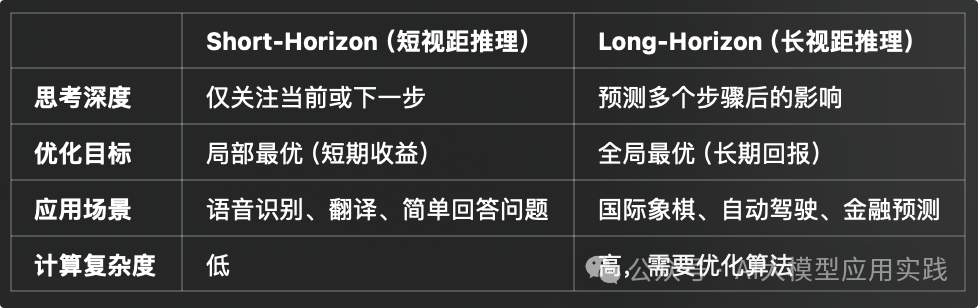
DeepSeek-R1 + LlamaIndex:基于推理模型的RAG/RAT应用新玩法
RAT是 RAG的一种改进,它结合了 CoT(Chain of Thought,思维链)推理,让模型在回答问题时不仅能够参考外部知识,还能更好地进行深度的推理与思维。RAT的标准流程为:**1. 生成初步的思维链(CoT):**即推理时的一步步思考过程,通常会分成n个步骤,直到生成最终答案,但此时的CoT可能不够完善或者有错误。
春节期间,科技界最火爆出圈的恐怕非国产大模型DeepSeek莫属,特别是其在V3后推出的对标OpenAI o1的推理模型DeepSeek-R1,以其强大的性能与低廉的成本震惊了全球。

不过,再强大的模型终究要服务于上层,让我们来关注基于DeepSeek-R1的RAG应用及其特别的玩法。
-
基于DeepSeek-R1+LlamaIndex的RAG
-
将RAG转化为RAT(检索增强思维)
基于DeepSeek-R1的RAG
首先我们来快速构建一个DeepSeek-R1的RAG原型,以了解其不同之处。
原料
-
模型:开源DeepSeek-R1+Ollama本地推理
-
RAG框架:LlamaIndex
-
UI原型:Streamlit
准备Ollama与模型服务
-
下载Ollama:https://ollama.com/
-
安装后运行:ollama run deepseek-r1
等待模型下载完成后,我们就拥有了可完全离线使用的本地deepseek-r1模型(根据硬件条件选择不同的参数大小,默认为7b)
基于LlamaIndex的RAG管道
1. 设置模型
在LlamaIndex中使用Ollama模型很简单:
...
llm = Ollama(model="deepseek-r1")
embed\_model = OllamaEmbedding(model\_name="milkey/dmeta-embedding-zh:f16")
Settings.llm = llm
Settings.embed\_model = embed\_model
2. 上传文档处理
提供一个上传知识文档的地方并做处理(为了测试方便,这里允许重新上传):
...
\# 上传文件(这里允许上传的类型为 txt/ PDF)
uploaded\_file = st.file\_uploader("", type\=\["pdf", "txt"\])
if uploaded\_file is not None:
# 计算文件内容的哈希值
file\_content = uploaded\_file.getvalue()
new\_file\_hash = hashlib.md5(file\_content).hexdigest()
# 如果文件发生变化或第一次上传,则重新创建 query\_engine
if st.session\_state.file\_hash != new\_file\_hash:
st.session\_state.file\_hash = new\_file\_hash
with st.spinner("正在处理文档..."):
st.session\_state.messages = \[\]
# 将上传的文件保存到临时位置
with open("temp.pdf", "wb") as f:
f.write(file\_content)
...
3. 创建基于LlamaIndex的RAG管道
然后用最简洁的方式创建LlamaIndex的RAG管道,采用默认的内存向量存储:
...
\# 加载并处理文档
docs = SimpleDirectoryReader(input\_files=\["temp.pdf"\]).load\_data()
\# 创建向量存储索引
index = VectorStoreIndex.from\_documents(docs)
\# 使用自定义提示创建查询引擎
query\_prompt = """
1. 使用以下上下文来回答最后的问题。
2. 如果你不知道答案,请直接说"我不知道",不要编造答案。
3. 保持答案简洁,限制在3-4句话内。
上下文:{context\_str}
问题:{query\_str}
答案:"""
st.session\_state.query\_engine = index.as\_query\_engine(
text\_qa\_template=PromptTemplate(query\_prompt),
similarity\_top\_k=3,
)
4. 显示聊天历史并输入
接下来就可以接收问题输入,并生成响应,同时添加到对话历史:
...
