【NLP】「科学推理」基准榜单出炉!DeepSeek-R1 登顶,推理等级7级,o1紧随其后...
SuperCLUE-Science中文大模型「科学推理」测评报告发布,皆在深入评估大模型在研究生级别的科学推理能力。该测评不仅关注模型的最终答案,还重点考察其解题过程。测评内容体系涵盖了 3 大维度,即物理、化学以及生物,每个维度之下还会有数个子维度,全面考察大模型在科学推理任务的综合表现。本次我们测评了国内外 10 个代表性大模型的科学推理能力,以下为详细测评报告。科学推理测评摘要测评要点1:.

SuperCLUE-Science中文大模型「科学推理」测评报告发布,皆在深入评估大模型在研究生级别的科学推理能力。该测评不仅关注模型的最终答案,还重点考察其解题过程。测评内容体系涵盖了 3 大维度,即物理、化学以及生物,每个维度之下还会有数个子维度,全面考察大模型在科学推理任务的综合表现。
本次我们测评了国内外 10 个代表性大模型的科学推理能力,以下为详细测评报告。
![]()
科学推理测评摘要
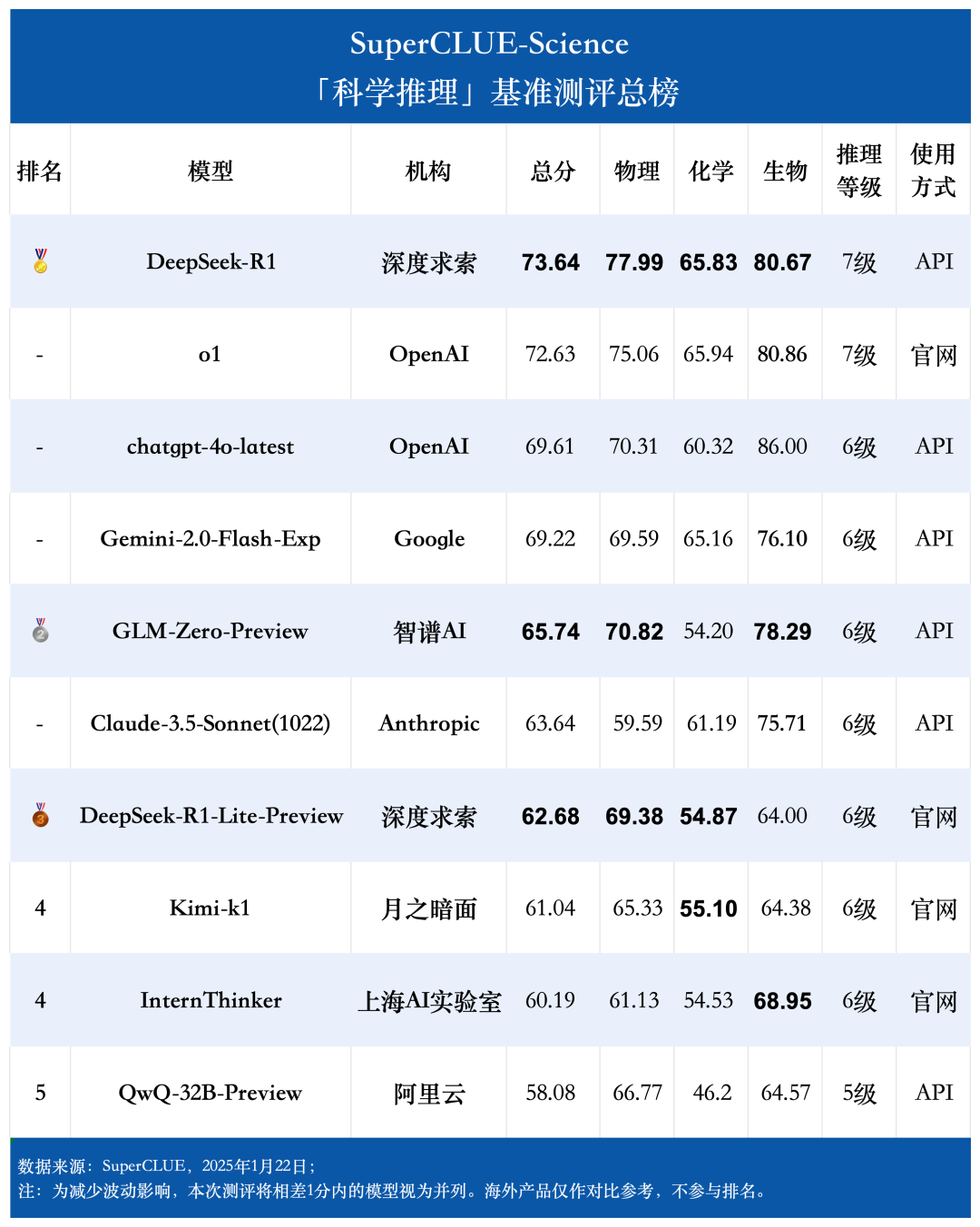
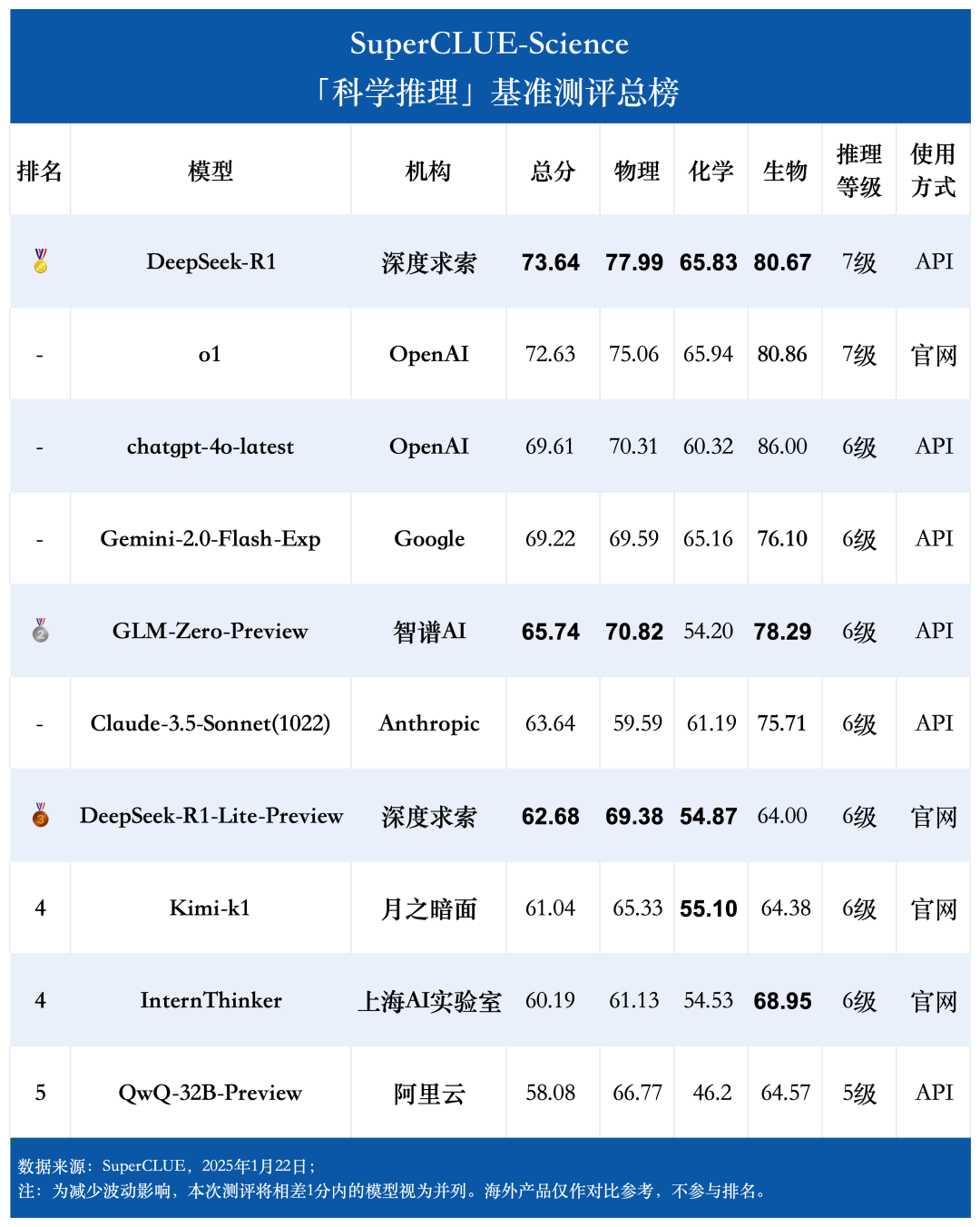
