deepseek-ai/DeepSeek-V3
架构:创新的负载均衡策略和训练目标除了 DeepSeek-V2 的高效架构之外,我们还开创了一种用于负载均衡的辅助无损策略,该策略可以最大限度地减少因鼓励负载均衡而引起的性能下降。我们研究了多标记预测 (MTP) 目标,并证明它对模型性能有益。它还可用于推理加速的推测解码。训练前:迈向终极训练效率我们设计了一个 FP8 混合精度训练框架,并首次在超大规模模型上验证了 FP8 训练的可行性和有效性。
1. 引言
我们介绍了 DeepSeek-V3,这是一个强大的专家混合 (MoE) 语言模型,总共有 671B 个参数,每个令牌激活了 37B。为了实现高效的推理和具有成本效益的训练,DeepSeek-V3 采用了多头潜在注意力 (MLA) 和 DeepSeekMoE 架构,这些架构在 DeepSeek-V2 中得到了全面验证。此外,DeepSeek-V3 开创了一种用于负载均衡的辅助无损策略,并设定了多标记预测训练目标以获得更强的性能。我们在 14.8 万亿个多样化和高质量的代币上对 DeepSeek-V3 进行预训练,然后是监督微调和强化学习阶段,以充分利用其功能。综合评估表明,DeepSeek-V3 的性能优于其他开源模型,并实现了与领先的闭源模型相当的性能。尽管性能出色,但 DeepSeek-V3 只需要 2.788M H800 GPU 小时即可进行完整训练。此外,它的训练过程非常稳定。在整个训练过程中,我们没有遇到任何无法恢复的损失峰值或执行任何回滚。
2. 模型概述
架构:创新的负载均衡策略和训练目标
-
除了 DeepSeek-V2 的高效架构之外,我们还开创了一种用于负载均衡的辅助无损策略,该策略可以最大限度地减少因鼓励负载均衡而引起的性能下降。
-
我们研究了多标记预测 (MTP) 目标,并证明它对模型性能有益。它还可用于推理加速的推测解码。
训练前:迈向终极训练效率
-
我们设计了一个 FP8 混合精度训练框架,并首次在超大规模模型上验证了 FP8 训练的可行性和有效性。
-
通过算法、框架和硬件的协同设计,我们克服了跨节点 MoE 训练中的通信瓶颈,几乎实现了完全的计算-通信重叠。
这显著提高了我们的训练效率并降低了训练成本,使我们能够在不增加开销的情况下进一步扩大模型大小。 -
我们以仅 2.664M H800 GPU 小时的经济成本,在 14.8T 令牌上完成了 DeepSeek-V3 的预训练,生成了目前最强的开源基础模型。预训练后的后续训练阶段只需要 0.1M GPU 小时。
培训后:DeepSeek-R1 的知识提炼
-
我们引入了一种创新方法,将长链思维 (CoT) 模型的推理能力,特别是 DeepSeek R1 系列模型之一的推理能力提炼到标准 LLM 中,特别是 DeepSeek-V3。我们的 pipeline 将 R1 的验证和反射模式优雅地整合到 DeepSeek-V3 中,并显著提高了它的推理性能。同时,我们还保持对 DeepSeek-V3 的输出样式和长度的控制。
3. 模型下载
| 型 | #Total Params | #Activated Params | 上下文长度 | 下载 |
|---|---|---|---|---|
| DeepSeek-V3-基础 | 671B 系列 | 编号 37B | 128K | 🤗 拥抱脸 |
| 深度搜索-V3 | 671B 系列 | 编号 37B | 128K | 🤗 拥抱脸 |
注意:HuggingFace 上的 DeepSeek-V3 模型总大小为 685B,其中包括 671B 的主模型权重和 14B 的多标记预测 (MTP) 模块权重。
为了确保最佳性能和灵活性,我们与开源社区和硬件供应商合作,提供了多种在本地运行模型的方法。有关分步指南,请查看第 6 节:How_to Run_Locally。
对于希望深入了解的开发人员,我们建议探索 README_WEIGHTS.md 以了解有关主模型权重和多标记预测 (MTP) 模块的详细信息。请注意,MTP 支持目前在社区内正在积极开发中,我们欢迎您的贡献和反馈。
