深度求索(DeepSeek)人工智能大模型的发展过程及其App初体验
介绍深度求索(DeepSeek)人工智能大模型的发展过程及其App初体验。
一、什么是深度求索(DeepSeek)?
深度求索(DeepSeek)是一款人工智能大模型(Artificial Intelligence Large Model,AILM),是由杭州深度求索人工智能基础技术研究有限公司开发。

DeepSeek人工智能大模型包含大语言模型(Large Language Model,LLM),称为DeepSeek LLM,包含代码大模型(Coder Large Model,Coder LM),称为DeepSeek Coder,包含数学大模型(Math Large Model,Math LM),称为DeepSeek Math,包含视觉大模型(Vision Language Mode,VLM),称为DeepSeek VL。
DeepSeek大语言模型(DeepSeek LLM),是一款由670亿(67 Billion,67B)个参数组成的大语言模型,它是在一个包含2万亿(2 Trillion,2T)个英文和中文基本单元(token)的庞大数据集上训练而成的,目前已开放了DeepSeek LLM Base(基础版本)和DeepSeek LLM Chat(对话版本),上述两个版本均分别包含70亿(7B)和670亿(67B)参数两个版本。
DeepSeek代码大模型(DeepSeek Coder)由一系列代大语言模型组成,每个模型都是在2万亿(2 Trillion,2T)个基本单元 (token)数据集上训练而成的,由87%的代码和13%的自然语言组成,包括英语和中文,其提供从1B到33B参数规模的代码模型。
DeepSeek数学大模型(DeepSeek Math)是一款基于deepseek - code -v1.5,且由70亿(7B)个参数组成的数学大模型,并持续通过Common Crawl免费Web数据库、自然语言中数学相关的基本单元(token)进行训练,基本单元数量达5000亿(500B)。DeepSeek Math 7B在不依赖外部工具包和投票技术(voting techniques)的情况下,其数学处理能力接近Gemini-Ultra和GPT-4的性能水平。
DeepSeek视觉大模型(DeepSeek VL)是一款开源的视觉语言(VL)模型,专为现实世界的视觉和语言理解应用而设计。DeepSeek VL具有通用的多模态理解能力,能够处理逻辑图、网页、公式识别、科学文献、自然图像和复杂场景下的人工智能。
