分,得到相应的奖励,通过减去组平均值并除以组标准差来归一化这些奖励,最终 。
以上这种方法使用的是一般的奖励模型,只对整个结果给出一个奖励分数,这种方式称为结果监督(Outcome Supervision),我们之前在介绍PPO的文章提到过,对于单个动作使用整个轨迹的分数来优化其实并不太合理,对于数学任务尤其是如此,数学任务常常需要多步连续的推导,如果某个过程开始错了,后面的结果往往也对不了,如果存在过程监督的方法,我们可以让模型学会去得到尽可能多的过程分,这样得到正确结果的概率也会增加。
针对仅在输出末尾提供奖励的结果监督在复杂数学任务中可能不足的问题,GRPO 引入了过程监督 (Process Supervision)。过程监督在每个推理步骤的末尾提供奖励,从而更细粒度地指导策略学习。
对于每个问题 q 和一组采样输出 ,使用过程奖励模型对每个输出的每个推理步骤进行评分,得到步骤奖励 。其中表示第步的结束 token 索引,是第i个输出的思维链的总步骤数。以下是一个例子。
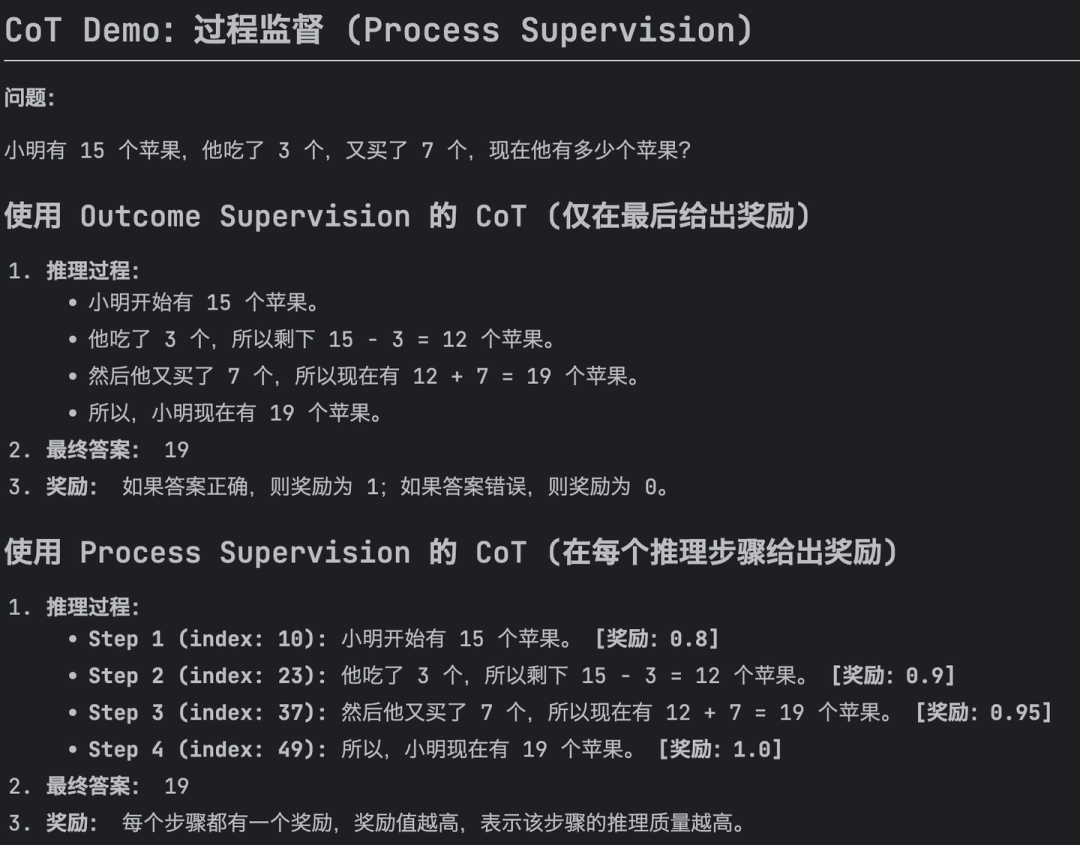
Process Supervision演示
得到过程监督的奖励之后,通过减去组平均值并除以组标准差来归一化这些奖励,最后每个 token 的优势函数 计算为该 token 之后所有步骤的奖励之和。计算过程如下:
2.3 Reward model训练数据构建
之前提到的过程监督需要用到过程奖励模型,我们还没有介绍这个过程奖励模型是用什么数据训练的。
DeepSeekMath模型的SFT阶段构建了一个数学教学调优数据集,涵盖了来自不同数学领域和不同复杂程度的英语和汉语问题,样本总数为776K,每个样本都是包含思维链的question-solution对。RL阶段所使用的数据抽取自SFT阶段数据的questions,共144K个问题。
对这么多问题标注问题的解法CoT是非常耗时耗力的——不仅要对结果打分,还要对思维链的每一个step赋分。论文里使用了一种自动化的数据标注方法,这种自动标注方法来自MATH-SHEPHERD。