4. 评估结果
基本模型
标准基准
| 基准 (度量) | # 镜头 | 深度搜索-V2 | Qwen2.5 72B | LLaMA3.1 405B | 深度搜索-V3 | |
|---|---|---|---|---|---|---|
| 建筑 | - | 教育部 | 稠 | 稠 | 教育部 | |
| # 激活的 Params | - | 21B | 72B 系列 | 405B 系列 | 编号 37B | |
| # 总参数 | - | 编号 236B | 72B 系列 | 405B 系列 | 671B 系列 | |
| 英语 | 桩测试 (BPB) | - | 0.606 | 0.638 | 0.542 | 0.548 |
| BBH (EM) | 3 镜头 | 78.8 | 79.8 | 82.9 | 87.5 | |
| MMLU (Acc.) | 5 镜头 | 78.4 | 85.0 | 84.4 | 87.1 | |
| MMLU-Redux (Acc.) | 5 镜头 | 75.6 | 83.2 | 81.3 | 86.2 | |
| MMLU-Pro (附件) | 5 镜头 | 51.4 | 58.3 | 52.8 | 64.4 | |
| DROP (F1) | 3 镜头 | 80.4 | 80.6 | 86.0 | 89.0 | |
| ARC-Easy (累积) | 25 发 | 97.6 | 98.4 | 98.4 | 98.9 | |
| ARC-Challenge (累积) | 25 发 | 92.2 | 94.5 | 95.3 | 95.3 | |
| HellaSwag (累积) | 10 次拍摄 | 87.1 | 84.8 | 89.2 | 88.9 | |
| PIQA (累积) | 0 次射击 | 83.9 | 82.6 | 85.9 | 84.7 | |
| WinoGrande (Acc.) | 5 镜头 | 86.3 | 82.3 | 85.2 | 84.9 | |
| RACE-中 (Acc.) | 5 镜头 | 73.1 | 68.1 | 74.2 | 67.1 | |
| RACE-High (累积) | 5 镜头 | 52.6 | 50.3 | 56.8 | 51.3 | |
| 花絮QA (EM) | 5 镜头 | 80.0 | 71.9 | 82.7 | 82.9 | |
| 自然问题 (EM) | 5 镜头 | 38.6 | 33.2 | 41.5 | 40.0 | |
| AGIEval (Acc.) | 0 次射击 | 57.5 | 75.8 | 60.6 | 79.6 | |
| 法典 | HumanEval (Pass@1) | 0 次射击 | 43.3 | 53.0 | 54.9 | 65.2 |
| MBPP (Pass@1) | 3 镜头 | 65.0 | 72.6 | 68.4 | 75.4 | |
| LiveCodeBench-Base (Pass@1) | 3 镜头 | 11.6 | 12.9 | 15.5 | 19.4 | |
| CRUXEval-I (Acc.) | 2 次射击 | 52.5 | 59.1 | 58.5 | 67.3 | |
| CRUXEval-O (Acc.) | 2 次射击 | 49.8 | 59.9 | 59.9 | 69.8 | |
| 数学 | GSM8K (电磁) | 8 镜头 | 81.6 | 88.3 | 83.5 | 89.3 |
| 数学 (EM) | 4 发 | 43.4 | 54.4 | 49.0 | 61.6 | |
| MGSM (EM) | 8 镜头 | 63.6 | 76.2 | 69.9 | 79.8 | |
| CMath (EM) | 3 镜头 | 78.7 | 84.5 | 77.3 | 90.7 | |
| 中文 | CLUEWSC (EM) | 5 镜头 | 82.0 | 82.5 | 83.0 | 82.7 |