二、深度求索(DeepSeek)大模型的发展过程
2023年11月2日,DeepSeek公司发布了DeepSeek Coder代码大模型,包括:DeepSeek-Coder-1B、DeepSeek-Coder-5.7B、DeepSeek-Coder-6.7B和DeepSeek-Coder-33B等系列版本。

2023年11月29日,DeepSeek公司发布了DeepSeek LLM大语言模型,包括:DeepSeek-LLM-7B-Base、DeepSeek-LLM-7B-Chat、DeepSeek-LLM-67B-Base、DeepSeek-LLM-67B-Chat共计4个版本。
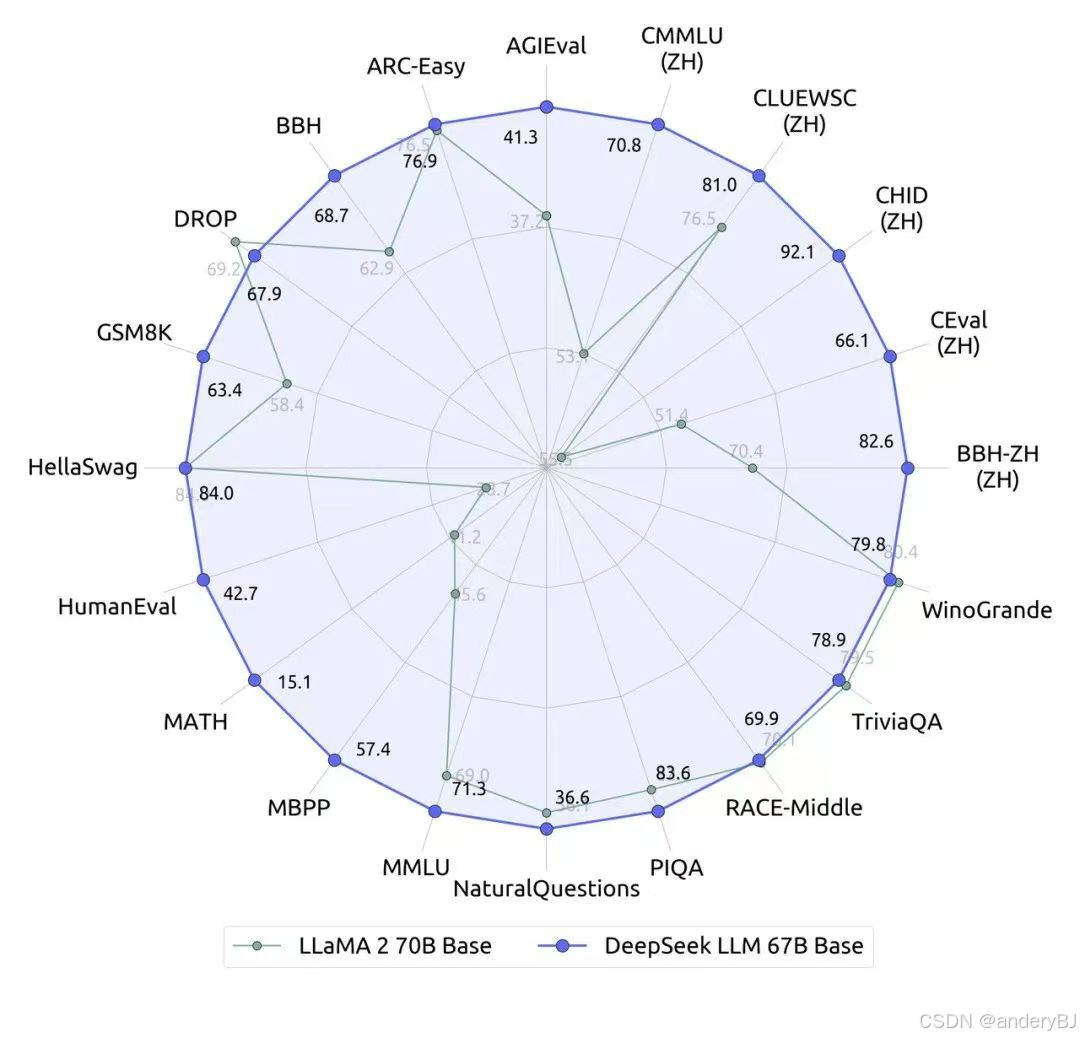
2024年2月6日,DeepSeek公司发布了DeepSeek Math数学大模型,包括:DeepSeekMath-Base 7B、DeepSeekMath-Instruct 7B和DeepSeekMath-RL 7B共计3个版本。
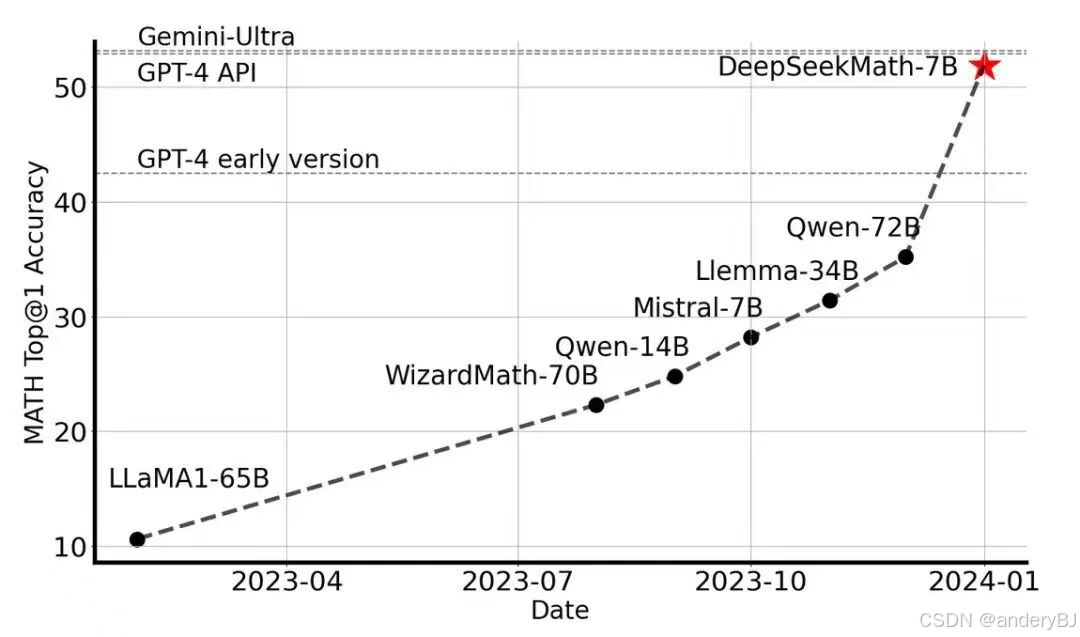
DeepSeekMath,一个7B模型但有逼近GPT-4的数学推理能力,在MATH基准榜单上超过一众30B~70B的开源模型。
