DeepSeekMath:在开放语言模型中突破数学推理的极限
24年4月来自DeepSeek-AI、清华和北大的论文“DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models”。数学推理因其复杂性和结构性而对语言模型构成了重大挑战。本文引入 DeepSeekMath 7B,它继续使用来自 Common Crawl 的 120B 个数学相关tokens以
24年4月来自DeepSeek-AI、清华和北大的论文“DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models”。
数学推理因其复杂性和结构性而对语言模型构成了重大挑战。本文引入 DeepSeekMath 7B,它继续使用来自 Common Crawl 的 120B 个数学相关tokens以及自然语言和代码数据,对 DeepSeek-Coder-Base-v1.5 7B 进行预训练。DeepSeekMath 7B 在不依赖外部工具包和投票技术的情况下,在竞赛级 MATH 基准上取得了 51.7% 的成绩,接近 Gemini-Ultra 和 GPT-4 的性能水平。DeepSeekMath 7B 在 64 个样本上的自洽性在 MATH 上达到 60.9%。DeepSeekMath 的数学推理能力归功于两个关键因素:首先,通过精心设计的数据选择流水线充分利用了公开可用的网络数据的巨大潜力。其次,引入近端策略优化(PPO)的一种变型——组相对策略优化(GRPO),它可以增强数学推理能力,同时优化 PPO 的内存使用情况。
DeepSeekMath 是一种域特定语言模型,其数学能力显著优于开源模型,在学术基准上接近 GPT-4 的性能水平。为了实现这一目标,创建 DeepSeek-Math 语料库,这是一个包含 1200 亿个数学tokens的大规模高质量预训练语料库。该数据集是使用基于 fastText 的分类器 (Joulin,2016) 从 Common Crawl (CC) 中提取的。在初始迭代中,使用来自 OpenWebMath (Paster,2023) 的实例作为正例对分类器进行训练,同时结合各种其他网页作为负例。随后,使用分类器从 CC 中挖掘更多正例,并通过人工注释进一步细化这些正例。然后使用这个增强的数据集更新分类器以提高其性能。评估结果表明,大规模语料库质量很高,因为基础模型 DeepSeekMath-Base 7B 在 GSM8K(Cobbe,2021)上达到 64.2%,在竞赛级 MATH 数据集(Hendrycks,2021)上达到 36.2%,优于 Minerva 540B(Lewkowycz,2022a)。此外,DeepSeekMath 语料库是多语言的,因此中文数学基准测试有所改进(Wei,2023;Zhong,2023)。在数学数据处理方面的经验是研究界的起点,未来还有很大的改进空间。
先说数学预训练。
数据收集和净化
如图所示从 Common Crawl 构建 DeepSeekMath 语料库的过程。其中是一个迭代流水线,演示如何从 Common Crawl 系统地收集大规模数学语料库,从种子语料库(例如,一个小型但高质量的数学相关数据集集合)开始。
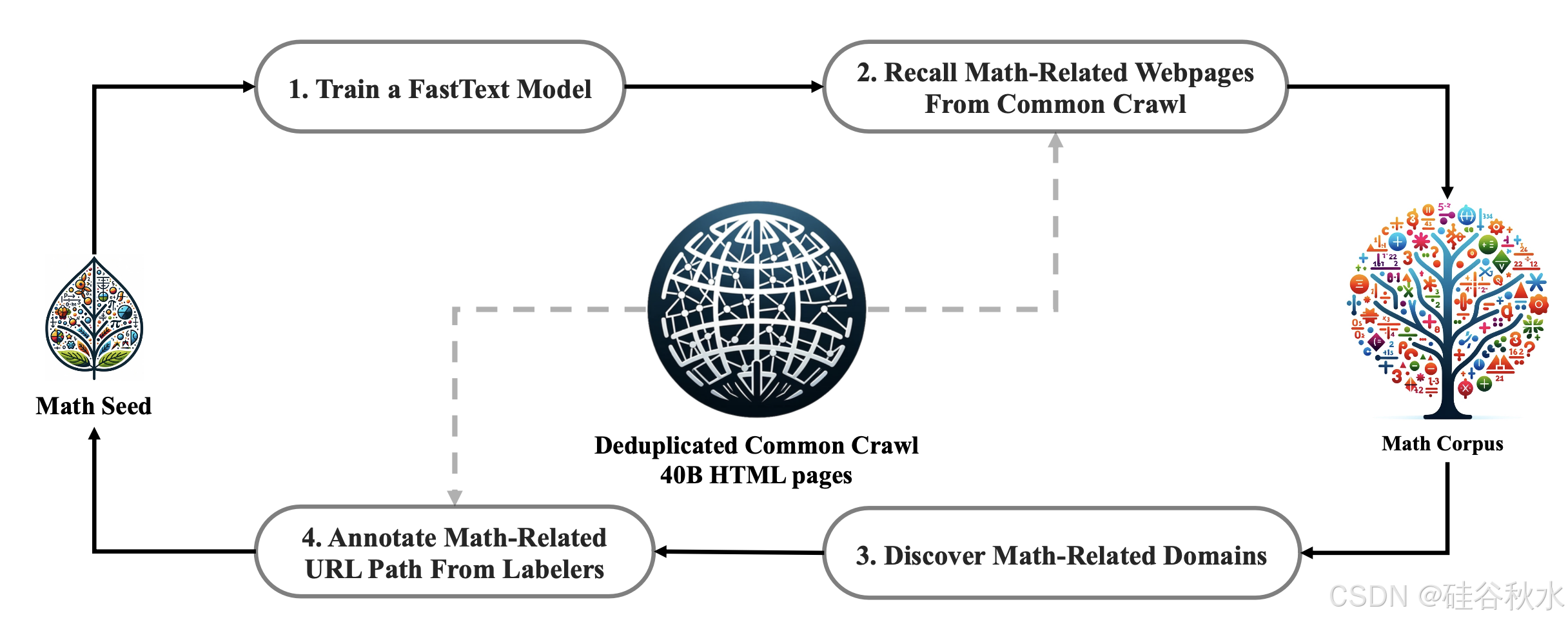
