DeepSeek R1 本地部署保姆级教程
DeepSeek 是一个强大的 AI 模型,通过 Ollama 这个便捷工具,我们可以轻松实现本地部署。Ollama 不仅支持 DeepSeek,还支持通义千问等多个开源模型,是一个非常实用的 AI 模型运行平台。
本教程将指导您如何使用 Ollama 在本地轻松部署 DeepSeek 模型,即使您不是技术专家也能轻松上手。
一、前言
DeepSeek 是一个强大的 AI 模型,通过 Ollama 这个便捷工具,我们可以轻松实现本地部署。Ollama 不仅支持 DeepSeek,还支持通义千问等多个开源模型,是一个非常实用的 AI 模型运行平台。
二、安装 Ollama
- 访问 Ollama 官网:https://ollama.com/
- 点击 “Download” 按钮
- 选择适合您系统的版本下载(本教程以 Windows 为例)
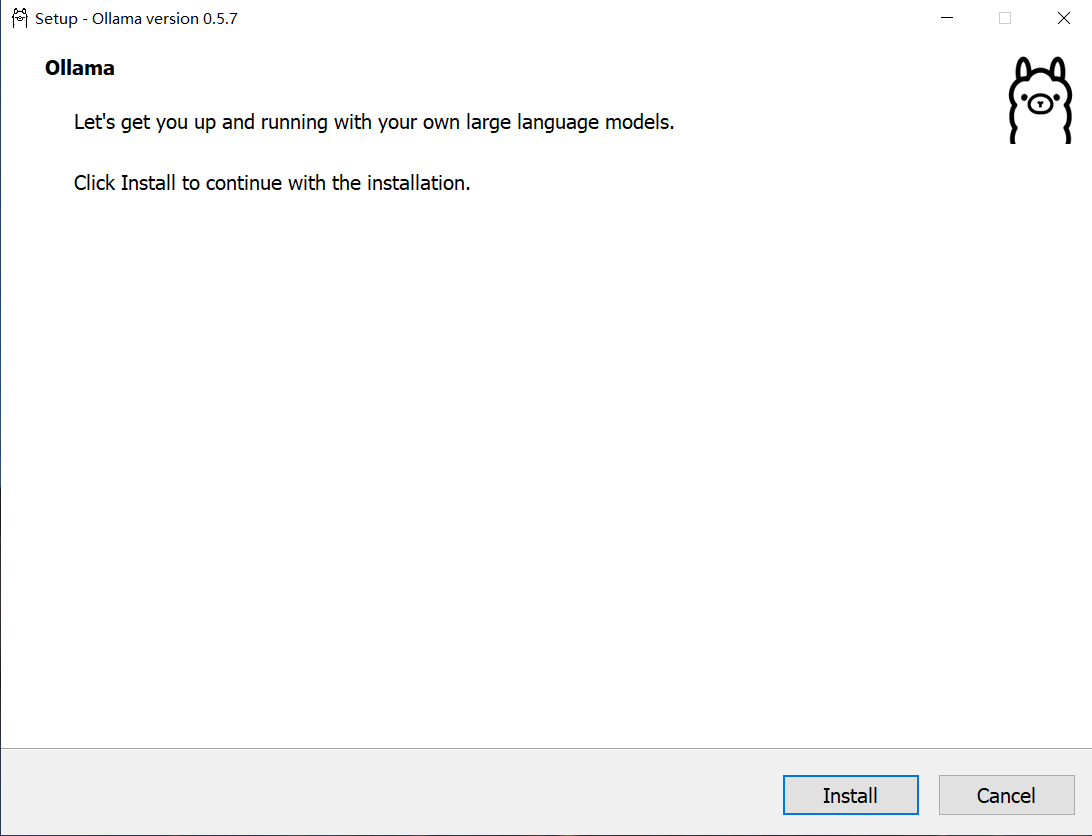
- 下载完成后运行安装程序
- 点击 “Install” 按钮完成安装
提示:如果下载速度较慢,可以尝试使用迅雷等下载工具加速。

三、选择并下载模型
-
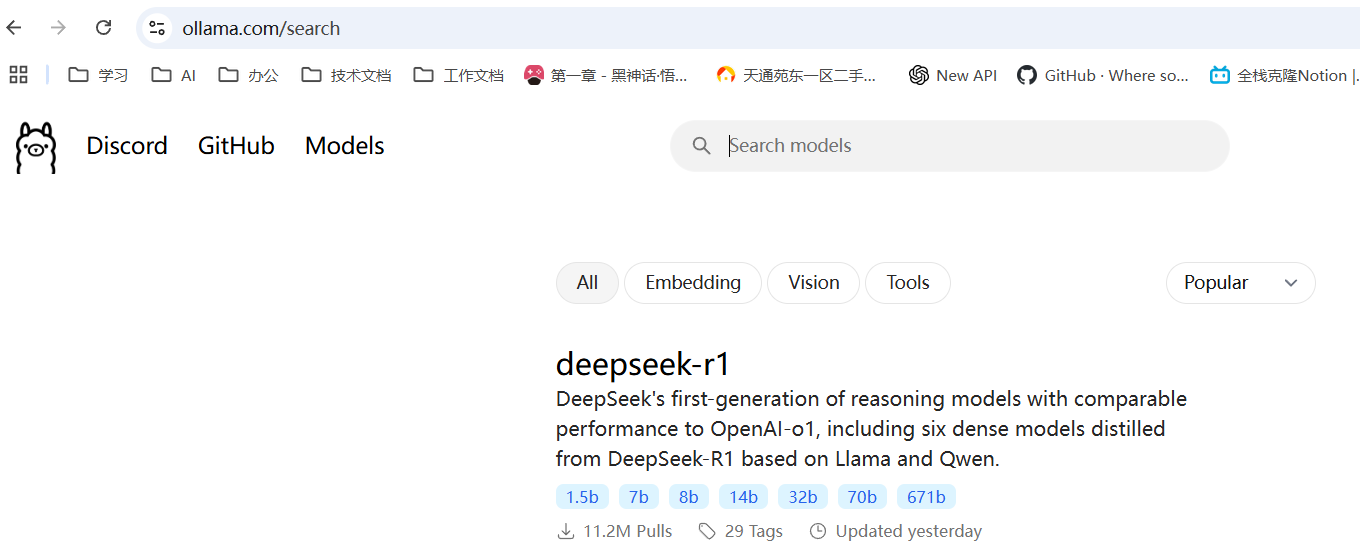
在 Ollama 官网点击左上角 “Models”
-
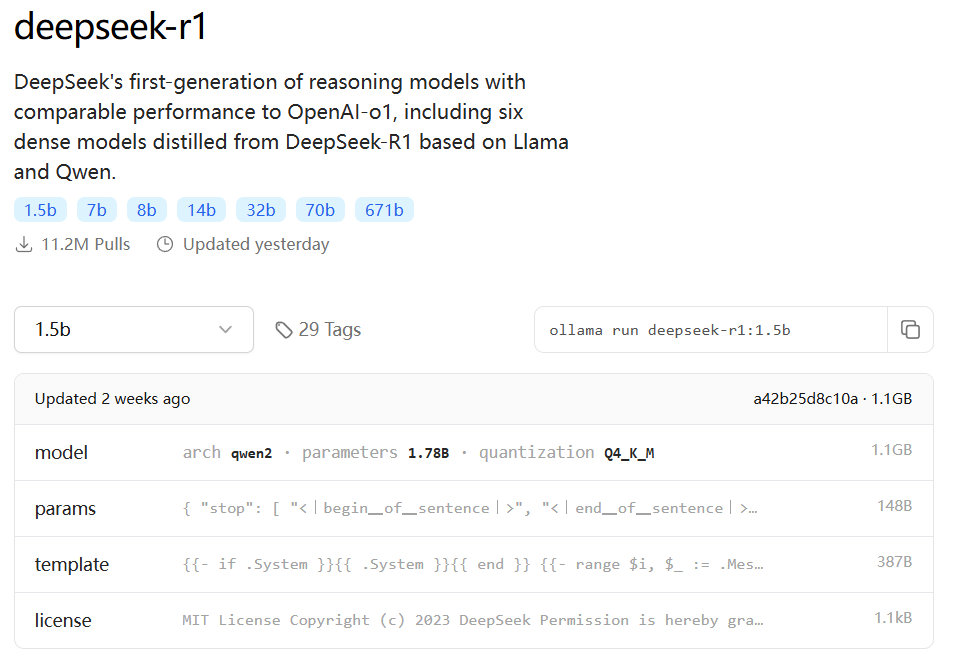
找到 deepseek-r1 系列模型
-
根据您的设备配置选择合适的模型版本:
- 入门级设备建议选择 1.5b 版本
- 性能较好的设备可以尝试 7b 或 14b 版本
- 具体选择可以参考设备配置要求
- 打开命令提示符(Win+R 输入 cmd)
- 输入模型下载命令:
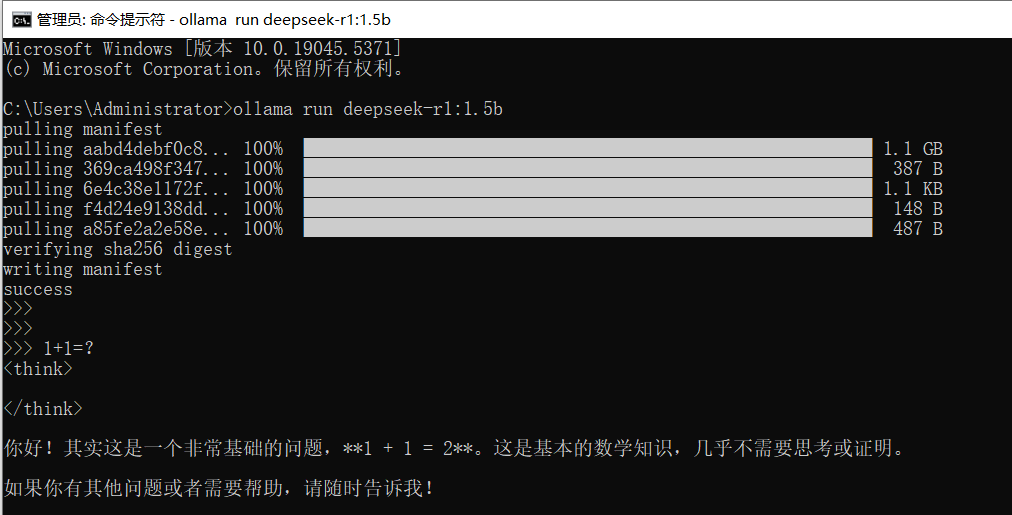