2024年3月11日,DeepSeek公司发布了DeepSeek VL大模型,包括:DeepSeek-VL-7B-base、DeepSeek-VL-7B-chat、DeepSeek-VL-1.3B-base和DeepSeek-VL-1.3B-chat共计4个版本。
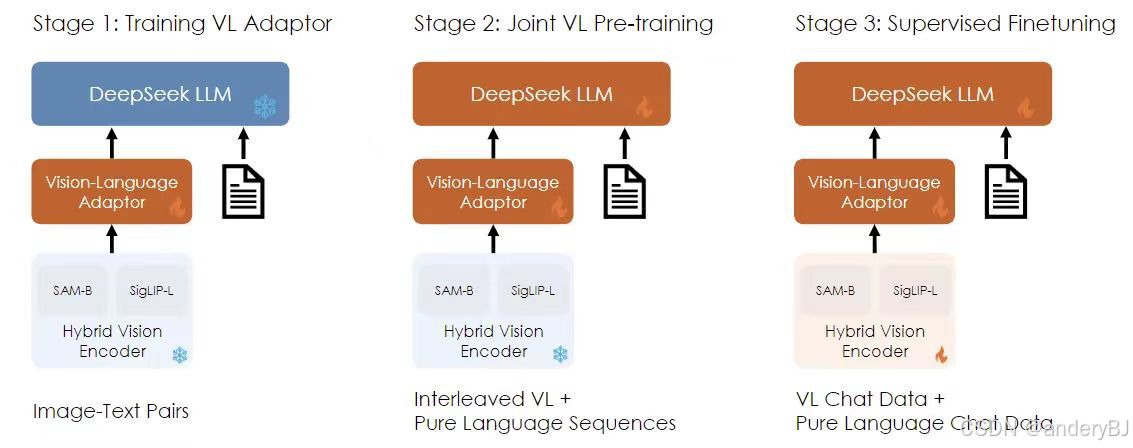
2024年5月6日,DeepSeek公司发布了DeepSeek-V2大模型,并于2024年5月16日发布了其轻量化版本DeepSeek-V2-Lite。DeepSeek-V2是一款强大且经济高效的混合专家(Mixture-of-Experts,MoE)语言模型,其特点是经济的训练成本以及高效的推理能力。它总共包含2360亿(236B)个参数(是DeepSeek LLM的3.5倍),其中每个基本单元(token)能够激活210亿(21B)个参数。与DeepSeek LLM 67B相比,DeepSeek-V2的性能更强,同时节省了42.5%的训练成本,减少了93.3%的键值(Key Value,KV)缓存,最大生成吞吐量提高到5.76倍。
