Cyber Weekly #42
DeepSeek爆火以后,据说国内各大模型厂商春节期间都在加班。
赛博·新闻
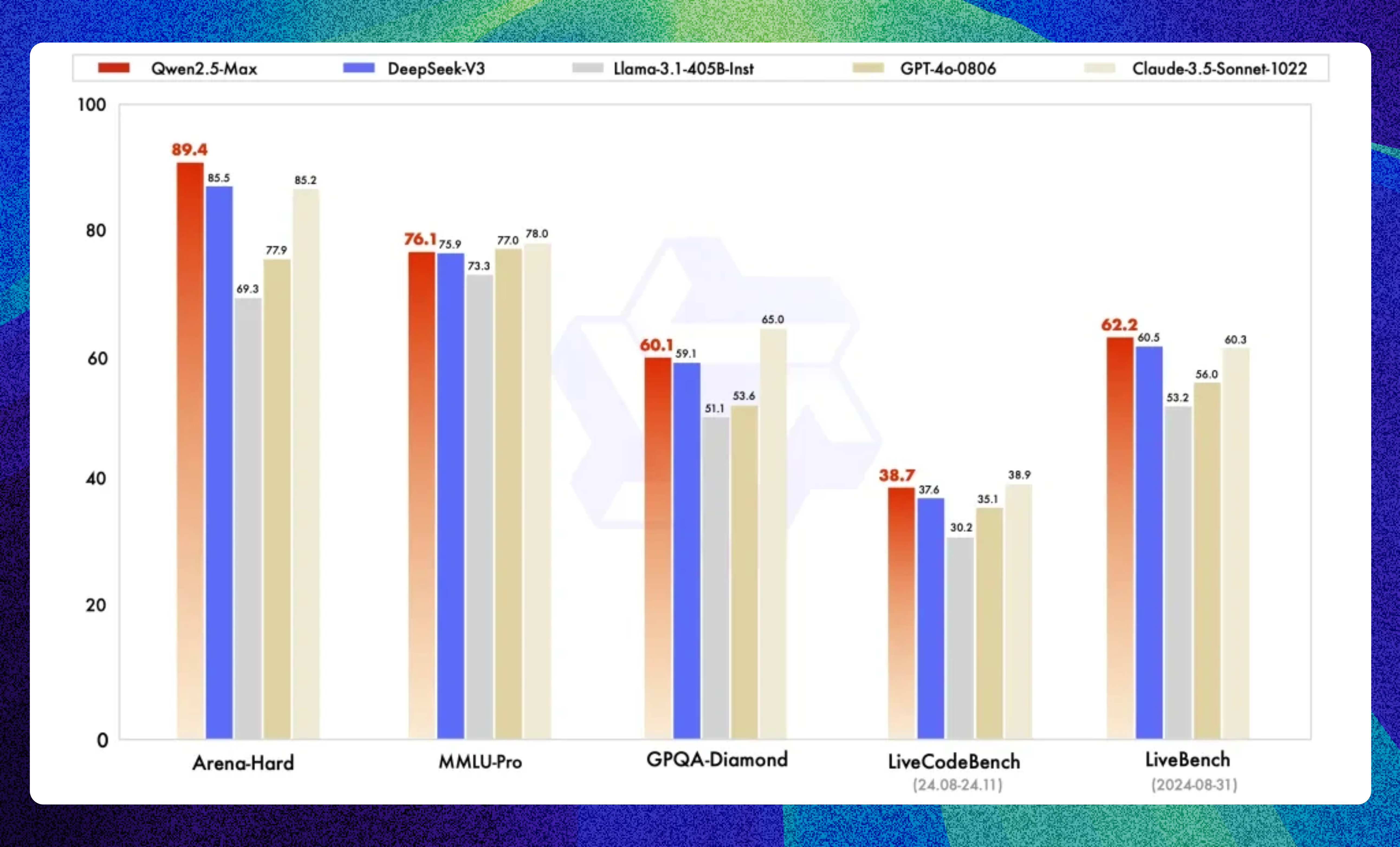
1、阿里发布Qwen2.5-Max
大年初一,阿里云通义团队发布了最新的旗舰版模型Qwen2.5-Max,预训练数据超过20万亿tokens。该模型在知识、编程、综合评估以及人类偏好对齐等主流权威基准测试上展现出全球领先的性能。Qwen2.5-Max的指令模型版本在多个基准测试中几乎全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B等竞品。基座模型也在所有11项基准测试中全部超越了对比模型。目前,开发者可以在Qwen Chat平台上免费体验该模型,企业和机构也可以通过阿里云百炼平台调用新模型的API服务。
2、OpenAI上线DeepResearch功能
为应对DeepSeek的强烈攻势,OpenAI于2月3号紧急上线了Deep Research功能。Deep Research旨在帮助用户快速完成复杂的信息查询与分析工作,目前仅对Pro用户开放,未来将逐步向Plus和Team用户开放。Deep Research由即将推出的o3模型支持,针对网页浏览和数据分析进行了优化。它能够在几十分钟内完成原本需要数小时的人工研究,并且可以独立为用户提供服务。此外,Deep Research在多个基准测试中表现出色,特别是在“人类终极考试”评估中达到了新高。尽管仍处于早期阶段,但其潜力巨大,有望成为自动化研究的重要工具。
3、Google推出Gemini 2.0 Flash系列大模型
2月5日,Google宣布推出Gemini2.0系列大模型。Gemini2.0系列模型主要特点有:
- Gemini 2.0 Flash:支持多模态输入和文本输出,具备100万tokens的上下文窗口,并支持结构化输出、函数调用和代码执行等功能。
- Gemini 2.0 Flash Thinking:已在Gemini App中开放使用,供用户体验。
- Gemini2.0 Pro Experimental:主打编码性能和处理复杂提示能力,在知识理解和逻辑推理方面表现出色。
- Gemini 2.0 Flash-Lite:可看做「Gemini 2.0 Flash」的轻量版模型,暂不支持多模态实时API、搜索工具和代码执行,但它保留了100万tokens的上下文窗口,以及多模态输入、文本输出和函数调用等核心功能。