# 显示聊天历史
for message in st.session\_state.messages:
with st.chat\_message(message\["role"\]):
st.write(message\["content"\])
# 聊天输入
if prompt := st.chat\_input("请输入您的问题"):
# 显示用户问题
with st.chat\_message("user"):
st.write(prompt)
st.session\_state.messages.append({"role": "user", "content": prompt})
# 生成回答
with st.chat\_message("assistant"):
with st.spinner("思考中..."):
response = st.session\_state.query\_engine.query(prompt)
st.markdown(response.response)
st.session\_state.messages.append({"role": "assistant", "response": response.response})
else:
st.write("上传 PDF 文件以开始对话。")
5. 清除历史记录按钮
为了方便测试,添加一个清除对话历史的按钮:
...
\# 添加清除对话历史的按钮
if st.button("清除对话历史"):
st.session\_state.messages = \[\]
st.rerun()
6. 测试效果
在当前目录下运行streamlit run xxx.py,会自动打开浏览器访问应用,能够看到类似如下界面:
现在上传一个简单的PDF文件,开始对话。效果如下:
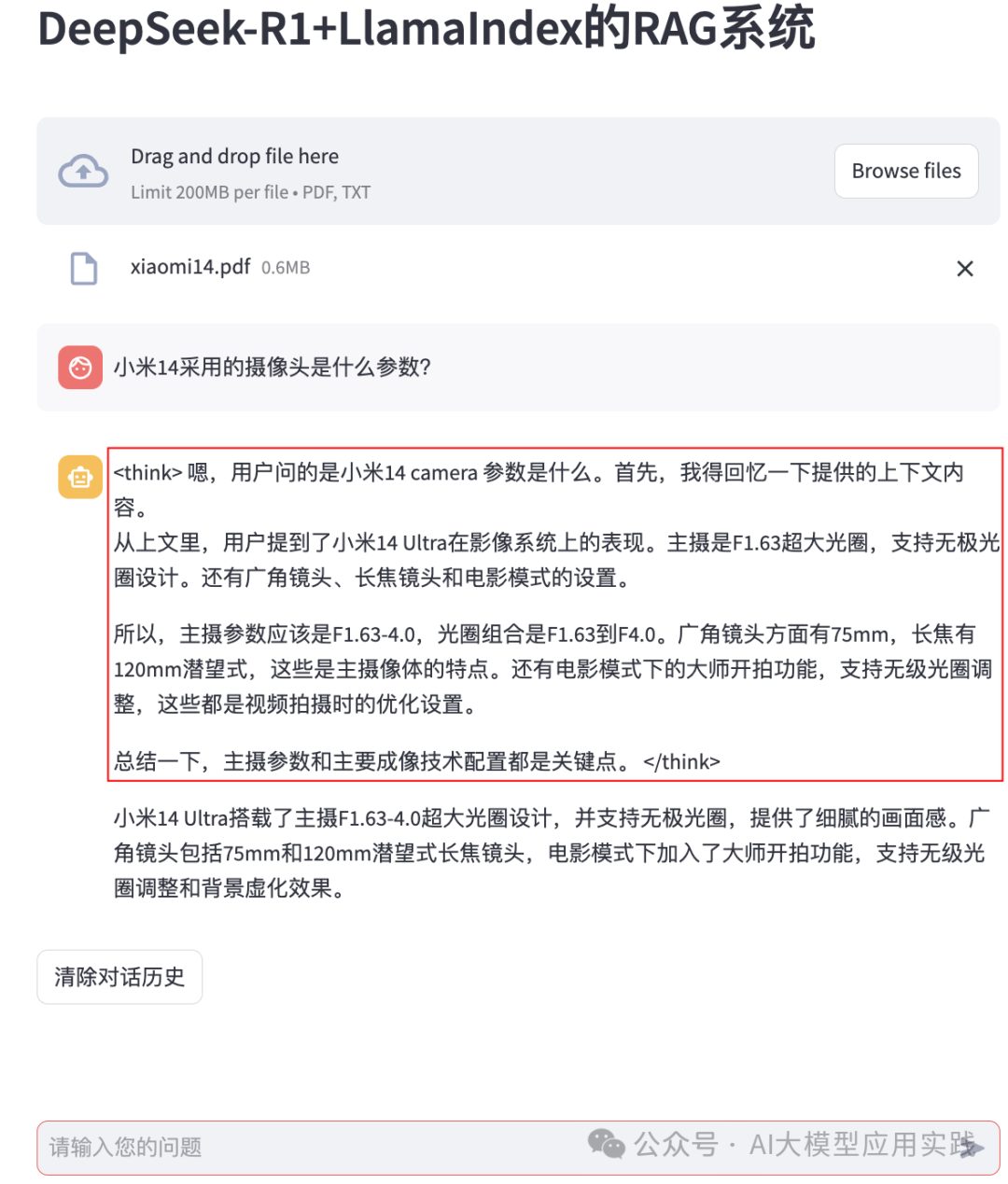
这里我们可以看到,DeepSeek-R1这样的推理模型在输出时会带有一个“思考”过程,这个逐步推理过程会放在输出内容的标签内:

7. 优化显示
实际应用时,可以对中的内容进行简单处理,比如隐藏。这里我们用简单的方法将这部分内容用不同的样式显示,并在保存历史消息时去除这部分。把上面代码中的响应处理部分做如下修改:
...
\# 处理回答中的<think>标签
text = response.response