测评要点1:在科学推理综合能力上,国内模型 DeepSeek-R1 实现了对世界顶尖模型 o1 的超越
在本次测评中,DeepSeek-R1 以优异成绩获得 73.64 分,领先所有参评模型,成为首个超越世界顶尖模型 o1 的国内推理模型,在研究生级别的科学题中表现出色,展现了出色的思维能力和回答质量,在物理、化学、生物 3 大学科对应的 16 个学科子域上展现出卓越的全面表现。
测评要点2:国内推理大模型在物理学科方面表现出色,在化学与生物学科仍有进步空间
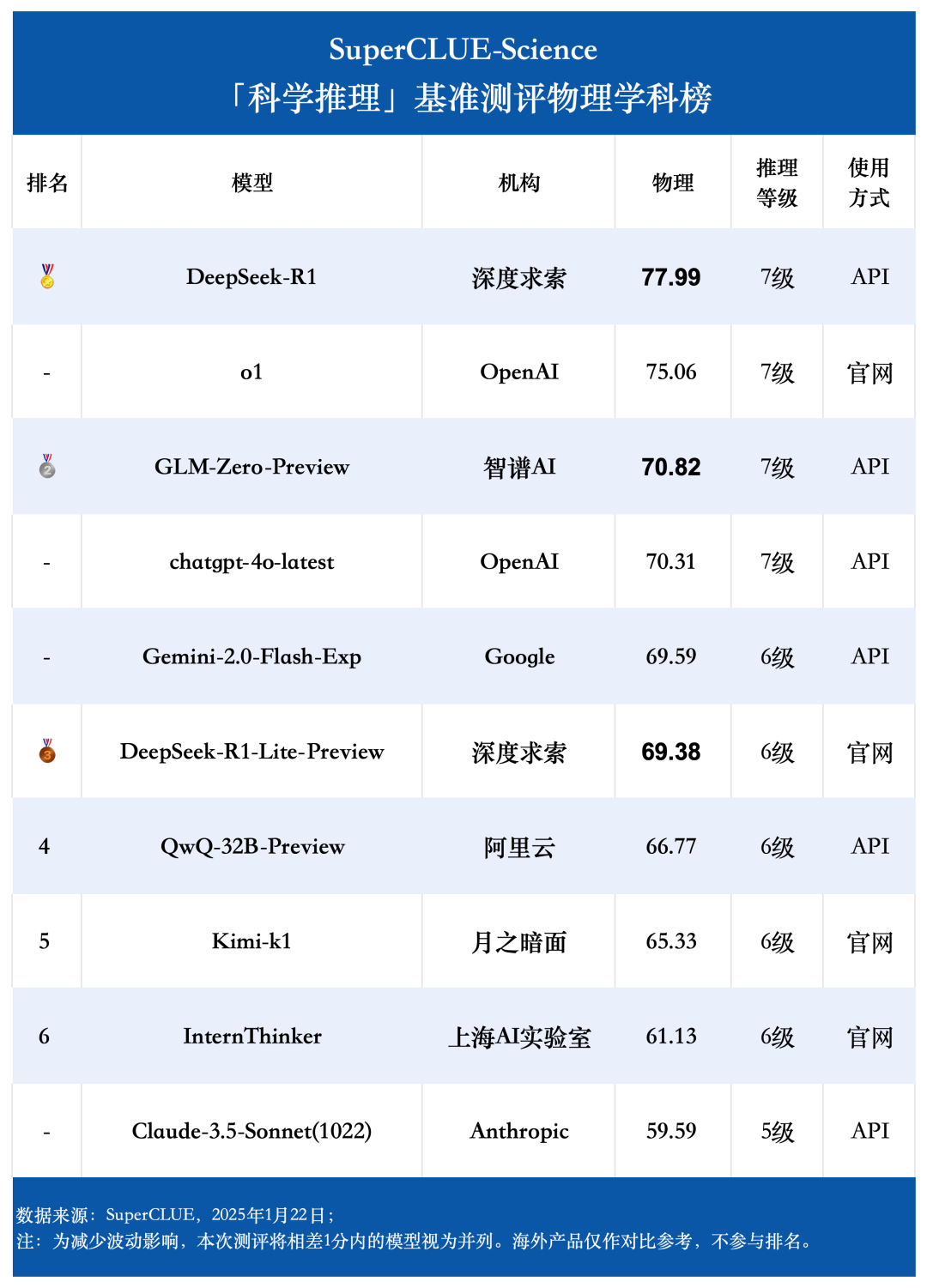
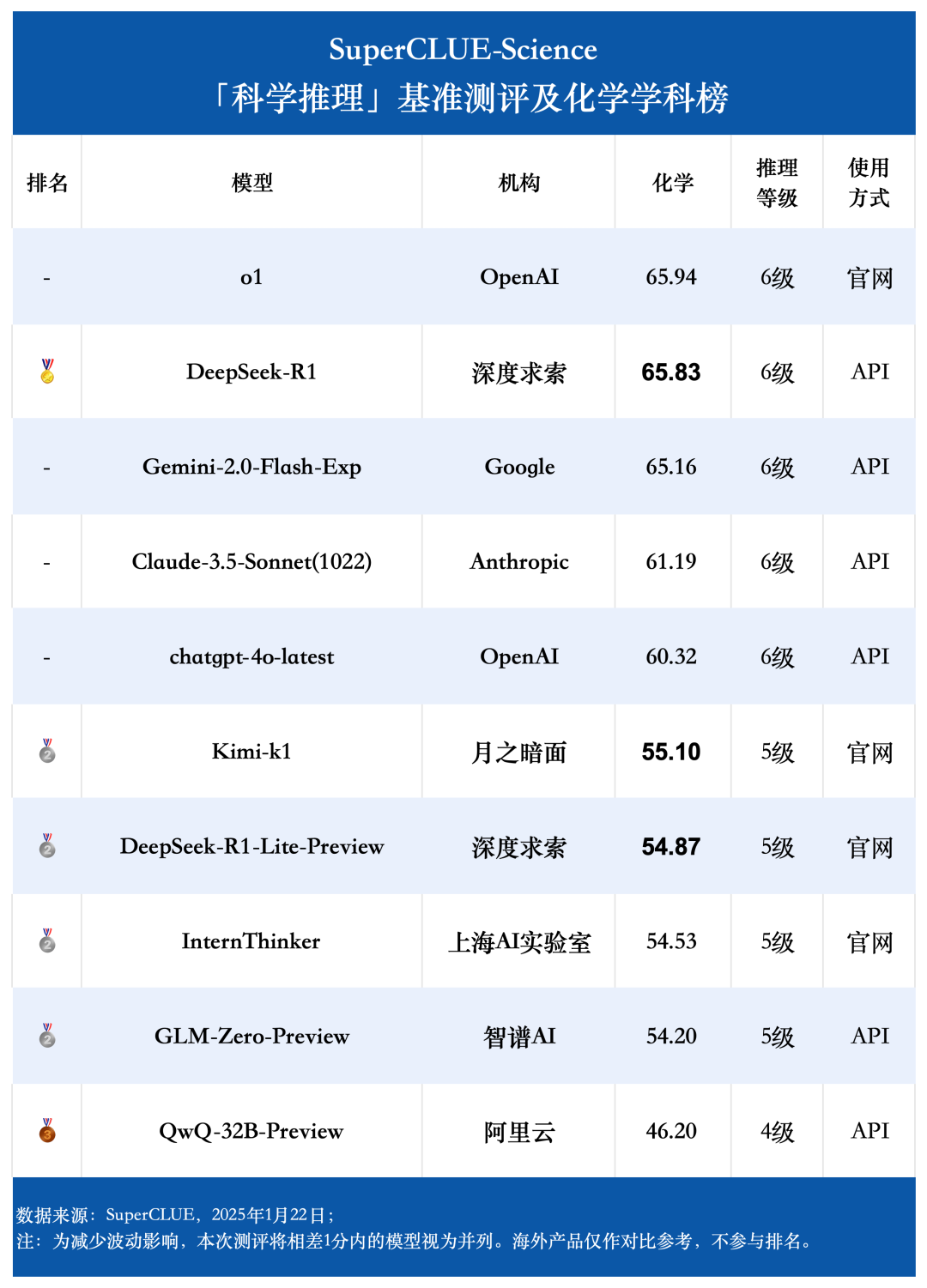
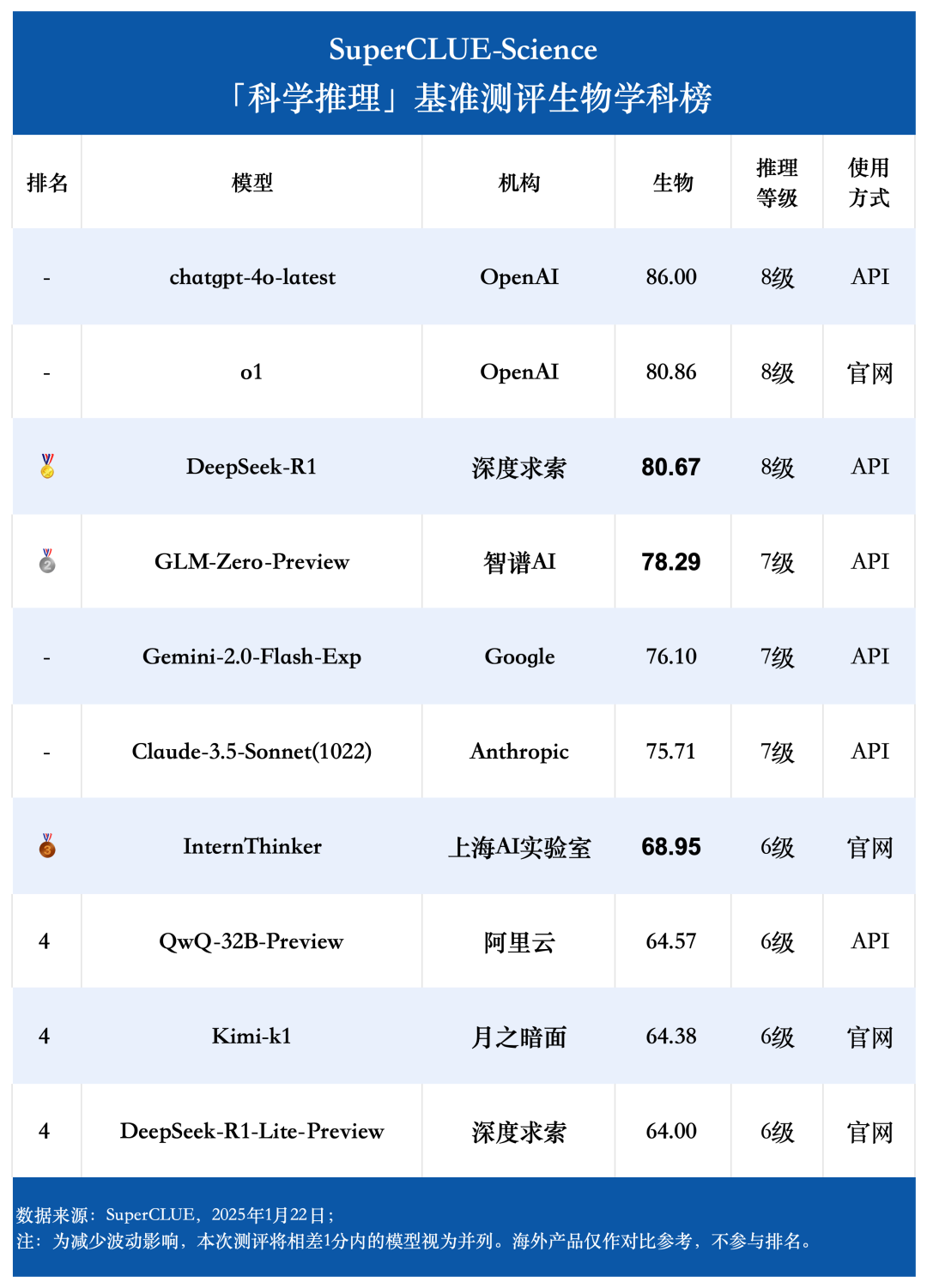
通过测评数据可以发现,国内大模型在物理学科上的表现可圈可点,DeepSeek-R1 在物理学科上的得分第一高,超越了 o1,且第三高的 GLM-Zero-Preview 表现同样出色,超越了海外知名大模型 chatgpt-4o-latest 和 Gemini-2.0-Flash-Exp;但相比起来,国内大模型在化学和生物学科方面的平均表现较为一般 ,还有一定提升空间。
测评要点3:国内外推理大模型展现了深度思考与自我反思的能力
