广告行业中那些趣事系列97:从理论到实践详解国货之光DeepSeek大模型
导读:本文是“数据拾光者”专栏的第九十七篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要从理论到实践详解了国货之光DeepSeek,普通人也可以很简单的构建自己的DeepSeek大模型。欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。知乎专栏:数据拾光者公众号:数据拾光者最近铺天盖地的都是DeepSeek大模型的消息,作为国货之光,不仅
导读:本文是“数据拾光者”专栏的第九十七篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要从理论到实践详解了国货之光DeepSeek,普通人也可以很简单的构建自己的DeepSeek大模型。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
最近铺天盖地的都是DeepSeek大模型的消息,作为国货之光,不仅效果媲美GPT-4,而且成本非常低,还开源。以前如果想玩大模型,硬件成本极高,基本只能大厂玩玩。现在DeepSeek的出现,这使得很多中小公司也有机会加入这场AI盛宴,尤其还是咱们自己弄出来的。感觉这波流量要赶超之前大火的ChatGPT了。
也不知道是真的那么火,还是上面想让咱们产生浓浓的民族自豪感。但是不管怎么样,作为AI行业的老兵,这个模型肯定是要学习的。本篇会详细介绍下DeepSeek架构的核心技术,以及咱们普通人怎么玩DeepSeek。
文章导读,如果对DeepSeek架构里牛逼的技术不怎么感冒,只想了解下普通人怎么用DeepSeek大模型,可以直接跳转到第三章和第四章。如果想大概了解下核心技术,也可以看看前两章。
01 DeepSeek以及背后的幻方量化
DeepSeek(杭州深度求索人工智能基础技术研究有限公司)是一家专注于通用人工智能(AGI)和大语言模型(LLM)研发的创新型科技公司,成立于2023年7月。DeepSeek由国内头部量化私募基金幻方量化孵化并全资控股,是幻方在人工智能领域的核心布局。公司致力于通过大模型推动AGI发展,其核心技术结合了大语言模型与搜索引擎能力,通过实时检索增强模型的知识库,解决了传统LLM的幻觉和时效性不足等问题。
DeepSeek的模型以低成本和高效能著称。例如,其DeepSeek-V3模型采用自研的MoE架构,拥有6710亿参数规模,训练成本仅约557万美元,远低于同等级模型。此外,DeepSeek还发布了多款开源与闭源大模型,如DeepSeek-R1,部分性能对标GPT-4,但成本仅为1/20。
DeepSeek背后的幻方量化是一家中国领先的量化对冲基金公司,成立于2015年,专注于将人工智能技术应用于投资交易。公司由浙江大学的顶尖人才团队创立,核心成员在2008年全球金融危机期间就开始探索量化交易与机器学习的结合。幻方量化在量化投资领域深耕多年,拥有强大的技术团队和先进的量化投资技术,管理规模逾60亿元。