首先,选择 OpenWebMath(Paster,2023),一组高质量的数学网络文本,作为初始种子语料库。使用这个语料库,训练一个 fastText 模型(Joulin,2016 年)来回忆更多类似 OpenWebMath 的数学网页。具体来说,从种子语料库中随机选择 500,000 个数据点作为正训练示例,并从 Common Crawl 中随机选择另外 500,000 个网页作为负训练示例。使用一个 fastText 开源库进行训练,将向量维度配置为256,学习率为0.1,单词n-gram的最大长度为3,单词出现的最小次数为3,训练周期数为3。为了减小原始Common Crawl的大小,用基于URL的去重和近似去重技术,得到40B的HTML网页。然后使用fastText模型,从去重后的Common Crawl中调用数学网页。为了过滤掉低质量的数学内容,根据fastText模型预测的分数对收集的页面进行排名,只保留排名靠前的页面。通过对前40B、80B、120B和160B个token进行预训练实验,评估保留的数据量。在第一次迭代中,选择保留前40B个token。
在第一次数据收集迭代之后,仍有许多数学网页未被收集,这主要是因为 fastText 模型是在一组缺乏足够多样性的正例上训练的因此,确定其他数学网络资源来丰富种子语料库,以便我们可以优化 fastText 模型。具体来说,首先将整个 Common Crawl 组织成不相交的域;域被定义为共享相同基本 URL 的网页。对于每个域,计算在第一次迭代中收集的网页百分比。收集超过 10% 网页的域,被归类为与数学相关的域(例如 MathOverflow)。随后,手动注释这些已识别域中与数学内容相关的 URL(例如 mathoverflow.net/questions)。链接到这些 URL 的网页(尚未收集)将被添加到种子语料库中。这种方法能够收集更多正例,从而训练出一个改进的 fastText 模型,该模型能够在后续迭代中调用更多数学数据。经过四次数据收集迭代,最终得到了 3550 万个数学网页,总计 1200 亿个 token。在第四次迭代中,发现近 98% 的数据已经在第三次迭代中收集,因此决定停止数据收集。
为了避免基准污染,遵循 Guo(2024 年)的做法,过滤掉包含英语数学基准(例如 GSM8K(Cobbe,2021)和 MATH(Hendrycks,2021))和中文基准(例如 CMATH(Wei,2023)和 AGIEval(Zhong,2023))中问题或答案的网页。过滤标准如下:任何包含与评估基准中的任何子字符串完全匹配的 10-gram 字符串的文本段都将从数学训练语料库中删除。对于长度少于10克但至少有3克的基准文本,采用精确匹配来过滤掉受污染的网页。
验证 DeepSeekMath 语料库的质量
预训练实验研究 DeepSeekMath 语料库与最近发布的数学训练语料库比较情况:
• MathPile (Wang,2023c):一个多源语料库(89 亿个tokens),来自教科书、维基百科、ProofWiki、CommonCrawl、StackExchange 和 arXiv,其中大部分(超过 85%)来自 arXiv;
• OpenWebMath (Paster,2023):Common Crawl 数据经过数学内容过滤,总计 136 亿个tokens;
• Proof-Pile-2 (Azerbayev,2023):一个由 OpenWeb-Math、AlgebraicStack(103 亿个数学代码tokens)和 arXiv 论文(280 亿个tokens)组成的数学语料库。在 Proof-Pile-2 上进行实验时,遵循 Azerbayev (2023) 的方法,使用 arXiv:Web:Code 比例为 2:4:1。