2024年6月14日,DeepSeek公司发布了DeepSeek-Coder-V2代码大模型,一款开源的混合专家(MoE)代码大模型。DeepSeek-Coder-V2在DeepSeek-V2的基础上进一步训练,增加了6万亿个基本单元(token)。通过这种持续的训练,DeepSeek-Coder-V2大大增强了DeepSeek-V2的编码和数学推理能力。此外,DeepSeek-Coder-V2将其对编程语言的支持从86种扩展到338种,同时将上下文长度从16K扩展到128K。
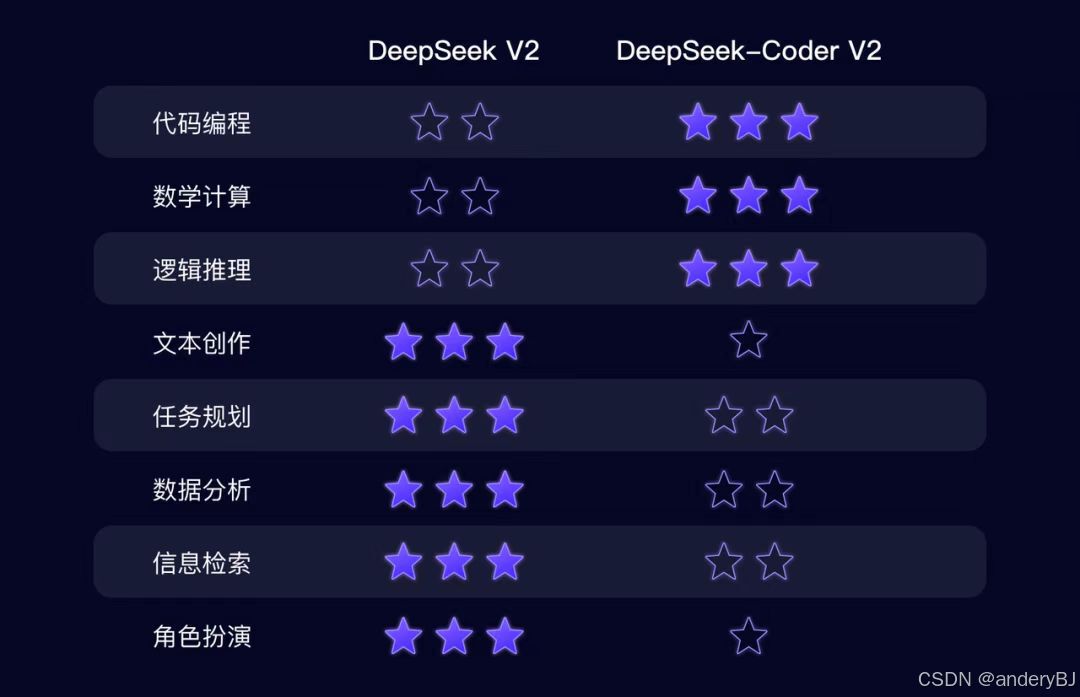
2024年9月5日,DeepSeek公司发布了DeepSeek-V2.5大模型,实现了DeepSeek-V2-Chat和DeepSeek-Coder-V2两个大模型的合并。DeepSeek-V2.5 不仅保留了原有 Chat 模型的通用对话能力和 Coder 模型的强大代码处理能力,还更好地对齐了人类偏好。此外,DeepSeek-V2.5 在写作任务、指令跟随等多个方面也实现了大幅提升。
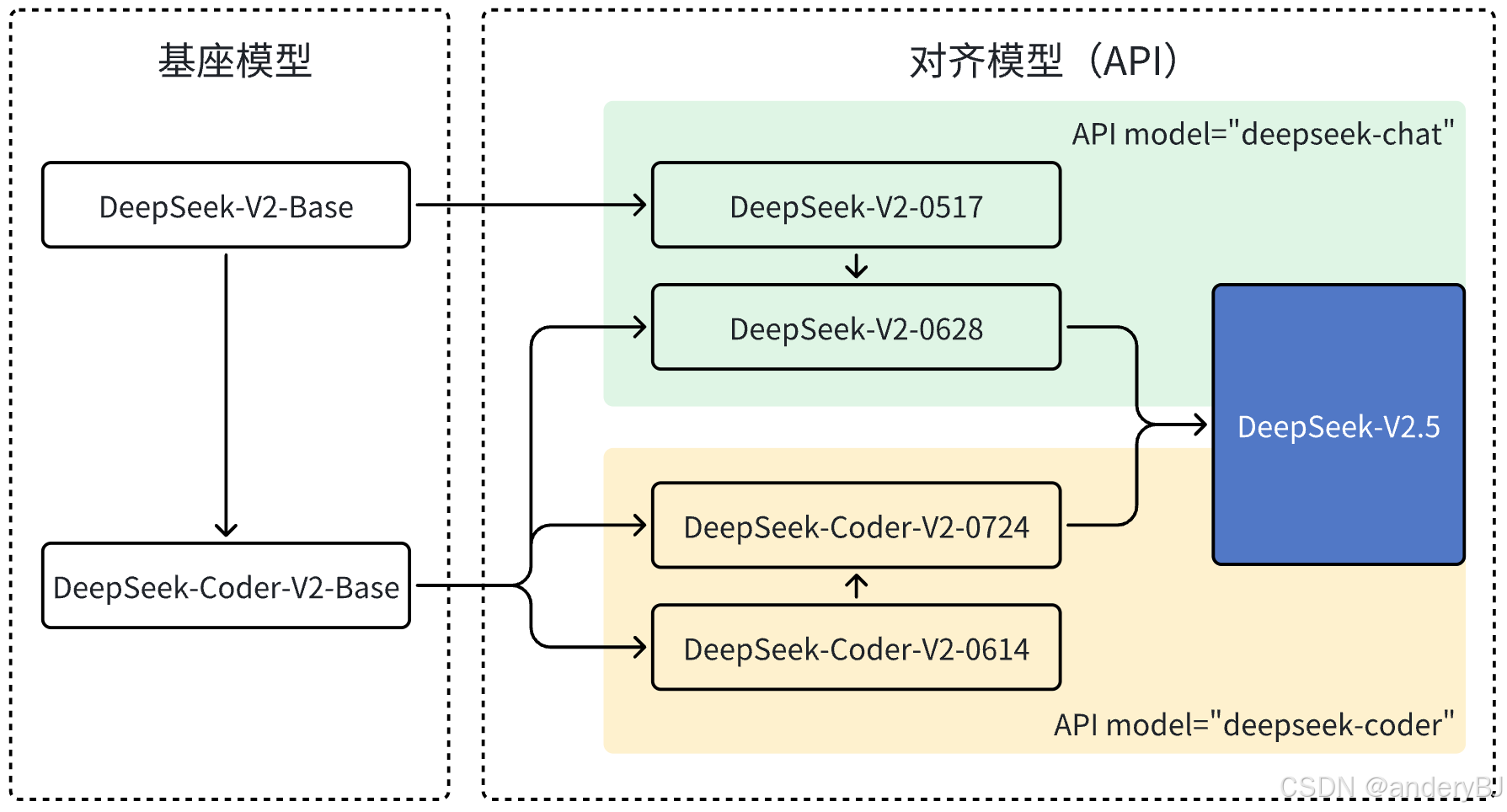
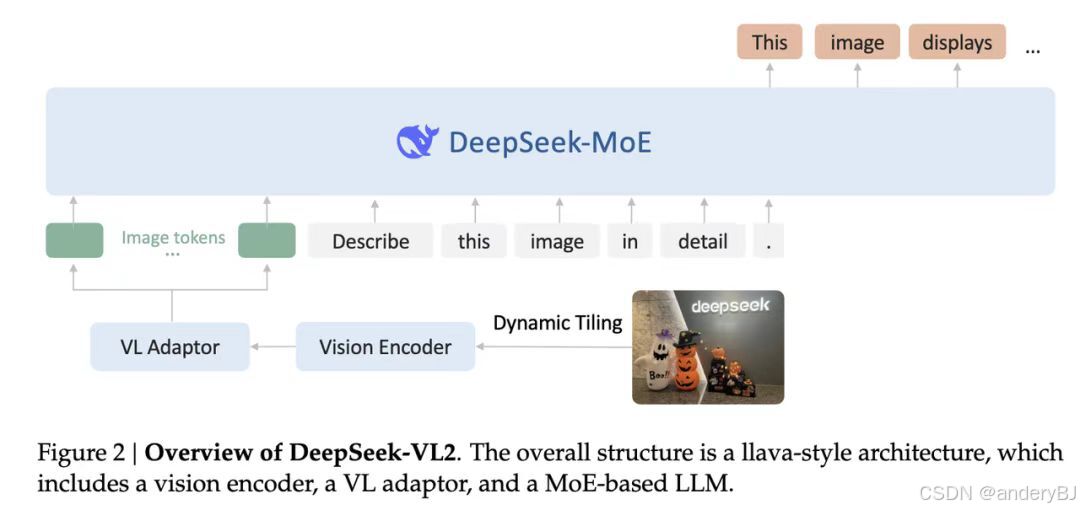