ollama run deepseek-r1:1.5b # 1.5b版本 # 或 ollama run deepseek-r1:7b # 7b版本 # 或 ollama run deepseek-r1:14b # 14b版本
四、使用模型对话
- 模型下载完成后会自动进入对话模式
- 在提示符
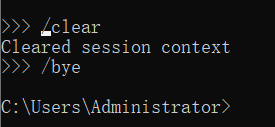
>>>后输入问题并按回车 - 常用命令:
/clear- 清除上下文,重新开始对话/bye- 退出对话模式- 直接输入问题 - 开始对话
五、日常使用说明
启动模型
- 按 Win+R 打开运行
- 输入 cmd 打开命令提示符
- 输入启动命令:
ollama run 模型名称
例如:ollama run deepseek-r1:1.5b
模型管理命令
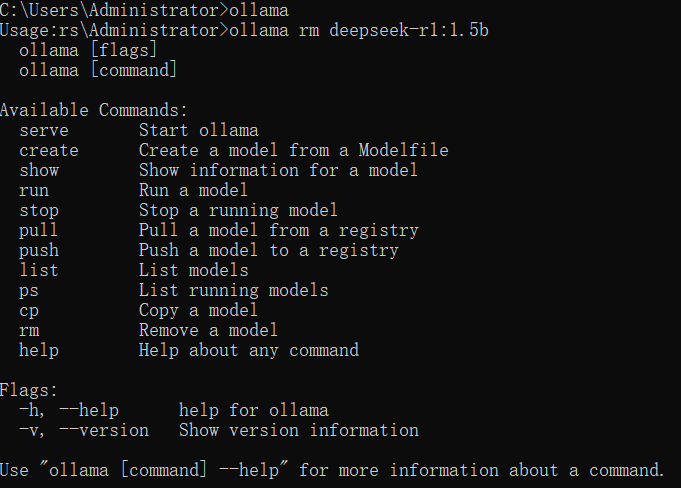
-
查看已安装模型:
ollama list -
删除模型:
ollama rm 模型名称
例如:ollama rm deepseek-r1:1.5b -
查看所有命令:直接输入
ollama

六、注意事项
-
硬件要求:
- 1.5b 版本:最低 8GB 内存
- 7b 版本:建议 16GB 以上内存
- 14b 版本:建议 32GB 以上内存
-
存储空间:
- 请确保有足够的硬盘空间(模型文件较大)
- 1.5b 约需 3GB
- 7b 约需 15GB
- 14b 约需 30GB
-
使用建议:
- 首次使用建议从小模型开始尝试
- 确保网络稳定,避免下载中断
- 使用时保持电脑有足够的可用内存
七、常见问题解答
-
Q: 模型下载速度慢怎么办?
A: 可以尝试使用迅雷等下载工具,或者在网络良好的环境下进行下载 -
Q: 如何切换不同的模型?
A: 退出当前模型对话后,使用ollama run命令启动其他模型 -
Q: 模型占用空间太大怎么办?