训练设置
将数学训练应用于具有 1.3B 参数的通用预训练语言模型,该模型与 DeepSeek LLM(DeepSeek-AI,2024)共享相同的框架,记为 DeepSeek-LLM 1.3B。在每个数学语料库上分别训练一个模型,使用 150B 个 token。所有实验均使用高效轻量级的 HAI-LLM(High-flyer,2023)训练框架进行。遵循 DeepSeek LLM 的训练实践,用 AdamW 优化器(Loshchilov and Hutter,2017),其中 𝛽1 = 0.9、𝛽2 = 0.95、weight_decay = 0.1,以及多步学习率进度,其中学习率在 2,000 个预热步骤后达到峰值,在训练过程的 80% 后降至 31.6%,在训练过程的 90% 后进一步降至峰值的 10.0%。将学习率的最大值设置为 5.3e-4,并使用 4M 个 token 的批处理大小和 4K 上下文长度。
评估结果
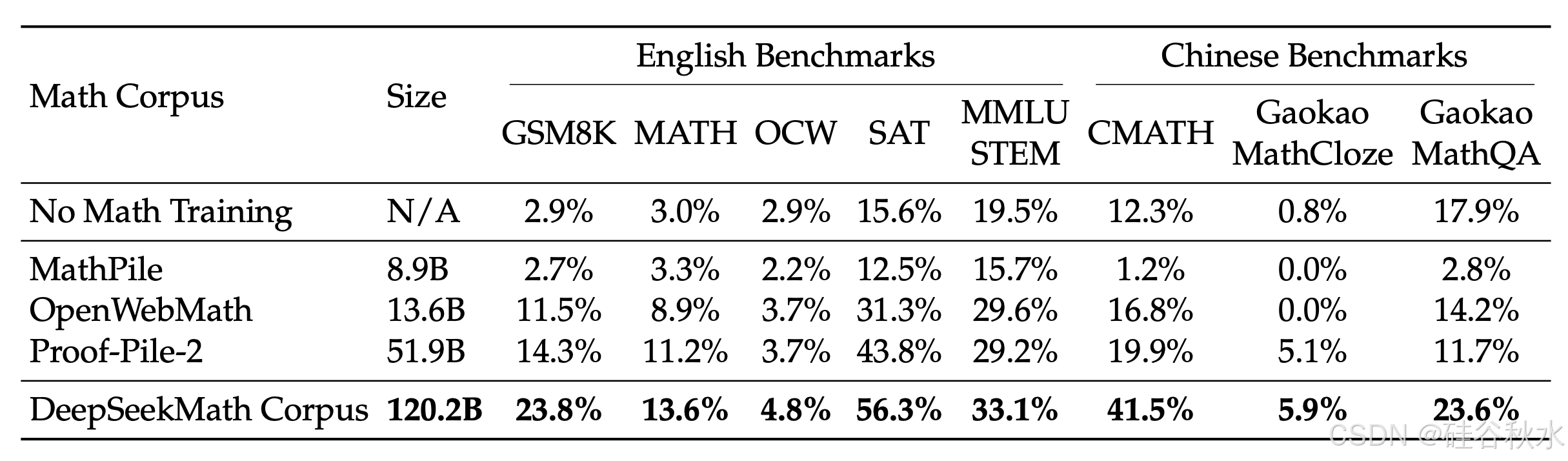
DeepSeekMath 语料库质量高,涵盖多语言数学内容,规模最大。
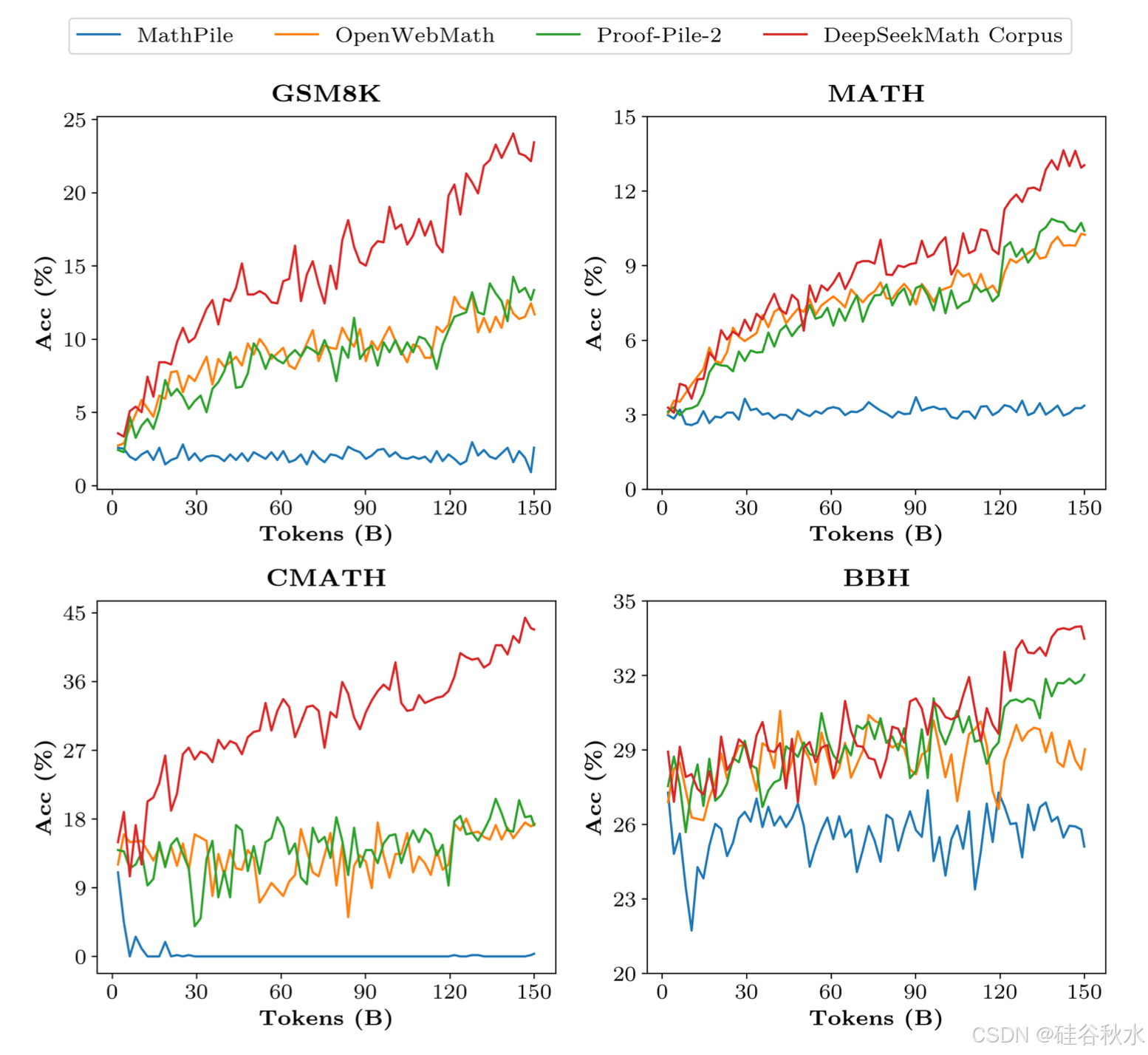
• 高质量:用 Wei(2022)提出的少样本思维链方法在 8 个数学基准上评估下游性能。如表所示,在 DeepSeekMath 语料库上训练的模型在性能上明显领先。如下图显示在 DeepSeekMath 语料库上训练的模型在 50B 个 token(Proof-Pile-2 的 1 个完整 epoch)下表现出比 Proof-Pile-2 更好的性能,表明DeepSeekMath 语料库的平均质量更高。
• 多语言:DeepSeekMath 语料库包含多种语言的数据,主要以英语和中文为代表的两种语言。如表所示,在 DeepSeekMath 语料库上进行训练可提高英语和中文的数学推理性能。相比之下,现有的以英语为中心的数学语料库的改进有限,甚至可能阻碍中文数学推理的表现。
• 规模大:DeepSeekMath 语料库比现有数学语料库大几倍。如图所示,DeepSeek-LLM 1.3B 在 DeepSeek-Math 语料库上训练时,学习曲线更陡峭,改进更持久。相比之下,基线语料库要小得多,并且在训练过程中已经重复了多轮,最终的模型性能很快达到稳定水平。
训练和评估 DeepSeekMath-Base 7B
DeepSeekMath-Base 7B,是一个具有强大推理能力的基础模型,尤其是在数学方面。模型使用 DeepSeek-Coder-Base-v1.5 7B(Guo,2024)初始化,并针对 500B 个 token 进行训练。数据分布如下:56%来自DeepSeekMath Corpus,4%来自AlgebraicStack,10%来自arXiv,20%是Github代码,剩下的10%是来自Common Crawl的中英文自然语言数据。主要采用上面验证时的训练设置,但将学习率的最大值设置为4.2e-4,并使用10M token的批处理大小。
对DeepSeekMath-Base 7B的数学能力进行全面的评估,重点关注其在不依赖外部工具的情况下产生自包含的数学解决方案、使用工具解决数学问题以及进行形式化定理证明的能力。除了数学之外,还提供了基础模型的更一般的概况,包括其自然语言理解、推理和编程技能的表现。