在本次测评中,我们采用了具有客观答案的科学题,推理模型在得出答案后,通常会针对其自身给出的答案进行反思,将其与实际情况进行对比,分析其在客观层面的合理性以及计算的准确性。在“对比反思”这一环节,模型充分展现了其在推理过程中的自我反思能力与深度思考能力的进步。
# 榜单概览
为了更好的衡量大模型在科学推理上的能力,我们制定了一个推理等级体系,1到10级,10.00-19.99分为1级、20.00-29.99为2级,以此类推,90.00-99.99分为9级,100分为10级(这里不考虑总分10分以下的模型)
榜单地址:www.superclueai.com
详情请查看下方#正文。
# SuperCLUE-Science介绍
随着人工智能技术的迅速发展,大语言模型在复杂和专业的数理问题中的推理表现成为研究重点。以 OpenAI 为例,其在 2024 年 12 月 5 日正式发布的新模型 OpenAI o1 展现了强大的科学推理能力,o1 在测试研究生级别的物理、化学和生物学专业知识的基准 GPQA-Diamond 上表现惊人,展现了比肩人类博士级别的能力。
在完整版的 o1 推出之后,国内大模型厂商也迅速跟进,陆续推出了自己的推理模型,比如深度求索团队发布 DeepSeek-R1 模型,阿里通义团队发布 QwQ 模型,月之暗面团队发布 Kimi-k1 模型,智谱 GLM 团队发布 GLM-Zero 模型以及昆仑万维发布 Skywork-o1 模型等等。