| C-Eval (Acc.) | 5 镜头 | 81.4 | 89.2 | 72.5 | 90.1 | |
| CMMLU (Acc.) | 5 镜头 | 84.0 | 89.5 | 73.7 | 88.8 | |
| CMRC (EM) | 1 次 | 77.4 | 75.8 | 76.0 | 76.3 | |
| C3 (累积) | 0 次射击 | 77.4 | 76.7 | 79.7 | 78.6 | |
| CCPM (累积) | 0 次射击 | 93.0 | 88.5 | 78.6 | 92.0 | |
| 多种语言 | MMMLU-non-English (Acc.) | 5 镜头 | 64.0 | 74.8 | 73.8 | 79.4 |
注意:最佳结果以粗体显示。差距不超过 0.3 的分数被视为处于同一水平。DeepSeek-V3 在大多数基准测试中实现了最佳性能,尤其是在数学和代码任务上。有关更多评估详情,请查看我们的论文。
上下文窗口
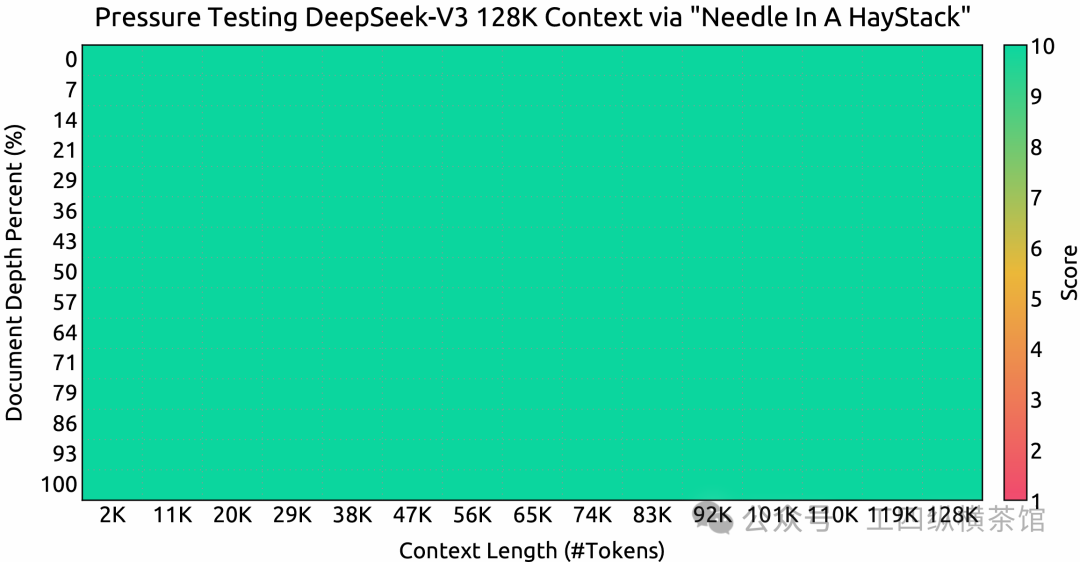
(NIAH) 测试的评估结果。DeepSeek-V3 在高达 128K 的所有上下文窗口长度上都表现良好。Needle In A Haystack
聊天模型
标准基准(大于 67B 的型号)
| 基准 (度量) | 深度寻觅 V2-0506 | 深度seek V2.5-0905 | Qwen2.5 72B-研究所 | 骆驼3.1 405B-研究所 | 克劳德-3.5-十四行诗-1022 | GPT-4o 0513的 | 深度seek V3 | |
|---|---|---|---|---|---|---|---|---|
| 建筑 | 教育部 | 教育部 | 稠 | 稠 | - | - | 教育部 | |
| # 激活的 Params | 21B | 21B | 72B 系列 | 405B 系列 | - | - | 编号 37B | |
| # 总参数 | 编号 236B | 编号 236B | 72B 系列 | 405B 系列 | - | - | 671B 系列 | |
| 英语 | MMLU (EM) | 78.2 | 80.6 | 85.3 | 88.6 | 88.3 | 87.2 | 88.5 |
| MMLU-Redux (EM) | 77.9 | 80.3 | 85.6 | 86.2 | 88.9 | 88.0 | 89.1 | |
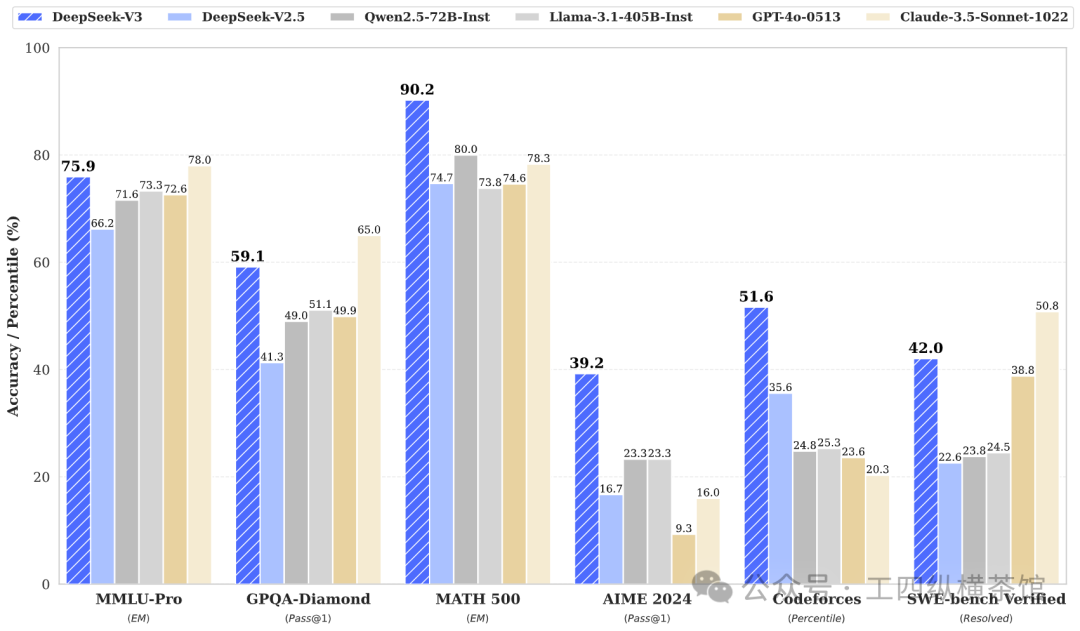
| MMLU-Pro (EM) | 58.5 | 66.2 | 71.6 | 73.3 | 78.0 | 72.6 | 75.9 | |
| DROP (3 次 F1) | 83.0 | 87.8 | 76.7 | 88.7 | 88.3 | 83.7 | 91.6 | |
| IF-Eval (Prompt Strict) | 57.7 | 80.6 | 84.1 | 86.0 | 86.5 | 84.3 | 86.1 | |
| GPQA 钻石 (Pass@1) | 35.3 | 41.3 | 49.0 | 51.1 | 65.0 | 49.9 | 59.1 | |
| SimpleQA(正确) | 9.0 | 10.2 | 9.1 | 17.1 | 28.4 | 38.2 | 24.9 | |
| FRAMES (Acc.) | 66.9 | 65.4 | 69.8 | 70.0 | 72.5 | 80.5 | 73.3 | |
| LongBench v2 (Acc.) | 31.6 | 35.4 | 39.4 | 36.1 | 41.0 | 48.1 | 48.7 | |
| 法典 | HumanEval-Mul (Pass@1) | 69.3 | 77.4 | 77.3 | 77.2 | 81.7 | 80.5 | 82.6 |
| LiveCodeBench (Pass@1-COT) | 18.8 | 29.2 | 31.1 | 28.4 | 36.3 | 33.4 | 40.5 | |
