deepseek janus本地环境部署
DeepSeek Janus 是由深度求索(DeepSeek)公司开发的 AI 智能体开发框架,旨在帮助开发者更高效地构建和部署智能体(AI Agents)。它通过模块化设计与工具集成,降低开发门槛,适用于代码生成、数据分析、自动化办公等多种场景,推动AI技术的实际应用。此外,Janus项目中还提供了前端调用脚本,我们可以按照如下流程开启前端并与Janus进行对话。安装 pip 依赖: 激活环境后
deepseek janus本地环境部署
DeepSeek Janus 是由深度求索(DeepSeek)公司开发的 AI 智能体开发框架,旨在帮助开发者更高效地构建和部署智能体(AI Agents)。它通过模块化设计与工具集成,降低开发门槛,适用于代码生成、数据分析、自动化办公等多种场景,推动AI技术的实际应用。
部署步骤
- git 克隆 HunyuanVideo 仓库到本地
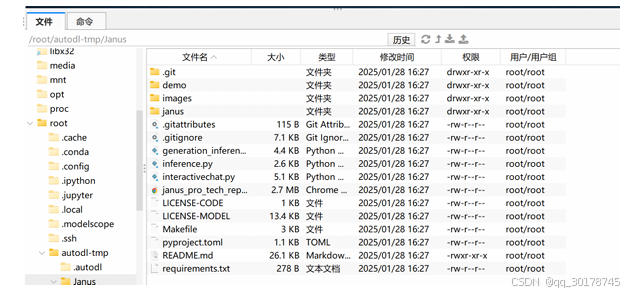
git clone https://github.com/deepseek-ai/Janus.git
2. 准备 Conda 虚拟环境: 使用以下命令创建 Conda 环境:
conda create -n janus python=3.9
3.激活环境: 创建环境后,激活它
conda init
source ~/.bashrc
conda activate janus
安装 pip 依赖: 激活环境后,安装所需的 Python 依赖
进入janus目录下安装依赖
pip install -e .
考虑到后续需要在代码环境中调用Janus,这里还需要下载JupyterLab,并配置kernel:
conda install jupyterlab
conda install ipykernel
python -m ipykernel install --user --name janus --display-name "Python (janus)"
打开Jupyter
jupyter lab --allow-root
- 下载预训练模型
这里我们考虑在项目主目录下创建models文件夹,用于保存Janus-Pro-1B和7B模型权重。考虑到国
内网络环境,这里推荐直接在Modelscope上进行模型权重下载。
Janus-Pro-1B模型权重:
https://www.modelscope.cn/models/deepseek-ai/Janus-Pro-1B
Janus-Pro-7B模型权重:
https://www.modelscope.cn/models/deepseek-ai/Janus-Pro-7B
安装modelscope
pip install modelscope
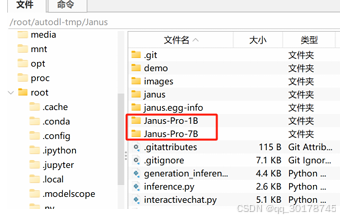
创建权重保存文件夹
cd /root/autodl-tmp/Janus
mkdir ./Janus-Pro-1B
mkdir ./Janus-Pro-7B
modelscope download --model deepseek-ai/Janus-Pro-1B --local_dir ./Janus-Pro-1B
本地调用
本部分内容详见Jupyter代码文件:
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images
model_path = "./Janus-Pro-7B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
image = "./pic1.png"
question = "explain this meme"
conversation = [
{
"role": "<|User|>",
"content": f"<image_placeholder>\n{question}",
"images": [image],
},
{"role": "<|Assistant|>", "content": ""},
]
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
inputs_embeds
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
此外,Janus项目中还提供了前端调用脚本,我们可以按照如下流程开启前端并与Janus进行对话。
安装相关依赖
pip install -e .[gradio]
修改推理脚本
若要调用本地模型进行推理,则需要修改对应的前端脚本。打开
./demo/app_januspro.py 文件,
并在15行处修改为当前本地模型下载地址: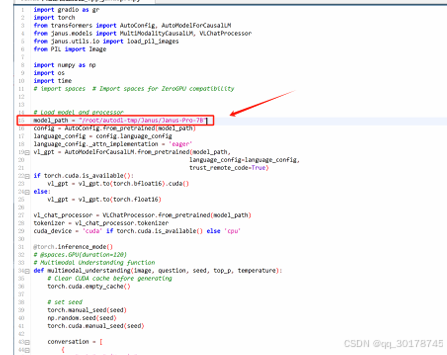
保存并退出即可。
然后添加至
janus/lib/python3.9/site-packages/gradio 文件夹内:
开启前端服务
然后即可开启前端服务:
python demo/app_januspro.py
即可得到网页版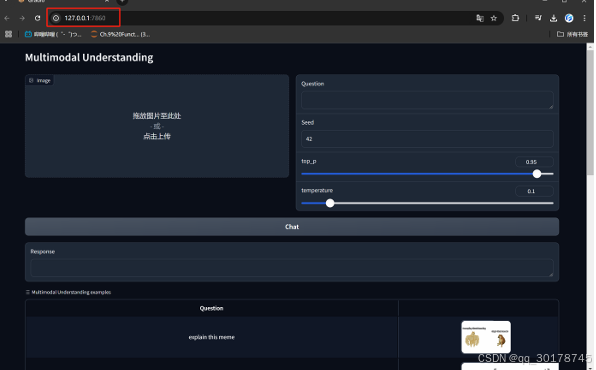

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)