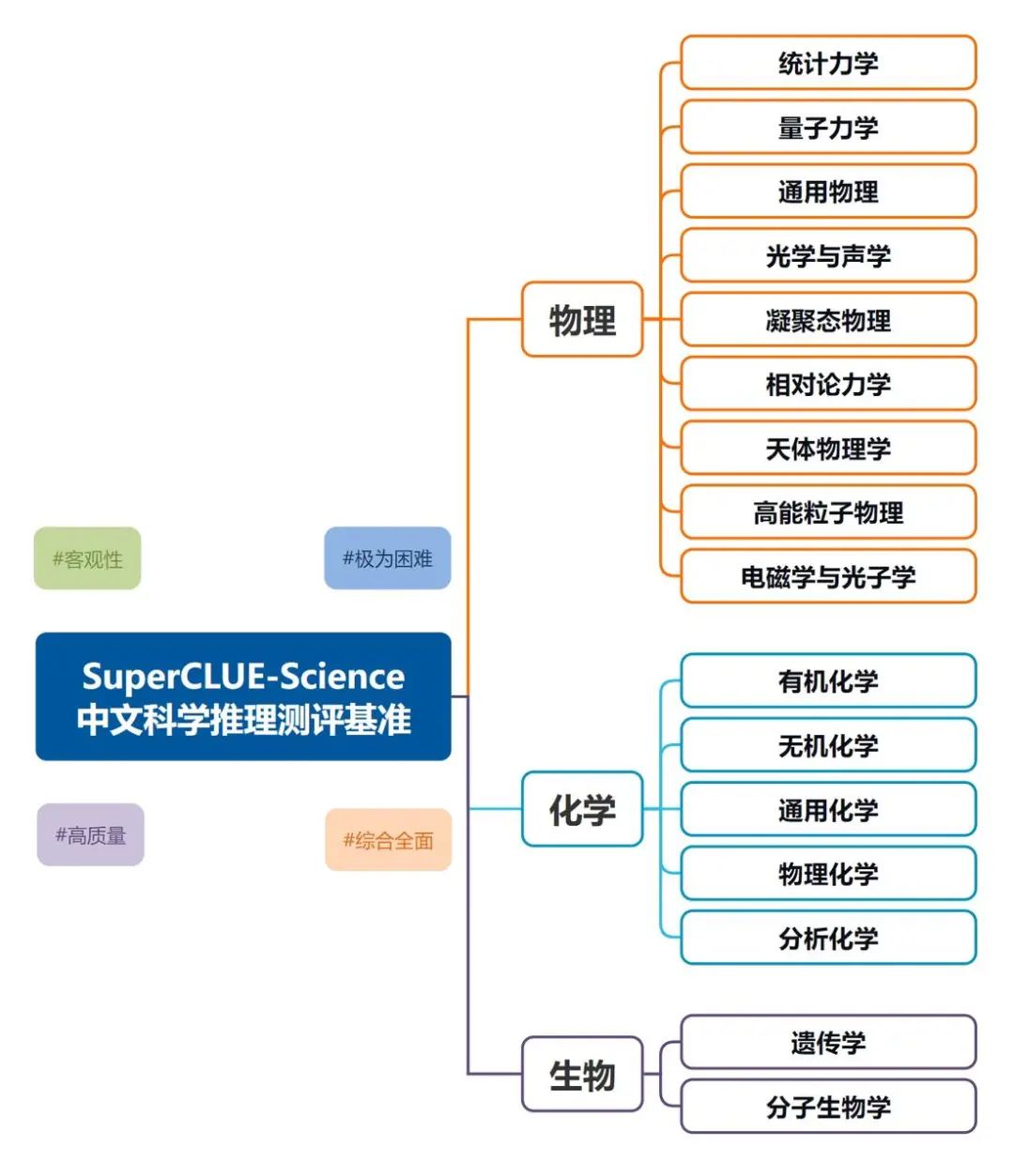
为更精确评估大模型在复杂和专业科学问题上的推理能力,我们基于中文基准测评经验,推出了科学推理测评基准 SuperCLUE-Science。该基准评估中文大模型在研究生级别的科学问题推理任务中的能力,特别关注题目涵盖知识点的广度与题目所需学术深度,对现有的国内外模型进行了严格的评测。这一框架旨在为未来模型研发提供参考,确保其在复杂任务中具备更高的可靠性和灵活性。
现在,我们正式发布中文大模型「科学推理」测评基准 SuperCLUE-Science 报告。
# 测评方法
1)测评集构建
科学推理中文题库构建流程:
1. 搜集和整理研究生级别的化学、物理和生物学专业知识 --->
2. 中文科学推理题撰写 --->
3. 题目质量和难度测试 --->
4. 修改并确定科学推理中文题库,参考国内外的标准,针对每一个维度构建专用的测评集
2)评分方法
评估标准涵盖了两个评价科学推理能力的重要维度,包括解题过程和最终答案,确保全面评估模型在研究生级别科学题上的推理能力。