text = re.sub(
r'<think>(\[\\s\\S\]\*?)</think>',
lambda m: f'<div style="display: inline;"><span style="color: gray; font-size: 0.9em">{m.group(1)}</span></div>',
text,
flags=re.DOTALL
)
st.markdown(text, unsafe\_allow\_html=True)
clean\_text = re.sub(r'<think>\[\\s\\S\]\*?</think>', '', response.response).strip()
st.session\_state.messages.append({"role": "assistant", "content": clean\_text})
现在显示效果如下,你可以快速的区分出“思考”与“答案”部分:
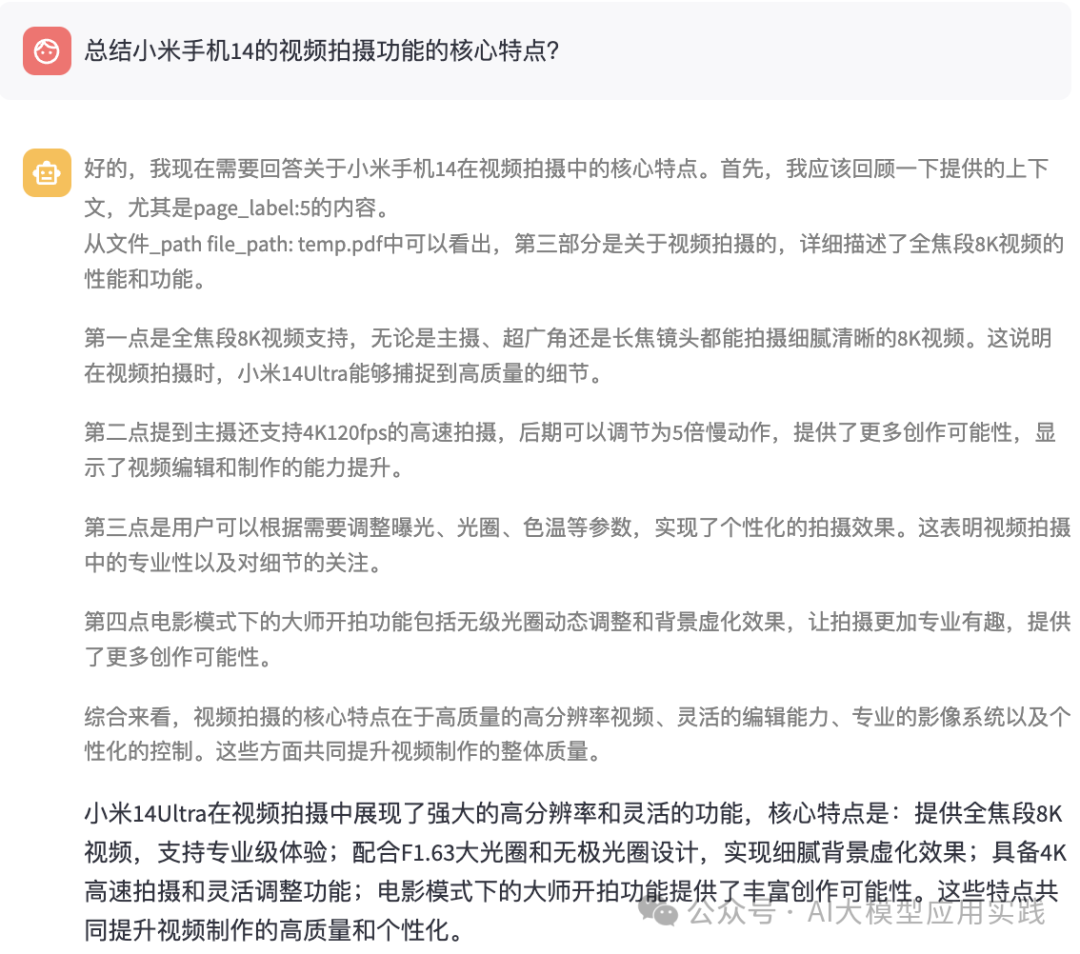
如果你使用一些开源的RAG构建平台或类似open-webui这样开箱即用的应用来对接R1,则需要自行对的部分进行处理,比如做折叠显示等。
DeepSeek-R1将RAG转化为RAT
将DeepSeek-R1这样的推理模型用于RAG的另一种改进思路是:**将DeepSeek-R1卓越的推理能力与其他模型(如GPT-4o)的生成能力结合,生成更具思考深度与准确性的答案。**这种改进形式也被称为RAT(Retrieval Augmented Thoughts),检索增强思维。
什么是RAT
RAT是 RAG的一种改进,它结合了 CoT(Chain of Thought,思维链)推理,让模型在回答问题时不仅能够参考外部知识,还能更好地进行深度的推理与思维。
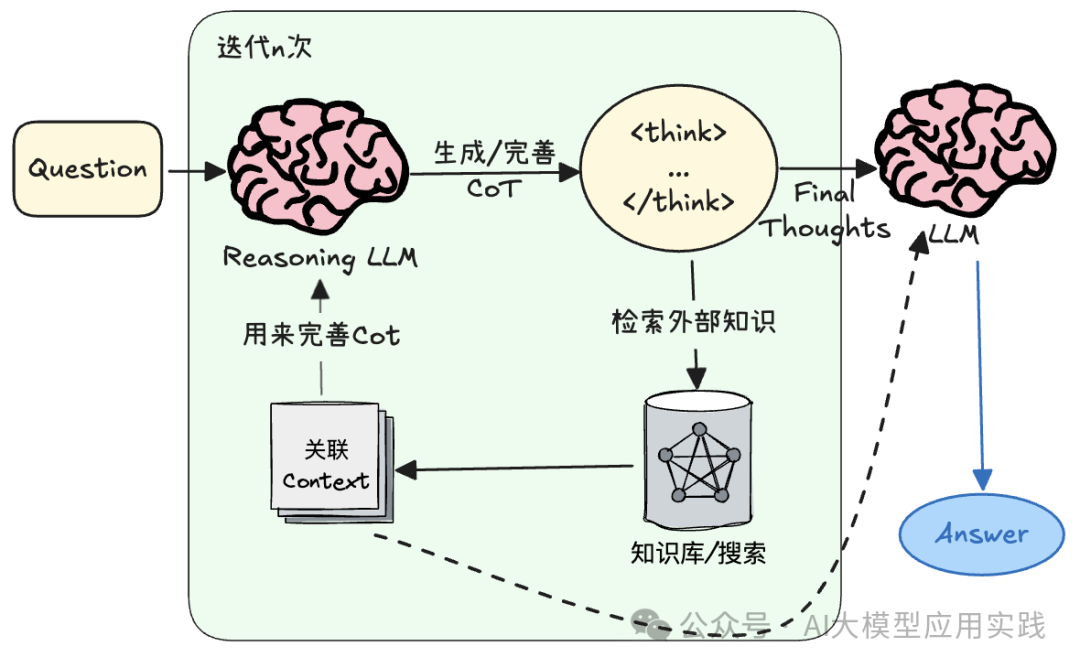
RAT的标准流程为:
**1. 生成初步的思维链(CoT):**即推理时的一步步思考过程,通常会分成n个步骤,直到生成最终答案,但此时的CoT可能不够完善或者有错误。
2. 迭代完善思维链: 根据已有CoT的步骤来检索外部知识,并用来不断修正CoT中的错误或遗漏,使CoT更加精准与丰富。经过多次这样的迭代,最终形成一个完善的CoT思维过程。
