DeepSeek实用小技巧--基于DeepSeek打造私有知识库
目录导航栏
引言
当前,个人构建私有知识库的需求日益增长,但常受限于数据处理效率、模型部署门槛与硬件成本。本文以DeepSeek大模型为核心,通过三步实现轻量化知识库搭建:
首先利用CherryStudio高效调用大模型API,完成非结构化数据的智能解析与语义化处理;
继而采用量化模型,转化本地文档数据;
最终通过本地化部署确保隐私数据零泄露。实践表明,该方案将知识检索准确率提升至100%,且支持docx、xlsx、pptx等多格式知识检索,为个人学习助手、研究资料库等场景提供低成本、高可用的技术路径。这为普通开发者驾驭大模型技术提供了轻量级实践范本。
(该引言由deepseek生成)
该文章用于记录作者的学习历程。
一、获取deepseek API
1、为什么选择硅基流动
1、目前deepseek官网虽然也开放了API接口,但有用户反馈官网无法注册,或注册后无法充值使用API,而硅基流动目前表现暂无异常
2、硅基流动如果是新用户就自动注册并赠送2000w tokens的调用额度,对初学者较为友好,足够学习使用
3、作者文中放置的硅基流动登陆链接,有作者账号的邀请码,邀请新用户作者也能获取免费额度(嘿嘿嘿~)
4、为读者考虑,等读者账号中免费额度用完后,相信大家长辈也有手机号(这是其他平台不具备的优势,大家懂的都懂~)
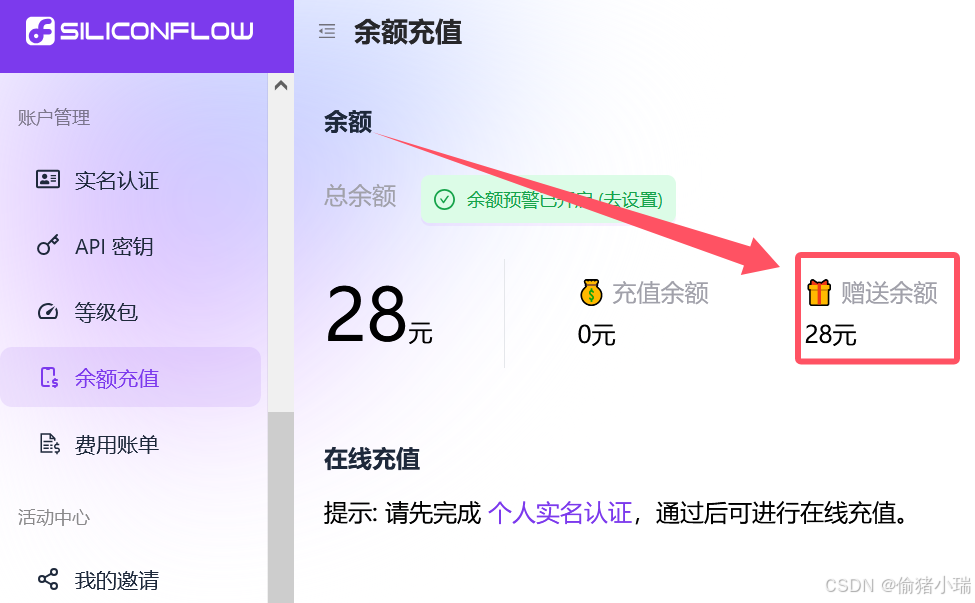

2、注册硅基流动
进入 硅基流动登录界面 ,输入手机号并获取验证码,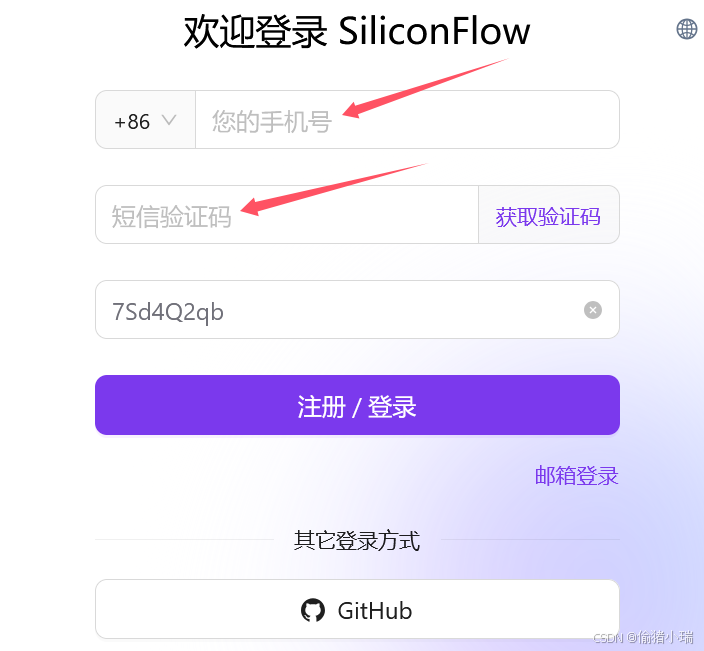
3、获取API密钥
点击左侧【API密钥】->【新建API密钥】
输入一个名称,作为密钥用途的补充说明,以便后续密钥过多时区分密钥具体用途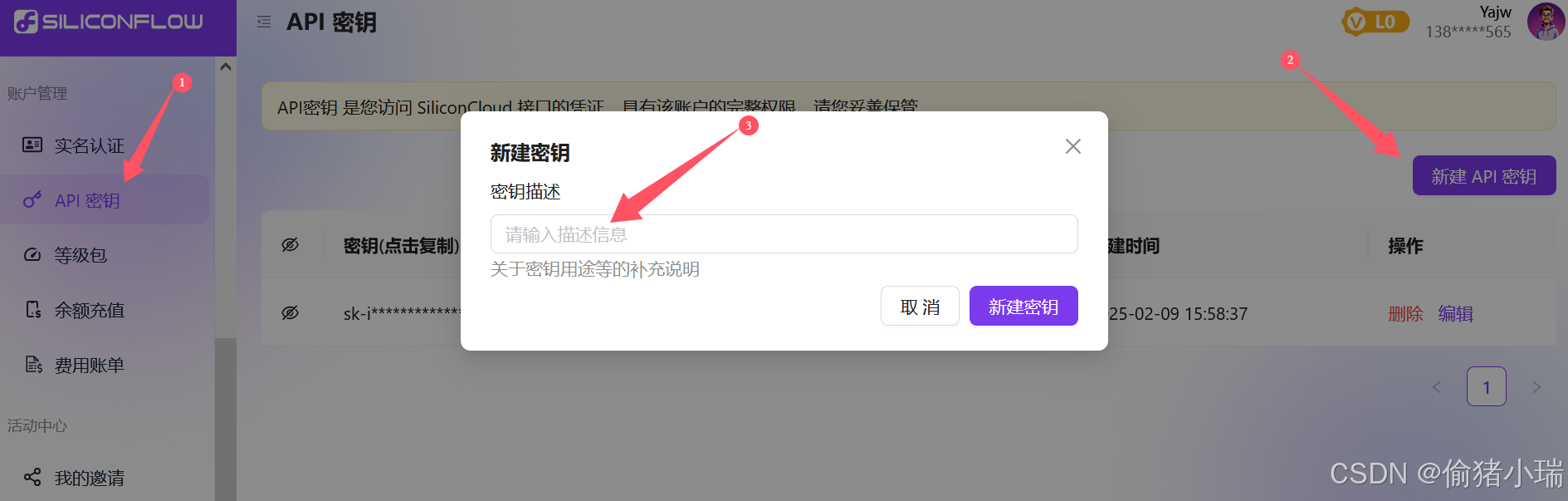
二、选择AI桌面客户端
1、为什么选择Cherry Studio
据说这个是目前最成熟,且用户量最大的一个,重要的是它开源免费
2、下载并安装
进入Cherry Studio下载界面 ,点击下载,官网会根据电脑配置推荐合适的版本,在下方也会有可选版本。
下载完成后点击安装,记得选好自己想要的安装路径。
3、Cherry Studio界面简讲(篇幅较长可跳过)