该方法的核心是将一个推理步骤的质量定义为“其推导出正确答案的潜力”,并通过“补全”和“估计”两个步骤来实现自动标注。
1>补全
对于一个给定的推理步骤,我们使用一个“补全器”(completer)从这个步骤开始,完成 N 个后续的推理过程。这 N 个完成的推理过程可以表示为 。其中,表示第 j 个完成推理过程的后续步骤,表示第 j 个完成推理过程的解码答案,表示第 j 个完成推理过程的总步骤数。通过这些完成的推理过程,我们可以评估步骤 的潜力。
2>估计
基于补全步骤得到的N个完成推理过程的答案,我们来估计步骤 的质量,有以下两种方式。
硬估计 (Hard Estimation, HE):只要存在一个完成推理过程的答案 等于正确答案 ,我们就认为步骤 是好的,并将其标签设置为 1。否则,标签设置为 0。
软估计 (Soft Estimation, SE):我们将步骤的质量定义为,完成推理过程的答案等于正确答案 的频率。
这种自动标注方法的核心在于,它能够自动生成推理步骤的标签,从而避免了人工标注的成本。通过“补全”和“估计”两个步骤,我们可以量化和估计推理步骤的质量,并构建高质量的 PRM 训练数据集。

有了这些数据就可以像训练普通的带valuehead的结果奖励模型一样,训练过程奖励模型(PRM)。
2.4 迭代RL
随着强化学习训练过程的推进,策略发生变化,旧的奖励模型可能不足以监督当前的策略模型。因此,论文探索了使用GRPO的迭代RL。在迭代GRPO过程中,根据策略模型的采样结果为奖励模型生成新的训练集,并使用包含10%历史数据的重放机制不断训练旧的奖励模型。在每个iteration中,将参考模型设置为策略模型,并用新的奖励模型不断训练策略模型。至此GRPO的完整过程已经讲解完毕,算法全流程如下所示。

Iterative RL with GRPO
总结GRPO 的优点:
1.无需额外的价值函数:GRPO 使用组内平均奖励作为基线,避免了训练额外的价值函数,从而减少了内存和计算负担。
2.与奖励模型的比较性质对齐:GRPO 使用组内相对奖励计算优势函数,这与奖励模型通常在同一问题的不同输出之间进行比较的性质相符。