**3. 生成最终答案:**将最终的CoT,即更完善的思维过程,交给负责生成最终答案的LLM,获得最终响应。
整个过程可以下图表示:
在推理模型之前,你只能借助Prompt来生成CoT步骤,后来出现了o1但价格昂贵,现在DeepSeek-R1的开源给了我们一种新的选择:
让DeepSeek- R1来负责生成与完善CoT,以“提取”其思维过程。
**RAT的特点
**
在理解了RAT的工作流程后,可以总结出RAT的特点:
-
**基于CoT生成:**借助CoT模式生成更加深思熟虑与完善的答案。
-
**迭代推理:**通过多次迭代推理精细化CoT,借助外部知识完善。
-
**动态检索:**每次根据新的迭代推理结果,来调整检索的上下文。
由于RAT的流程复杂度增高,所以会带来一定程度的响应速度下降。因此,也并非所有的场景都适用RAT,其更适用于需要长距推理、需要借助外部知识(本地知识库或网络搜索)的一些复杂应用:
-
综合问答:比如一些需要结合多个关联内容的对比、计算、总结等
-
**编程任务:**借助CoT可以让LLM更准确的理解需求并生成更精准的代码
-
数学推理、游戏步骤推理、机器人路径规划等
RAT的简单实现
参考RAT的流程,我们在上面的RAG代码增加一个“思考”的核心步骤:即借助deepseek迭代生成一个CoT结果。流程稍作简化:
- 迭代完善CoT时,使用上一次的CoT结果进行检索,并把检索出的上下文交给DeepSeek,用来再次完善CoT
...
THINK\_PROMPT = """
请结合下面提供的上下文(context字段),仔细思考我的问题(question字段),完善之前的推理过程(thoughts字段)。
如果上下文与问题并不相关,请忽略context字段,直接思考问题。
注意你只需思考该问题,不需要输出答案,答案部分直接输出"Reasoning Done"即可。
"""
\# 初始化组件
reasoning\_llm = Ollama(model="deepseek-r1:1.5b")
class DeepSeek:
def \_\_init\_\_(self, reasoning\_llm, reasoning\_times=1):
self.reasoning\_llm = reasoning\_llm
self.reasoning\_times = reasoning\_times
#检索相关上下文