幻方量化在技术研发上投入巨大,2019年投资2亿元自主研发深度学习训练平台“萤火一号”,2021年又投入10亿元用于“萤火二号”的研发,搭载约1万张英伟达A100显卡,为量化投资和AI研发提供了坚实基础。幻方量化将AI技术应用于信号发现、投资组合优化、交易执行优化等多个方面,取得了较为稳定的优化效果。
DeepSeek与幻方量化之间的关系可以概括为“子公司与母公司”的协同模式:
-
孵化与股权关系:DeepSeek由幻方量化孵化成立,幻方量化全资控股DeepSeek,并将其定位为通用人工智能和大模型研发的技术引擎。
-
技术协同:DeepSeek的技术直接服务于幻方量化的量化投资业务,例如通过大模型分析市场数据、优化交易策略以及降低技术成本。DeepSeek发布的模型已被幻方量化用于实际投资。
-
独立运营与商业化:尽管DeepSeek由幻方量化孵化,但它已发展为独立运营的实体,专注于AGI技术的研发,并对外开源和商业化。DeepSeek模型采用MIT协议开源,并提供API接口服务,客户包括企业、科研机构等。
-
资源支持:幻方量化为DeepSeek提供了算力、资金和数据支持。例如,幻方量化投资数千万美元建设了由英伟达A100芯片组成的超级计算集群,这些资源为DeepSeek的模型训练提供了强大支持。
总结来说,幻方量化与DeepSeek的关系可以比喻为“AI大脑与金融躯干”:DeepSeek是幻方量化的技术引擎,既为母公司提供技术支持,也独立发展形成技术生态。
02 DeepSeek架构核心技术介绍
DeepSeek架构通过MoE、MLA、MTP等技术的结合,实现了高效、灵活且强大的AI系统。MoE提升计算效率,MLA增强信息处理能力,MTP优化多任务学习,这些技术共同推动了AI的进步。下面是核心技术介绍:
2.1 MoE专家混合
MoE(Mixture of Experts,专家混合)是一种强大的机器学习和深度学习架构,通过将复杂任务分解为多个子任务,并由多个“专家”子模型分别处理,从而提高模型的效率和可扩展性。以下是关于MoE的详细介绍:
(1)MoE核心概念
MoE的核心思想是“分而治之”,即将复杂任务分解为多个较简单的子任务,每个子任务由一个专门的“专家”模型负责处理。MoE模型由以下三个关键组件构成:
-
专家(Experts):每个专家是一个独立的子模型,可以是神经网络、决策树等,负责处理输入数据的一个子集或特定任务。
-
门控网络(Gating Network):门控网络决定输入数据应分配给哪些专家。它基于输入特征生成权重分布,用于选择和组合专家的输出。
-
加权输出:最终结果由门控网络给出的权重对专家的预测进行加权求和得到。
(2)MoE工作原理
MoE的工作流程可以概括为“任务分解-专家处理-结果汇总”:
-
输入数据进入系统后,门控网络首先分析输入数据的特征,计算出每个专家的激活概率。
-
每个被激活的专家网络独立处理输入数据的一部分,并产生相应的输出。
-
所有专家的输出根据门控网络的激活概率进行加权组合,形成最终的模型输出。
