
DeepSeek-V3:开源 AI 模型的新高度,真的火得一塌糊涂
在大语言模型(LLM)方面,各大技术团队不断突破模型规模和性能的极限。而的发布,则为开源社区带来了新的里程碑。作为一个拥有的专家混合(Mixture-of-Experts,MoE)模型,DeepSeek-V3[1] 展示了在效率、性能和训练成本方面的全面创新。DeepSeek-V3 的表现不仅在开源模型中独占鳌头,更在许多基准测试中接近甚至超过一些主流闭源模型(如 GPT-4 和 Claude)。
在大语言模型(LLM)方面,各大技术团队不断突破模型规模和性能的极限。而 DeepSeek-V3 的发布,则为开源社区带来了新的里程碑。作为一个拥有 6710 亿参数的专家混合(Mixture-of-Experts,MoE)模型,DeepSeek-V3[1] 展示了在效率、性能和训练成本方面的全面创新。
一、DeepSeek-V3 的独特亮点
DeepSeek-V3 在多个方面实现了技术突破,其中包括:
-
- 创新的负载均衡策略
与传统 MoE 模型依赖额外损失函数(auxiliary loss)不同,DeepSeek-V3 采用了无辅助损失的负载均衡机制,大幅降低了模型性能受限的问题。
- 创新的负载均衡策略
-
- 多标记预测目标(MTP)
通过多标记预测目标,模型在训练期间能够优化多个输出的预测准确性,这项技术在推理加速(speculative decoding)中也有显著作用。
- 多标记预测目标(MTP)
-
- 超高效的 FP8 混合精度训练
DeepSeek-V3 率先在大规模模型中验证了 FP8 精度训练的可行性,结合软硬件协同设计,突破了跨节点通信的瓶颈,实现了几乎完全的计算与通信重叠。这一创新使模型训练成本降至 278.8 万 H800 GPU 小时,远低于同类模型的训练成本。
- 超高效的 FP8 混合精度训练
-
- 稳定的训练过程
在整个训练过程中,DeepSeek-V3 未发生不可恢复的损失波动或回滚操作。这意味着模型的训练过程不仅高效,而且异常稳定。
- 稳定的训练过程
二、性能超越开源与闭源的对手
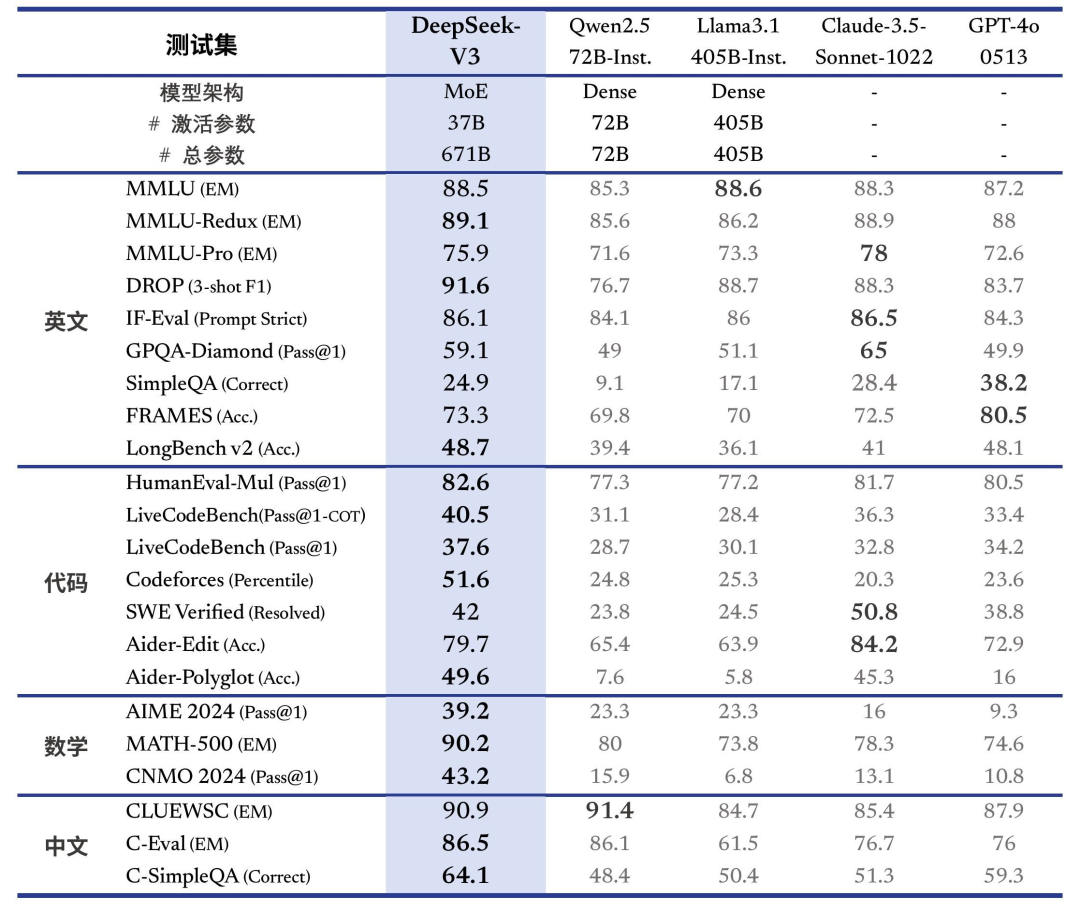