def retrieve(self, query):
nodes = st.session\_state.query\_engine.retrieve(query\["question"\])
return {
"context": nodes,
"question": query\["question"\]
}
#迭代推理,并返回最终COT
def think(self, input: str) -> str:
thoughts = input
for \_ in range(self.reasoning\_times):
retrieved\_docs = self.retrieve({"question": thoughts})
docs\_content = "\\n\\n".join(
node.text for node in retrieved\_docs\["context"\]
)
prompt\_json = {
"context": docs\_content,
"question": input,
"thoughts": thoughts
}
response = self.reasoning\_llm.complete(THINK\_PROMPT + '\\n\\n' + dumps(prompt\_json, ensure\_ascii=False))
think = re.findall(r'<think>(.\*?)</think>', response.text, re.DOTALL)
if not think:
return thoughts or "No reasoning available."
thoughts = think\[0\]
st.write(f"thoughts: {thoughts}")
return thoughts
测试这里的代码,每次迭代都可以获得一个CoT的“思维”结果。比如:

如果知识库很完善,那么经过多次的迭代,这里的CoT将会更完善,最后就可以交给LLM生成更精准的响应结果。
以上研究了DeepSeek-R1推理模型在RAG中的应用、特点,以及一种新的改进形式:RAT,我们也期待有更多的应用形式让DeepSeek-R1这种优秀的国产模型发挥更大的作用与潜能。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)