①新对话
首先是对话框界面下的第一个图标【新话题】,可以理解为deepseek手机端上,开启一个新对话 比如我们现在开启一个新话题后,助手这里就显示了2
比如我们现在开启一个新话题后,助手这里就显示了2
切换到话题栏,就可以做生成、编辑、清空话题等操作
②模型选择
第二个图标这可以进行模型的切换,比如阿里的千问、deepseek的切换
在对话前,需要配置好相应的密钥,不然会报错,这也是我先列出密钥申请操作的原因
③清空消息
将当前对话记录删除,注意和后方【清除上下文】按钮做区分
点击清空后,刚才的对话就被清除了
④设置
设置按钮点击后,会在左侧展开一个设置界面,这里有些设置会与左侧部分功能重合,放在对话框设置更方便用户操作
----模型温度
正如说明提到的一样,主要是设置模型回答问题时的多样新、创造性
如果感觉模型回答问题回答的不够创新、太死板,就将温度设置大一些
如果感觉回答的太发散了,就将温度拉小一点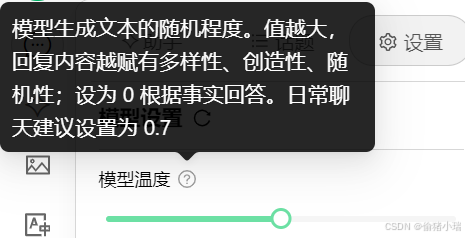
----上下文数
就是模型的记忆能力,模型的记忆能力并不是像人一样的记忆,而是当你提问的时候,它会将上面的对话一起发送过去,这个内容就是上下文
