集体出走的Stability AI 发布全新代码大模型,3B以下性能最优,超越Code Llama和DeepSeek-Coder
Stability AI又有新动作!程序员又有危机了?3月26日,Stability AI推出了先进的代码语言模型Stable Code Instruct 3B,该模型是在Stable Code 3B的基础上进行指令调优的Code LM。
Stability AI又有新动作!程序员又有危机了? 3月26日,Stability AI推出了先进的代码语言模型Stable Code Instruct 3B,该模型是在Stable Code 3B的基础上进行指令调优的Code LM。

Stability AI 表示,Stable Code Instruct 3B 在代码完成准确性、对自然语言指令的理解以及处理多种编程语言方面都优于同类模型,在 3B 规模下提供最先进的性能,并且性能媲美Codellama 7B Instruct以及DeepSeek-Coder Instruct 1.3B
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
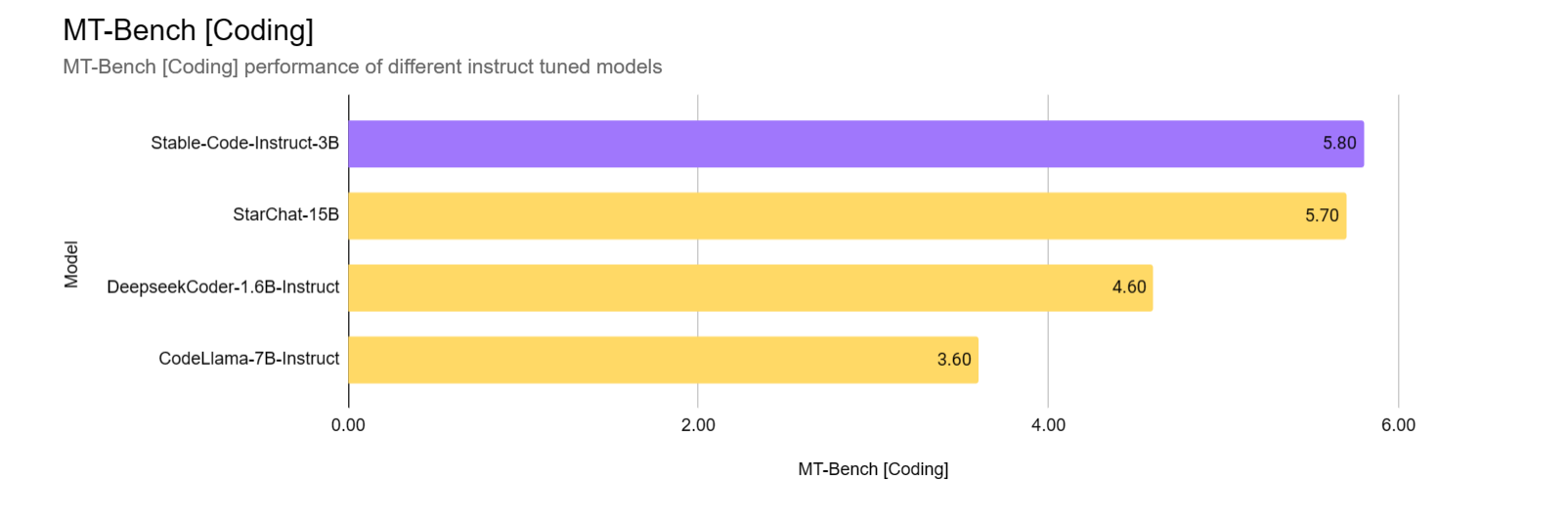
先让我们来感受一下Stable Code Instruct 3B的效果吧~
在线试用:
https://huggingface.co/spaces/stabilityai/stable-code-instruct-3b
Hugging Face地址:
https://huggingface.co/stabilityai/stable-code-instruct-3b
技术报告:
https://static1.squarespace.com/static/6213c340453c3f502425776e/t/6601c5713150412edcd56f8e/1711392114564/Stable_Code_TechReport_release.pdf
从效果图以及Stability AI的介绍可以看出Stable Code Instruct 3B有以下几个功能特点:
-
自然语言理解 :Stable Code Instruct 3B可以理解以自然语言为主的编程指令,并有效执行生成高质量代码。
-
支持多种编程语言 :Stable Code Instruct 3B不仅支持Python、Javascript、Java、C、C++和Go等语言,还支持其他广泛采用的语言如SQL、PHP和Rust
-
多样化编程任务:Stable Code Instruct 3B不仅精通代码生成,还擅长FIM(填充中间)任务、数据库查询、代码翻译、解释和创作。