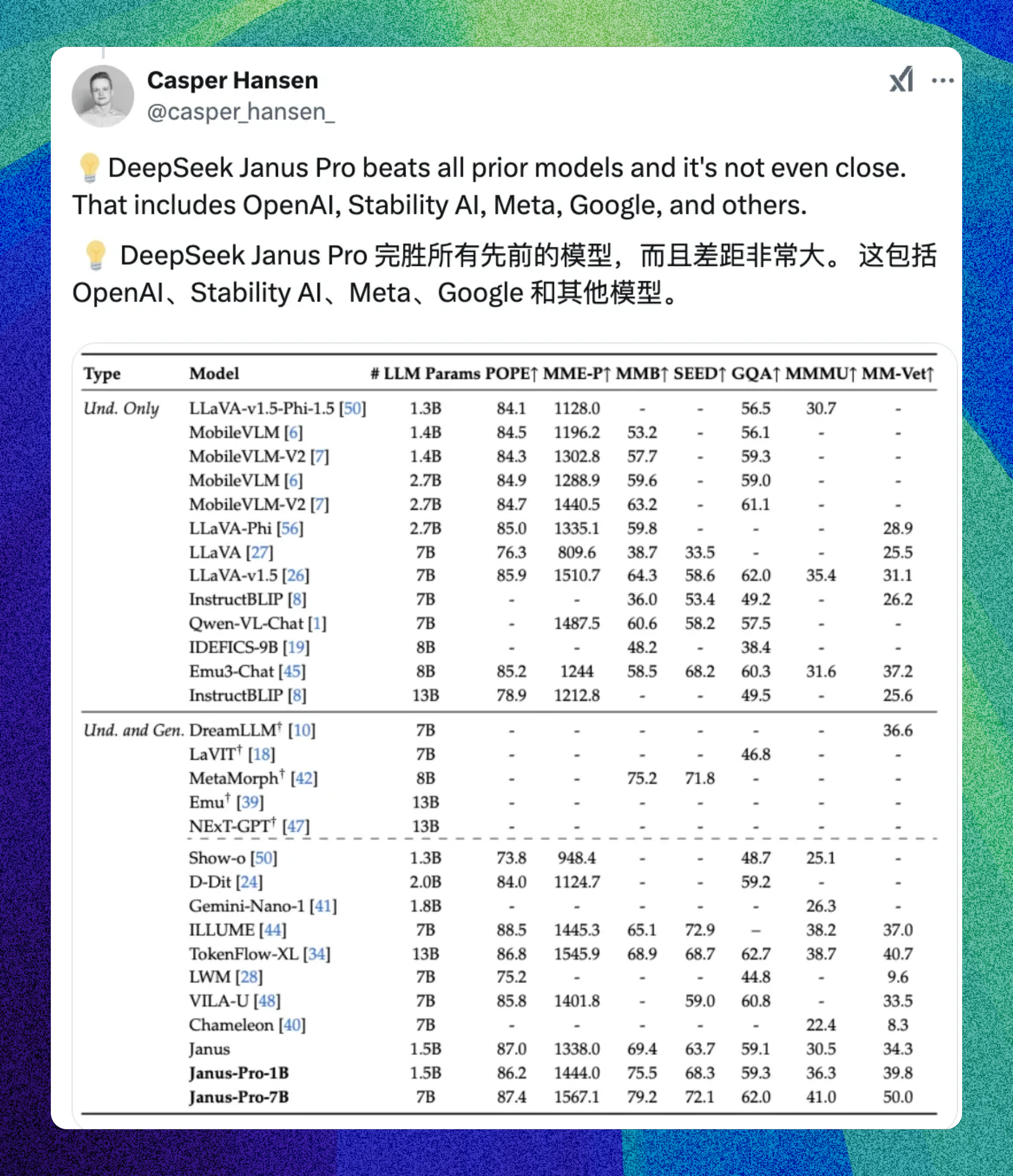
4、DeepSeek开源多模态模型Janus-Pro
1月28日,DeepSeek团队发布最新的多模态模型Janus-Pro。该模型名称来源于古罗马神话中的双面神“雅努斯”,象征着其同时具备视觉理解和图像生成的能力。Janus-Pro在图像生成方面明显优于原版Janus,并且在参数上领先于OpenAI的DALL-E3。除了图像生成,Janus-Pro还具备图像识别、地标识别、文字识别等多种能力。文章解释了Janus-Pro如何通过更优化的训练策略、更海量的训练数据和更大规模的模型来实现这些功能。
赛博·洞见
1、朱啸虎现实主义故事1周年连载:“DeepSeek快让我相信AGI了”
文章通过访谈朱啸虎,记录了他对DeepSeek AI技术的看法及其对AGI态度的转变。朱啸虎曾对大模型和AGI持怀疑态度,但DeepSeek的出现让他重新评估了AI的潜力,认为DeepSeek可能成为机器意识的原点,并表示如果DeepSeek开放融资,他愿意投资。文章还涉及了DeepSeek对AI市场格局的影响,朱啸虎预测DeepSeek可能成为AI时代的安卓,并对全球AI市场格局产生重大影响。他强调了高质量数据的重要性,并认为开源模型将在未来AI发展中占据主导地位。