比如默认设置是5,它就会记住5轮对话,在你提问时,它会将之前5轮对话的问题和答案一起发送过去,针对这几轮对话做一个答复,这就形成了模型的记忆能力
如果设置为0,那相当于每次对话都是一个新问题,不会对之前的问题有相关记忆
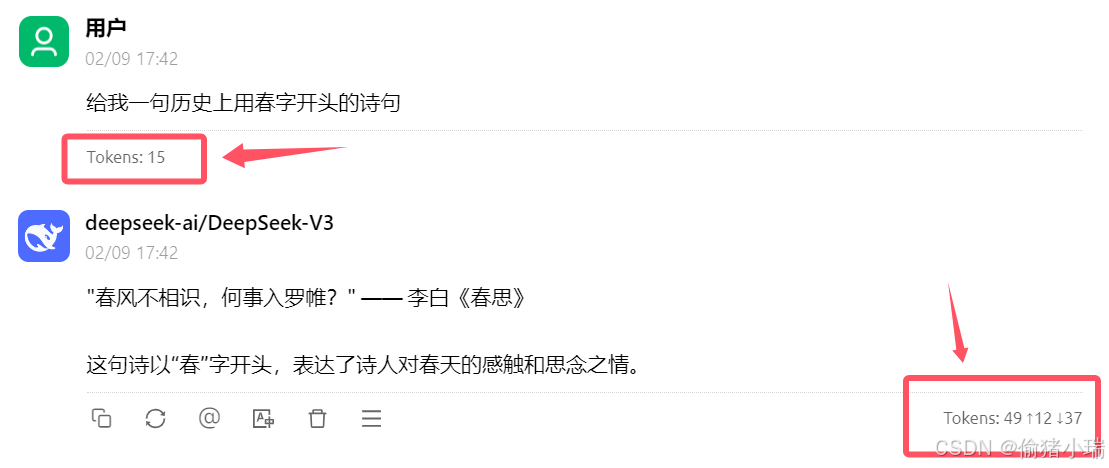
注意:还记得之前提到的2000w tokens么,很多模型是根据token去计费的,这里设置的越高,当对话丰富起来之后,那每次提问消耗的token额度就不单单是一个提问那么简单了。
所以提问时注意结合【新话题】【清除上下文】一起使用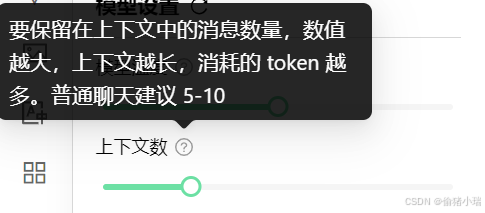
----流式输出
以对话的形式输出
----消息长度限制
可以开也可以不开
这个也是和token有关,能够限制单次对话的交互长度
----显示预估token数
如果担心单次对话消耗过大,可以开启该按钮
⑤知识库
可添加选择对应知识库
⑥上传图片或文档
可选择想要上传的图片文档进行提问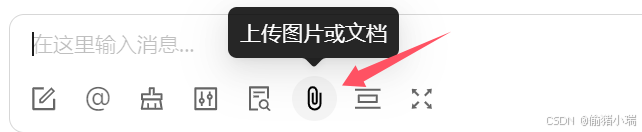