使用分步推理解决数学问题。评估 DeepSeekMathBase 使用少样本思维链提示 (Wei et al., 2022) 解决数学问题的性能,测试 8 个英文和中文基准。这些基准涵盖定量推理(例如 GSM8K (Cobbe et al., 2021)、MATH (Hendrycks et al., 2021) 和 CMATH (Wei et al., 2023))和多项选择题(例如 MMLU-STEM (Hendrycks et al., 2020) 和 Gaokao-MathQA (Zhong et al., 2023)),涵盖从小学到大学水平复杂程度的各个数学领域。
如表所示,DeepSeekMath-Base 7B 在开源基础模型(包括广泛使用的通用模型 Mistral 7B(Jiang et al., 2023)和最近发布在 Proof-Pile-2(Azerbayev et al., 2023)上进行数学训练的 Llemma 34B(Azerbayev et al., 2023)),所有 8 个基准测试中均表现领先。值得注意的是,在竞赛级 MATH 数据集上,DeepSeekMath-Base 绝对性能超越现有开源基础模型 10% 以上,并且优于 Minerva 540B(Lewkowycz et al., 2022a),后者是一个比其大 77 倍的闭源基础模型,它基于 PaLM(Lewkowycz et al., 2022b)建立,并在数学文本上进行了进一步训练。
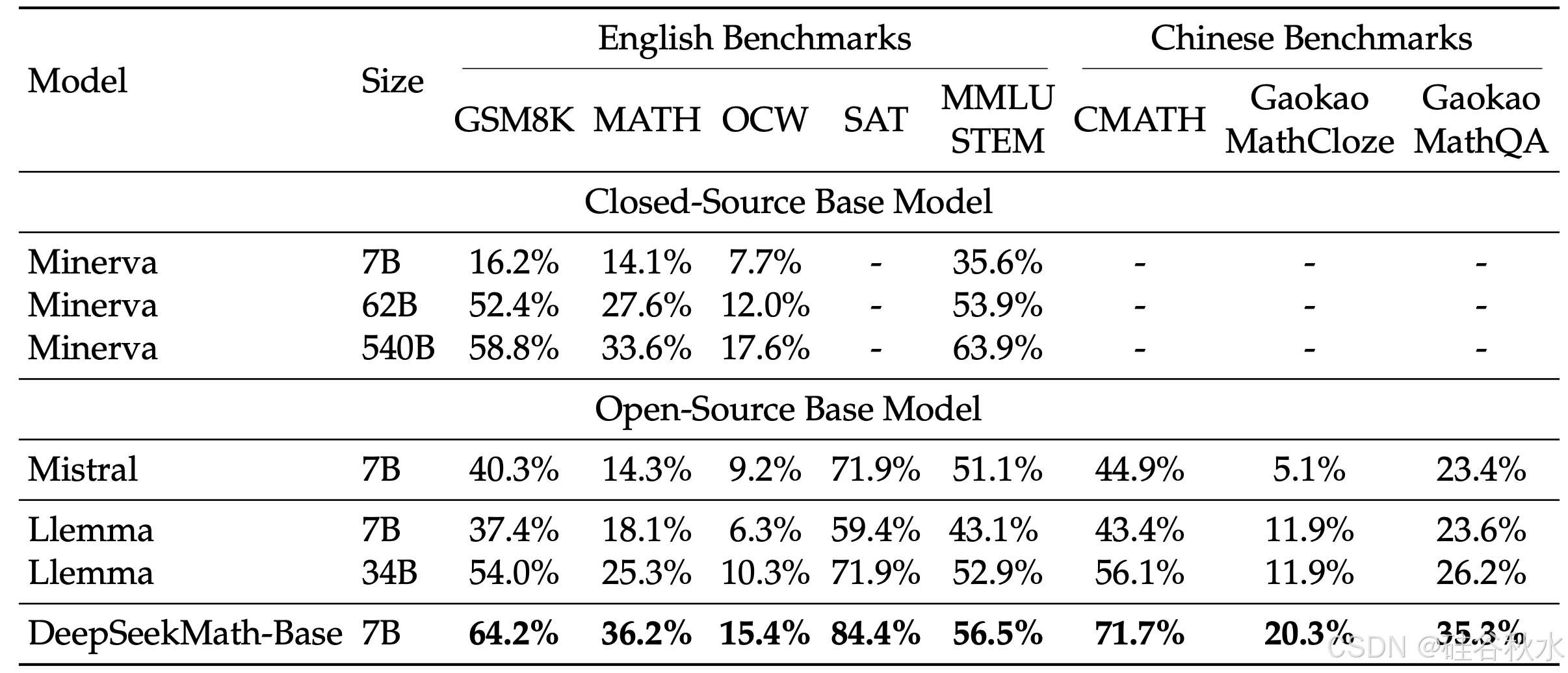
使用工具解决数学问题。用少样本思维程序提示 (Chen et al., 2022; Gao et al., 2023) 评估 GSM8K 和 MATH 上的程序辅助数学推理。通过编写 Python 程序提示模型解决每个问题,其中可以使用 math 和 sympy 等库进行复杂的计算。程序的执行结果被评估为答案。如表所示,DeepSeekMath-Base 7B 的表现优于之前最先进的 Llemma 34B。
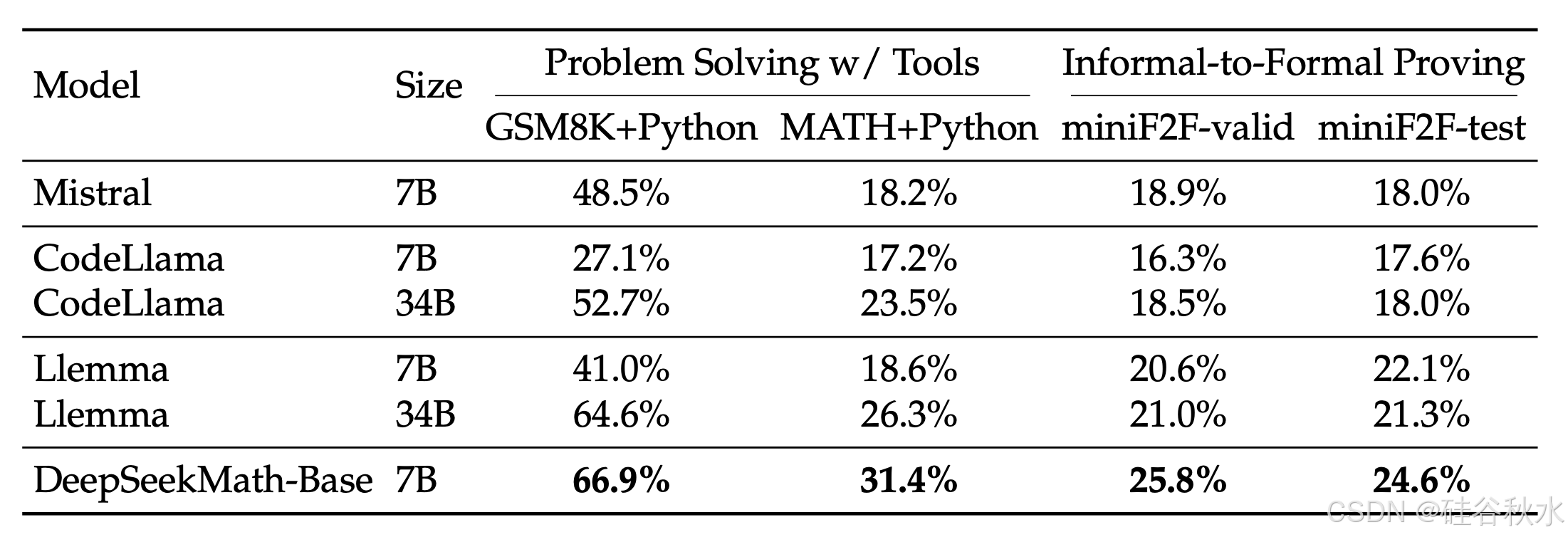
形式化数学。形式化定理证明自动化,有利于保证数学证明的准确性和可靠性,提高效率,近年来受到越来越多的关注。在 (Jiang et al., 2022) 的非形式化到形式化证明任务上,对 DeepSeekMath-Base 7B 进行评估,即基于非形式化语句、该语句的形式对应项和非形式化证明生成形式化证明。在形式化奥林匹克级数学基准 miniF2F (Zheng et al., 2021) 上进行评估,并在 Isabelle 中为每个问题生成一个带有少量提示的形式证明。继 Jiang et al. (2022) 之后,利用模型生成证明草图,并执行现成的自动证明器 Sledgehammer (Paulson, 2010) 来填补缺失的细节。如上表所示,DeepSeekMath-Base 7B 在证明自动形式化方面表现出色。
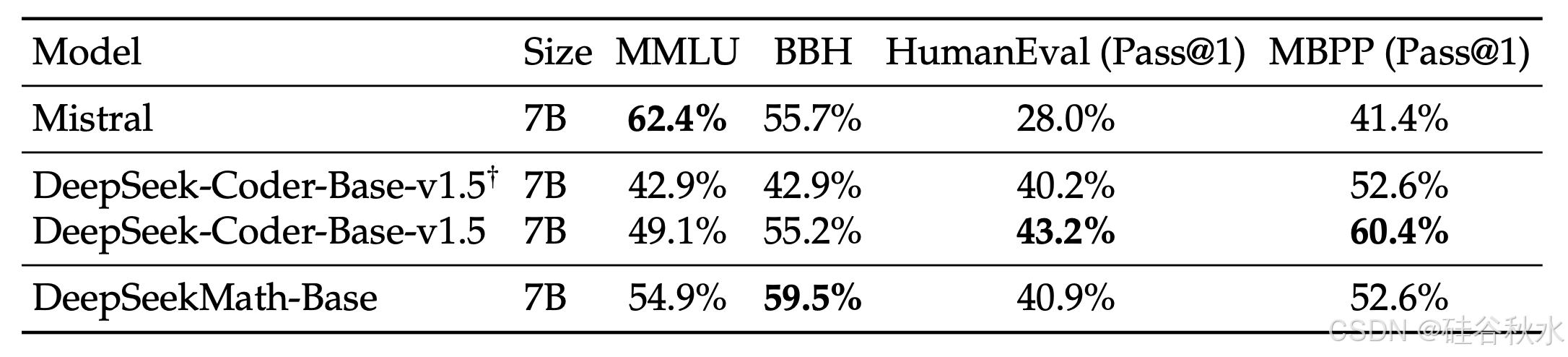
