变天了!Deepseek-R1解读
作者|duckling编辑| 自动驾驶之心原文链接:https://zhuanlan.zhihu.com/p/19668739243点击下方卡片,关注“自动驾驶之心”公众号戳我-> 领取自动驾驶近15个方向学习路线>>点击进入→自动驾驶之心『大模型』技术交流群本文只做学术分享,如有侵权,联系删文一句话概括: Simple RL(GRPO) + 精确的reward信号(类t...
作者 | duckling 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/19668739243
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
一句话概括: Simple RL(GRPO) + 精确的reward信号(类tulu3的RLVF), no MCTS, no PRM.
完美的RL training curve
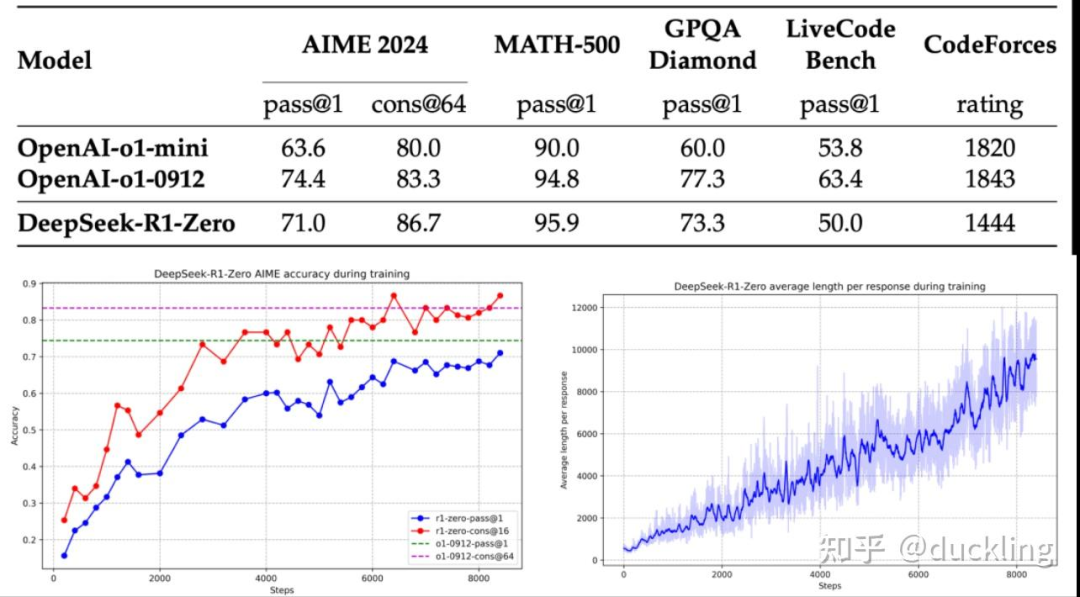
官方给了两个不同方式训练的模型:
-
R1-zero: 直接基于base模型做RL训练(无sft stage)
-
R1: multi-stage RL/SFT训练
DeepSeek-R1-zero
RL is all you need?