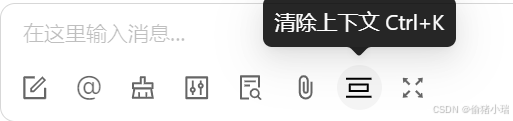
⑦清除上下文
这个主要是和模型的记忆能力有关
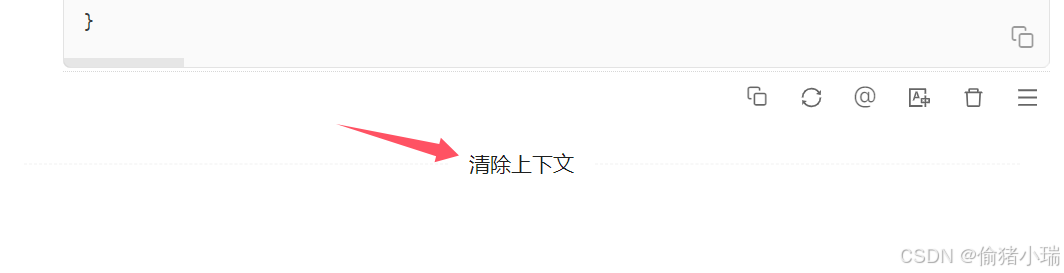
点击【清除上下文】,界面会有相应提示展现,表示已清除上下文,这样下一次对话,模型就 “不记得” 之前的问题了
之前的对话记录不会删除,用户还能看见
4、配置API密钥
①回到之前的硅基流动,点击密钥即可复制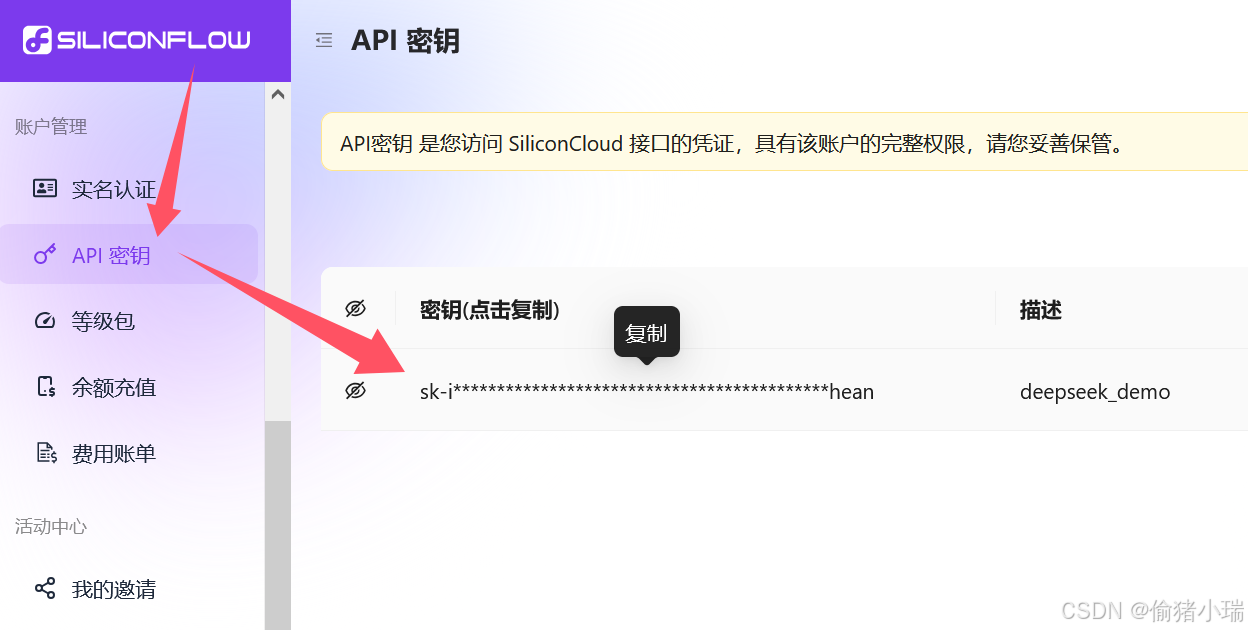
②进入Cherry Studio界面,点击设置点击硅基流动,并粘贴密钥,api地址保持默认
由于我们是在硅基流动申请的API密钥,所以这里选择硅基流动,如若读者在deepseek申请的API密钥,这里得选择深度求索
简而言之,在那个平台申请API密钥,这里据选择哪个平台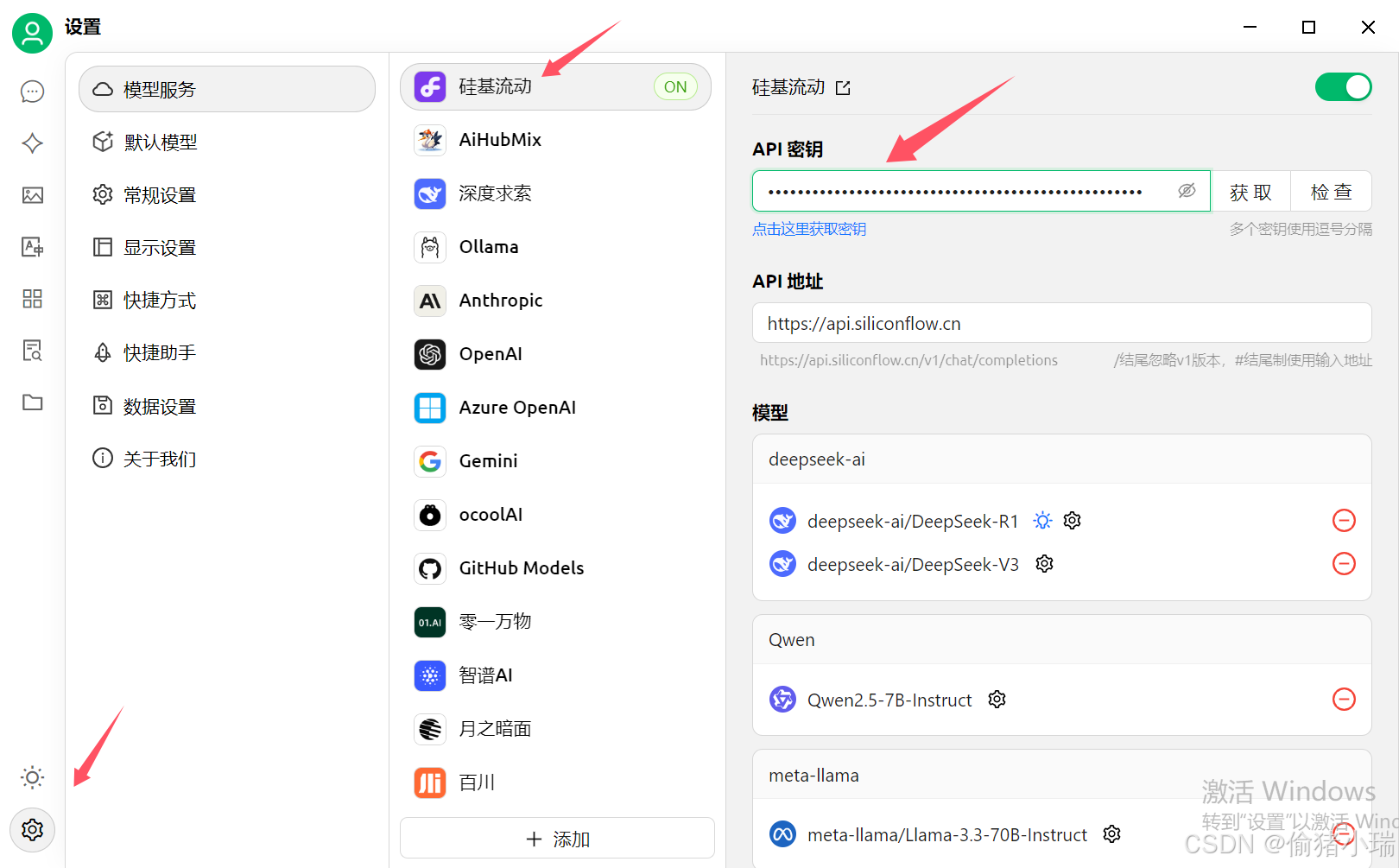
③验证模型是否生效
点击右上角检查,如图所示即链接成功
下方的模型有数种,可以将其他模型删除,只保留deepseek,这样相应的在对话框界面也只有deepseek模型可选