-
更强的代码理解能力:Stable Code Instruct 3B在训练集最初未包括的语言(如Lua)中也能够表现出较强的测试性能。这种熟练程度可能源于其对底层编码原理的理解。
让我们再来看看Stable Code Instruct 3B的实现方法吧~
方法
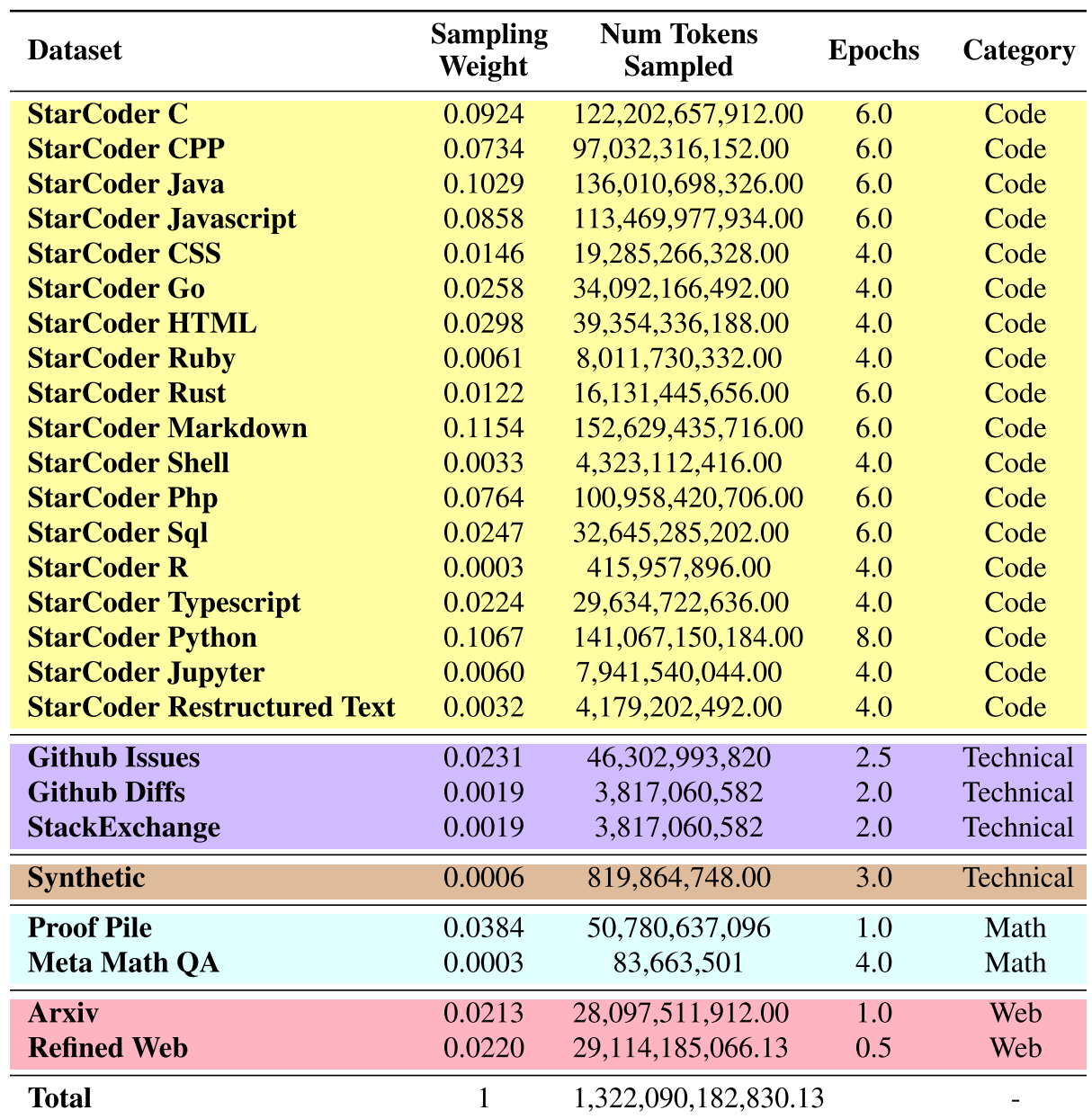
训练数据
Stable Code Instruct收集了一系列公开访问的大规模数据源。这些来源包括广泛的代码库、广泛的技术文档集合(例如:readthedocs)、以数学为重点的文本和全面的网络数据集,以在预训练阶段学习丰富的内部表达,超越单纯的代码理解。模型旨在显著提升在数学理解、逻辑推理和处理软件开发相关的复杂技术文本方面的能力。
模型架构
Stable Code是建立在Stable LM 3B基础上构建的,并且该模型是一个causal decoder-only transformer,架构上与Llama类似,但和Llama有以下几点区别:
-
位置嵌入:采用了旋转位置嵌入(Rotary Position Embeddings),应用于头嵌入维度的前25%,以提高吞吐量
-
归一化方法:使用了具有学习偏置项的LayerNorm进行归一化处理,而不是采用RMSNorm
-
偏置调整:除了键、查询和值投影的偏差,Stable Code 从前馈网络和多头自注意力层中删除了所有偏差项

模型训练
-
计算基础设施和设置

-
Stable Code在32个Amazon P4d实例上进行训练,包含256个NVIDIA A100 (40GB HBM2) GPUs。采用ZeRO阶段1的分布式优化方法,消除了对模型分片的需求。
-
采用的全局批量大小为4,194,304个令牌。在表中的设置下,设备的性能达到大约222 TFLOPs/s,或71.15%的模型浮点操作利用率(MFU)。
-
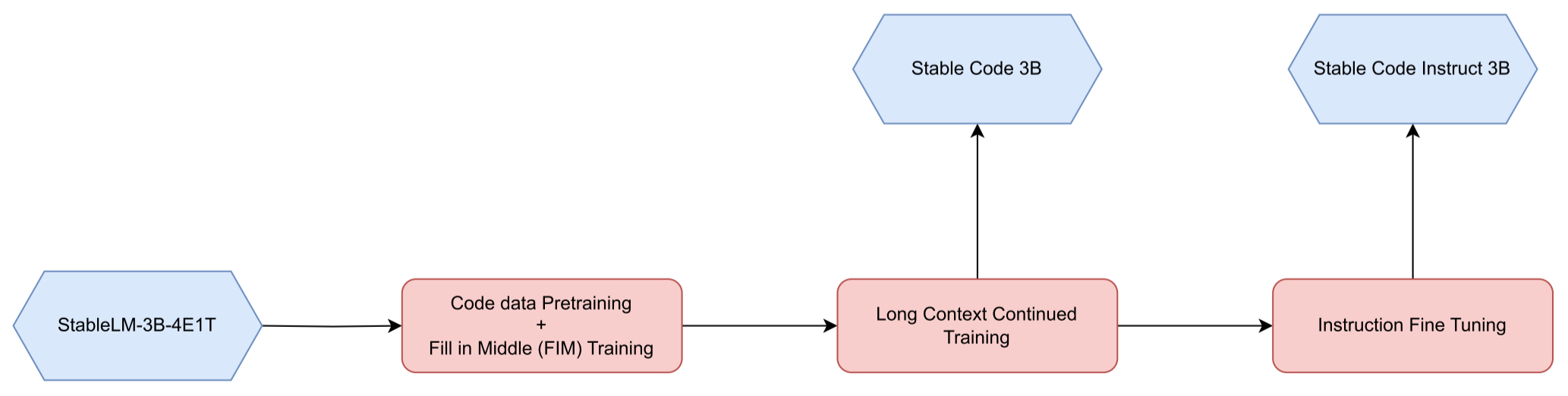
多阶段训练
-
采用了在其他强大的代码语言模型(如CodeGen、Stable Code Alpha、CodeLLaMA和DeepSeekCoder)中流行的分阶段训练方法。
-
训练分为几个阶段,包括代码数据预训练、中间填充(FIM)训练、长上下文持续训练和指令微调。
-
模型初始化
-
代码模型大多遵循两种主要训练方法之一:使用代码和相关文本从头开始训练的模型(例如,CodeGen、Stable code Alpha、Deepsseek Coder),以及利用基础语言模型的持续预训练的模型。
-