(3)MoE优势
-
更高的可扩展性:MoE通过稀疏激活机制,只激活部分专家来处理输入,从而在不牺牲性能的情况下减少计算开销。这使得模型可以轻松扩展到数十亿甚至数万亿参数。
-
更高的效率:与传统密集模型相比,MoE在训练和推理过程中计算成本更低,速度更快。
-
更好的灵活性:MoE可以针对不同任务或数据子集训练不同的专家,使其在处理复杂任务时更具优势。
(4)MoE应用领域
-
自然语言处理(NLP):在机器翻译、情感分析等任务中,MoE可以集成多个模型,提高文本理解和生成的质量。
-
计算机视觉:在图像分类、物体检测等任务中,MoE能够结合多个专家模型的特点,提升模型对图像的表征和理解能力。
-
推荐系统:MoE可以将多个推荐模型组合起来,提供更准确和个性化的推荐结果。
-
药物研发:MoE在基于结构的设计、药效团发现、蛋白质和抗体建模等领域也有广泛应用。
(5)MoE挑战
尽管MoE具有诸多优势,但在实际应用中也面临一些挑战,例如:
-
训练复杂性:MoE模型的训练过程较为复杂,需要分别训练专家和门控网络。
-
通信成本:MoE的分布式训练需要大量的机间通信,对网络带宽提出了较高要求。
-
微调困难:在微调阶段,MoE模型可能面临一些挑战,但相关研究正在不断取得进展。
总体而言,MoE作为一种高效的模型架构,通过专家分工和稀疏激活机制,在处理复杂任务和大规模数据时展现出了显著的优势,已成为现代AI架构中的重要基石。
2.2 MLA多级注意力机制
MLA(Multi-Level Attention,多级注意力机制)是一种在深度学习中用于处理复杂数据和任务的注意力机制架构,它通过在不同层次上应用注意力机制,能够更全面地捕捉数据中的特征和信息。以下是关于MLA的详细介绍:
(1)MLA的定义与背景
MLA是一种多级结构的注意力机制,旨在通过多层次的特征提取和融合,提升模型对复杂数据的理解能力。它通常应用于自然语言处理(NLP)、计算机视觉(CV)等领域,用于处理长序列数据、多模态数据等复杂任务。
(2)MLA的工作原理
MLA的核心在于多层次的特征提取和融合,具体实现方式可能因应用场景而异,但通常包括以下几个关键步骤:
-
多模态特征提取:从不同模态(如文本、图像等)中提取特征。
-
多级特征融合:将不同层次的特征(如低层次的单词特征和高层次的语义特征)进行融合。
-
注意力机制应用:在每个层次上应用注意力机制,动态地关注重要的特征或信息。
(3)MLA的具体实现
以DeepSeek V3中的多头潜在注意力(Multi-Head Latent Attention,MLA)为例,其主要特点包括:
-
低秩压缩:将键(Key)和值(Value)联合压缩成一个潜在向量,显著降低KV缓存。
-
解耦的键和查询:引入RoPE(Rotary Positional Embedding,旋转式位置编码)的解耦键和查询,分别通过不同的矩阵生成。
-
多头注意力:通过多个头的并行计算,同时关注不同位置和语义层面的信息。
(4)MLA的优势
-
高效性:通过低秩压缩和解耦机制,MLA显著降低了计算复杂度和内存开销。