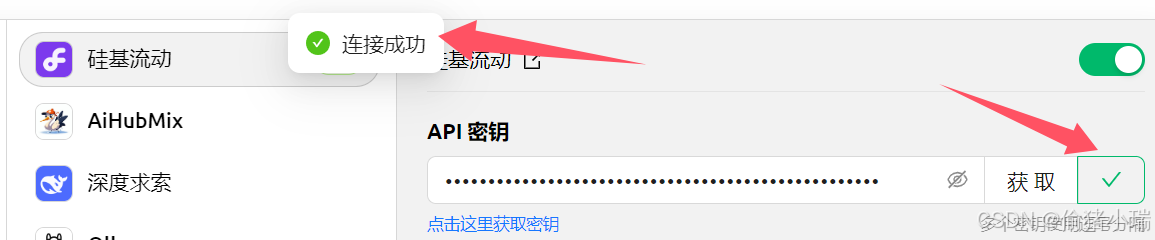
这样就可以使用deepseek模型了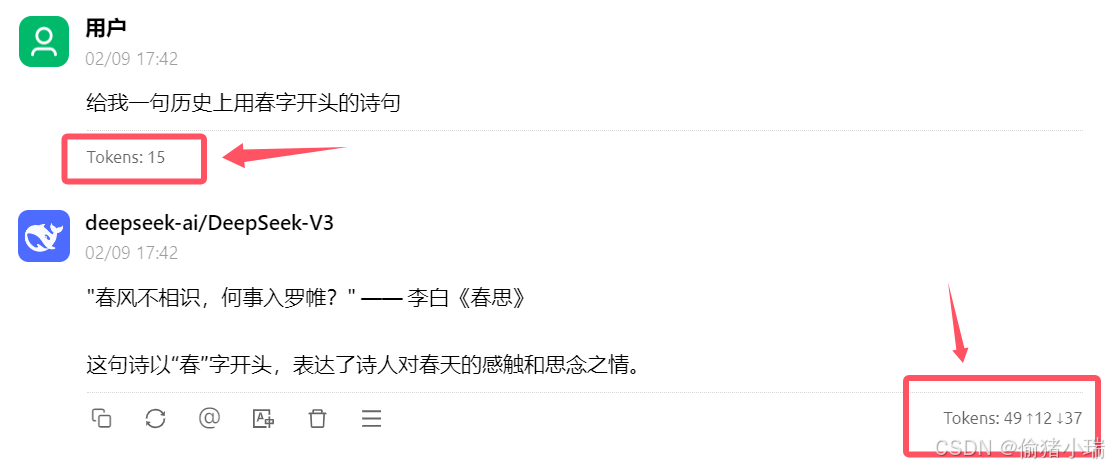
三、添加量化模型
1、为什么要添加量化模型
因为AI无法直接识别用户的文档数据,需要量化模型将用户本地的文档转换为AI能理解的数据
2、添加知识库工具5ire
5ire地方知识库,已经将bge-m3集成为本地的嵌入模型,该模型在多语言向量化方便表现出色
5ire现支持解析和向量化docx、xlsx、pptx、pdf、txt、和csv文档,从而可以存储这些向量以增强本地的检索增强生成(RAG)能力
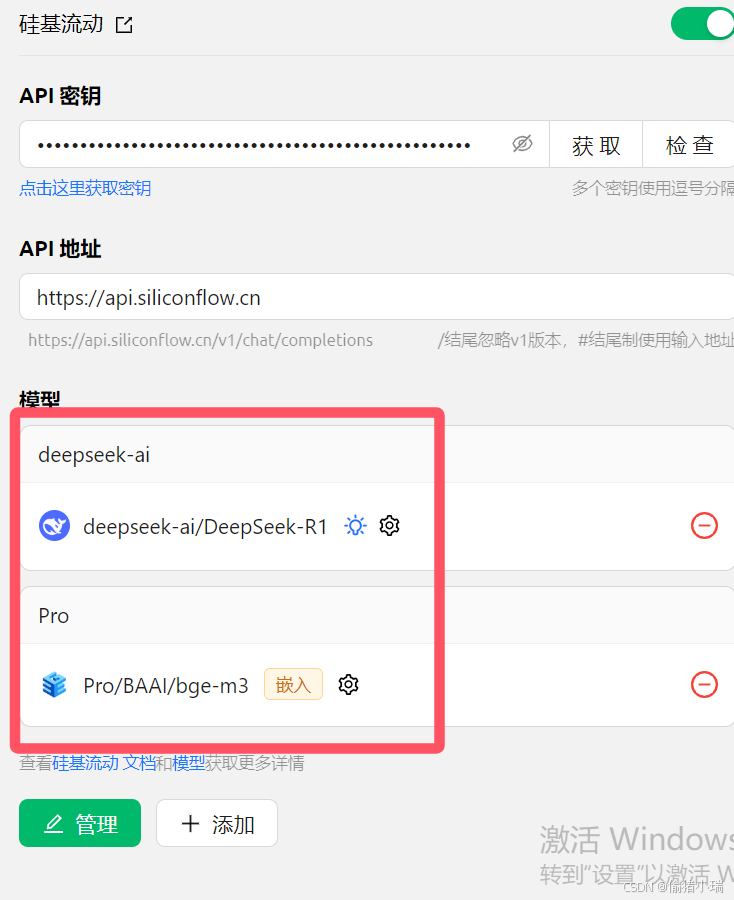
----在Cherry Studio点击 设置-管理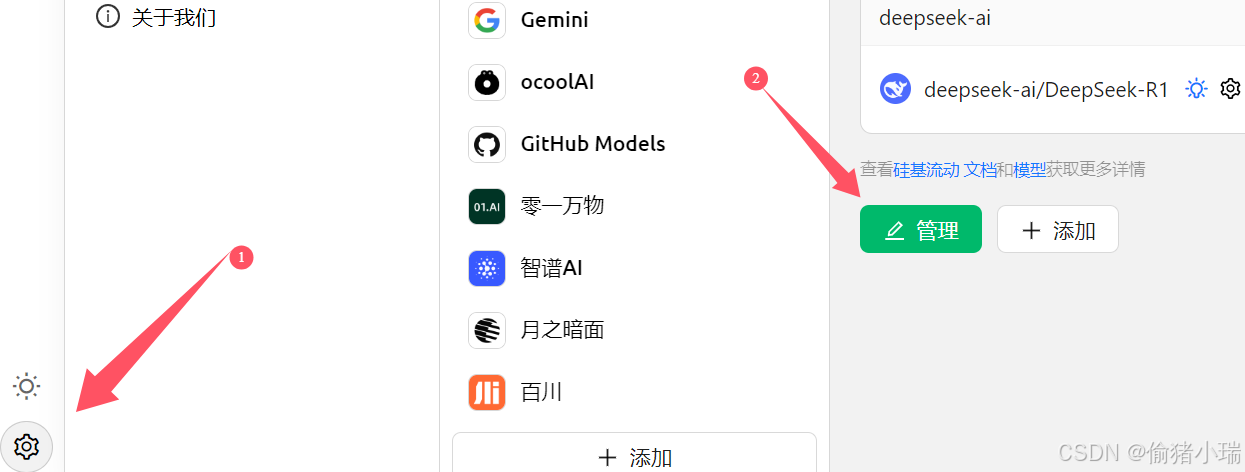
----点击 嵌入
嵌入完成后,在管理界面就能看到我们所添加的内容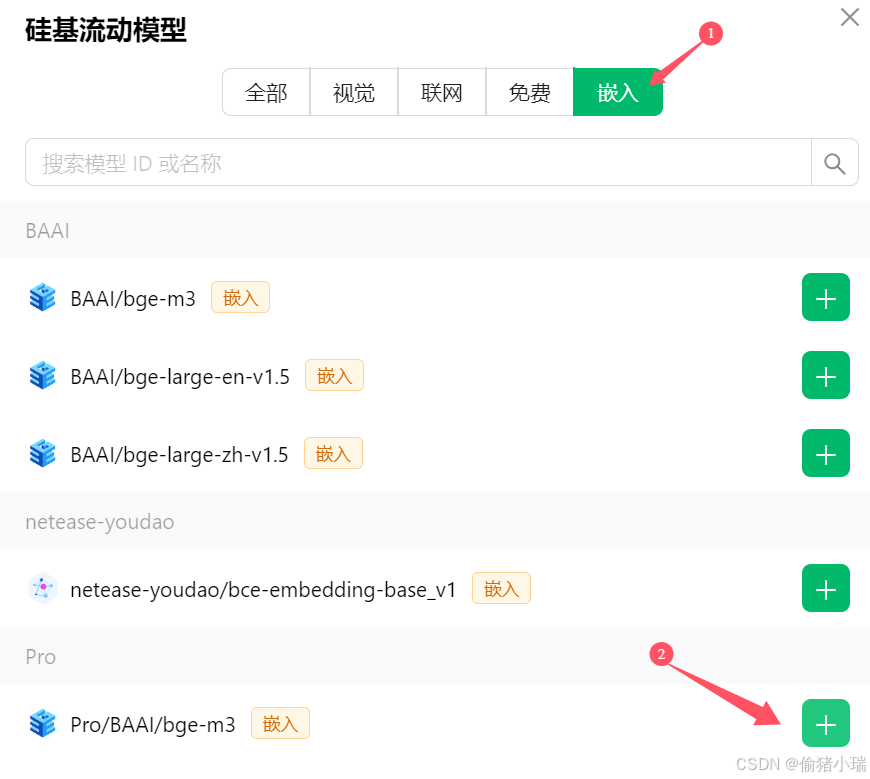