-
Pure RL on base model: GRPO + rule-based RM
训练模板:
-
通过prompt让模型输出在特殊token
<think></think>中输出resoning过程 -
最后在
<answer></anwser>输出最终结果

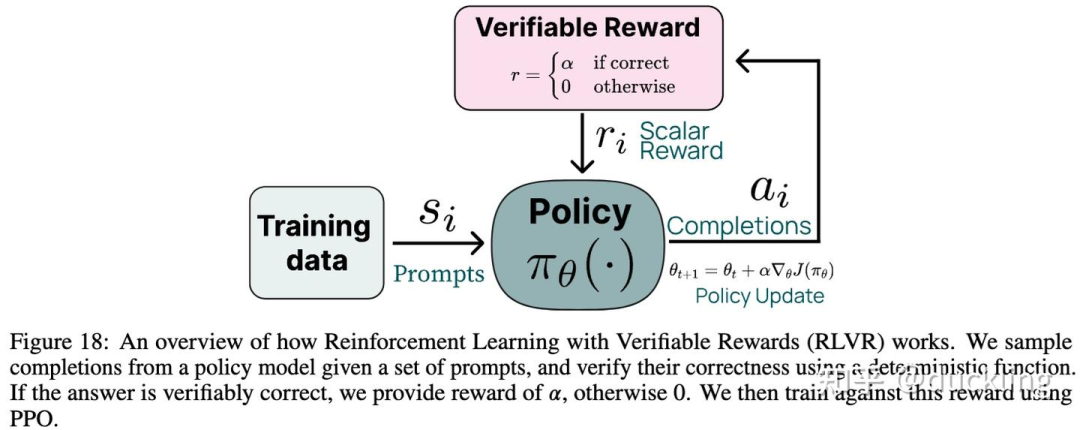
Rule-based RM
类似Tulu3的RLVR
-
精确的RM信号:
-
Math: 最终答案以一种特殊格式输出,如输出到box里(eg. sympy方式输出解析答案)
-
Code: 编译器feedback(例如leetcode代码, 输出testcases的结果做验证)
-
-
Format reward: 要求模型将思考过程输出到tags之间
Aha moment:
-
训练中自然涌现思考,反思、探索不同方案的的现象
-
中间模型观察到分配更多的思考时间来重新评估初始方案

DeepSeek-R1
-
R1-zero存在问题:
-
生成的思考过程可读性差(也许reasoning过程本身可读性并不重要?)
-
有混合语言输出的现象
-
-
R1: 解决R1-zero的问题, 以少量冷启动数据的multi-stage的训练pipeline
stage1: 冷启动数据
-
通过冷启动数据解决r1-zero生成的可读性问题
-
具有人类先验的冷启动数据的模式比r1-zero有更好的性能(实验验证)
数据格式 |special_token|<reasoning_process>|special_token|<summary>
在回复最后加上summary, 过滤掉可读性差的数据, 提升可读性
stage2: reasoning oriented RL
这一阶段主要强化模型在推理密集且定义清晰有确定答案的任务上的性能, 包括math, code, science, logic reasoning
-
发现问题: CoT经常会有混合语言的输出, 尤其是prompt包含不同语言的时候
-
解决方法: 引入language consistant reward, 计算CoT中目标输出语言的比例
-
最终的reward为reasoning的准确率+language consistency reward score
本阶段的checkpoint用于接下来一轮的sft数据收集
stage3: Reject sampling + SFT
这一阶段目标主要强化通用领域的能力, 如写作/role play等.. 。包含两类数据
-
reasoning data:
-
与之前部分的reward 不同,这部分除了rule based的RM外, 还引入了非rule base RM的数据, 通过deepseek-v3 as judgement作为Reward
-
