为什么低成本?深度拆解 DeepSeek-V3的训练之道
DeepSeek-V3 以极低的成本(约 550 万美金)实现了与 Claude 3.5 等顶尖模型相媲美甚至更优的性能,并且选择了开源的道路,为全球的研究者和开发者带来了巨大的惊喜。那么,DeepSeek-V3 是如何炼成的呢?今天,我们就深入拆解其训练过程。
导读
DeepSeek-V3 以极低的成本(约 550 万美金)实现了与 Claude 3.5 等顶尖模型相媲美甚至更优的性能,并且选择了开源的道路,为全球的研究者和开发者带来了巨大的惊喜。那么,DeepSeek-V3 是如何炼成的呢?今天,我们就深入拆解其训练过程。
一、架构创新:为性能与效率奠基
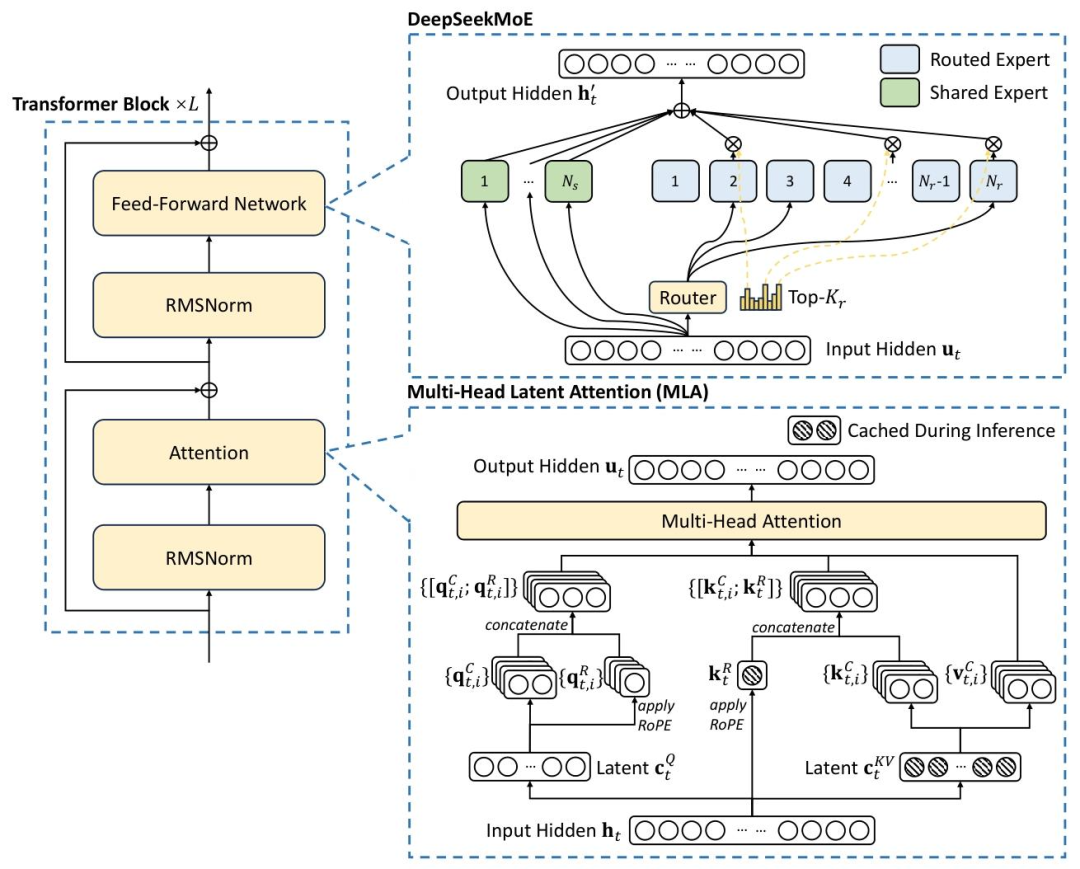
unsetunset(一)Multi-head Latent Attention(MLA)unsetunset
DeepSeek-V3 采用了 MLA 架构来高效处理长文本。传统 Transformer 中的注意力机制在处理长文本时会面临 KV Cache 过大导致显存占用高的问题。MLA 通过将 Key(K)和 Value(V)联合映射至低维潜空间向量(cKV),显著降低了 KV Cache 的大小。在 DeepSeek-V3 中,MLA 的 KV 压缩维度(dc)设置为 512,Query 压缩维度(d’)设置为 1536,解耦 Key 的头维度(dr)设置为 64。这种设计在保证模型性能的同时,大幅减少了显存占用和计算开销,使得模型能够更高效地处理长文本,为后续的长上下文扩展训练奠定了基础。
详细可见:DeepSeek模型性能跃迁的幕后英雄 ——MLA 框架
unsetunset(二)DeepSeekMoE 架构unsetunset
为了实现模型容量的高效扩展,DeepSeek-V3 采用了 DeepSeekMoE 架构。该架构通过细粒度专家、共享专家和 Top-K 路由策略,让模型在不显著增加计算成本的情况下拥有庞大的模型容量。具体来说,每个 MoE 层包含 1 个共享专家和 256 个路由专家,每个 Token 选择 8 个路由专家,最多路由至 4 个节点。这种稀疏激活的机制,使得 DeepSeek-V3 在处理大规模数据时能够更加灵活地分配计算资源,提升了整体的训练效率和性能表现。
详细可见:一文揭秘 DeepSeekMoE:技术与优势全解析
unsetunset(三)无额外损耗的负载均衡策略unsetunset
在 MoE 架构中,负载均衡是一个关键问题。传统的辅助损失方法虽然可以实现负载均衡,但会对模型性能产生负面影响。DeepSeek-V3 提出了一种创新的无额外损耗负载均衡策略,通过引入并动态调整可学习的偏置项(Bias Term)来影响路由决策。该策略的偏置项更新速度(γ)在预训练的前 14.3T 个 Token 中设置为 0.001,剩余 500B 个 Token 中设置为 0.0;序列级平衡损失因子(α)设置为 0.0001。这种策略使得模型在训练过程中能够更好地平衡各专家的负载,避免了因负载不均衡导致的性能下降,同时也不会对模型性能产生额外的损耗。