-
鲁棒性:多级特征融合能够有效缓解噪声词的影响,提升模型的鲁棒性。
-
全局感知:能够同时关注局部和全局信息,提供更全面的特征表示。
(5)MLA的应用场景
-
自然语言处理:用于机器翻译、文本生成等任务,提升对长序列和复杂语义的理解。
-
计算机视觉:在视觉导航、图像分类等任务中,融合视觉和语义特征。
-
多模态任务:如视觉与语言导航(VLN),通过多级特征融合提升任务表现。
(6)MLA的挑战与未来方向
尽管MLA在多个领域展现了显著优势,但其设计和实现较为复杂,需要针对具体任务进行优化。未来的研究方向可能包括进一步降低计算成本、提升模型的可扩展性以及探索更多应用场景。
总之,MLA通过多层次的特征提取和融合,显著提升了模型对复杂数据的理解能力,是当前深度学习领域的重要研究方向之一。
2.3 MTP多任务学习与任务特定投影
MTP(Multi-Task Learning with Task-specific Projections,多任务学习与任务特定投影)是一种多任务学习方法,旨在通过共享和任务特定的网络结构,提高模型在多个相关任务上的学习效率和性能。以下是关于MTP的详细介绍:
(1)MTP的定义与背景
MTP是一种多任务学习(MTL)架构,通过在共享网络结构的基础上添加任务特定的投影层,来解决多任务学习中的任务冲突和负迁移问题。这种方法结合了硬参数共享(hard-parameter sharing)和任务特定参数(task-specific parameters)的优点,既利用了任务之间的共享知识,又保留了任务之间的差异。
(2)MTP的工作原理
MTP的核心在于其网络架构设计,具体包括以下几个部分:
共享主干网络(Shared Backbone):所有任务共享一个主干网络,用于提取通用特征。这个主干网络通常是一个深度神经网络,负责学习任务之间的共享知识。
任务特定投影层(Task-specific Projections):在共享主干网络的基础上,为每个任务添加任务特定的投影层。这些投影层通过低秩线性层或投影模块实现,允许模型为每个任务学习特定的特征表示。
特征融合与输出:共享主干网络的输出与任务特定投影层的输出结合,形成每个任务的最终特征表示,然后通过任务特定的输出层生成预测结果。
(3)MTP的优势
减少任务冲突:通过任务特定的投影层,MTP能够更好地处理任务之间的差异,减少任务之间的冲突和负迁移。
提高学习效率:共享主干网络使得模型能够利用任务之间的共享知识,从而提高学习效率。
更好的泛化能力:MTP通过结合共享和任务特定的特征表示,能够更好地泛化到未见过的任务。
(4)MTP的应用场景
MTP在多个领域具有广泛的应用,包括但不限于:
自然语言处理(NLP):用于多语言翻译、情感分析等任务,通过共享语言模型的主干网络,同时为每种语言或任务添加特定的投影层。
计算机视觉(CV):在多目标检测、图像分类等任务中,MTP可以共享特征提取网络,同时为每个任务学习特定的分类器。
强化学习(RL):在多任务强化学习中,MTP通过共享策略网络和任务特定的调整层,提高机器人在多个相关任务上的学习效率。