过滤掉可读性差的数据: CoT混合语言、包含code blocks、长段落的数据
-
对于每个prompt, 采样多个response, 是基于答案正确的样本训练(reject sampling),
-
最终收集了600k样本
-
-
non-reasoning data
-
数据类别包含QA、writing、translation、self-congnition: 直接adopt deepseek-v3的部分sft数据
-
对于个别特殊的non-reasoning数据, 通过prompt让deepseek-v3回复答案前先生成CoT过程
-
最后收集200k non-reasoning样本
-
stage4: RL for all scenario
-
目的: 进一步对齐人类偏好(比如安全, xx特色), 提升helpfulness、harmlessness, 同时细化推理能力
-
方法: 组合reward信号和prompt 分布多样性
-
resoning数据: 如code/math, 同r1-zero的rule-based rm
-
通用领域数据: 通过RM来捕捉复杂和细微场景的偏好
-
distill
直接基于R1生成的long CoT的数据做SFT
-
蒸馏R1的数据做SFT 与 纯RL的对比实验发现几个有趣的现象:
-
R1蒸馏的Qwen-32B性能比QwQ好很大一截
-
R1蒸馏的Qwen-14B也能beats Qwen team的QwQ-32B model
-
基于Qwen-32b-base distill R1输出明显好于Qwen-32B + RL
-
Qwen-32B RL效果提升不如DeepSeek-V3-base
-
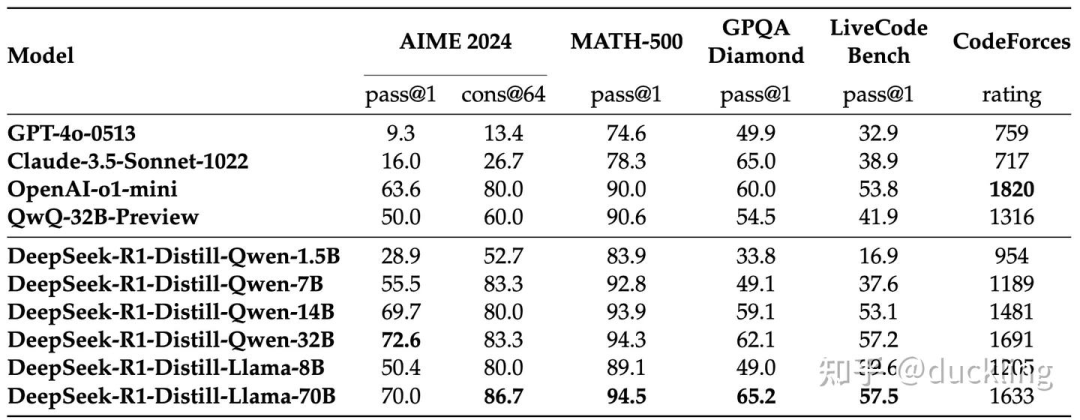
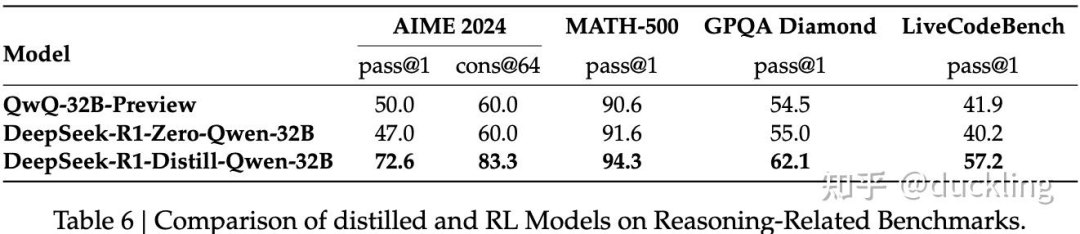
-
结论
-
对于小模型large scale 的RL效果可能不如distill模型
-
尽管distill可以既经济又高效地训练reasonning模型,但是对于提升模型能力的边界,还是需要强的base模型以及Larage scale 的RL训练
-
失败的尝试
尝试了被公开讨论的比较多,但因为挑战很大而没有成功的几个方案
-
PRM:
-
如何显示地定义step, 以及评估step的准确性
-
PRM 的reward hacking问题
-
PRM实验带来的提升有限,但带来更高的算力要求以及系统复杂性
-
-
MCTS 难以scaling
-
不同于棋类游戏定义了有限的空间, LLM 的token space巨大
-
尝试了没给node限制token数方案, 但发现经常陷入局部最优
-
疑问:
-
R1 stag3 reasoning data中把code block去掉了,是否会导致输出可读性差(例如markdown的输出)?