二、训练基础设施:高效计算与通信的协同

image
DeepSeek-V3的训练依赖于强大的计算基础设施和高效的训练框架。它在配备2048个NVIDIA H800 GPU的计算集群上进行训练,这些GPU通过InfiniBand(IB)和NVLink网络进行通信。为了实现高效的训练,DeepSeek团队设计了一系列创新的算法和框架优化,包括流水线并行、通信优化、内存管理和低精度训练等多个方面,全方位提升了训练效率。
unsetunset(一)DualPipe 流水线并行unsetunset
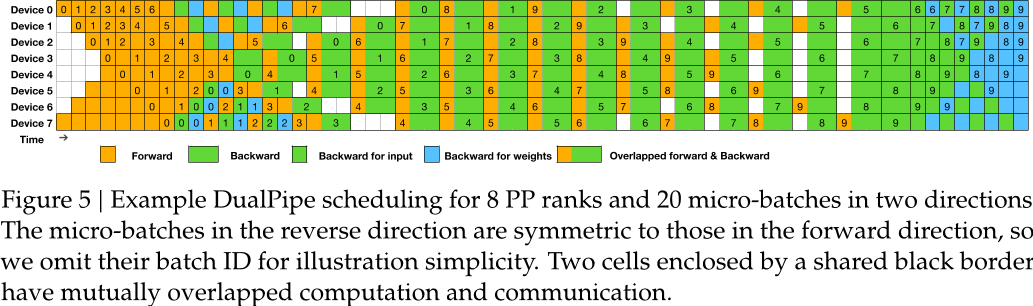
image
在训练过程中,流水线并行是一种常见的加速手段。然而,传统的单向流水线(如 1F1B)存在流水线气泡(Pipeline Bubble)的问题,导致 GPU 利用率不高。
DeepSeek-V3 采用了一种名为 DualPipe 的创新流水线并行策略,它采用双向流水线设计,即同时从流水线的两端馈送 micro-batch。这种设计显著减少了流水线气泡,提高了 GPU 的利用率。DualPipe 还将每个 micro-batch 进一步划分为更小的 chunk,并对每个 chunk 的计算和通信进行精细的调度,实现了计算和通信的高度重叠。通过巧妙地编排计算和通信的顺序,DeepSeek-V3 在 8 个 PP rank 上,20 个 micro-batch 的 DualPipe 调度情况下,流水线气泡被显著减少,GPU 利用率得到了极大提升,从而大幅提高了训练效率。
unsetunset(二)高效的跨节点全节点通信实现unsetunset
跨节点 MoE 训练的一大挑战是巨大的通信开销。DeepSeek-V3 通过一系列精细的优化策略,有效地缓解了这一瓶颈。具体包括:
首先,采用了节点限制路由(Node-Limited Routing),将每个 Token 最多路由到 4 个节点,有效限制了跨节点通信的范围和规模。
其次,定制了高效的跨节点 All-to-All 通信内核,这些内核充分利用了 IB(InfiniBand)和 NVLink 的带宽,并最大程度地减少了用于通信的 SM(Streaming Multiprocessors)数量。
此外,还采用了 Warp 专业化(Warp Specialization),将不同的通信任务分配给不同的 Warp,并根据实际负载情况动态调整每个任务的 Warp 数量,实现了通信任务的精细化管理和优化。
最后,通过自动调整通信块大小,减少了对 L2 缓存的依赖,降低了对其他计算内核的干扰,进一步提升了通信效率。
这些通信优化策略的综合运用,使得 DeepSeek-V3 在大规模分布式训练中能够高效地进行数据交换,减少了通信延迟,加快了训练速度。