自然语言理解、推理和编码。评估模型在 MMLU(Hendrycks,2020)上的自然语言理解性能、在 BBH(Suzgun,2022)上的推理性能以及在 HumanEval(Chen,2021)和 MBPP(Austin,2021)上的编码能力。如表所示,DeepSeekMath-Base 7B 在 MMLU 和 BBH 上的性能与其前身 DeepSeek-Coder-Base-v1.5(Guo,2024)相比有显著提升,说明数学训练对语言理解和推理的积极影响。此外,通过包含用于持续训练的代码tokens,DeepSeekMath-Base 7B 在两个编码基准上有效地保持 DeepSeek-Coder-Base-v1.5 的性能。总体而言,DeepSeekMath-Base 7B 在三个推理和编码基准上的表现明显优于通用模型 Mistral 7B(Jiang et al., 2023)。
再说监督微调 (SFT)。
SFT 数据管理
构建一个数学指令调整数据集,涵盖来自不同数学领域和不同复杂程度的英语和中文问题:问题与解决方案以思维链 (CoT)(Wei,2022)、思维程序 (PoT)(Chen,2022;Gao,2023)和工具-集成推理格式(Gou,2023)配对。训练示例总数为 776K。
• 英语数学数据集:用工具集成解决方案注释 GSM8K 和 MATH 问题,并采用 MathInstruct(Yue,2023)的子集以及 Lila-OOD(Mishra,2022)的训练集,其中问题用 CoT 或 PoT 解决。英文数据集涵盖代数、概率、数论、微积分和几何等各种数学领域。
• 中文数学数据集:收集涵盖 76 个子主题(例如线性方程)的中文 K-12 数学问题,其解决方案以 CoT 和工具集成推理格式注释。
训练和评估 DeepSeekMath-Instruct 7B
DeepSeekMath-Instruct 7B 基于 DeepSeekMath-Base 进行数学指令调整,其训练示例被随机连接,直到达到 4K 个 token 的最大上下文长度。以 256 的批处理大小和 5e-5 的恒定学习率对模型进行 500 步训练。
在 4 个英文和中文定量推理基准上评估模型在使用和不使用工具时的数学性能。将模型与领先模型进行对比:
• 闭源模型包括:(1)GPT 系列,其中 GPT-4(OpenAI,2023)和 GPT-4 Code Interpreter 是最强大的模型,(2)Gemini Ultra 和 Pro(Anil,2023),(3)Inflection-2(Inflection AI,2023),(4)Grok-1,以及中国公司最近发布的模型,包括(5)百川-3,(6)GLM 系列中最新的 GLM-4(Du,2022)。这些模型用于通用目的,其中大多数都经过一系列对齐程序。
• 开源模型包括:(1) DeepSeek-LLM-Chat 67B (DeepSeek-AI, 2024)、(2) Qwen 72B (Bai et al., 2023)、(3) SeaLLM-v2 7B (Nguyen et al., 2023) 和 (4) ChatGLM3 6B (ChatGLM3 Team, 2023) 等通用模型,以及在数学方面有所增强的模型,包括 (5) InternLM2-Math 20B,该模型以 InternLM2 为基础,经过数学训练后进行指令调整,(6) Math-Shepherd-Mistral 7B,将 PPO 训练 (Schulman et al., 2017) 应用于 Mistral 7B (Jiang et al., 2023),并采用过程监督奖励模型,(7) WizardMath 系列 (Luo et al., 2023) 使用 evolve-instruct(即使用 AI 