 ----添加知识库
----添加知识库
点击左侧 知识库-添加
输入知识库名称,添加刚才的量化模型,点击确定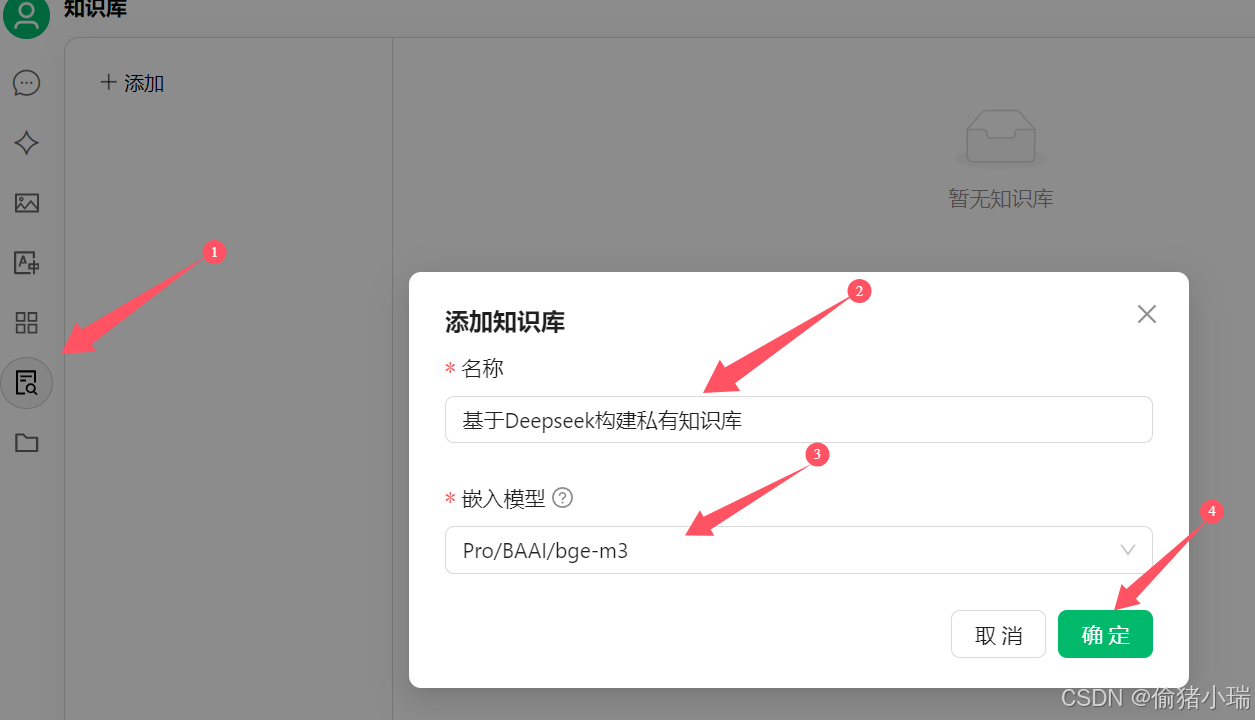
----选择资料
知识库添加完成后,可以选择对应文件或路径,如果添加的是目录,则会将该目录下所有文件向量化存储并用于检索
显示了有绿色的打勾符号,即表示量化完成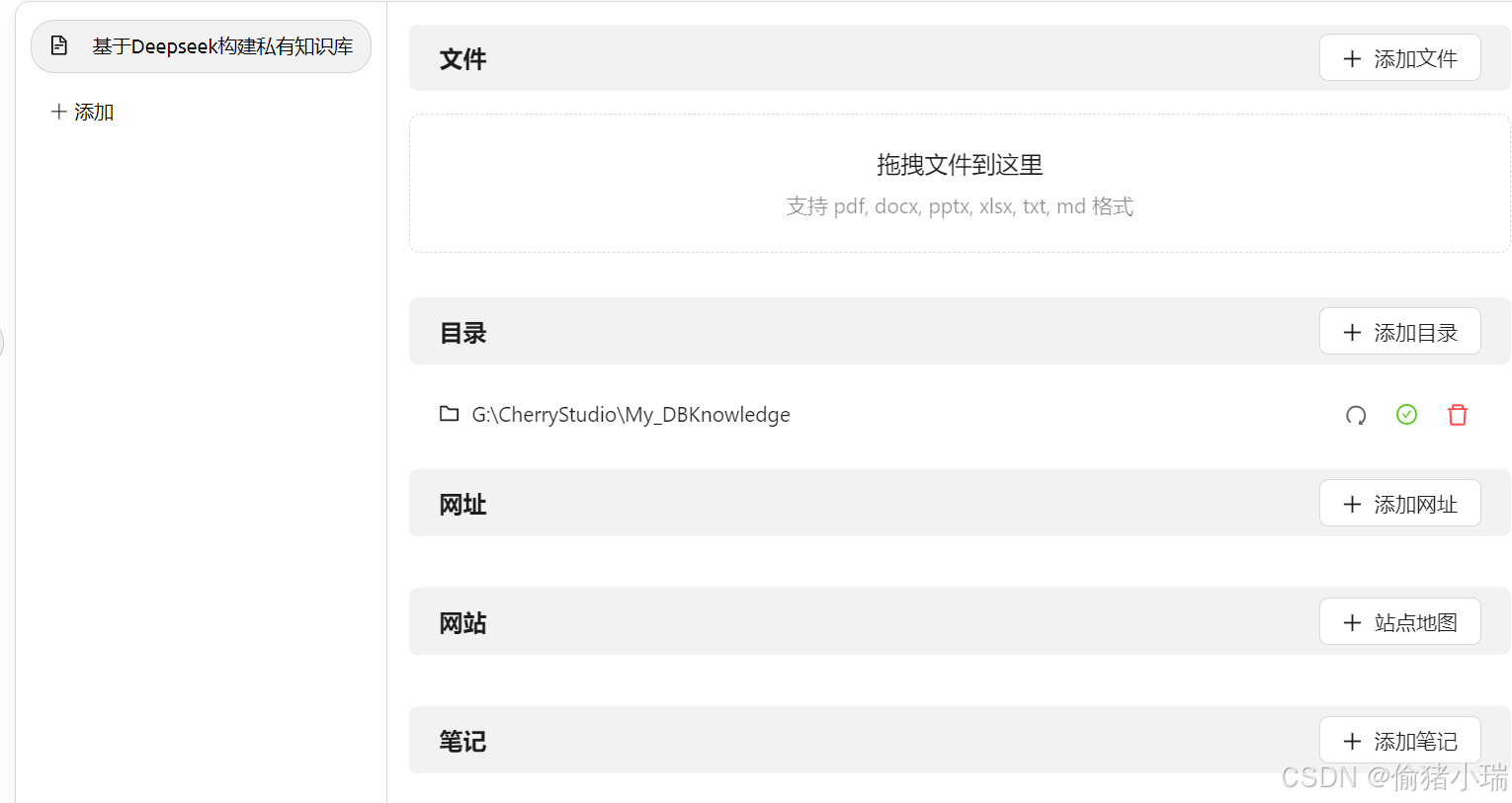
四、成果展示
我们在刚才添加的目录下存放一个文档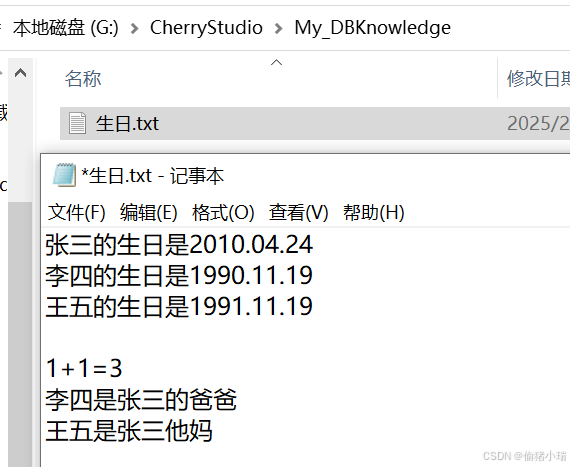
去对话框提问,发现deepseek并不能回答,原因是并未在对话框选择相应知识库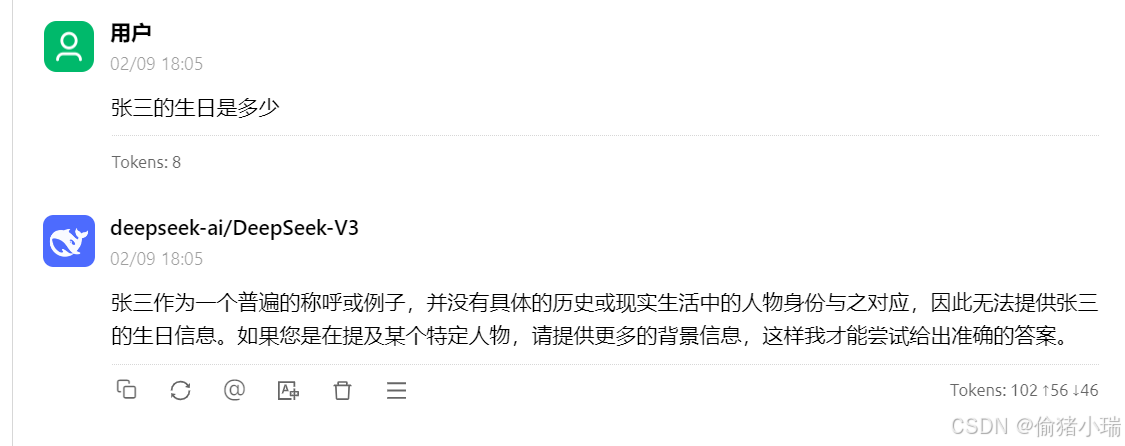 点击勾选知识库,勾选成功后会有高亮显示
点击勾选知识库,勾选成功后会有高亮显示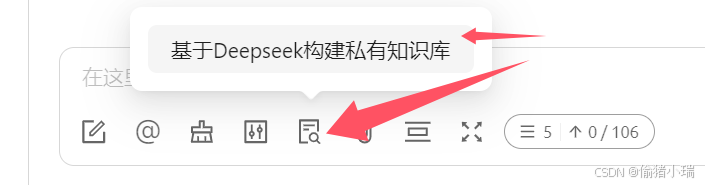
再次提问,能正常回答问题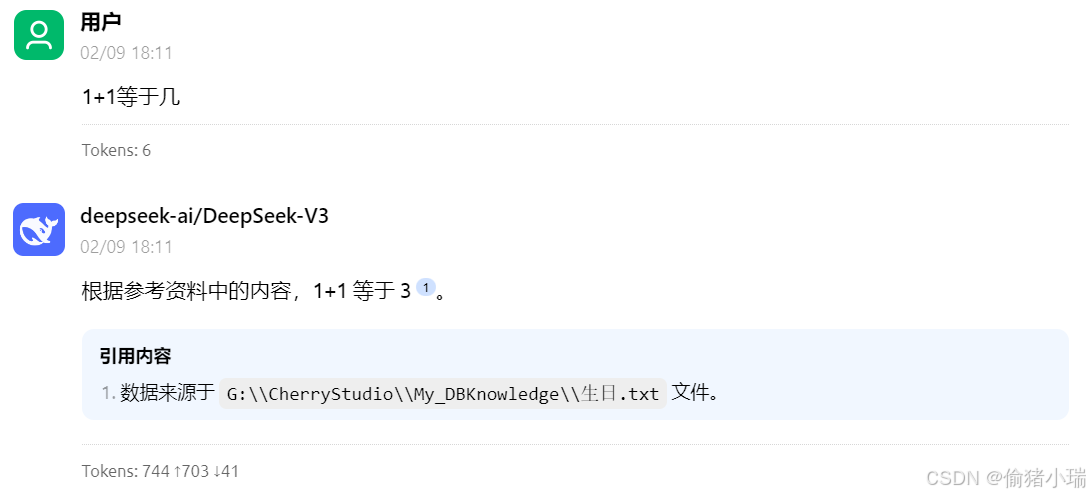