3.KL惩罚在损失函数中:GRPO 直接将训练策略 和参考策略 之间的 KL 散度添加到损失中,而不是像 PPO 那样在奖励中添加 KL 惩罚项,从而避免了复杂化的计算。
二、一种理解LLM多种学习方法的统一范式
这篇论文最有意思的一点是提供了一个统一的范式来分析不同的训练方法,如SFT、RFT、DPO、PPO、GRPO,并进一步进行实验来探索影响学习的因素。通常,训练中模型参数 的梯度可以写成:
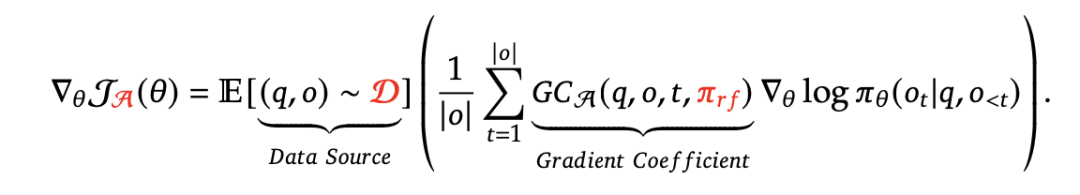
其中有三个关键组成部分:
1> 数据源 :它决定了训练数据;
2> 奖励函数(reward function):它是训练过程奖励信号的来源;
3> 梯度计算算法 :它将训练数据和奖励信号处理为梯度系数 GC ,该系数决定了数据的惩罚或强化幅度。
下面,我们从这三个角度来理解一下各种学习方法。
SFT(Supervised Fine-tuning)
1、数据源:用于SFT的数据集,
2、奖励函数:SFT的数据都是人工挑选的,可以视为一种奖励规则,对所有数据都是一样的正向奖励。
3、梯度计算算法:
SFT的优化目标是
目标函数的梯度是
即 恒等于1。
RFT(Rejection Sampling Fine-tuning)
拒绝采样微调首先针对每个问题从经过SFT的LLM中采样多个输出,然后利用具有正确答案的采样输出对大型语言模型进行训练。
1、数据源:采样 的回答, ,
2、奖励函数:基于规则,即正确与否。
3、梯度计算算法:
RFT的优化目标是
目标函数的梯度是
即
DPO(Direct Preference Optimization)
DPO是一种简单的不需要reward model的强化学习算法,通过使用pair-wise的DPO loss对SFT模型采样的增强输出进行微调。
1、数据源:采样自 的回答,包含正负样本,,
2、奖励函数:对于数学题,基于规则,即正确与否
3、梯度计算算法:
DPO的优化目标是
优化目标的梯度是
即
上述求导过程有一点点复杂,具体计算过程如下:
令:
R(o) = (1/|o|) * sum(log(π_θ(o_t|q,o_<t)) - log(π_ref(o_t|q,o_<t)))
即每个序列的对数似然比的平均值
则目标函数可以写为:
J_DPO(θ) = E[logsigmoid(β(R(o+) - R(o-)))]
1. 首先,logsigmoid的导数:
d/dx(logsigmoid(x)) = sigmoid(-x)
2. 链式法则:
∇_θ J_DPO = E[sigmoid(-β(R(o+) - R(o-))) * β * ∇_θ(R(o+) - R(o-))]
3. 对R(o)求导:
∇_θ R(o) = (1/|o|) * sum(∇_θ log(π_θ(o_t|q,o_<t)))
4. 最终梯度:
∇_θ J_DPO = E[sigmoid(-β(R(o+) - R(o-))) * β *
((1/|o+|) * sum(∇_θ log(π_θ(o_t+|q,o_<t+))) -
(1/|o-|) * sum(∇_θ log(π_θ(o_t-|q,o_<t-))))]Online RFT(Online Rejection Sampling Fine-tuning)
Online RFT使用SFT模型 初始化策略模型 ,它和RFT的唯一区别是通过使用从实时策略模型 中采样的增强输出进行微调来对其进行优化。
1、数据源:采样自 的回答, ,
2、奖励函数:同RFT,基于规则 ,即正确与否。
3、梯度计算算法:
Online RFT的优化目标是
优化目标的梯度是
即
PPO(Proximal Policy Optimization)
PPO也是从实时策略模型 采样输出然后用这些数据优化模型。
1、数据源:采样自 的回答, ,
2、奖励函数:由reward model给出。
3、梯度计算算法:
PPO的优化目标是
有clip太复杂了,简化形式是
目标函数的梯度是
即 ,是使用GAE计算的优势,计算要用到奖励 和Critic模型。
GRPO(Group Relative Policy Optimization)