2、一场关于DeepSeek的高质量闭门会:“比技术更重要的是愿景”
本文记录了一场由拾象创始人李广密组织的关于DeepSeek项目的闭门讨论会。与会者包括多位顶尖AI研究员、投资人及一线从业者,他们围绕DeepSeek的技术特点、团队文化以及其未来影响进行了深入交流。讨论中提到,DeepSeek的成功不仅在于其技术领先性,更在于其明确的愿景和优秀的团队协作。此外,文章还涉及了DeepSeek在资源利用效率、模型训练方法等方面的具体实践,并对其商业模式、人才策略等进行了评价。

3、我们应如何看待DeepSeek的557.6万美元训练成本?|甲子光年
文章分析了DeepSeek-V3的训练成本,并指出外界对其成本的误读。DeepSeek-V3使用2048块英伟达H800GPU,耗费557.6万美元完成了训练,相比其他同等规模模型大幅降低了成本。文章强调了前期研究和消融实验等“隐性成本”,并解释了不同成本计算方式的影响。DeepSeek-V3通过算法、框架和硬件上的优化协同设计实现了降本增效,包括负载均衡优化、通信优化、内存优化和计算优化。文章最后强调,DeepSeek的成功是“小米加步枪”式的,基于朴实而简单的创新。
4、前DeepSeek科学家万字大揭秘,RL与MoE如何点燃大模型革命
文章通过介绍前DeepSeek研究员王子涵的观点,揭示了强化学习(RL)与混合专家系统(MoE)结合对大语言模型训练框架的影响。重点讨论了参数高效微调(PEFT)方法,特别是Expert-Specialized Tuning(ESFT)技术,它允许针对特定任务优化模型而不牺牲泛化能力。此外,还提到了将RL应用于多轮对话等复杂场景时的技术挑战及解决方案。
5、对DeepSeek和智能下半场的几条判断
文章围绕DeepSeek近期的技术进展,特别是其开源模型R1和R1-zero,讨论了这些成就如何推动整个AI行业进入新的范式。尽管DeepSeek尚未超越OpenAI等领先者,但通过公开强化学习(RL)与推理模型的新方法,它极大地促进了该领域内新研究路径的探索。此外,文章还分析了DeepSeek成功背后的原因,包括技术优势如低成本、联网功能以及透明化的思考过程展示;同时也指出了其成功中的偶然因素。

6、Semi Analysis万字解析DeepSeek:训练成本、技术创新点、以及对封闭模型的影响
该文通过详尽的数据和分析,揭示了DeepSeek作为一家新兴AI公司,在短时间内取得显著成就的原因。文章首先介绍了DeepSeek拥有约5万个HopperGPU,总投资超过5亿美元,同时指出该公司从中国顶尖高校招聘人才,提供极具竞争力的薪资。接着,文章讨论了DeepSeek的关键技术革新——多头潜在注意力(MLA),这一创新大幅降低了推理成本。此外,文章还比较了DeepSeek的R1模型与OpenAI的o1等其他模型之间的性能差异,强调尽管R1在某些方面表现出色,但整体上并不完全超越竞争对手。最后,文章纠正了外界对于DeepSeek训练成本过低的看法,指出600万美元仅是预训练阶段的成本,而实际总成本远高于此。

