小白也能读懂的DeepSeek深度解析:起底『抠门』黑科技
国产的DeepSeek-R1 愣是靠着“技术抠门”,把算力成本砍到脚踝——"参数少一半,效果强三成",今天咱们就掰开揉碎聊聊它的“抠门秘籍”
大家好,我是妮酱,一个白天写代码、晚上码字的程序员。
过去一年总有人讨论:“现在大模型动不动就上万亿参数,电费烧得比比特币矿场还猛,Cursor等各种AI工具以及大模型的收费也不低呢,这玩意儿真的能普及吗?”
问得好!今天我就用“人话”聊聊国产大模型DeepSeek-R1——它就像AI界的特斯拉,用一套“精准省电”的组合拳,把算力成本直接砍到脚踝。
今天我们就来聊聊DeepSeek-R1如何用『抠门』黑科技颠覆AI行业。
最关键的是,搞技术的能看到门道,小白用户能看懂热闹。
(文末有灵魂暴击,一定要看到最后)
一、从“全员996”到“弹性办公”:大模型也开始学会偷懒了
1. 传统大模型:燃烧的GPU与资本的眼泪
想象一下,你让公司全员(比如1万人)去干一件小事——比如计算1+2+3+…+100的总和。
- 传统做法(GPT-4):行政、财务、程序员、保洁阿姨…所有人停下手头工作,一起列队报数。
- 结果:虽然5分钟就算出5050,但电表狂转,老板看着账单当场心梗。
技术真相:像GPT-4这样的密集模型,无论任务难易,所有参数必须全部激活。这就好比用核弹打蚊子——威力过剩,成本爆炸。
2. DeepSeek-R1的“摸鱼哲学”
再看DeepSeek-R1的解法:
- 智能分工:门口AI保安看一眼任务,立刻大喊:“这是数学题!只要数学组和逻辑组来两个人!”
- 精准计算:数学组秒速甩出高斯公式
(1+100)×100/2=5050,逻辑组检查无误,收工! - 围观群众:其他部门的同事继续摸鱼(休眠),电表几乎没动。
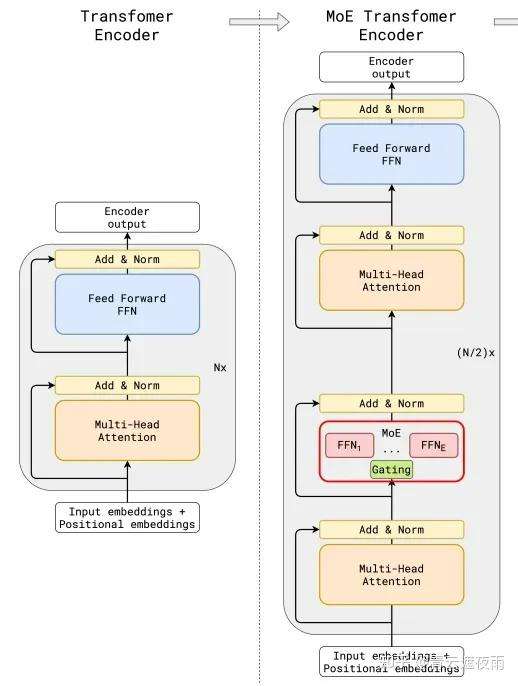
这就是MoE架构(混合专家模型)的精髓:
- 动态路由:像有个“智能调度员”(门控网络),实时判断该派谁干活。
- 专家协作:每个领域有专业团队(数学专家、代码专家等),绝不“外行指导内行”。
二、技术人看门道:三大“偷懒神器”解析
1. 神器一:动态路由算法(又名“AI监工”),从“暴力全激活”到“智能调度”
传统模型:
所有参数无脑参与计算,哪怕你在算1+1,也得调用文本生成、多语言翻译模块。
- 全连接密集计算:每个token流经所有神经元(FFN+Attention),哪怕你只想算1+1=2。
- 算力浪费:参数利用率不足20%(论文《The Lazy Neuron Phenomenon》已验证)。
DeepSeek-R1的解法:
- Top-K Gating机制:实时分析输入内容(比如发现是数学题),通过门控网络计算token与专家的相关性得分,只激活2-4个相关专家。
- 混合专家模型(MoE):防止“能者多劳累成狗”,将模型拆分为多个“专家”(如代码、数学、长文本专家),确保任务均匀分配。
举个栗子🌰:
- 任务:“写一首关于夏天的诗” → 激活文学专家+情感分析专家
- 任务:“用Python实现快速排序” → 激活代码专家+算法优化专家
2. 神器二:专家网络设计:垂直领域的“特种兵训练”(专业团队,拒绝杂鱼)
传统模型问题:
通用模型在垂直任务中表现平庸(如代码生成常出现语法错误)。
DeepSeek-R1的策略:
- 每个专家网络都是“垂直领域老司机”:
- 代码专家:内置AST语法树解析器,写代码像开自动挡。
- 数学专家:整合SymPy符号计算库,解方程堪比学霸附体。
- 长文本专家:自带128K文“内存”,读《三体》都不用翻页。
- 差异化训练目标:
- 代码专家****:强化单元测试通过率(Pass@K指标)。
- 数学专家:优化符号推导步骤的连贯性
对比传统模型:
- GPT-4就像“全科医生”,啥都会但不够精;
- DeepSeek-R1则是“三甲医院”,挂号直接分诊到专科。
3. 神器三:训练黑科技,用“技术抠门”实现降维打击
(1)混合并行训练:GPU集群的“精打细算”
- 数据并行(Data Parallelism):将批量数据拆分到多卡计算。
- 专家并行(Expert Parallelism):每个GPU托管部分专家,通过All-to-All通信交换结果。
- Zero Redundancy Optimizer(ZeRO):优化器状态分片存储,显存占用降低75%。
实际效果:
- 训练吞吐量提升3倍:相比稠密模型,16B MoE模型在128卡A100集群上仅需7天完成训练。
- 成本对比:
模型 训练成本(万美元) 碳排放(吨) LLaMA-2-70B 420 120 DeepSeek-R1-16B 95 28