评分规则采用定量方式,旨在确保评估过程的科学性和公正性。我们还引入了先进的自动化评分系统,极大地减少了人工干预,进一步地提升评估的效率和一致性。
在测评任务中,每个维度的评估标准都有明确的界定。将题目和模型回复送入评价模型(Gemini-2.0-Flash-Exp)进行评估,评价模型将遵循预定义的评估流程、标准和评分规则对模型回复进行评分,最终获得各个维度的评估结果。这一系统化的方法不仅提升了评估的精确度,还为大模型的改进提供了有力的数据支持。
评价过程中会提供人工校验后的参考答案,以便客观评估。
3)评分标准
针对各个大模型在测评任务上的回答质量,我们采取两个标准进行评估。
在科学推理题目的评估体系中,核心评判准则聚焦于“最终答案”是否精确无误,紧随其后的是对“解题过程”中推理步骤的严谨考量。我们设置“解题过程”占比 40%,“最终答案”占比 60%,将两者的加权得分作为最终得分。
SuperCLUE-Science 科学推理题异于常规科学题目,它们触及研究生层次的学术深度,不仅知识覆盖面广泛,而且在逻辑推理上更为错综复杂,这需要大模型跳出传统思维模式,采用创新性的思考策略。因此,在对此类题目进行评估时,我们不仅严格把关最终答案的准确性,同时也高度重视解题过程中推理逻辑的清晰与合理性,力求全面、深入地衡量大模型的科学推理能力。