进化指令的指令调整版本)和 PPO 训练改进 Mistral 7B 和 Llama-2 70B (Touvron et al., 2023) 中的数学推理能力,训练问题主要来自 GSM8K 和 MATH,(8) MetaMath 70B (Yu et al., 2023) 是在 GSM8K 和 MATH 的增强版本上微调的 Llama-2 70B,(9) ToRA 34B Gou et al. (2023) 是经过微调以进行工具集成数学推理的 CodeLlama 34B,(10) MAmmoTH 70B (Yue et al., 2023) 是在 MathInstruct 上进行指令调整的 Llama-2 70B。
如表所示,在禁止使用工具的评估设置下,DeepSeekMath-Instruct 7B 表现出强大的分步推理性能。值得注意的是,在竞赛级 MATH 数据集上,模型至少以绝对优势超过所有开源模型和大多数专有模型(例如 Inflection-2 和 Gemini Pro)9%。即使对于大得多的模型(例如 Qwen 72B)或通过以数学为中心的强化学习(例如 WizardMath-v1.1 7B)进行专门增强的模型也是如此。虽然 DeepSeekMath-Instruct 在 MATH 上可与中国专有模型 GLM-4 和 Baichuan-3 相媲美,但它的表现仍不及 GPT-4 和 Gemini Ultra。
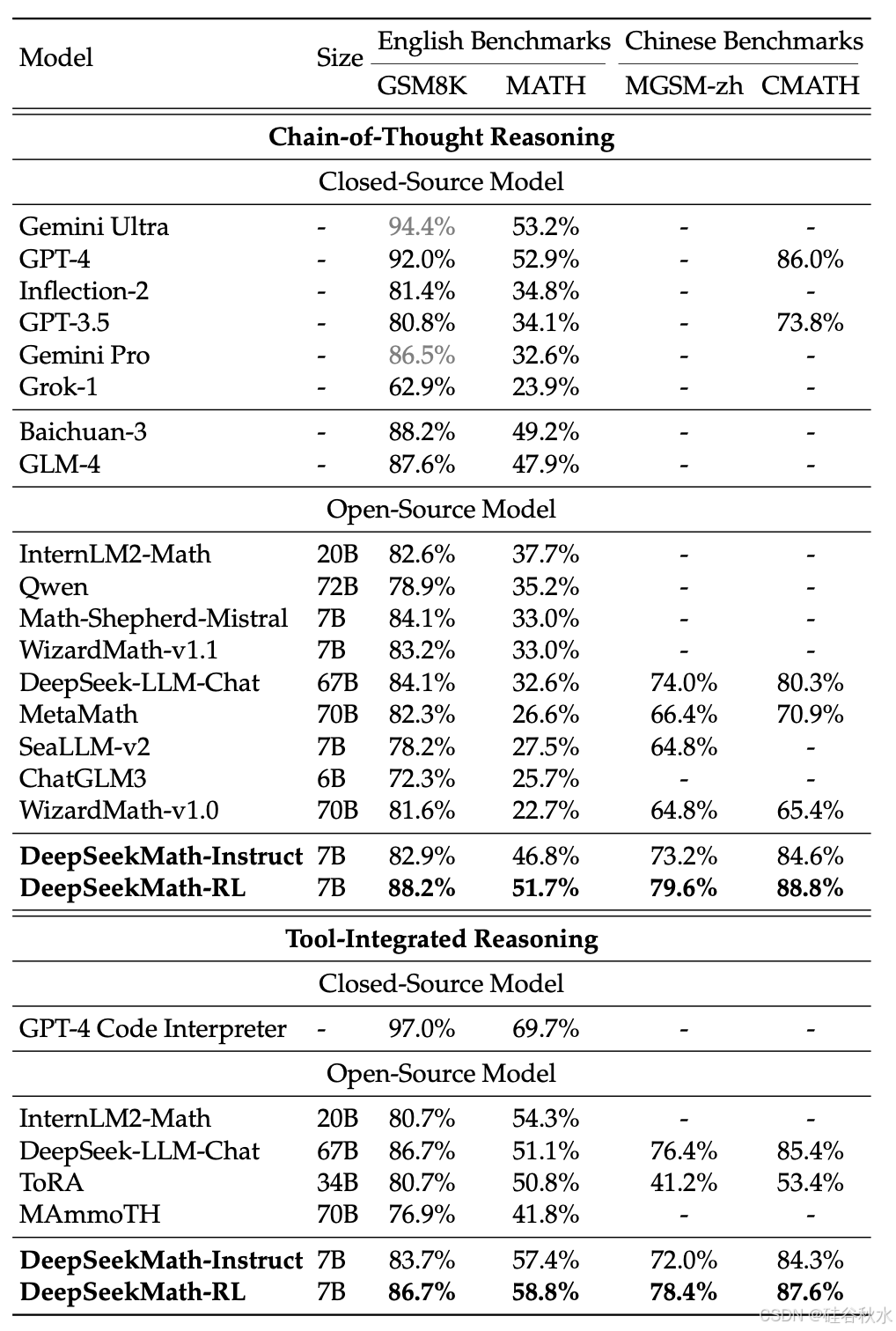
在评估设置下,模型可以整合自然语言推理和基于程序的工具来解决问题,DeepSeekMath-Instruct 7B 在数学上的准确率接近 60%,超越所有现有的开源模型。在其他基准测试中,模型与 DeepSeek-LLM-Chat 67B 相媲美,后者规模是 DeepSeek-LLM-Chat 67B 的 10 倍。
下面讲强化学习。
群体相对策略优化
强化学习 (RL) 已被证明能够有效地在监督微调 (SFT) 阶段之后进一步提高 LLM 的数学推理能力 (Luo et al., 2023; Wang et al., 2023b)。本文提出一种高效且有效的 RL 算法,即组相对策略优化 (GRPO)。
从 PPO 到 GRPO
近端策略优化 (PPO) (Schulman et al., 2017) 是一种 AC RL 算法,广泛应用于 LLM 的 RL 微调阶段 (Ouyang et al., 2022)。具体而言,它通过最大化以下替代目标来优化 LLM:
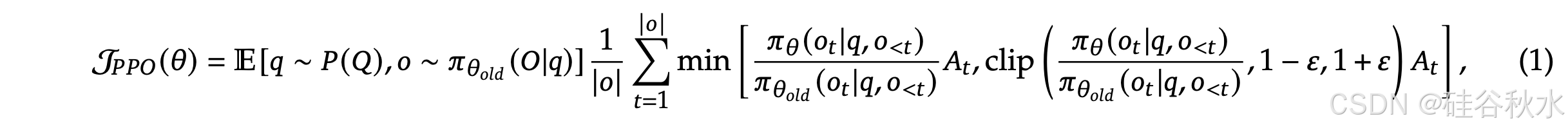
𝐴/𝑡 是优势,它是通过应用广义优势估计 (GAE) (Schulman et al., 2015) 计算得出的,基于奖励 { 𝑟≥ 𝑡 } 和学习的价值函数 𝑉/𝜓。因此,在 PPO 中,需要与策略模型一起训练价值函数,并且为了减轻奖励模型的过度优化,标准方法是在每个 token 奖励中添加来自参考模型的 token KL 惩罚 (Ouyang et al., 2022),即,
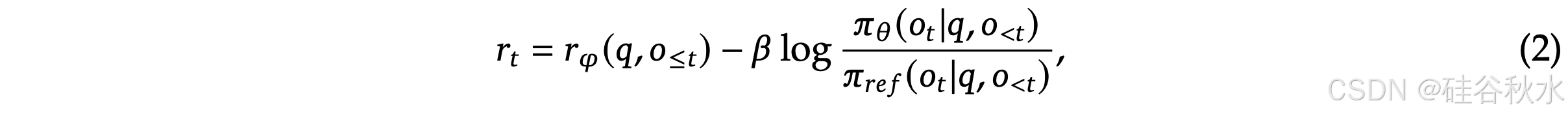
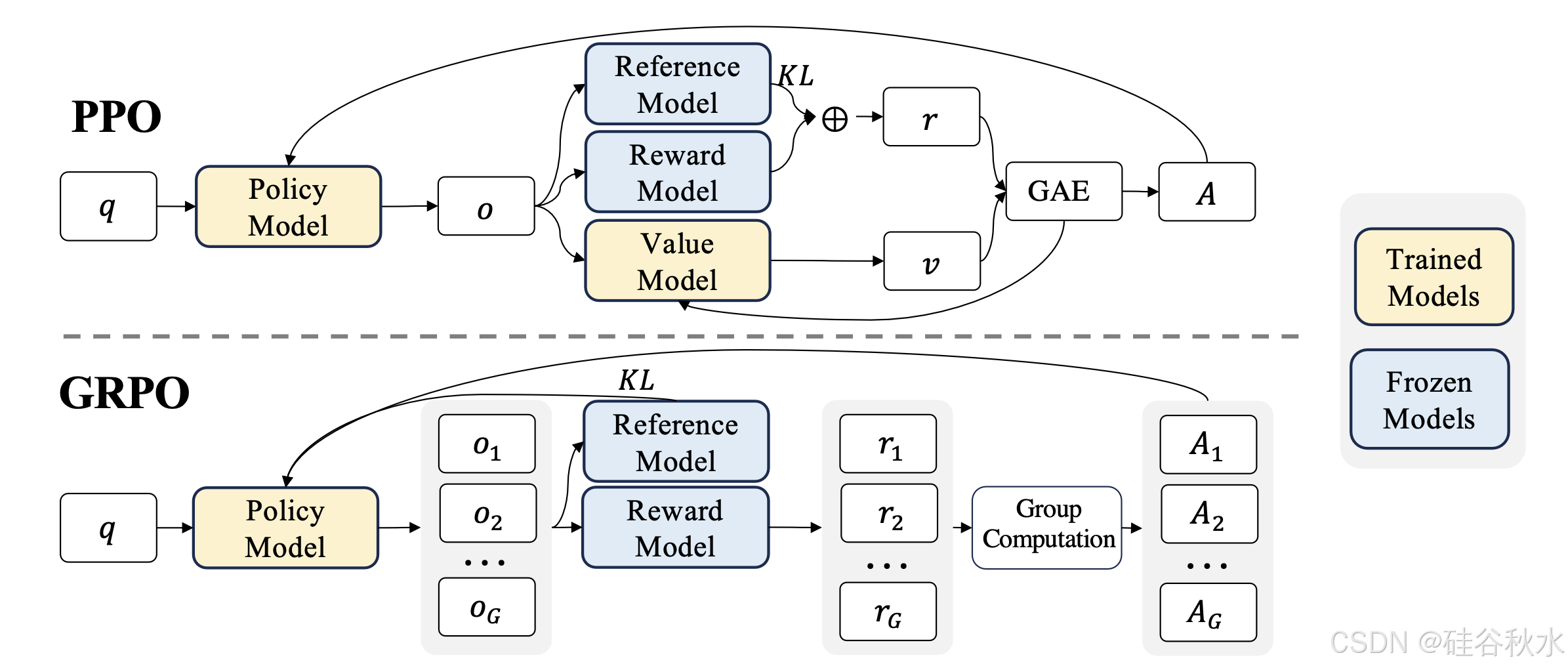
