AI及数据中心行业分析完整版Part4-DeepSeek模型分析+AI算法发展需求及投资前景
DeepSeek模型分析+AI算法发展需求及投资前景概述
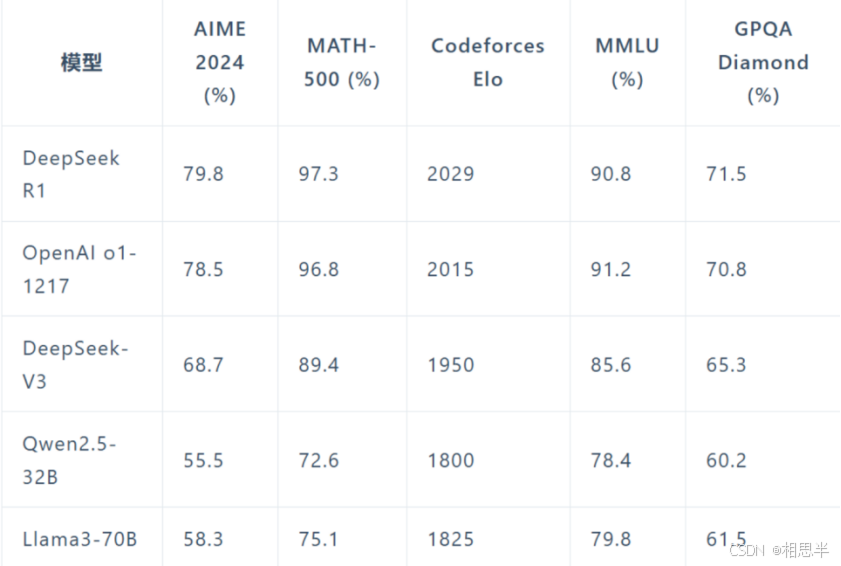
DeepSeek大模型与其他热门大模型(如Open AI o1)的能力对比:
(图源网络,侵删)
Deepseek-国产AI的优化
“成本骤降:AI界的“拼多多”
一、DeepSeek的R1的预训练费用只有557.6万美元,及约2000个英伟达专用芯片就完成了新模型的训练,而OpenAI训练ChatGPT-4o所花费的成本高达7800万美元甚至是1亿美元,还需要上万张GPU芯片;DeepSeek的R1仅是OpenAI GPT-4o模型训练成本的不到十分之一。
二、多项创新技术:
历经推理导向强化学习(Reasoning-oriented Reinforcement Learning)重点提升模型在推理密集型任务(如编码、数学、科学和逻辑推理)上的性能,添加了语言一致性奖励;
拒绝采样和监督微调( Rejection Sampling and Supervised Fine-Tuning )可以利用人类的先验知识来引导模型,又可以发挥强化学习的自学习和自进化能力;
全 场 景 强 化 学 习(Reinforcement Learning for all Scenarios) 的多阶段训练解决 DeepSeek-R1-Zero的缺陷,提升模型的应用能力
三、超高的性能
DeepSeek-R1展现出了与OpenAI o1相当甚至在某些方面更优的性能。在MATH基准测试上,R1达到了77.5%的准确率,与o1的77.3%相近;在更具挑战性的AIME 2024上,R1的准确率达到71.3%,超过了o1的71.0%。在代码领域,R1在Codeforces评测中达到了2441分的水平,高于96.3%的人类参与者。”
版权声明:上文最近一处双引号标记处为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
AI算法优化展现良好的投资前景
1.医疗健康:
智能诊断与治疗: AI通过分析医学影像、基因组数据和电子病历,辅助医生进行疾病的早期筛查和精准诊断,提高诊断效率和准确性。
个性化医疗: 基于患者的健康数据,AI能够制定个性化的治疗方案,提升治疗效果和患者满意度。
2. 金融服务:
风险管理: AI通过大数据分析和机器学习,帮助金融机构识别和预测潜在风险,优化风险控制策略。
智能投顾: AI根据客户的财务状况和投资偏好,提供个性化的投资建议,提升投资决策的科学性和准确性。
3. 自动驾驶:
环境感知与决策: AI通过传感器和深度学习算法,实现对周围环境的实时感知和分析,支持自动驾驶系统的决策制定。
路径规划与控制: AI根据交通状况和道路信息,优化行驶路径和控制策略,提高驾驶安全性和效率。
4. 智能制造:
生产优化: AI通过实时监控生产线,分析数据,优化生产流程,提高生产效率和产品质量。
预测性维护: AI分析设备运行数据,预测设备故障,提前进行维护,减少停机时间和维修成本

-
人工智能行业发展的需求
AI训练离不开海量优质数据及算力
大规模数据集是深度学习的核心:
深度学习模型,尤其是神经网络,有着数百万、甚至数十亿的参数,它们需要通过大量的数据来进行优化。数据越丰富,模型就能从中学习到更复杂的特征和模式,从而提高准确性。
复杂的计算需求:
训练深度学习模型时,特别是大型的神经网络(如BERT、GPT系列等),涉及大量矩阵运算和参数(通过tokens/tokenization输入调整参数值)更新。在训练过程中,模型需要处理和计算海量的数据和参数,这就需要高效的计算资源,尤其是GPU(图形处理单元)和TPU(张量处理单元),它们能够并行处理复杂的运算任务。
数据为模型提供了学习的基础和依据,而算力则保证了模型能够在合理的时间内完成训练和推理。两者的紧密结合,促使AI技术能够在各个领域取得突破并实现实际应用。

ImageNet classification with deep convolutional neural networks
-by Hinton
该论文说明了训练深度学习网络模型需要大量的数据和高效的算力。
即该研究首次通过大规模数据和算力显著提升了图像分类性能:
数据量:使用ImageNet LSVRC-2010竞赛中的120万张高分辨率图像,覆盖1000个类别。
算力需求:模型包含6000万参数和65万个神经元,训练过程中通过GPU加速卷积运算以缩短时间,并采用了非饱和神经元(ReLU)优化计算效率。
效果验证:在测试集上达到17.0%的top-5错误率,显著优于传统方法。
此实验直接证明,海量数据与高性能计算是深度学习突破的关键。
 (摘录自原文图片,侵删)
(摘录自原文图片,侵删)
本文结合部分deepseek,kimiai,chatgpt整理分析而成,仅供参考和作为读者灵感分析的启发。(若有侵权请联系作者删除~)
本贴的其他相关学习笔记资料可以通过订阅专栏获取,喜欢的小伙伴可以多多点赞+关注呀!后续会 持续更新相关资源的~
最后,感谢每一位阅读这篇文章的朋友,你们的反馈对我来说非常宝贵。如果有任何问题或建议,请随时告诉我。让我们一起学习和进步吧!如果您喜欢我的内容,别忘了点赞和关注哦,我会定期分享更多有价值的信息。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)