| LiveCodeBench (Pass@1) | 20.3 | 28.4 | 28.7 | 30.1 | 32.8 | 34.2 | 37.6 | |
| Codeforces (百分位数) | 17.5 | 35.6 | 24.8 | 25.3 | 20.3 | 23.6 | 51.6 | |
| SWE 验证 (已解决) | - | 22.6 | 23.8 | 24.5 | 50.8 | 38.8 | 42.0 | |
| Aider-Edit (Acc.) | 60.3 | 71.6 | 65.4 | 63.9 | 84.2 | 72.9 | 79.7 | |
| Aider-Polyglot (Acc.) | - | 18.2 | 7.6 | 5.8 | 45.3 | 16.0 | 49.6 | |
| 数学 | AIME 2024 (Pass@1) | 4.6 | 16.7 | 23.3 | 23.3 | 16.0 | 9.3 | 39.2 |
| 数学 500 (EM) | 56.3 | 74.7 | 80.0 | 73.8 | 78.3 | 74.6 | 90.2 | |
| CNMO 2024 (Pass@1) | 2.8 | 10.8 | 15.9 | 6.8 | 13.1 | 10.8 | 43.2 | |
| 中文 | CLUEWSC (EM) | 89.9 | 90.4 | 91.4 | 84.7 | 85.4 | 87.9 | 90.9 |
| C-Eval (EM) | 78.6 | 79.5 | 86.1 | 61.5 | 76.7 | 76.0 | 86.5 | |
| C-SimpleQA(正确) | 48.5 | 54.1 | 48.4 | 50.4 | 51.3 | 59.3 | 64.8 |
注:所有模型均在将输出长度限制为 8K 的配置中进行评估。包含少于 1000 个样品的基准使用不同的温度设置进行多次测试,以获得可靠的最终结果。DeepSeek-V3 是性能最佳的开源模型,并且与前沿的闭源模型相比也表现出有竞争力的性能。
开放式生成评估
| 型 | 竞技场-困难 | 羊驼评估 2.0 |
|---|---|---|
| 深度搜索-V2.5-0905 | 76.2 | 50.5 |
| Qwen2.5-72B-指令 | 81.2 | 49.1 |
| LLaMA-3.1 405B | 69.3 | 40.5 |
| GPT-4o-0513 | 80.4 | 51.1 |
| 克劳德-十四行诗-3.5-1022 | 85.2 | 52.0 |
| 深度搜索-V3 | 85.5 | 70.0 |
注意:英语开放式对话评估。对于 AlpacaEval 2.0,我们使用长度控制的胜率作为指标。
5. 聊天网站和API平台
您可以在 DeepSeek 的官方网站上与 DeepSeek-V3 聊天:chat.deepseek.com
我们还在 DeepSeek 平台上提供兼容 OpenAI 的 API:platform.deepseek.com
6. 如何在本地运行
DeepSeek-V3 可以使用以下硬件和开源社区软件在本地部署:
-
DeepSeek-Infer Demo:我们为 FP8 和 BF16 推理提供了一个简单轻量级的 Demo。
-
SGLang:完全支持 BF16 和 FP8 推理模式下的 DeepSeek-V3 模型。
-
LMDeploy:为本地和云部署提供高效的 FP8 和 BF16 推理。
-
TensorRT-LLM :目前支持 BF16 推理和 INT4/8 量化,即将推出 FP8 支持。
-
vLLM:支持 DeekSeek-V3 模型,具有 FP8 和 BF16 模式,用于张量并行和流水线并行。
-
AMD GPU:支持通过 SGLang 在 BF16 和 FP8 模式下在 AMD GPU 上运行 DeepSeek-V3 模型。
-
华为昇腾 NPU:支持在华为昇腾设备上运行 DeepSeek-V3。