2024年12月13日,DeepSeek公司发布了DeepSeek-VL2视觉大模型,一款先进的大型混合专家(MoE)视觉大模型,采用DeepSeek-MoE架构配合动态切图,在其前身DeepSeek-VL的基础上进行了显著改进。DeepSeek-VL2在各种任务中展示了卓越的能力,包括但不限于视觉问答、光学字符识别、文档/表格/图表理解和视觉基础。该模型系列由三个变体组成:DeepSeek-VL2-tiny、DeepSeek-VL2-small和DeepSeek-VL2,激活参数分别为1.0B、2.8B和4.5B。
2024年12月26日,DeepSeek公司发布了DeepSeek-V3大模型,一款强大的混合专家(MoE)大模型,具有6710亿(671B)个参数,每个基本单元(token)激活370亿(37B)个参数。为了实现高效的推理和低成本的训练,DeepSeek-V3采用了多头潜在注意力(Multi-head Latent Attention,MLA)架构和DeepSeek-MoE架构。此外,DeepSeek-V3开创了负载平衡的辅助无丢失策略,并为更强的性能设置了多令牌(token)预测训练目标。在14.8万亿(14.8T)个不同的高质量令牌(token)上进行了预训练,然后进行监督微调和强化学习阶段,以充分利用其能力。
