DeepSeek V3 vs R1:到底哪个更适合你?全面对比来袭
V3 vs R1:如果你需要的是一个通用性强、知识面广的 AI 模型,V3 更适合你;而如果你需要的是具备强大推理能力和自我学习能力的 AI 模型,R1 则是你的不二之选。蒸馏小模型:如果你预算有限,或者需要在资源受限的环境中部署 AI,蒸馏后的小模型无疑是最佳选择。
最近都是 DeepSeek 相关文章,但 V3 与 R1 是究竟怎么回事?我整理了相关文档,一起来学习一下吧。
一、DeepSeek V3:AI 界的巨无霸,用“大力”铸就奇迹
DeepSeek V3 是一款震撼登场的超级 AI 模型,其拥有 6710 亿个参数,堪称一个超级复杂的“智慧大脑”。它的性能表现已然能够与全球顶尖的 AI 模型 GPT-4 和 Claude 3.5 平起平坐,稳稳站在了世界级 AI 大模型的阵营之中。
1、V3 的训练秘籍:以“大力”成就奇迹
V3 的训练方式颇有一种“大力出奇迹”的豪迈。它不依赖于复杂精巧的思考路径,而是凭借海量的数据和充沛的计算资源来实现性能的飞跃。这就好比你为了掌握一项技能而不断反复练习,V3 亦是通过海量数据的持续训练,逐渐变得愈发聪慧。
2、私有化部署:成本的“高山”
若想将 V3 纳入自家麾下进行私有化部署,那可得做好“掏空钱包”的准备。V3 需要 1370GB 的显存,按照 70% 的显存利用率来计算,你至少需要配备 32 张 A100 显卡(每张 80GB),起步价大致在 200 到 300 万人民币之间。
3、如何选择:
- 适用场景:当面对极其复杂的任务,例如大规模数据分析、自然语言处理,或者需要超高精度 AI 模型的关键场景时,V3 绝对是你的不二之选。
- 预算考量:鉴于其高昂的部署成本,V3 更适合大型企业或研究机构来驾驭。若你的预算捉襟见肘,不妨考虑云端服务,按需付费,灵活又经济。
二、DeepSeek R1:AI 的顿悟时刻,开启智能新纪元
DeepSeek R1 无疑是 AI 领域的一次重大突破,它凭借“强化学习”这把钥匙,开启了 AI 的全新世界。强化学习是一种让 AI 在不断试错中学习的机制,就如同你通过一次次尝试来学会骑自行车一样。R1 完全依靠强化学习,无需人类手把手教导,便能自主习得强大的推理能力。
强化学习:AI 的成长法则
强化学习是一种让 AI 通过与环境互动来学习的模式。AI 通过尝试各种行动,并依据反馈(奖励或惩罚)来调整自身策略,最终学会如何最大化奖励。这就好比你在玩电子游戏时,通过不断尝试来探寻通关的最优策略。
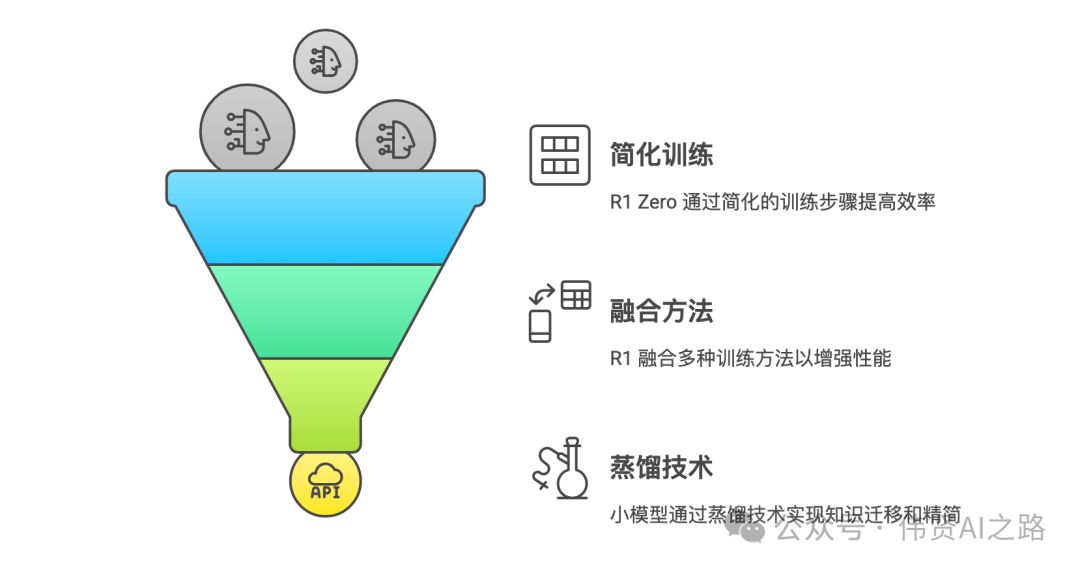
1、DeepSeek R1 Zero:以简洁铸就强大
DeepSeek R1 Zero 提出了一种极为简洁的强化学习方法,不仅效果出色,还大幅节省了计算资源。以往的 AI 模型通常要经历多个复杂繁琐的训练步骤,而 R1 Zero 仅靠强化学习便能达成同等效果。
R1 Zero 的训练目标:培养 AI 的自我思考能力
R1 Zero 的核心目标是让 AI 学会自我思考与推理,使其更接近人类的思维模式。它通过面向结果的强化学习,促使 AI 在解决问题时能够进行深度思考。R1 Zero 的奖励系统主要依据两个标准:准确率和格式。
2、DeepSeek R1:融合多元训练方法,提升性能