(5)MTP的挑战与未来方向
尽管MTP在多任务学习中展现了显著的优势,但其设计和实现较为复杂,需要在任务选择、网络结构设计和训练策略等方面进行精细调整。未来的研究方向可能包括进一步优化任务特定投影层的设计、探索更高效的训练算法以及扩展到更多任务和领域。
总之,MTP通过结合共享和任务特定的网络结构,有效地解决了多任务学习中的任务冲突和负迁移问题,是当前多任务学习领域的重要研究方向之一。
2.4 DPM对偶流水线机制
DPM(Dual Pipeline Mechanism,对偶流水线机制)是一种用于优化大规模模型训练的技术,特别是在深度学习和大规模分布式训练中。该机制通过高效的流水线调度,显著提升了计算资源的利用率,减少了训练过程中的瓶颈。
(1)DPM核心原理
对偶流水线机制的核心在于将模型训练过程中的计算任务和通信任务进行并行处理。具体来说:
计算与通信的并行隐藏:在传统的流水线并行中,计算和通信通常是顺序执行的,这会导致计算设备(如GPU)在通信过程中闲置,形成“气泡”(即闲置时间)。对偶流水线机制通过设计极致的流水线调度,将计算任务和通信任务并行化,使得GPU在执行计算任务的同时,通信任务也在后台进行,从而减少了闲置时间。
减少流水线中的“气泡”:理论上,对偶流水线机制可以将GPU指令执行流水线中的“气泡”减少接近一半,从而显著提高硬件利用率。
(2)DPM应用优势
-
提升硬件利用率:通过对计算和通信任务的并行处理,对偶流水线机制能够最大限度地减少GPU的闲置时间,从而提高硬件资源的利用率。
-
降低通信开销:该机制通过限制每个token发送到GPU集群节点的数量,保持较低的通信开销,进一步优化了训练效率。
-
支持大规模模型训练:对偶流水线机制特别适用于大规模模型训练,能够有效解决单卡存储限制,支持远超单卡容量的模型训练。
(3)DPM实际应用
对偶流水线机制在DeepSeek-V3模型中得到了应用。DeepSeek-V3通过该机制实现了高效的训练过程,显著提升了模型的训练速度和资源利用率。此外,该机制还可以应用于其他需要大规模并行计算的场景,如自然语言处理和计算机视觉中的超大规模模型训练。
总之,对偶流水线机制通过优化流水线调度,显著提高了大规模模型训练的效率和资源利用率,是当前深度学习领域中一种重要的优化技术。
2.5 FP8混合精度训练架构
DeepSeek采用了FP8混合精度训练架构。这种架构通过灵活使用不同精度的数字表示,加快了计算速度并降低了通信开销。这使得DeepSeek能够在低性能硬件上实现高效的训练,降低了硬件成本。
2.6 多模态框架
DeepSeek还发布了多模态框架,如Janus-Pro和JanusFlow。这些框架通过解耦视觉编码和融合生成流,提升了模型在多模态任务中的适配性和性能。
2.7 优化的训练策略
DeepSeek在训练过程中采用了多种优化策略:
-
数据并行和模型并行:通过数据并行、张量并行、序列并行和1F1B流水线并行等策略,提高了硬件利用率,加快了模型的训练速度。
-