# 测评示例
问题:

参考答案:11个
模型回答:

超级模型(Gemini-2.0-Flash-Exp)裁判:
对这个答案进行评估如下:
AI助手在解题过程中展现了逐步推理的能力,对每一步反应都进行了尝试性的分析,并尝试根据反应试剂推测可能的产物结构。虽然部分步骤的推导是错误的,但它能够意识到错误并进行自我纠正。最终答案正确。
AI助手的解题过程较为冗长,虽然逐步推理是好的,但在一些步骤中过于犹豫,且对一些反应的理解存在偏差,导致多次假设和纠正,反而增加了理解的难度。此外,AI助手对一些反应的推断存在偏差。
-
解题过程(5分):
AI助手在解题过程中进行了详细的分析,但部分分析是错误的,且过于犹豫,影响了推理的流畅性。解题思路基本符合要求,但部分推断不合理。基于标准1的得分,如 3 分;
得分:3/5
-
最终答案(5分):
AI助手提供的最终答案与参考答案完全相符。基于标准2的得分,如 5 分。
得分:5/5
综合得分 = 3*0.4 + 5*0.6 = 4.2
综合以上,AI助手的回答的综合得分为 4.2 分。(满分5分)
# 参评模型
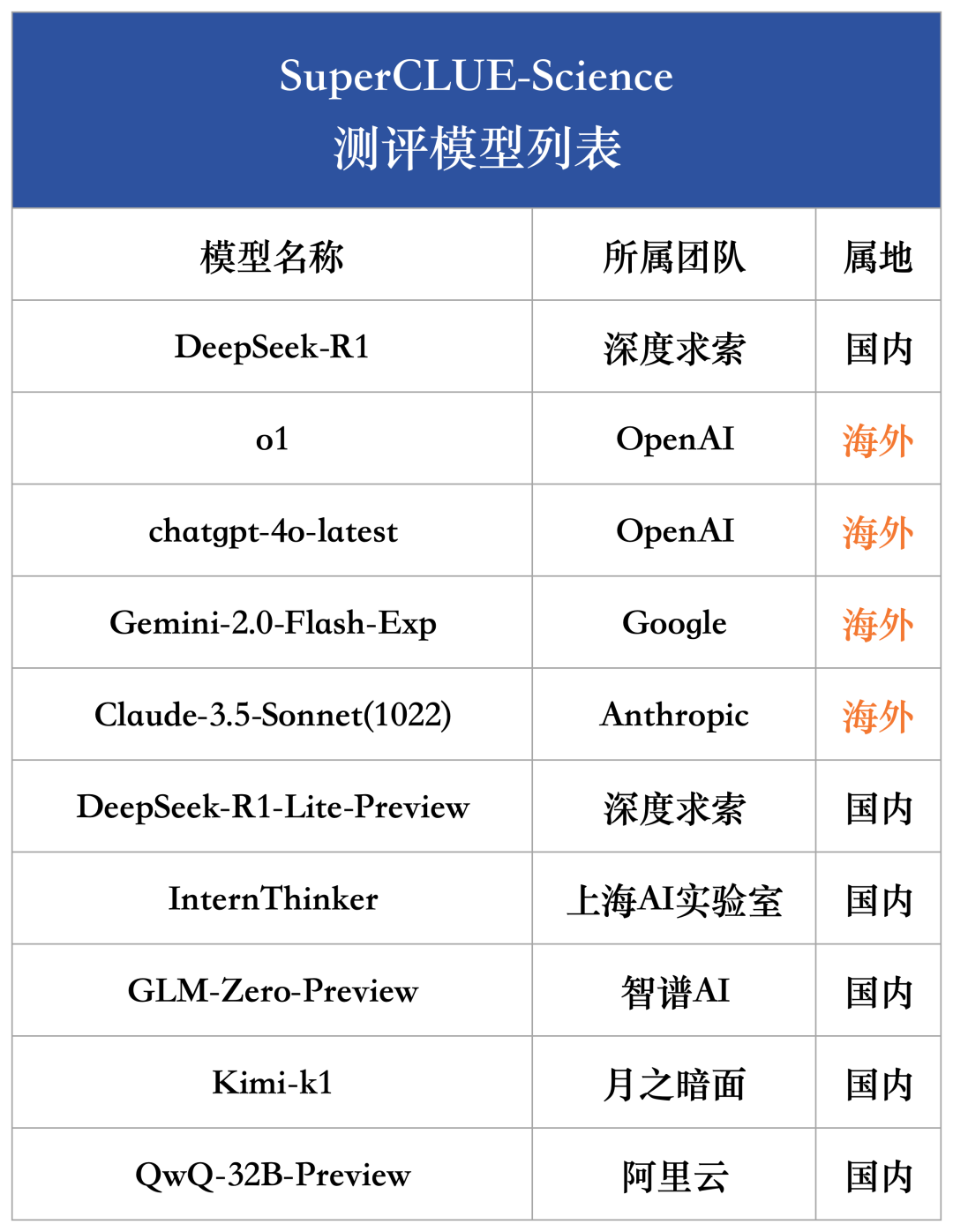
为综合衡量当前国内外大模型在科学推理能力的发展水平,本次测评选取了4个海外模型和6个国内代表性模型。
# 测评结果
总榜单
物理科学榜单
化学学科榜单
生物学科榜单
# 模型对比示例
#示例1 统计力学
问题:

参考答案:
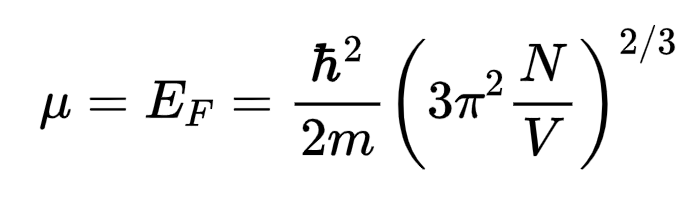
模型回答比较:
【Deepseek-R1】:5分(满分5分)

【InternThinker】:1.2分(满分5分)

#示例2 天体物理学
问题:

参考答案:
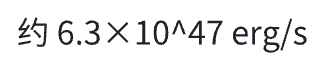
模型回答比较:
【o1】:4.6分(满分5分)

【Claude 3.5 Sonnet(20241022)】:1.2分(满分5分)

#示例3 分子生物学
问题:

参考答案:约5000
模型回答比较:
【GLM-Zero-Preview】:4.2分(满分5分)

【QwQ-32B-Preview】:3.8分(满分5分)

#示例4 有机化学
问题:

参考答案:3种
模型回答比较:
【chatgpt-4o-latest】:4.6分(满分5分)

【Kimi-k1】:3.34分(满分5分)