A: 可以使用ollama rm命令删除不常用的模型,需要时再重新下载 -
Q: 运行时提示内存不足?
A: 尝试使用更小的模型版本,或关闭其他占用内存的程序
八、通过 API 接口访问模型
1. API 基本信息
- 默认 API 地址:
http://localhost:11434/api - 支持的请求方式:POST
- 数据格式:JSON
2. 主要 API 接口
生成回答(Generate)
curl -X POST http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:1.5b",
"prompt": "你好,请介绍一下自己",
"stream": false
}'
聊天对话(Chat)
curl -X POST http://localhost:11434/api/chat -d '{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "你好,请介绍一下自己"
}
],
"stream": false
}'
3. Python 示例代码
import requests
def chat_with_model(prompt):
url = "http://localhost:11434/api/chat"
data = {
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": prompt
}
],
"stream": False
}
response = requests.post(url, json=data)
return response.json()
# 使用示例
response = chat_with_model("你好,请介绍一下自己")
print(response['message']['content'])
4. JavaScript 示例代码
async function chatWithModel(prompt) {
const url = "http://localhost:11434/api/chat";
const data = {
model: "deepseek-r1:1.5b",
messages: [
{
role: "user",
content: prompt,
},
],
stream: false,
};
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
return await response.json();
}
// 使用示例
chatWithModel("你好,请介绍一下自己")
.then((response) => console.log(response.message.content))
.catch((error) => console.error("Error:", error));
5. 注意事项
- 确保 Ollama 服务正在运行
- API 默认只监听本地请求(localhost)
- 如需远程访问,需要配置 Ollama 允许远程连接
- 建议在生产环境中添加适当的安全措施
- stream 参数设置为 true 时可获得流式响应
6. 常见问题
-
Q: 无法连接到 API?
A: 检查 Ollama 服务是否正常运行,默认端口 11434 是否被占用 -
Q: 如何处理流式响应?
A: 将 stream 参数设置为 true,并相应调整代码以处理流式数据 -
Q: 如何设置超时时间?
A: 在请求时添加适当的超时设置,避免长时间等待

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 32
32 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)