-
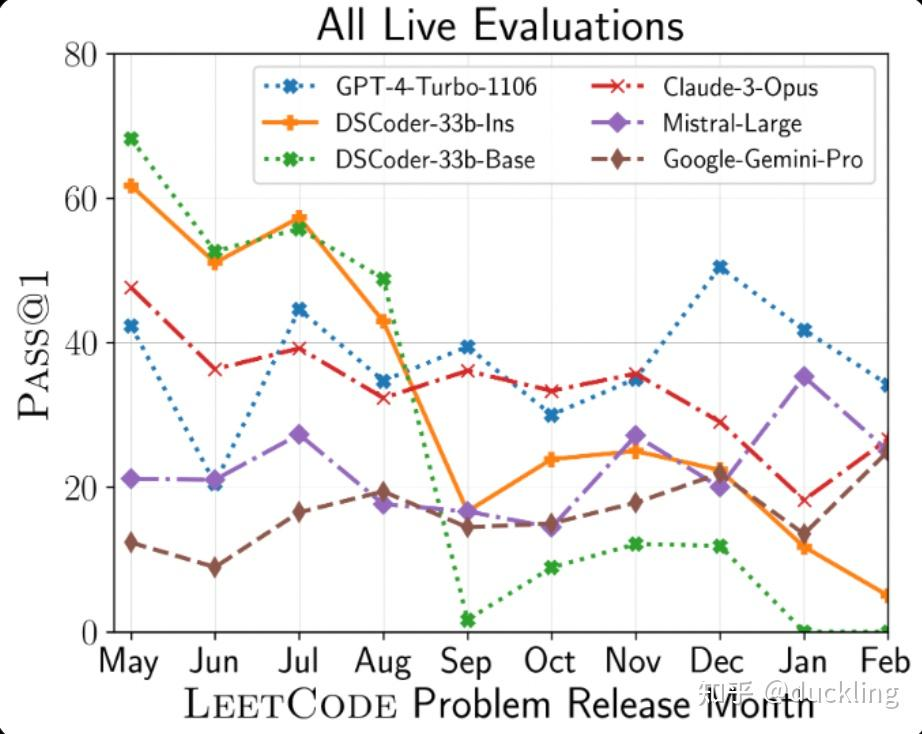
关于r1-zero的结论:通过纯RL可以激活LLM的reasoning能力(不需要sft)。但问题是当前的base模型在预训练中( 参考下图ds-33b base模型在leetcode上的测试)混了sft/prompt 已经不是纯粹的base模型了?(这已经是当前LLM pretrain的常规做法了. 类似的qwen base模型具备zero-shot的指令跟随能力,应该也是在pretrain decay阶段混了QA数据)
-
如何构建好的的起始prompt, RL stage的数据有多少?
-
GRPO训练的具体setting是怎样的,笔者做过类似的实验,发现respone length并没有像文章开始那样一直增长(应该是细节没有做对 , 数据太少, 训练时长不够,还是有其他rl trick?)
-
R1-zero式训练是否更依赖有一个非常strong的base模型?
-
目前在code/math上通过RL产生的强reasoning能力能否很好的泛化到其它领域?
kimi-k1.5
deepseek-R1的技术报告整体比较有诚意,是第一个公开release模型并把成功的方法和失败的尝试公开发表的(此处BS Closed-AI, twitter上卖关子、炒作没完没了)。
但是不足的地方是关于GRPO训练的细节没有讲. kimi 的技术报告有几个类似的结论,同时给出了RL infra的细节, 包括Long ctx, CoT压缩,采样策略等,也值得一讲(先给自己留个作业吧:))
总结 & 思考
-
Deepseek-R1 可以说是reasoning LLM的gpt2 moment, 它告诉了我们RL on CoT with rule-based RM就能让LLM获得强大的reasoning能力, 不需要复杂的MCTS、PRM(国内同行应该都有类似的方案尝试没有公开)
-
只是gpt2 moment而不是gpt3/chatgpt moment, 是感觉R1只是初步验证这个简洁方案的可行性,但还有很多改进/可探索的空间:
-
R1 RL用的GRPO, 感觉更多是出于算力/计算效率的选择。PPO/reinforce类的方法是否更好?
-
deepseek没有把PRM做work, 但感觉类似PRIME那种隐式的PRM应该有助于提升模型能力的.
-
从inference角度看, kimi-k1.5那种long Cot -> 压缩为short CoT的方式是一种更友好的方式
-
Math/Code有获得精确信号的手段, 物理、化学等领域如何或得精确的信号(reward/verifier)
-
人类的resoning过程是必须以自然语言的形式的表达么?Coconut那种reasoning on latent space是否是更好的一种方式?
-
MCTS在LLM上能否做work, 出现LLM的alpha-zero、MuZero时刻,从而大幅提升能力上限?
越想越兴奋, 2025, 我们拭目以待 : )
ps. 知乎文章编辑器真TN的难用:
Reference
-
DeepSeek-R1
-
Kimi-k1.5
-
PRIME
-
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
-
Coconut: Training Large Language Models to Reason in a Continuous Latent Space
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)