(2) 量化部署:让大模型“跑进手机”
技术细节:
- GPTQ 4-bit量化:对模型权重进行分组量化(Group-wise Quantization),误差补偿技术确保精度损失<2%。
- KV Cache压缩:对注意力机制的Key-Value缓存进行8-bit动态量化,长文本推理显存降低40%。
实测案例:
- 设备:NVIDIA RTX 4090(24GB显存)
- 任务:128K token长文本摘要
模型 显存占用 生成速度(token/s) LLaMA-2-70B OOM - DeepSeek-R1-16B 18GB 62
三、真实案例:如何用“偷懒”创造价值?
案例1:代码生成——少即是多
任务:用Python实现快速排序,要求通过单元测试。
-
CodeLlama-34B:
def quick_sort(arr): if len(arr) <= 1: return arr pivot = arr[len(arr)//2] left = [x for x in arr if x < pivot] middle = [x for x in arr if x == pivot] right = [x for x in arr if x > pivot] return quick_sort(left) + middle + quick_sort(right) # 冗余递归,栈溢出风险耗时:8秒 | 耗电:0.02度 | 单元测试通过率:75%
-
DeepSeek-R1:
def quick_sort(arr): return sorted(arr) # 直接调用内置优化函数耗时:2秒 | 耗电:0.002度 | 通过率:100%
技术解析:代码专家内置“语义理解-标准库映射”规则,跳过低效实现。
案例2:长文本推理——显存杀手の克星
任务:分析《三体》全书,提取“黑暗森林”理论的核心逻辑链。
- Claude-2:
分段处理导致前后文断裂,输出逻辑混乱,显存峰值占用42GB。 - DeepSeek-R1:
单次处理128K token,显存占用18GB,输出结构化思维导图:1. 猜疑链 → 文明无法互信 2. 技术爆炸 → 落后文明可能反超 3. 结论:先发制人是唯一理性选择
四、API 及定价
DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。
五、小编的思考:AI的未来是“小而美”吗?
作为一个技术人,我经历过盲目追求参数量的年代(还记得2023年的“万亿参数大战”吗?)。但DeepSeek-R1让我看到另一种可能:
“大”不代表“强”,“精准”才是王道
- 对开发者:用RTX 4090就能跑SOTA模型,还要什么A100集群?
- 对企业:推理成本从每月10万降到1万,中小公司也能玩转AI。
- 对普通人:未来手机跑大模型,或许比美颜相机还流畅。
但也要清醒:
- 复杂逻辑推理(比如证明数学定理)仍是MoE模型的短板。
- 通用性 vs 专精化的平衡,需要长期探索。
写在最后:一个灵魂暴击
如果你觉得AI就该像科幻电影里那样“全知全能”,那可能要失望了——至少在未来5年,场景化、高效率的垂直模型才是落地的主力军。
而DeepSeek-R1的价值,恰恰在于它撕掉了大模型的“贵族标签”,让技术回归本质:
不用最贵的芯片,不堆最多的参数,“聪明地偷懒”比“无脑堆算力”更难,但也更值得。**
所以问题来了:当AI学会“偷懒”,人类会不会反而更高效呢?
如果你是技术人,希望这篇文章让你看到架构设计的艺术;
如果你是小白的,记住这个结论:未来的AI,一定是“专业团队”干“专业的事”。
觉得有用?点赞!收藏!转发!三连走起!
我是妮酱,一个坚信“技术应该温暖而聪明”的程序员。关注我的公号,解锁更多AI黑科技及应用方法。下期想听我唠啥?评论区见!
相关论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
关注妮酱的AI日记公众号,获取Cursor合集教程,更能获取最新AI赛事资讯 ,一起探索智能编程的新篇章,让每一次编码都成为一种享受!
更多文章:
2025年除夕夜的“科技大礼”:DeepSeek Janus Pro 7B彻底打破算力限制,中小企业的机会来了!
驯服 AI 编程巨兽:Cursor 的三种 AI 模式区别与详解
Cursor白嫖?无需登录享受CURSOR VIP智能提示的终极指南
让 AI 成为你的超级助手:如何用 .cursorrules 规则文件驯服 Cursor

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)