优化的学习率调度器:使用多阶段学习率调度器,确保模型在不同训练阶段保持最佳的学习速率。
-
强化学习替代监督微调:通过强化学习替代传统的监督微调,进一步提升了模型的性能。
03 DeepSeek最火的两个模型
DeepSeek目前最火的两个大模型是DeepSeek V3和DeepSeek-R1。下面是两个模型对比:
3.1 架构方面
DeepSeek V3基于改进的Transformer架构,Transformer层数为61层,引入动态注意力机制,能根据输入文本实时特征自动调整注意力权重。采用专家混合(MoE)架构,总参数量为6710亿,每次处理激活370亿参数;DeepSeek-R1采用多模态融合架构,包含文本编码器、图像编码器、音频编码器和多模态融合层。同样基于MoE架构,总参数量为6710亿,每次激活370亿参数。Transformer层数也是61层。多种模态对应的注意力机制,用于处理不同模态数据。
3.2 应用场景方面
DeepSeek V3可以应用到以下场景:
-
智能客服:能够理解用户的文本和语音输入,并提供准确的回答。其多模态能力使其能够处理包含图像或视频的复杂查询。
-
内容创作:可帮助用户生成高质量的文章、故事和代码,例如自动生成技术文档或辅助写作。
-
教育与培训:可用于开发智能教育工具,如自动批改作业、生成个性化学习内容和提供实时答疑服务。
-
医疗健康:可用于分析医学影像、生成诊断报告和提供健康建议。
-
游戏与娱乐:可用于开发智能游戏角色和虚拟助手,与玩家进行自然对话并提供个性化的游戏体验。
DeepSeek-R1可以应用到以下场景:
-
数学和逻辑问题解决:擅长解决数学和逻辑问题,可作为AI辅导老师帮助学生准备考试,如SAT和GRE。
-
金融分析:可用于分析投资风险,通过逻辑推理和模式识别增强决策。
-
跨模态检索:支持通过文本搜索图像,或通过图像生成描述文本。
-
智能交互:可用于智能家居、智能音箱等设备,实现语音识别、文本理解和图像展示等多种功能的融合。
3.3 适用性方面
DeepSeek V3的优势是具有强大的综合性能和多模态处理能力,适合广泛的应用场景,包括需要处理多种模态数据的任务。其训练成本较低,完整训练过程仅需2.788M H800 GPU小时,在资源受限的情况下具有较高的性价比。DeepSeek V3的局限性在情感理解和互动方面表现略显不足,回答较为理性和安全,但缺乏情感色彩。
DeepSeek-R1的优势是通过强化学习实现了专业领域的推理突破,尤其在数学、逻辑和金融分析等需要强推理能力的领域表现出色。其训练过程中采用了多阶段混合训练策略,包括监督微调和强化学习优化,进一步提升了性能。DeepSeek-R1的局限性在虽然在推理能力上有显著提升,但在一些非专业领域的综合表现可能不如DeepSeek V3。
简单总结就是,DeepSeek V3可以处理大多数种类任务,但是R1更擅长处理逻辑推理任务,比如数学和代码等。
04 普通人如何使用DeepSeek模型
关于普通人如何使用DeepSeek模型,主要分成以下三种方法:
4.1 官方使用方法
DeepSeek模型本身虽然是开源的,但毕竟是大模型,完全体版本拥有6710亿参数规模,一般咱们个人电脑资源有限,是没法在本地完全部署完整版模型。所以要想使用完全体版本的DeepSeek模型,最简单有效的方法就是使用官方提供的方法,主要分成官方网页版和app移动端版。在官网https://www.deepseek.com/可以分别使用:

如果是通过网页版,点击上面的开始对话就可以体验服务了。对于新用户需要提前注册一下,因为是国产大模型,不存在之前ChatGPT那种国内无法注册或者很难轻松使用的情况,只要你有手机号,在官网输入手机号注册即可:
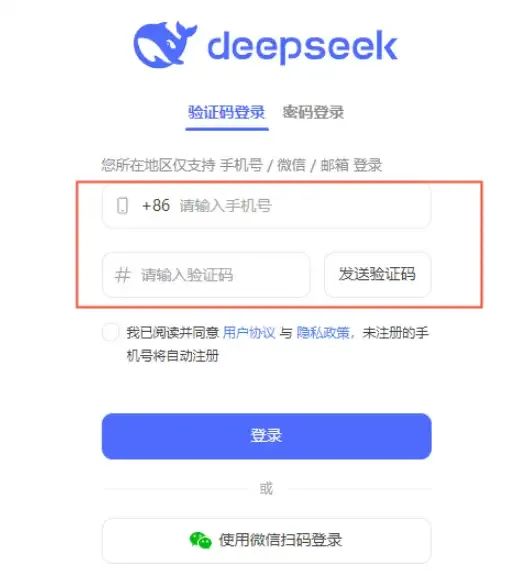
这里插一段题外话,关于赚钱的小套路。之前ChatGPT大火的时候,咱们国内没法很容易的注册,很多人就倒腾这个,通过各种小办法在国外注册,然后卖给国内需要使用ChatGPT的人。现在风水伦理转了,DeepSeek大火之后,国外的人没法轻易注册使用了。很多人又撺掇着在国内注册,然后卖给国外需要使用DeepSeek的人。所以处处是商机,重点是要快,利用信息差赚钱。
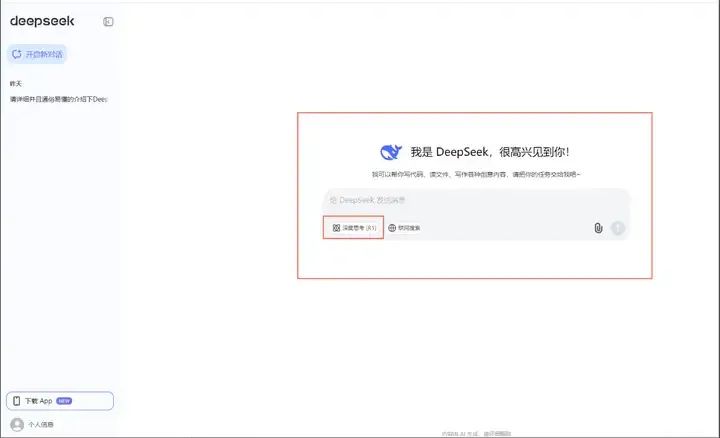
注册好了之后就会跳转到DeepSeek的主页面,这个经常使用大模型的朋友们应该很熟悉这个页面了。官方默认是DeepSeek V3模型,如果想使用R1模型,点击下面红色小框里的深度思考(R1)按钮即可,按完之后变成深色就说明使用的是DeepSeek R1模型。
app移动版本的话可以通过官网或者各大应用商店下载app,也非常方便。
4.2 使用api+客户端的方式部署
官方使用方法虽然可以使用完全体版本的DeepSeek,但是服务有时候不是那么稳定,这个原因有很多,有可能调用的人太多了,也有可能像最近由于受到各种恶意访问导致我们可能一个问题要请求好几次才能得到结果。同时,如果我们基于自身的业务想用一个完全属于自己的DeepSeek服务,那么还有个简单方法就是使用其他厂家的机器。因为DeepSeek本身已经开源,很多厂家已经在自己的机器上部署了DeepSeek模型,也可以提供类似官方的服务,并且稳定性会好一些。我们只需要通过客户端来调用这些厂商提供的DeepSeek服务就可以了。流程如下:
第一步,下载客户端。常见的客户端有OneAPI、LobeChat、NextChat、ChatBox、Cherry Studio等;
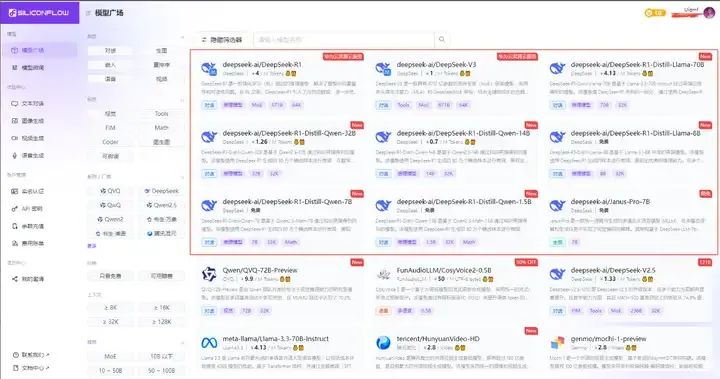
第二步,获取api。国外的英伟达、微软和亚马逊等,国内的比如硅基流动和华为云合作也上线了DeepSeek R1的API服务。这里可以简单使用硅基流动的免费套餐体验API服务。通过硅基流动官网https://siliconflow.cn/zh-cn/登录:

通过手机号登录注册之后就进入模型广场页面,前面几个就是当前主流的DeepSeek模型:
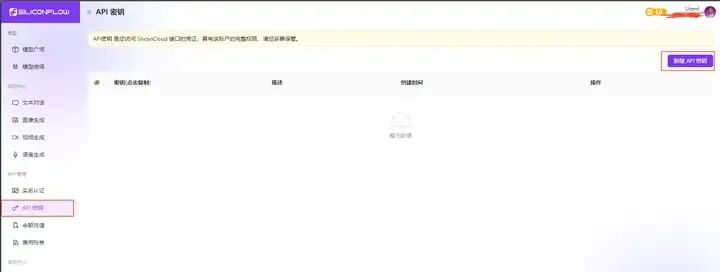
