使用 DeepSeek R1 和 Ollama 开发 RAG 系统(包含完整代码)
是否想过直接向PDF文档或技术手册提问?本文将演示如何通过开源推理工具DeepSeek R1与本地AI模型框架Ollama搭建检索增强生成(RAG)系统。高效工具推荐:用Apidog简化API测试流程Apidog作为一体化API解决方案,可实现:零脚本自动化核心流程无缝对接CI/CD管道精准定位性能瓶颈可视化接口管理https://apidog.comDeepSeek R1核心优势相比OpenAI

是否想过直接向PDF文档或技术手册提问?本文将演示如何通过开源推理工具DeepSeek R1与本地AI模型框架Ollama搭建检索增强生成(RAG)系统。
高效工具推荐:用Apidog简化API测试流程

Apidog作为一体化API解决方案,可实现:
-
零脚本自动化核心流程
-
无缝对接CI/CD管道
-
精准定位性能瓶颈
-
可视化接口管理
https://apidog.com
DeepSeek R1核心优势
相比OpenAI o1模型成本降低95%,具备:
-
精准检索:每次仅调用3个文档片段
-
严谨输出:未知问题主动返回"暂不了解"
-
本地运行:彻底消除云端API延迟
环境准备
1. Ollama本地部署
# 安装基础框架
ollama run deepseek-r1 # 默认使用7B模型
Ollama官网下载
https://ollama.ai
2. 模型选择策略
# 轻量级场景推荐1.5B版本
ollama run deepseek-r1:1.5b
硬件建议:70B大模型需32GB内存支持
RAG系统构建全流程
Step 1: 导入依赖库
-
用于文档处理和检索的 LangChain。
-
流利使用用户友好的Web界面。
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
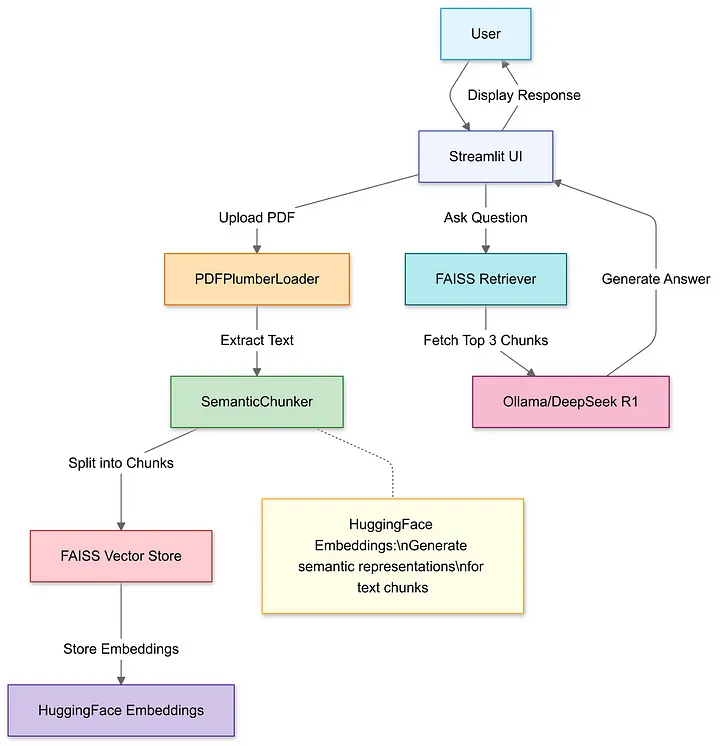
Step 2: PDF文件上传与解析
利用 Streamlit 的文件上传器选择本地 PDF。使用 PDFPlumberLoader 高效提取文本,无需手动解析。
# 创建Streamlit文件上传组件
uploaded_file = st.file_uploader("上传PDF文件", type="pdf")
if uploaded_file:
# 临时存储PDF文件
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# 加载PDF内容
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Step 3: 文档语义分块
利用 Streamlit 的文件上传器选择本地 PDF。使用 PDFPlumberLoader 高效提取文本,无需手动解析。
# 初始化语义分块器
text_splitter = SemanticChunker(
HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
)
# 执行分块操作
documents = text_splitter.split_documents(docs)
Step 4: 构建向量数据库
# 生成文本嵌入
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# 配置检索器
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
Step 5: 配置DeepSeek R1模型
# 初始化本地模型
llm = Ollama(model="deepseek-r1:1.5b")
# 定义提示模板
prompt_template = """
根据以下上下文:
{context}
问题:{question}
回答要求:
1. 仅使用给定上下文
2. 不确定时回答"暂不了解"
3. 答案控制在四句话内
最终答案:
"""
QA_PROMPT = PromptTemplate.from_template(prompt_template)
Step 6: 组装RAG处理链
# 创建LLM处理链
llm_chain = LLMChain(llm=llm, prompt=QA_PROMPT)
# 配置文档组合模板
document_prompt = PromptTemplate(
template="上下文内容:\n{page_content}\n来源:{source}",
input_variables=["page_content", "source"]
)
# 构建完整RAG管道
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Step 7: 启动交互界面
# 创建问题输入框
user_question = st.text_input("输入您的问题:")
if user_question:
with st.spinner("正在生成答案..."):
# 执行查询并显示结果
response = qa(user_question)["result"]
st.success(response)
完整的代码:https://gist.github.com/lisakim0/0204d7504d17cefceaf2d37261c1b7d5.js
技术实现要点
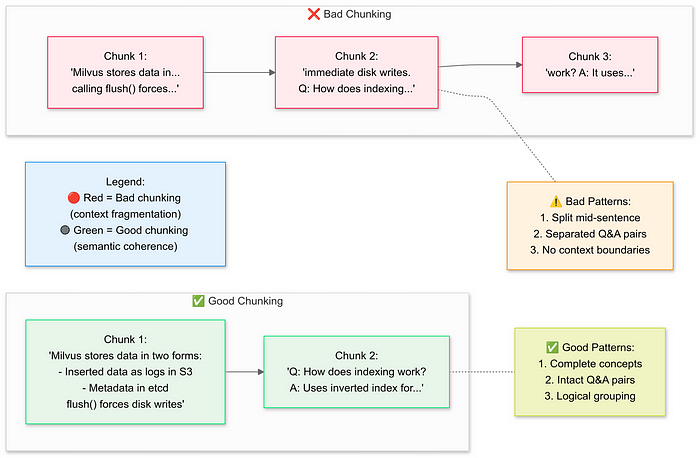
语义分块优化:采用SemanticChunker替代传统滑动窗口,提升上下文连贯性
# 示例:调整分块策略
text_splitter = SemanticChunker(
embeddings,
breakpoint_threshold=0.85 # 调整语义分割阈值
)
检索优化配置:动态调整检索数量
# 根据问题复杂度动态调整k值
def dynamic_retriever(question):
complexity = len(question.split())
return vector_store.as_retriever(search_kwargs={"k": min(complexity, 5)})
混合检索策略:结合关键词与向量搜索
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(documents)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6]
)
最后
DeepSeek R1 只是一个开始。凭借即将推出的自我验证和多跳推理等功能,未来的 RAG 系统可以自主辩论和完善其逻辑。
参考来源:Ollama官方技术文档与DeepSeek R1白皮书
最后:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0


 已为社区贡献20条内容
已为社区贡献20条内容






所有评论(0)