预训练的语言模型(如Stable LM 3B)初始化的模型往往表现优于从头开始训练的模型。这证实了自然语言与代码之间的正面交叉转移可以增强模型的能力。
-
中间填充(FIM)训练
-
为了解决代码中的左到右因果顺序不总是成立的问题(例如,函数调用和声明的顺序可以是任意的)
-
将文档随机分为三个部分:前缀、中间部分和后缀,然后将中间部分移动到文档的末尾。在重新排列之后,遵循相同的自回归训练过程。
-
在预训练的两个阶段中都应用了FIM。为了在长上下文训练阶段考虑FIM,我们确保只允许在单个文件的范围内应用FIM,以避免引入不现实的情景到训练目标中。
微调和对齐
在预训练之后,Stable Code Instruct通过由监督微调(SFT)和直接偏好优化(DPO)组成的微调阶段进一步提高了模型的对话能力
-
监督微调
-
使用了Hugging Face上公开可用的几个数据集进行SFT微调:OpenHermes、Code Feedback和CodeAlpaca。这些数据集合计提供了大约500,000个训练样本。
-
SFT模型训练了三个周期,使用余弦学习率调度器。在达到5e-5峰值学习率之前,实施了占训练持续时间10%的热身阶段。
-
设置全局批量大小为512个序列,并将输入打包成最多4096个令牌的序列。
-
直接偏好优化
-
继SFT之后,我们应用了DPO,这是一种关键技术,对近期高性能模型(如Zephyr-7B、Neural-Chat-7B和Tulu-2-DPO-70B)的成功起到了关键作用。
-
我们整理了大约7,000个样本的数据集,使用了来自UltraFeedback和Distilabel Capybara DPO-7k Binarized的数据,并仅保留了与代码相关的样本。
-
为提高模型安全性,我们添加了来自Bai等人的Helpful and Harmless RLFH数据集,以及HH-Anthropic数据集的无害子集。编译了大约15,000个高关联性的安全相关数据点。
结论
本文介绍了Stable Code Instruct,一种新的代码语言模型,该模型不仅支持多样的编程语言,更在3B规模的模型上提供最先进的性能。随着技术的进步,将会有更多高性能的代码模型被推出,未来写代码的工作是否会变得更加轻松呢?是否程序员就业会面临危机呢?Stable Code Instruct的出现为我们勾勒了一个充满无限可能的未来。



欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 28
28 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)