7、中国开源,震撼世界:DeepSeekR1的变革、启示与展望
作者橘子,讲述了DeepSeekR1如何成为行业焦点,超越OpenAI的ChatGPT,登顶美国区AppStore榜首。DeepSeekR1以其卓越的性能和开源模式,打破了昂贵推理模型的固有印象,证明了即使在资源受限的环境下,中国AI也能通过创新和开源取得世界一流成果。文章还讨论了DeepSeekR1Zero模型的革命性发现,即模型的思考能力可以自我涌现。此外,文章展望了DeepSeekR1对未来的影响,包括开源模型的进步、技术普惠平权、AI编程效率提升等,并以对蛇年满怀希望和国运辉煌的期待作为结尾。
8、深入解构DeepSeek-R1!
文章围绕着DeepSeek-R1这一新型推理模型展开讨论,从其架构设计到训练方法等多个角度进行了深入解析。首先介绍了R1相较于传统模型如o1,在强化学习框架下的独特优势,特别是它如何通过四个核心要素——策略初始化、奖励函数设计、搜索策略以及学习过程来实现性能提升。接着,文章强调了R1开源的重要性,并将其与OpenAI的做法进行了对比,指出了开源对于促进全球研究者参与及推动技术进步的关键作用。最后,还探讨了DeepSeek团队如何通过系统软件层面的优化大幅降低了训练成本,使得即使在有限算力条件下也能取得显著成果。
9、R1之后,提示词技巧的变与不变
本文由南瓜博士撰写,主要讨论了在使用DeepSeek-R1等大模型时,提示词技巧的变化和不变之处。文章指出,尽管大白话式的提示词仍然有效,但关键在于提供足够的背景信息。结构化提示词有助于AI“记住”和遵循指令,但在复杂内容中更为有用。此外,文章还提到不要在提示词中指定思考步骤,除非希望AI严格执行。示例是另一种重要的背景信息,可以按需提供。最后,文章建议通过分工协作来改进R1的指令遵循能力,并强调提升AI回复质量的关键在于用户的思考和表达能力。

10、我所见过的梁文锋
本文记录了作者在2018年6月对幻方量化的创始人梁文锋进行的一次深度调研。当时,幻方量化已经是中国量化投资领域的第一梯队,管理客户资金约45亿,自营盘约10亿。梁文锋作为公司的“总策略师”,虽然平时低调且不善言辞,但在专业问题上却表现得非常坦诚和细致。他穿着朴素,专注于编程和策略开发,甚至因为醉心于工作而无暇装修新房。尽管被预期只能交谈半小时,但实际调研时间远超预期,这得益于调研人员的专业性和充分准备。文章通过这次交流,展示了梁文锋的专业能力和专注精神。

赛博·工具
1、pixel-me
将你的头像像素化,质量挺好。

2、icon.kitchen
一次性生成Android、IOS、WEB三端icon图标,可直接预览,效果非常好。
赛博·资源
1、DeepSeek超ChatGPT成全球增长最快AI应用!下载破4000万,日活超豆包登顶中国No.1|量子位智库
DeepSeek自上线以来,下载量迅速增长,全球下载量接近4000万,日新增下载量显著领先于ChatGPT。在Web端,DeepSeek与ChatGPT的差距已从50倍缩小至5倍,并领先于豆包和Kimi智能助手。文章还讨论了DeepSeek在用户规模、用户活跃度、用户留存等方面的数据,并指出DeepSeek的增长对ChatGPT产生的影响,包括用户规模逆转、区域市场分化和竞争格局重构。

2、DeepSeek开启AI算法变革元年(关注公众号【产品老A】回复【DeepSeek开启AI算法变革元年】下载)
甲子光年智库指出,2025年是AI技术发展的战略拐点期,DeepSeek的算法创新成为关键推动力。
- 算力拐点:通过强化学习优化训练流程,DeepSeek-R1以少量算力实现高性能输出,验证“算力即性能”的新路径。
- 数据拐点:大模型向两极分化(高参数/低参数),低参数量模型适配端侧部署需求,推动AI处理重心向终端转移。
- 算法变革:DeepSeek-R1以强化学习为核心的训练架构,非Transformer架构(如LFM液态网络)崛起,突破性能天花板。
- 应用普及:推理成本降低30倍,C端场景加速落地;DeepSeek以“小米模式”实现普惠,并推动具身智能的规模化应用。
- 全球竞争:中美进入G2时代,美国扩大芯片出口管制和模型限制,DeepSeek成为全球AI竞争新变量。


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)