由于 FP8 训练是在我们的框架中原生采用的,因此我们只提供 FP8 权重。如果您需要 BF16 权重进行实验,则可以使用提供的转换脚本来执行转换。
以下是将 FP8 权重转换为 BF16 的示例:
cd inference
python fp8_cast_bf16.py --input-fp8-hf-path /path/to/fp8_weights --output-bf16-hf-path /path/to/bf16_weights
注意:尚未直接支持 Huggingface 的 Transformers。
6.1 使用 DeepSeek-Infer 进行推理 Demo (仅示例)
模型权重和演示代码准备
首先,克隆我们的 DeepSeek-V3 GitHub 存储库:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
导航到文件夹并安装 中列出的依赖项。inferencerequirements.txt
cd DeepSeek-V3/inference
pip install -r requirements.txt
从 HuggingFace 下载模型权重,并将它们放入文件夹中。/path/to/DeepSeek-V3
模型权重转换
将 HuggingFace 模型权重转换为特定格式:
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
跑
然后,您可以与 DeepSeek-V3 聊天:
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
或对给定文件进行批量推理:
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $FILE
6.2 使用 SGLang 进行推理(推荐)
SGLang 目前支持 MLA 优化、FP8 (W8A8)、FP8 KV Cache 和 Torch Compile,在开源框架中提供最先进的延迟和吞吐量性能。
值得注意的是,SGLang v0.4.1 完全支持在 NVIDIA 和 AMD GPU 上运行 DeepSeek-V3,使其成为一个高度通用且强大的解决方案。
以下是 SGLang 团队的启动说明:https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
6.3 使用 LMDeploy 进行推理(推荐)
LMDeploy 是一个为大型语言模型量身定制的灵活、高性能的推理和服务框架,现在支持 DeepSeek-V3。它提供离线管道处理和在线部署功能,与基于 PyTorch 的工作流无缝集成。
有关使用 LMDeploy 运行 DeepSeek-V3 的全面分步说明,请参阅此处:https://github.com/InternLM/lmdeploy/issues/2960
6.4 使用 TRT-LLM 进行推理(推荐)
TensorRT-LLM 现在支持 DeepSeek-V3 模型,仅提供 BF16 和 INT4/INT8 权重等精度选项。对 FP8 的支持目前正在进行中,并将很快发布。您可以通过以下链接访问 TRTLLM 专门用于 DeepSeek-V3 支持的自定义分支,直接体验新功能:https://github.com/NVIDIA/TensorRT-LLM/tree/deepseek/examples/deepseek_v3。
6.5 使用 vLLM 进行推理(推荐)
vLLM v0.6.6 支持在 NVIDIA 和 AMD GPU 上对 FP8 和 BF16 模式进行 DeepSeek-V3 推理。除了标准技术之外,vLLM 还提供管道并行性,允许您在通过网络连接的多台机器上运行此模型。有关详细指导,请参阅 vLLM 说明。也请随时遵循增强计划。
6.6 AMD GPU 的推荐推理功能
通过与 AMD 团队合作,我们实现了对使用 SGLang 的 AMD GPU 的第一天支持,完全兼容 FP8 和 BF16 精度。有关详细指南,请参阅 SGLang 说明。