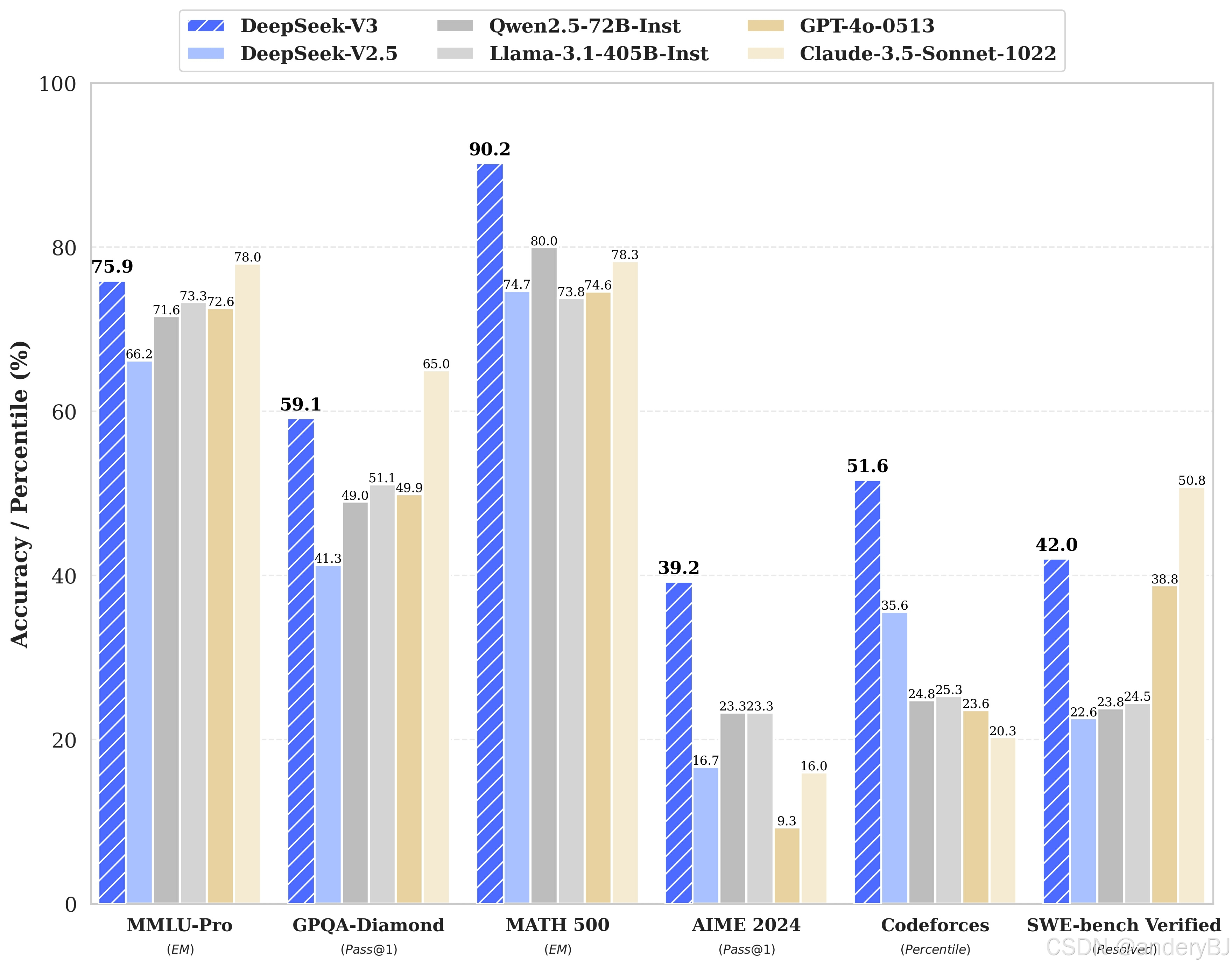
由上图可以看出,DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
2025年1月20日,DeepSeek公司发布了DeepSeek-R1大模型,是第一代推理模型,有两个版本:DeepSeek-R1-zero和DeepSeek-R1。DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,没有监督微调(SFT)作为起始步骤,在推理方面表现出卓越的性能。有了强化学习,DeepSeek-R1-Zero自然就出现了许多强大而有趣的推理行为。然而,DeepSeek-R1-Zero遇到了诸如无休止的重复、可读性差和语言混合等挑战。为了解决这些问题并进一步提高推理性能,我们引入了DeepSeek-R1,它在强化学习之前包含了冷启动数据。开源了DeepSeek-R1- zero, DeepSeek-R1,以及基于Llama和Qwen的DeepSeek-R1提炼的六个密集模型。
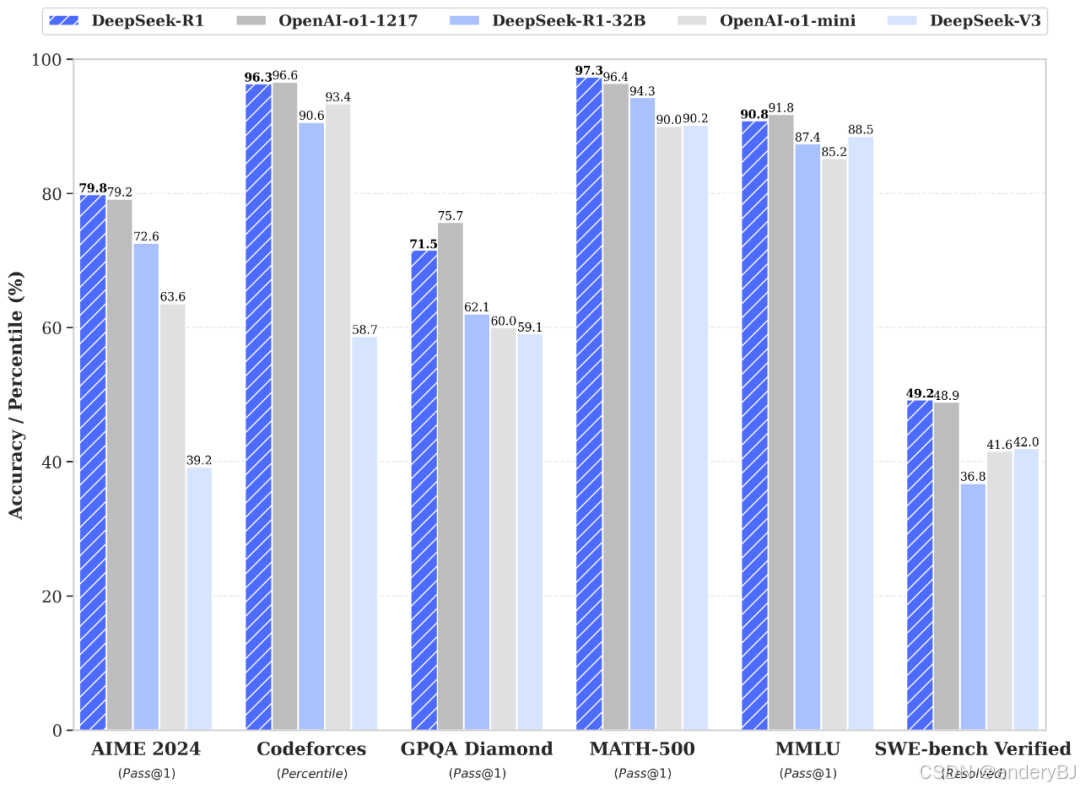
由上图可以看出,DeepSeek-R1的性能已对齐OpenAI-o1正式版。
三、深度求索(DeepSeek)大模型App初体验
2025年1月15日,DeepSeek公司发布了DeepSeek官方App,是一款功能强大的掌上助手,用户在移动终端安装后即可免费与性能世界领先的DeepSeek-V3(目前是更先进的DeepSeek-R1)模型进行互动交流。

支持联网搜索与深度思考模式,同时支持文件上传,能够扫描读取各类文件及图片中的文字内容,随时随地为用户答疑解惑、实现学习办公提效。
用户可以通过检索关键词“DeepSeek”从各大应用市场获取,也可以通过官方网站首页直接获取各应用市场内下载链接。
注册后,在DeepSeek App中选中“深度思考(R1)”和“联网搜索”功能,然后在输入框中输入需要提问的问题,这里输入“DeepSeek与OpenAI的性能对比”,DeepSeek的回答如下:

DeepSeek App在收到指令后,先是给出整个深度思考的过程,然后,再给出深度思考后的结果。
作者信息:朱赛,18210821611,zhusai@cesi.cn

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)