GRPO也是从实时策略模型 采样输出然后用这些数据优化模型,但是采样的数据是一组。
1、数据源:采样自 的回答, ,
2、奖励函数:由reward model给出。
3、梯度计算算法:
GRPO的优化目标是
目标函数的梯度是
即
以上GRPO的梯度和梯度系数计算结果和论文附录不一样,如果是我计算错误敬请指正。
三、实验结果
这篇文章提出了很多有意思的实验结果,在这里列一些。
1、数学语料的训练增强了模型的自然语言理解能力,说明数学训练对语言理解和推理有积极影响。
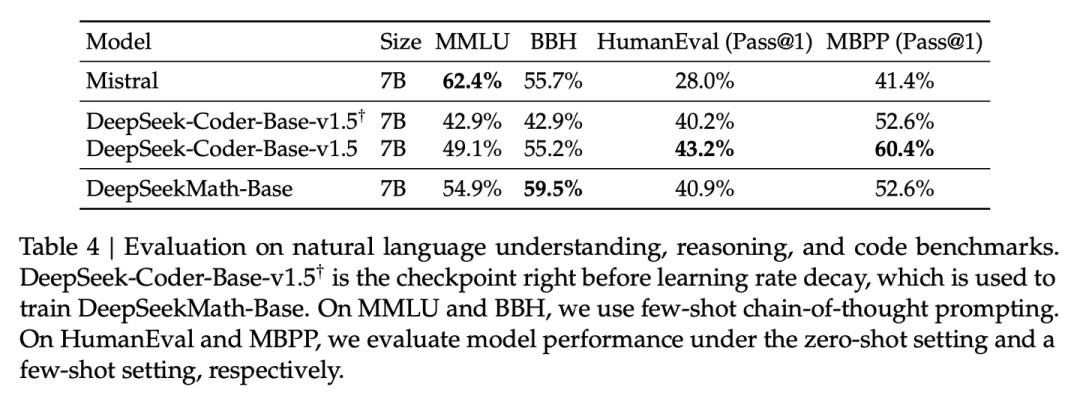
但是也可能是原本的coder v1.5的checkpoint没有在语言理解任务上充分训练,存疑。
2、代码训练对数学推理能力有积极影响,不管是code-math两阶段还是数据混合单阶段训练,都得到了正面收益。
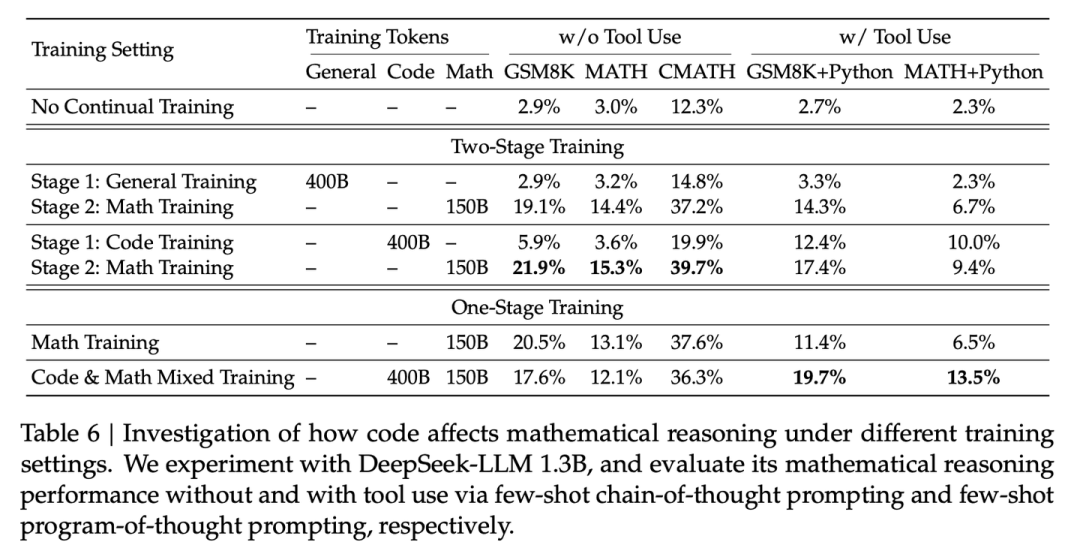
3、与预想结果不同,Arxiv paper作为训练数据没有增强模型的数学能力。
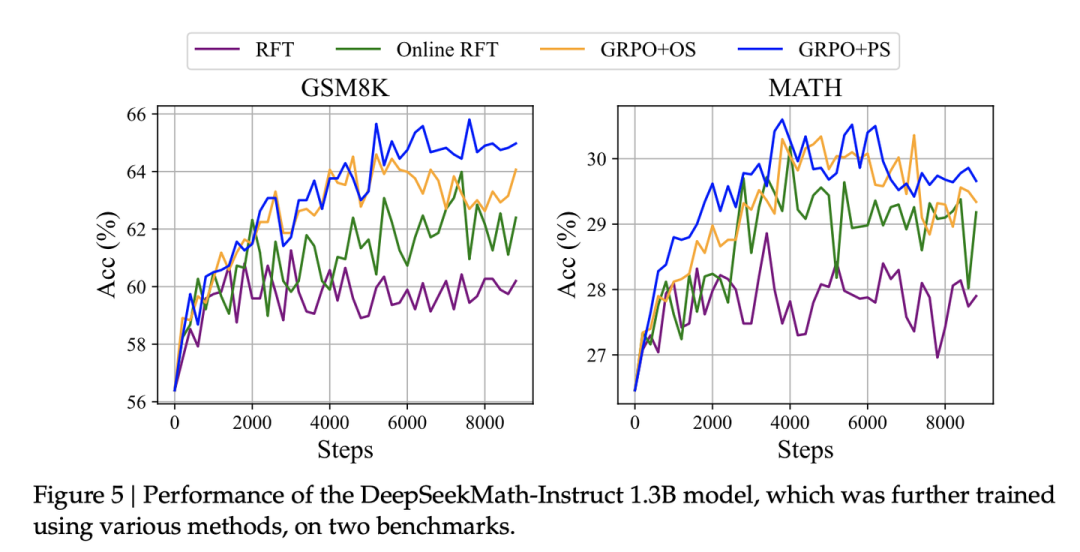
4、Online RFT比RFT效果好,这也符合直觉,毕竟策略模型在训练过程发生了偏移。GRPO过程监督比GRPO结果监督效果好。
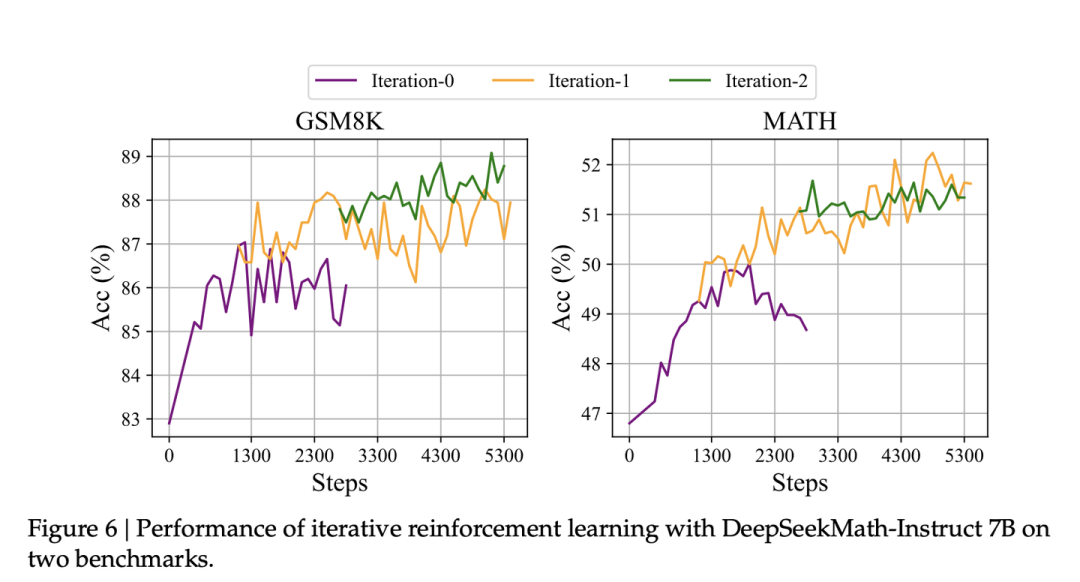
5、在一个iteration结束重新训练reward model对于模型能力有显著改善。
6、强化学习增强了模型输出正确答案的概率,但是没有增强模型的能力
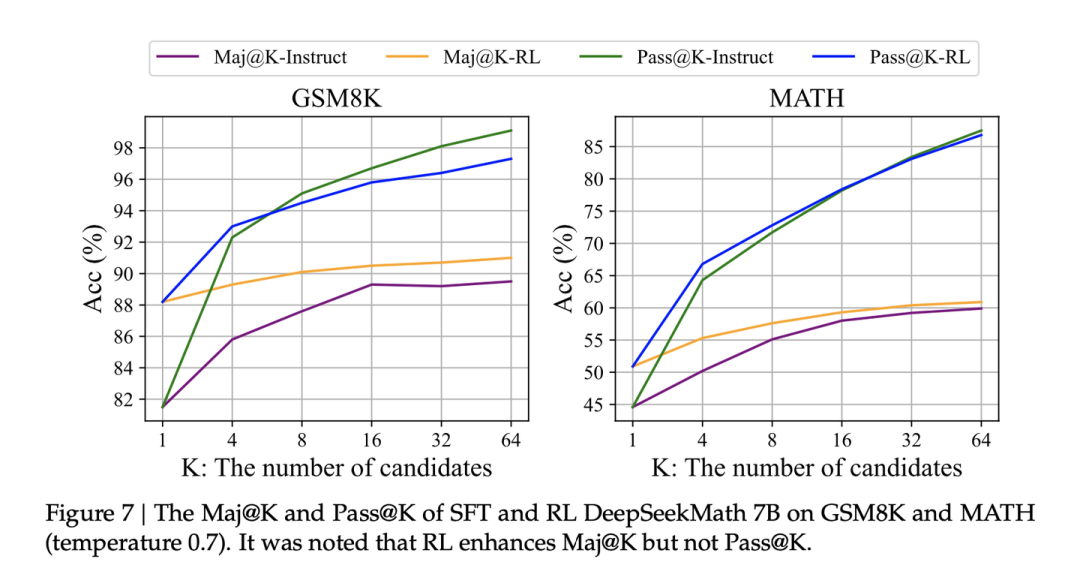
从实验结果观察到,RL增强了topK中正确答案的概率,但是在K次采样中至少有一次正确的概率没有显著提升,说明模型能力没有提升。但是我认为这个结论不太solid,因为其在RL阶段使用了SFT的数据,reward模型也是从SFT的采样结果里训练出来的,用这种训练方法去要求模型解本来不会解的题本来就牵强。
最后从论文的结论部分总结一下这篇论文:
论文核心贡献与发现:
1、DeepSeekMath 模型:
-
• 论文提出了 DeepSeekMath 模型,该模型在竞争级别的 MATH 基准测试中超越了所有开源模型,并接近了闭源模型的性能。
-
• DeepSeekMath 基于 DeepSeek-Coder-v1.5 7B 初始化,并进行了 500B tokens 的持续训练,其中 120B tokens 来自 Common Crawl 的数学数据。
2、高质量数学数据来源:
-
• 消融研究表明,网页(Common Crawl)提供了高质量数学数据的巨大潜力。
-
• arXiv 数据集对数学能力提升的益处可能不如预期。
3、GRPO 算法:
-
• 论文引入了 Group Relative Policy Optimization (GRPO) 算法,它是近端策略优化 (PPO) 的一种变体。
-
• GRPO 算法在内存消耗较少的情况下,显著提高了模型的数学推理能力。
-
• 实验结果表明,即使 DeepSeekMath-Instruct 7B 在基准测试中取得了高分,GRPO 仍然有效。
4、统一的理解框架:
-
• 论文提供了一个统一的框架来理解一系列方法,并总结了大型语言模型 (LLM) 强化学习的潜在方向。
论文的局限性与未来方向:
1、几何和定理证明能力:
-
• DeepSeekMath 在定量推理基准测试中表现出色,但在几何和定理证明方面的能力相对弱于闭源模型。
-
• 模型在处理三角形和椭圆相关问题时存在困难,这可能表明预训练和微调过程中存在数据选择偏差。
2、少样本学习能力:
-
• 受模型规模限制,DeepSeekMath 的少样本学习能力不如 GPT-4。
-
• GPT-4 可以通过少样本输入提高性能,而 DeepSeekMath 在零样本和少样本评估中表现相似。
3、未来工作:
-
• 改进数据选择流程,构建更高质量的预训练语料库。
-
• 探索更有效的 LLM 强化学习的潜在方向(论文 5.2.3 节中总结)。
期待在工作中使用GRPO获得收益。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)