6.7 华为昇腾 NPU 的推荐推理功能
来自华为昇腾社区的 MindIE 框架成功适配了 DeepSeek-V3 的 BF16 版本。有关 Ascend NPU 的分步指南,请按照此处的说明进行操作。
7. 许可
此代码存储库根据 MIT 许可证获得许可。使用 DeepSeek-V3 Base/Chat 模型需遵守模型许可证。DeepSeek-V3 系列(包括 Base 和 Chat)支持商用。
8. 引文
@misc{deepseekai2024deepseekv3technicalreport,
title={DeepSeek-V3 Technical Report},
author={DeepSeek-AI and Aixin Liu and Bei Feng and Bing Xue and Bingxuan Wang and Bochao Wu and Chengda Lu and Chenggang Zhao and Chengqi Deng and Chenyu Zhang and Chong Ruan and Damai Dai and Daya Guo and Dejian Yang and Deli Chen and Dongjie Ji and Erhang Li and Fangyun Lin and Fucong Dai and Fuli Luo and Guangbo Hao and Guanting Chen and Guowei Li and H. Zhang and Han Bao and Hanwei Xu and Haocheng Wang and Haowei Zhang and Honghui Ding and Huajian Xin and Huazuo Gao and Hui Li and Hui Qu and J. L. Cai and Jian Liang and Jianzhong Guo and Jiaqi Ni and Jiashi Li and Jiawei Wang and Jin Chen and Jingchang Chen and Jingyang Yuan and Junjie Qiu and Junlong Li and Junxiao Song and Kai Dong and Kai Hu and Kaige Gao and Kang Guan and Kexin Huang and Kuai Yu and Lean Wang and Lecong Zhang and Lei Xu and Leyi Xia and Liang Zhao and Litong Wang and Liyue Zhang and Meng Li and Miaojun Wang and Mingchuan Zhang and Minghua Zhang and Minghui Tang and Mingming Li and Ning Tian and Panpan Huang and Peiyi Wang and Peng Zhang and Qiancheng Wang and Qihao Zhu and Qinyu Chen and Qiushi Du and R. J. Chen and R. L. Jin and Ruiqi Ge and Ruisong Zhang and Ruizhe Pan and Runji Wang and Runxin Xu and Ruoyu Zhang and Ruyi Chen and S. S. Li and Shanghao Lu and Shangyan Zhou and Shanhuang Chen and Shaoqing Wu and Shengfeng Ye and Shengfeng Ye and Shirong Ma and Shiyu Wang and Shuang Zhou and Shuiping Yu and Shunfeng Zhou and