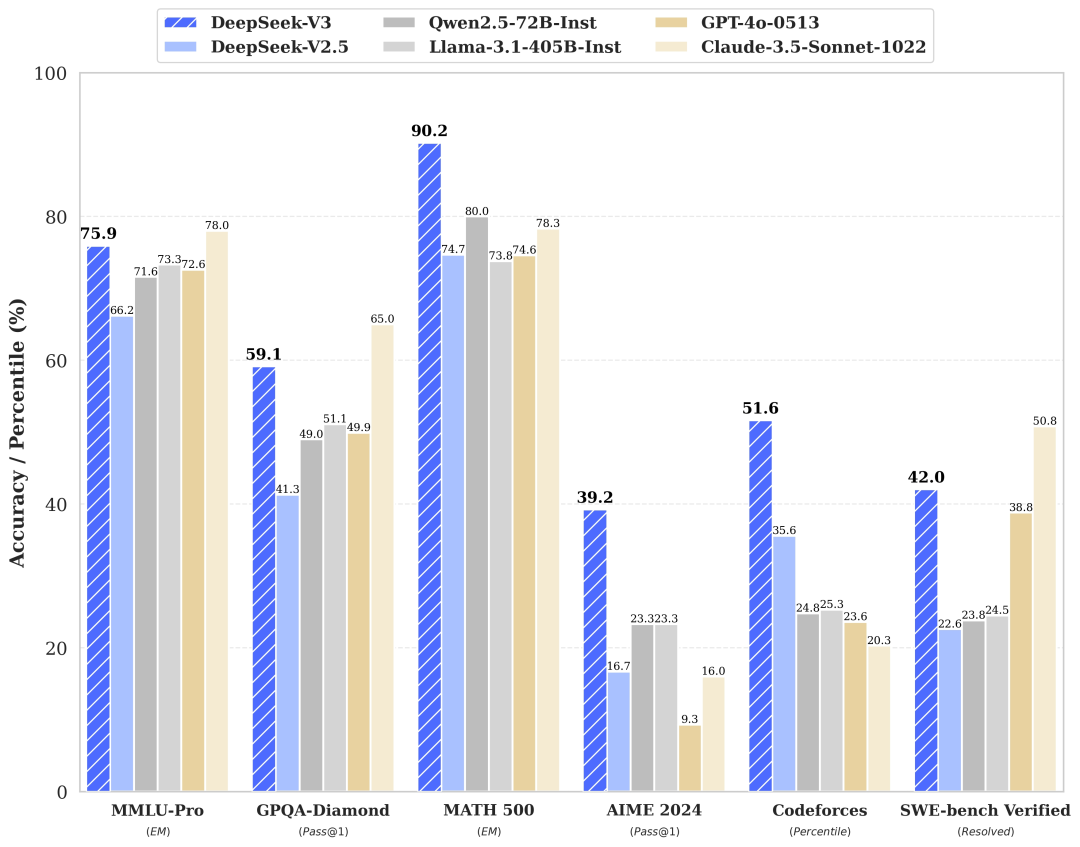
DeepSeek-V3 的表现不仅在开源模型中独占鳌头,更在许多基准测试中接近甚至超过一些主流闭源模型(如 GPT-4 和 Claude)。以下是几个值得注意的性能亮点:
-
• 数学与代码任务
在数学基准(如 MATH 和 GSM8K)以及代码生成任务(如 HumanEval 和 Codeforces)中,DeepSeek-V3 显著领先同类开源模型,并大幅提升了代码问题的解答通过率(Pass@1)。 -
• 多语言能力
无论是中文还是多语言基准测试,DeepSeek-V3 的表现均十分突出。在 C-Eval 和 CMMLU 等中文任务中,其准确率分别达到 90.1% 和 88.8%,在开源模型中处于领先地位。 -
• 推理和生成能力
在开放式生成评估中(如 AlpacaEval 2.0 和 Arena-Hard),DeepSeek-V3 的表现超过大多数竞品,其生成质量与语言理解能力得到了业界的高度认可。
三、优化的架构与高效训练
DeepSeek-V3 的成功离不开其优化的架构设计和训练策略:
-
- 深度继承 DeepSeek-V2 的技术基础
在上一代模型中验证过的 Multi-head Latent Attention (MLA) 和 DeepSeekMoE 架构,为 DeepSeek-V3 提供了高效计算与卓越性能的双重保证。
- 深度继承 DeepSeek-V2 的技术基础
-
- 知识蒸馏与能力迁移
DeepSeek-V3 从 DeepSeek-R1 系列模型中蒸馏了长链式推理(Chain-of-Thought,CoT)能力,并灵活地融入了验证与反思模式,使得其推理能力显著提升,同时输出风格和长度得到了有效控制。
- 知识蒸馏与能力迁移
-
- 经济成本与可扩展性
通过高效的训练框架,DeepSeek-V3 在不增加额外资源投入的情况下,成功将模型规模扩展至 6710 亿参数。此外,后续的微调与强化学习阶段仅需 0.1 万 GPU 小时即可完成。
- 经济成本与可扩展性
四、部署与使用的灵活性
为了让更多开发者能够快速上手,DeepSeek-V3 提供了多种运行方式,支持 NVIDIA、AMD 和华为 Ascend 等硬件平台,并与多家开源社区工具集成:
-
• SGLang
提供高性能 FP8 推理优化,兼容多节点张量并行模式,推荐开发者优先选择。 -
• LMDeploy 与 vLLM
这两种框架为在线与离线推理提供了灵活的解决方案,特别适合大规模应用场景。 -
• TensorRT-LLM
支持多种量化精度(如 BF16、INT4/8),并即将推出 FP8 支持。
此外,DeepSeek-V3 还开放了 Hugging Face 平台的模型权重,开发者可以通过官方文档快速部署。
推荐工具结合
使用 vscode 插件 cline,兼顾补全和类似 cursor composer 的能力
cline
使用开源项目bolt.diy[2] ,嘿嘿,下篇会解读这个神器的源码实现。
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《AI大模型入门+进阶学习资源包**》,扫码获取~
篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!
💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。
路线图很大就不一一展示了 (文末领取)
👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉国内企业大模型落地应用案例👈
💥两本《中国大模型落地应用案例集》 收录了近两年151个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)
👉GitHub海量高星开源项目👈
💥收集整理了海量的开源项目,地址、代码、文档等等全都下载共享给大家一起学习!
👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)
👉640份大模型行业报告(持续更新)👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 27
27 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)