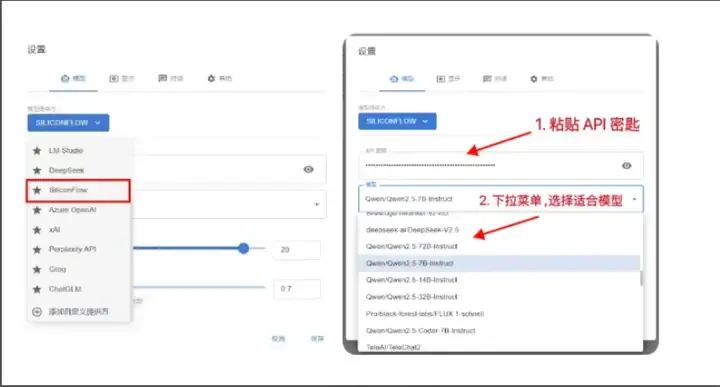
在左边的任务栏选择API密钥,然后点击右上角的新建API密钥保存下来就可以了。
第三步,在ChatBox应用设置里粘贴API密钥就可以了。
第四步,通过对话框测试即可完成。最简单你问问模型,你是属于哪个模型,它就会如实回答。
4.3 本地部署
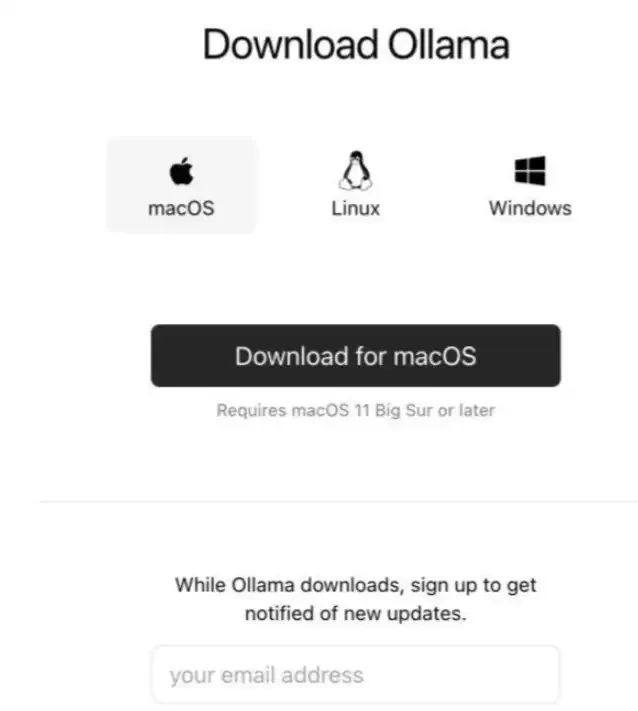
使用其他厂家的机器是需要根据资源时长等付费的,如果你手里有不错的硬件资源,想完全自己部署一套DeepSeek模型,也没问题。目前调研到比较简单方便的是通过Ollama来部署。通过访问Ollama官网https://ollama.com/download下载,选择对应的macOS、Linux或者Windows:
运行Ollama后,打开命令行,选择运行需要安装的模型。这里是DeepSeek R1对应的模型:
https://ollama.com/library/deepseek-r1
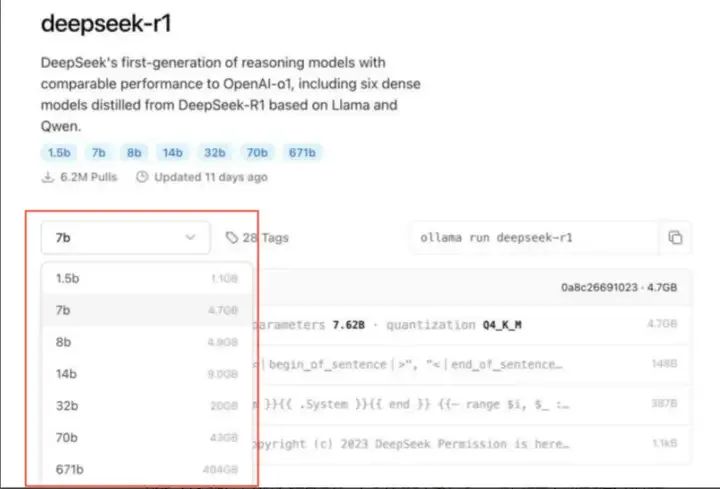
有很多不同的版本,如果只是自己玩一下可以先跑个最小的1.5b的,把整个流程跑通。如果是想部署到线上做实际项目,可以根据业务需求准备对应的硬件机器,部署对应参数量级的模型。
下载运行完之后输入命令:ollama run deepseek-r1:1.5B,等安装好之后就可以和DeepSeek对话了。
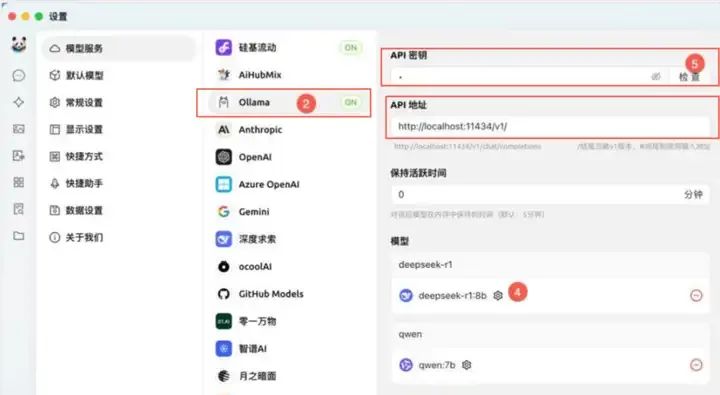
如果想使用前面ChatBox那样的UI界面,可以使用Cherry Studio 作为本地DeepSeek R1模型的 UI 界面。点击设置,选择模型服务,选择Ollama以及相关的配置即可完成。
总结
本篇从理论到实践介绍了当前国货之光DeepSeek大模型。首先简单介绍了DeepSeek以及背后的幻方量化;然后重点介绍了DeepSeek结构中重要的核心技术,包括MOE、MLA、MTP和DMP等;接着介绍了当前最火的两个DeepSeek V3和DeepSeek R1模型;最后介绍了普通人如何使用DeepSeek模型,包括官方使用方法、使用api+客户端的方式,还有本地部署的方式。
参考资料
【1】DeepSeek官网:DeepSeek
【2】DeepSeek Github主页:https://github.com/deepseek-ai
【3】DeepSeek HuggingFace主页:https://huggingface.co/deepseek-ai
【4】DeepSeek X主页https://x.com/deepseek_ai
【5】幻方技术博客:幻方 | 技术博客
【6】幻方量化首页:幻方 | 首页
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们关注和分享。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)