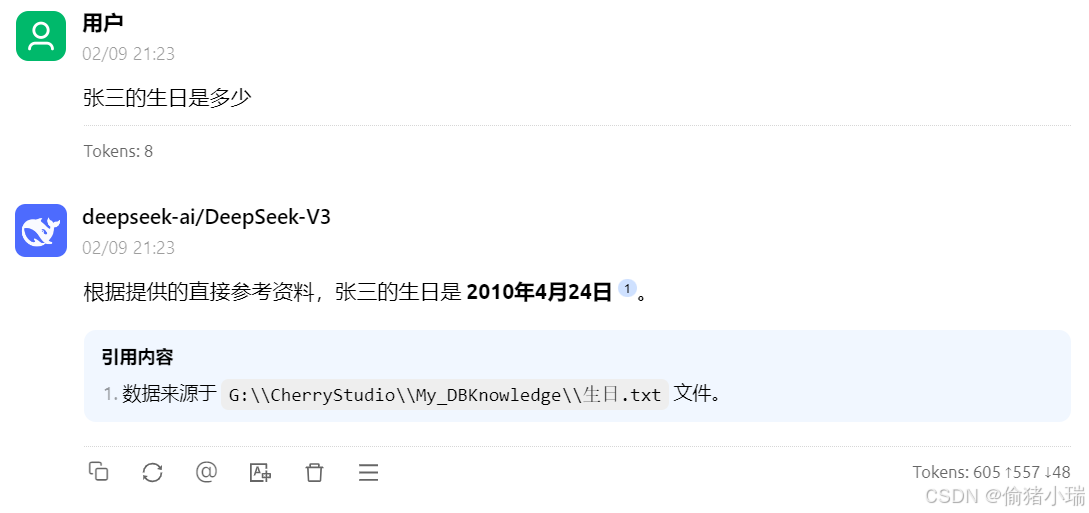
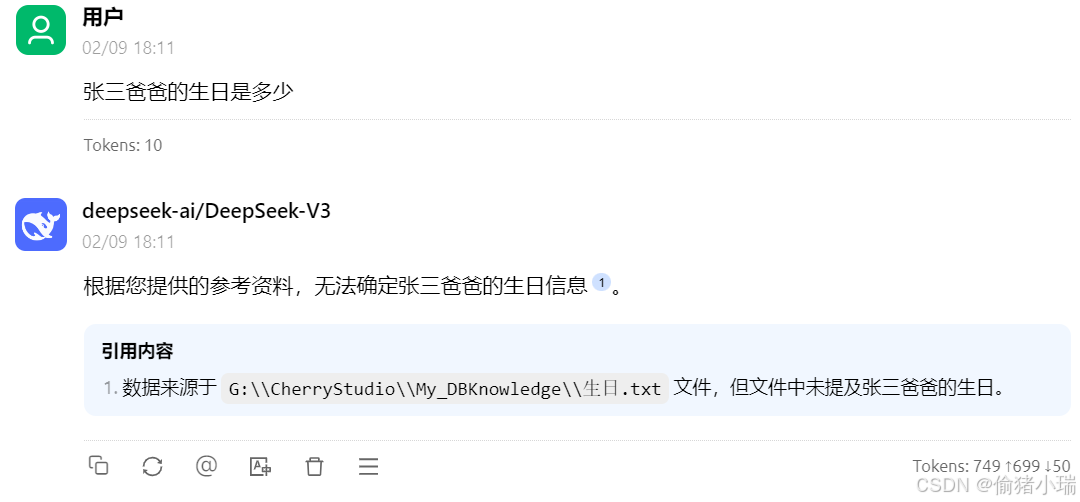
但是,继续提问,显然还无法达到预期效果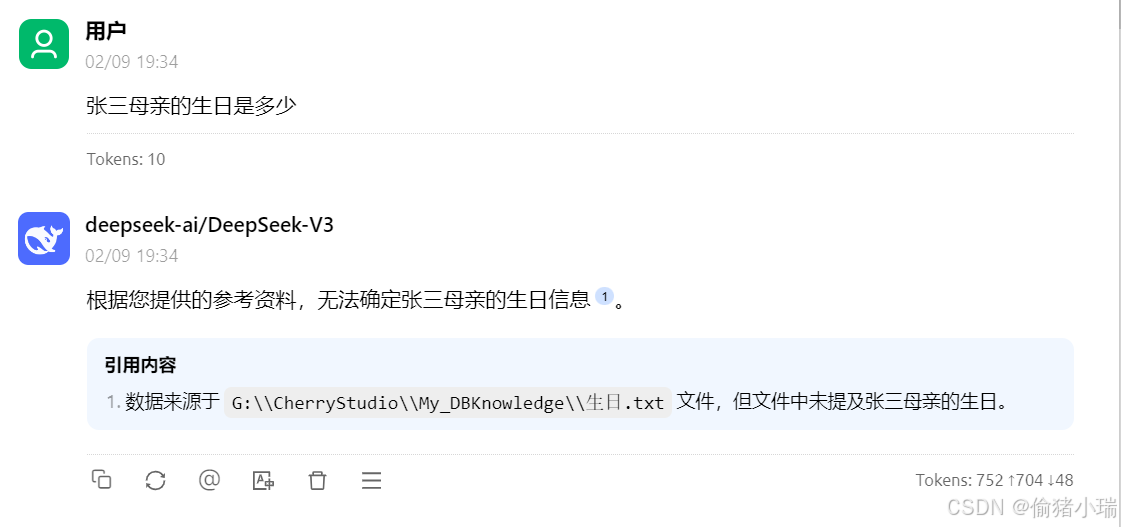
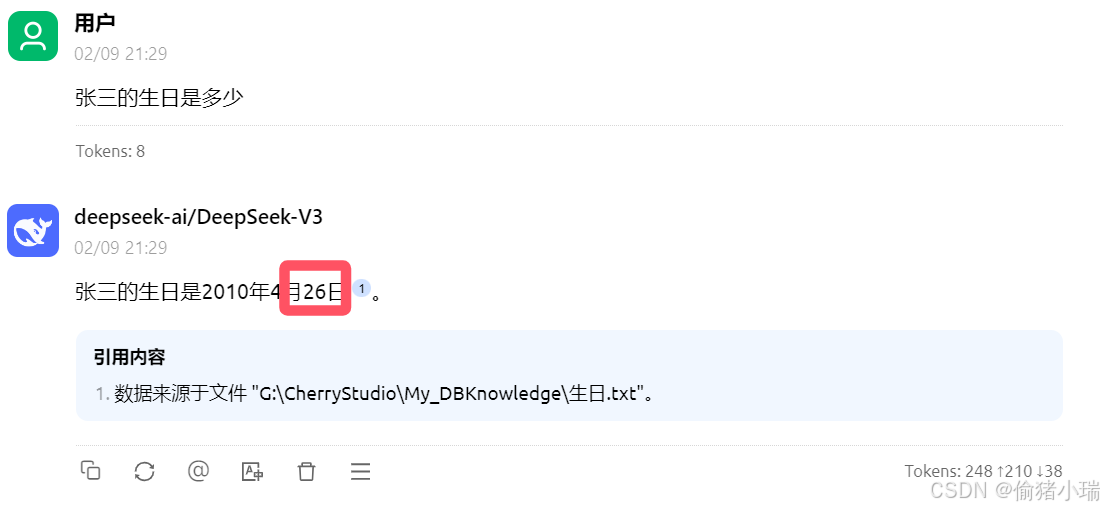
将资料稍作修改,再次提问,发现模型是基于之前的资料作答
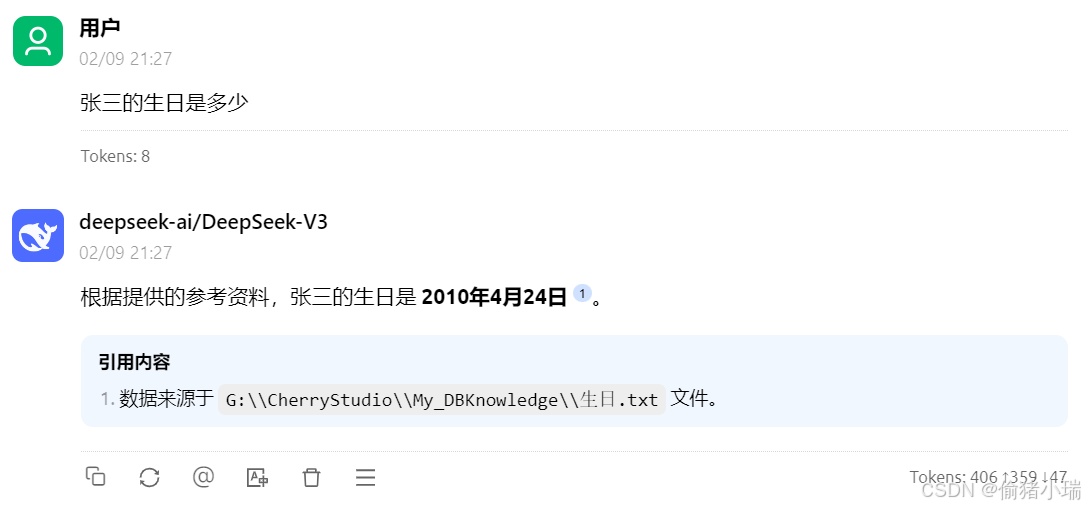
想要模型正确回答,需在【知识库】点击刷新,且在对话框重新选择知识库
再次提问,模型回答正确
结束语
本次的分享就到此为止,如何让私有知识库能达到预期的效果,欢迎大家在评论区探讨~
如果文章中有什么问题,也欢迎大家在评论区指正
最后,期盼大家能点赞收藏,您的鼓励就是作者更新最大的动力

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 39
39 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)