由于 PPO 中采用的价值函数通常是与策略模型大小相当的另一个模型,因此它会带来大量内存和计算负担。此外,在 RL 训练期间,为减少方差,价值函数被视作优势计算的基线。而在 LLM 环境中,奖励模型通常只为最后一个token分配奖励分数,这可能会让针对每个token准确的价值函数训练变得复杂。为了解决这个问题,如图所示,提出组相对策略优化 (GRPO),它避免像 PPO 中那样做额外价值函数近似,而是使用针对同一问题产生的多个采样输出平均奖励作为基线。
更具体地说,对于每个问题 𝑞,GRPO 从旧策略 𝜋_𝜃_𝑜𝑙𝑑 中采样一组输出 {𝑜_1, 𝑜_2, · · · , 𝑜_𝐺 },然后通过最大化以下目标来优化策略模型:
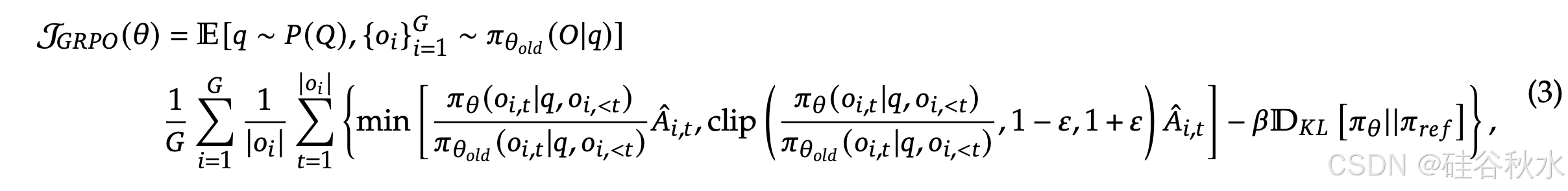
GRPO 利用组相对方式计算优势,这与奖励模型的比较性质非常吻合,因为奖励模型通常是在同一问题的输出比较数据集上训练的。另请注意,GRPO 不是在奖励中添加 KL 惩罚,而是通过将训练策略和参考策略之间的 KL 散度直接添加到损失中进行正则化,从而避免使优势 𝐴ˆ_𝑖,𝑡 的计算复杂化。
不同于(2)公式中的 KL 惩罚项计算,这里采用一个 保证为正的 KL 发散无偏估计:
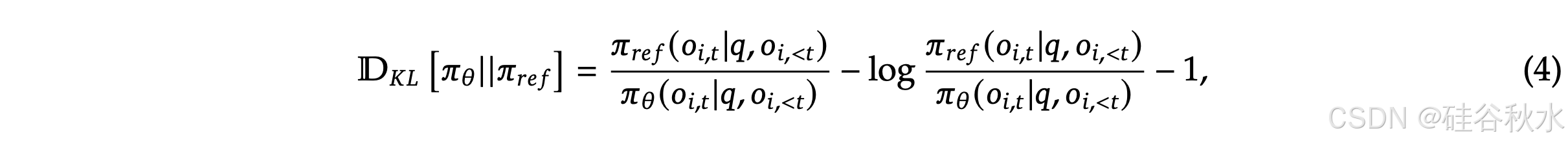
使用 GRPO 进行结果监督 RL
正式来说,对于每个问题 𝑞,从旧策略模型 𝜋_𝜃_𝑜𝑙𝑑 中抽取一组输出 {𝑜_1, 𝑜_2, · · · , 𝑜_𝐺 }。然后使用结果奖励模型(ORM)对输出进行评分,从而相应地产生 𝐺 个奖励 r = {𝑟_1, 𝑟_2, · · · , 𝑟_𝐺}。随后,通过减去组平均值并除以组标准差来对这些奖励进行归一化。结果监督在每个输出 𝑜_𝑖 结束时提供标准化奖励,并将输出中所有 tokens 的优势 𝐴ˆ_𝑖,𝑡 设置为标准化奖励,即𝐴ˆ_𝑖,𝑡 = ~𝑟_𝑖 = (𝑟𝑖 −mean®)/std®,然后通过最大化公式 (3) 中定义的目标来优化策略。
使用 GRPO 进行过程监督 RL
结果监督仅在每个输出结束时提供奖励,这可能不足以有效地监督复杂数学任务中的策略。 跟随 Wang (2023b) 的工作,探索过程监督,在每个推理步骤结束时提供奖励。正式地,给定问题 𝑞 和 𝐺 个采样输出 {𝑜_1, 𝑜_2, · · · , 𝑜_𝐺 },使用过程奖励模型(PRM)对输出的每个步骤进行评分,从而产生相应的奖励:R = {{𝑟_1^𝑖𝑛𝑑𝑒𝑥(1) , · · · , 𝑟_1^𝑖𝑛𝑑𝑒𝑥(K_1) }, · · · , {𝑟_𝐺^𝑖𝑛𝑑𝑒𝑥(1), · · · , 𝑟_𝐺^𝑖𝑛𝑑𝑒𝑥(K_G) }},其中𝑖𝑛𝑑𝑒𝑥 (𝑗) 是第 𝑗 步的结束token索引,𝐾_𝑖 是第 𝑖 步输出中的总步数。还使用平均值和标准差对这些 𝑖𝑛𝑑𝑒𝑥(𝑗) 奖励进行归一化,即 𝑟~_iindex(j) = (𝑟_iindex(j) - mean®)/std®。随后,过程监督将每个 token 的优势计算为以下步骤中标准化奖励的总和,即 ˆ𝐴𝑖,𝑡 = sum (~𝑟_i^index(j)) | _index(j) ≥ 𝑡,然后通过最大化公式 (3) 中定义的目标来优化策略。
使用 GRPO 的迭代强化学习
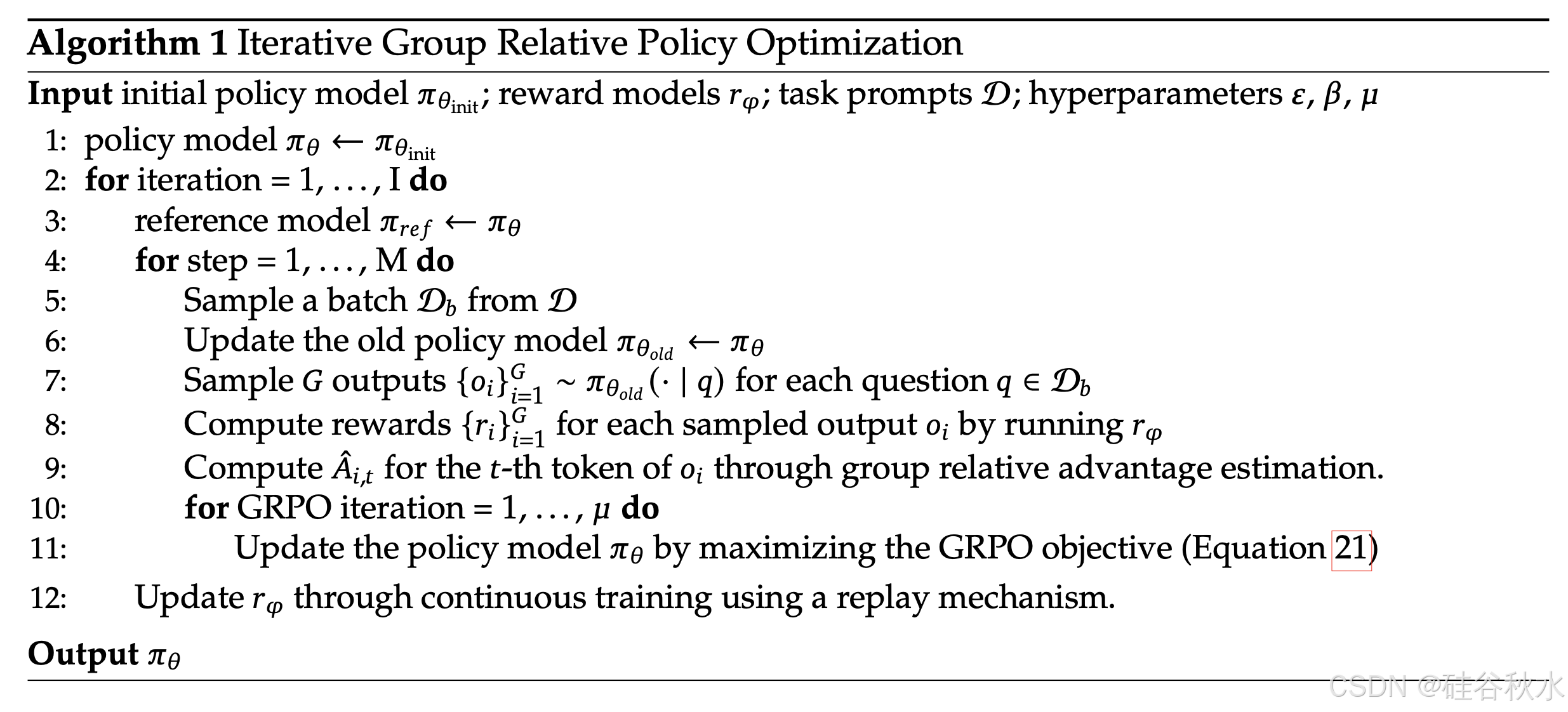
随着强化学习训练过程的进展,旧的奖励模型可能不足以监督当前的策略模型。因此,探索使用 GRPO 的迭代强化学习。如下算法所示,在迭代 GRPO 中,根据策略模型的采样结果为奖励模型生成新的训练集,并使用包含 10% 历史数据的重放机制不断训练旧的奖励模型。然后,将参考模型设置为策略模型,并使用新的奖励模型不断训练策略模型。