Shuting Pan and T. Wang and Tao Yun and Tian Pei and Tianyu Sun and W. L. Xiao and Wangding Zeng and Wanjia Zhao and Wei An and Wen Liu and Wenfeng Liang and Wenjun Gao and Wenqin Yu and Wentao Zhang and X. Q. Li and Xiangyue Jin and Xianzu Wang and Xiao Bi and Xiaodong Liu and Xiaohan Wang and Xiaojin Shen and Xiaokang Chen and Xiaokang Zhang and Xiaosha Chen and Xiaotao Nie and Xiaowen Sun and Xiaoxiang Wang and Xin Cheng and Xin Liu and Xin Xie and Xingchao Liu and Xingkai Yu and Xinnan Song and Xinxia Shan and Xinyi Zhou and Xinyu Yang and Xinyuan Li and Xuecheng Su and Xuheng Lin and Y. K. Li and Y. Q. Wang and Y. X. Wei and Y. X. Zhu and Yang Zhang and Yanhong Xu and Yanhong Xu and Yanping Huang and Yao Li and Yao Zhao and Yaofeng Sun and Yaohui Li and Yaohui Wang and Yi Yu and Yi Zheng and Yichao Zhang and Yifan Shi and Yiliang Xiong and Ying He and Ying Tang and Yishi Piao and Yisong Wang and Yixuan Tan and Yiyang Ma and Yiyuan Liu and Yongqiang Guo and Yu Wu and Yuan Ou and Yuchen Zhu and Yuduan Wang and Yue Gong and Yuheng Zou and Yujia He and Yukun Zha and Yunfan Xiong and Yunxian Ma and Yuting Yan and Yuxiang Luo and Yuxiang You and Yuxuan Liu and Yuyang Zhou and Z. F. Wu and Z. Z. Ren and Zehui Ren and Zhangli Sha and Zhe Fu and Zhean Xu and Zhen Huang and Zhen Zhang and Zhenda Xie and Zhengyan Zhang and Zhewen Hao and Zhibin Gou and Zhicheng Ma and Zhigang Yan and Zhihong Shao and Zhipeng Xu and Zhiyu Wu and Zhongyu Zhang and Zhuoshu Li and Zihui Gu and Zijia Zhu and Zijun Liu and Zilin Li and Ziwei Xie and Ziyang Song and Ziyi Gao and Zizheng Pan},
year={2024},
eprint={2412.19437},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.19437},
}
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)