DeepSeek R1 是在 R1 Zero 的基础上,融合了其他多种训练方法的成果。它借助冷启动、语言一致性约束、拒绝采样以及 SFT(监督微调)等技术,进一步提升了模型的性能。
全局强化学习:确保模型的可用性与安全性
R1 还通过全局强化学习来提升模型的可用性和无害性,确保模型不会产生无意义的废话或极端言论。这就好比你在训练一只宠物,既要让它学会各种技能,又要确保它不会做出危险行为。
如何选择:
- 适用场景:如果你需要 AI 具备强大的推理能力和自我学习能力,例如在复杂的决策支持系统、自动化客服,或者需要高度智能化的应用场景中,R1 绝对是你的理想选择。
- 预算考量:虽然 R1 的部署成本相对较高,但如果你追求的是高质量的推理能力,那么这笔投资绝对是物有所值。对于预算有限的中小企业,可以考虑使用 R1 的云端服务,既能满足需求又经济实惠。
3、DeepSeek R1 蒸馏小模型:知识压缩的魔法,让高效触手可及
蒸馏技术宛如一种“知识压缩”的魔法,它能够将庞大的 AI 模型(例如千亿参数的 DeepSeek-R1)的推理能力,精准提炼并迁移到更轻量的小模型之中。这种技术不仅打破了“模型越大越聪明”的传统认知,还让企业能够以更低的成本享受到 AI 的高性能。
知识迁移:自主学习与模式继承
蒸馏技术的核心在于让模型自主学习,筛选并生成高质量的训练样本。小模型通过微调参数,直接学习 R1 的复杂推理模式。这就好比你从老师那里学到解题技巧后,能够独立解决类似的问题。
效率革命:参数精简的奇迹
传统大模型需要激活千亿参数,而经过蒸馏的小模型仅需 1.5B 到 70B 参数,内存占用减少了 10 倍以上。这就好比你把一本厚重的百科全书压缩成一本薄薄的小册子,既节省了空间,又保留了核心知识。
如何选择:
- 适用场景:如果你需要 AI 具备较强的推理能力,但预算有限,或者需要在资源受限的环境(如移动设备、嵌入式系统)中部署 AI,蒸馏后的小模型无疑是绝佳之选。
- 预算考量:蒸馏后的小模型部署成本大幅降低,非常适合中小企业和个人开发者使用。你可以根据具体需求,灵活选择不同规模的模型,参数范围从 1.5B 到 70B 不等。
三、总结:V3 与 R1,各领风骚
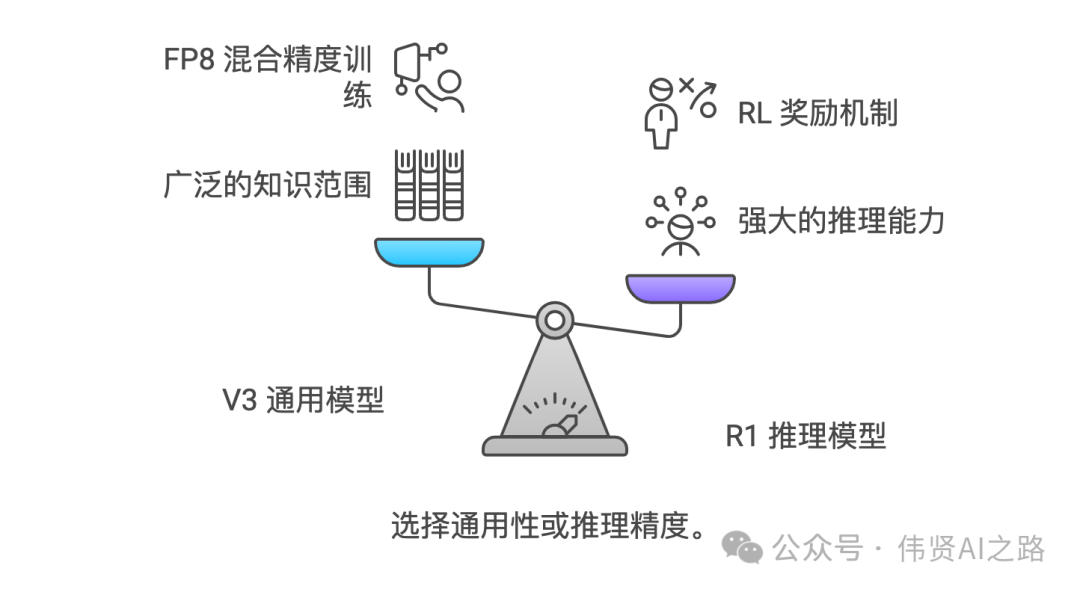
V3 的通用之道:数据海洋与混合精度训练
V3 通过 14.8 万亿的 token 数据以及 FP8 混合精度训练,实现了知识广度的指数级扩展。这就好比你通过阅读海量书籍来拓宽自己的知识面一样。
R1 的专精之术:推理链拆解与 RL 奖励机制
R1 则通过推理链拆解技术,将复杂问题转化为可训练的原子步骤,配合 RL 奖励机制塑造严谨的逻辑思维。这就好比你把一个复杂的问题拆解成多个小步骤,逐步解决,最终找到答案。
如何选择:
- V3 vs R1:如果你需要的是一个通用性强、知识面广的 AI 模型,V3 更适合你;而如果你需要的是具备强大推理能力和自我学习能力的 AI 模型,R1 则是你的不二之选。
- 蒸馏小模型:如果你预算有限,或者需要在资源受限的环境中部署 AI,蒸馏后的小模型无疑是最佳选择。
DeepSeek V3 和 R1 的横空出世,标志着 AI 大模型训练正从“暴力计算”迈向“精准智能”的全新范式。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)