训练和评估 DeepSeekMath-RL
下面基于 DeepSeekMath-Instruct 7B 进行 RL。RL 的训练数据是来自 SFT 数据、与 GSM8K 和 MATH 相关的思路链格式问题,其中包含约 144K 个问题。排除其他 SFT 问题,调查 RL 对整个 RL 阶段缺乏数据的基准影响。按照 (Wang et al., 2023b) 构建奖励模型的训练集。基于 DeepSeekMath-Base 7B 训练初始奖励模型,学习率为 2e-5。对于 GRPO,将策略模型的学习率设置为 1e-6。KL 系数为 0.04。对于每个问题,抽样 64 个输出。最大长度设置为 1024,训练批次大小为 1024。策略模型在每个探索阶段后仅进行一次更新。在 DeepSeekMath-Instruct 7B 之后的基准上对 DeepSeekMath-RL 7B 进行评估。对于 DeepSeekMath-RL 7B,具有思维链(COT)推理的 GSM8K 和 MATH 可以视为域内任务,而所有其他基准都可以视为域外任务。
上表已经展示在英文和中文基准上具有思维链推理和工具-集成推理的开源和闭源模型性能。1)DeepSeekMath-RL 7B 在利用思维链推理的 GSM8K 和 MATH 上分别达到 88.2% 和 51.7% 的准确率。这一性能超过 7B 到 70B 范围内的所有开源模型,以及大多数闭源模型。 2)至关重要的是,DeepSeekMath-RL 7B 仅使用 GSM8K 和 MATH 的链式指令调优数据进行训练,从 DeepSeekMath-Instruct 7B 开始。尽管其训练数据范围有限,但它在所有评估指标上均优于 DeepSeekMath-Instruct 7B,展示了强化学习的有效性。
讨论一下 RL 的训练方法。
提供一个统一的范式来分析不同的训练方法,例如 SFT、RFT、DPO、PPO、GRPO,并进一步进行实验来探索统一范式的因素。一般来说,关于一种训练方法的参数 𝜃 梯度可以写成:
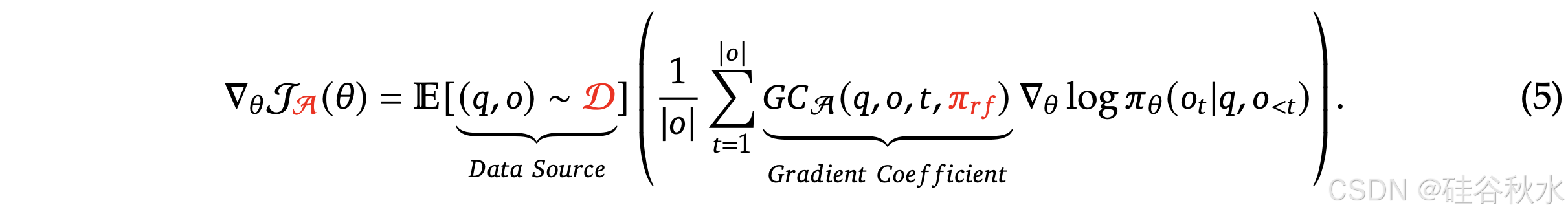
存在三个关键组件:1)数据源 D,它决定训练数据;2)奖励函数 𝜋/𝑟𝑓,它是训练奖励信号的来源;3)算法 A:它将训练数据和奖励信号处理为梯度系数 𝐺𝐶,该梯度系数决定了数据的惩罚或强化程度。基于这种统一范式的几种代表性方法如下:
• 监督微调 (SFT):SFT 在人类选择的 SFT 数据上微调预训练模型。
• 拒绝抽样微调 (RFT):RFT 在基于 SFT 问题从 SFT 模型中采样的过滤输出上进一步微调 SFT 模型。RFT 根据答案的正确性过滤输出。
• 直接偏好优化 (DPO):DPO 使用成对 DPO 损失,通过对从 SFT 模型中采样的增强输出进行微调来进一步完善 SFT 模型。
• 在线拒绝采样微调 (Online RFT):与 RFT 不同,Online RFT 使用 SFT 模型启动策略模型,并使用从实时策略模型采样的增强输出进行微调来完善它。
• PPO/GRPO:PPO/GRPO 使用 SFT 模型初始化策略模型,并使用从实时策略模型采样的输出来强化它。
如表总结这些方法的组成部分:


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 45
45 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)