# 测评分析及结论
1.科学推理综合能力上,国内模型 DeepSeek-R1 超越世界顶尖模型 o1
由测评结果可知,Deepseek-R1(73.64分)在科学推理榜单中登顶,表现十分出色,成为科学推理中首个超越世界顶尖模型 o1 的国内模型,领跑 SuperCLUE-Science 基准。Deepseek-R1 较 o1 高 1.01 分,较 chatgpt-4o-latest 高 4.03 分,较国内排名第二的的模型 GLM-Zero-Preview 高 7.9 分。
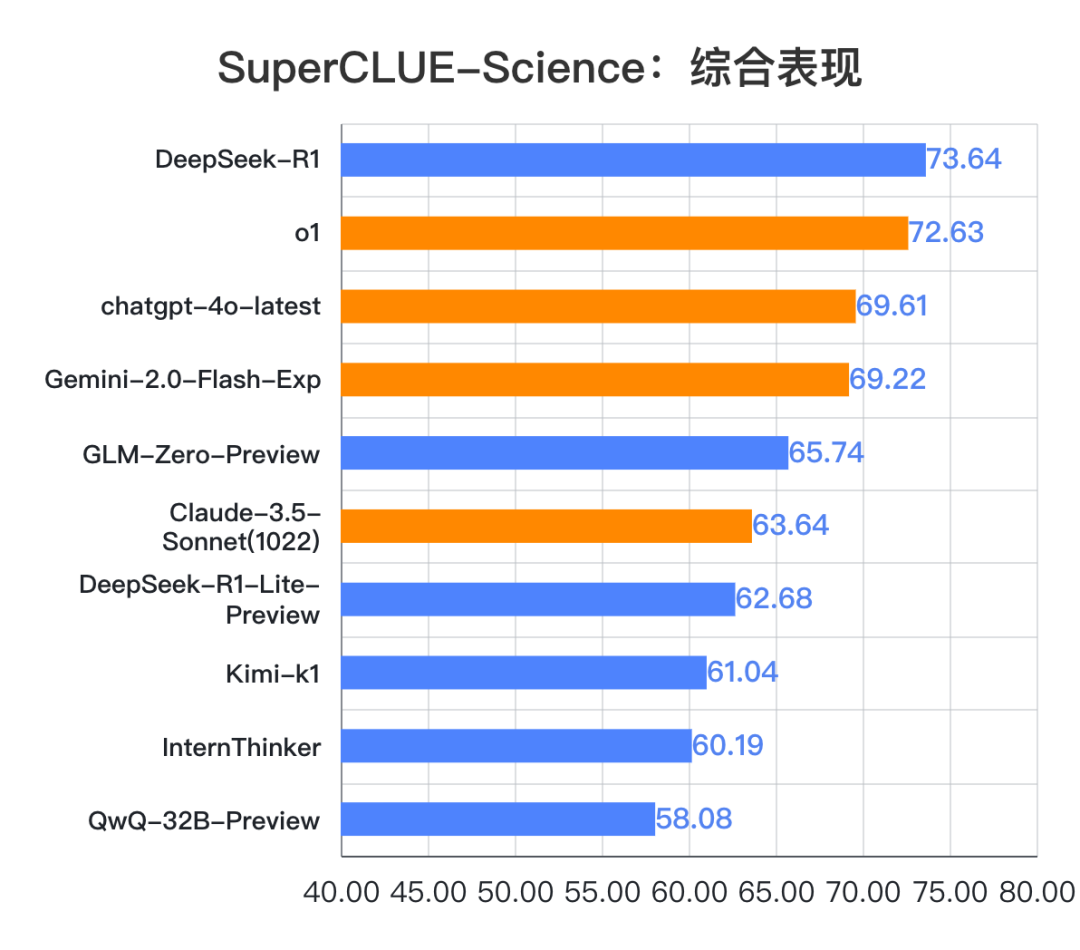
2.国内推理大模型整体表现优异,正在缩小与海外大模型的差距
通过测评结果可以发现,国内推理大模型的整体表现优异,特别是 DeepSeek-R1 和 GLM-Zero-Preview,它们在一众国内大模型中脱颖而出,除了 DeepSeek-R1 超越所有名列前茅的海外大模型,GLM-Zero-Preview 的表现也十分良好,有超越 Claude-3.5-Sonnet(1022) 趋势。
国内大模型在物理学科上的表现可圈可点,DeepSeek-R1 在物理学科上的得分第一高,比第二高的 o1 高了 2.93 分,且第三高的 GLM-Zero-Preview 表现同样出色,超越了海外知名大模型 chatgpt-4o-latest 和 Gemini-2.0-Flash-Exp;但相较而言在化学和生物学科方面,国内大模型的平均表现较为一般 ,还有一定提升空间。
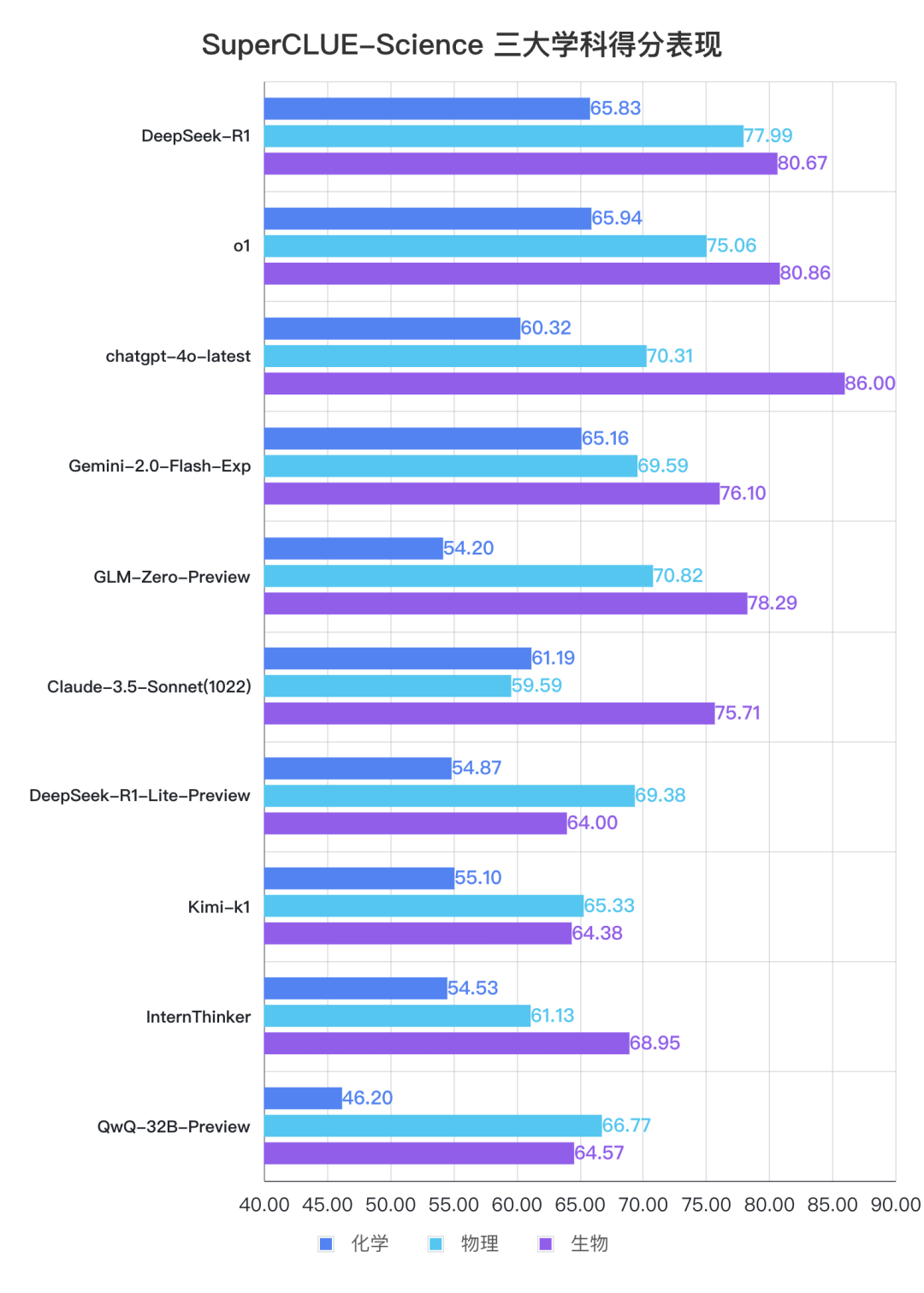
3.国内外推理模型展现了深度思考与自我反思的能力
在本次测评中,我们采用了研究生水平且基于客观事实的科学题目。推理模型在得出答案后,通常会针对答案进行自我反思。比如,推理模型会将其结论与客观实际情况进行比对,并针对自身给出的答案,分析其在客观层面的合理性以及计算的准确性。以物理学中的一些物理量为例,这些物理量往往处于特定的数量级范围之内,若明显答案超出范围则证明与事实不符,部分推理模型会据此进行自我反思,进一步确认给出的答案是否正确。模型“对比反思”的这一环节,充分展现了其在推理过程中的自我反思能力与深度思考能力的进步。
在科学推理任务中,大模型不仅需要全面掌握相关学科领域的专业知识,更要严谨、细致地分析推理场景中所涉及的约束条件与客观条件,在给定条件的基础上展开深入的逻辑推理。此外,科学推理通常伴随着一定规模的计算量,这对模型的计算推导能力提出了较高要求。模型需要具备高效且精准的计算能力,以确保在复杂的科学推理过程中,能够快速、准确地得出可靠的结论 ,从而满足科学推理任务的严格标准。

扩展阅读
[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark

往期精彩回顾
写了一本适合本科生的机器学习入门书适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑-
交流群
请备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“加群。
(也可以加入机器学习交流qq群772479961)


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)