unsetunset(三)极致的内存节省unsetunset
DeepSeek-V3 在内存管理方面也做到了极致,通过多种策略最大程度地减少了内存占用:
-
RMSNorm 和 MLA 上投影的重计算:在反向传播过程中,DeepSeek-V3 会重新计算 RMSNorm 和 MLA 上投影的输出,而不是将这些中间结果存储在显存中。这种策略虽然会略微增加计算量,但可以显著降低显存占用。
-
CPU 上的 EMA:DeepSeek-V3 将模型参数的 EMA 存储在 CPU 内存中,并异步更新。这种策略避免了在 GPU 上存储 EMA 参数带来的额外显存开销。
-
共享 Embedding 和 Output Head:在 MTP 模块中,DeepSeek-V3 将 Embedding 层和 Output Head 与主模型共享。这种设计减少了模型的参数量和内存占用。
unsetunset(四)FP8 低精度训练unsetunset
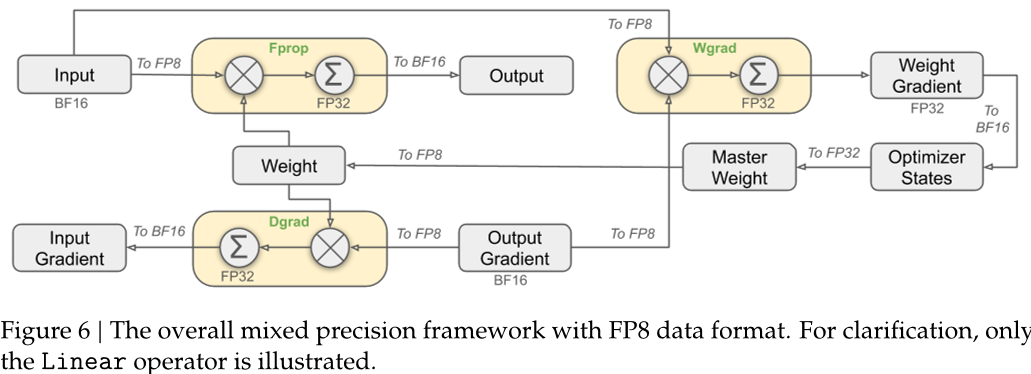
为了进一步降低训练成本,DeepSeek-V3 采用了 FP8 混合精度训练。FP8 是一种低精度的数据格式,相较于传统的 FP32 或 BF16,它能够显著减少显存占用和计算开销。然而,低精度训练也面临着精度损失的问题。DeepSeek-V3 通过一系列创新的方法,解决了这一难题。
首先,对于模型中对精度较为敏感的组件(如 Embedding、Output Head、MoE Gating、Normalization、Attention 等),仍然采用 BF16 或 FP32 进行计算,以保证模型的性能。
其次,采用了细粒度量化(Fine-Grained Quantization),对激活值采用 1x128 tile-wise 量化,对权重采用 128x128 block-wise 量化,这种策略可以更好地适应数据的分布,减少量化误差。
此外,为了减少 FP8 计算过程中的精度损失,DeepSeek-V3 将 MMA(Matrix Multiply-Accumulate)操作的中间结果累加到 FP32 寄存器中,提高了累加精度。
最后,将激活值和优化器状态以 FP8 或 BF16 格式进行存储,并在通信过程中也使用这些低精度格式,进一步降低了显存占用和通信开销。
通过这些策略,DeepSeek-V3 在保证模型精度的同时,大幅降低了训练成本,提高了训练效率。
三、预训练策略:构建高质量数据与优化训练过程
unsetunset(一)构建高质量数据unsetunset
DeepSeek-V3 的预训练语料库规模达到了14.8 万亿 Token,这些数据经过了严格的筛选和清洗,以确保其高质量和多样性。相比于前代模型 DeepSeek-V2,新模型的数据构建策略更加精细,主要体现在以下几个方面:
-
提升数学和编程相关数据占比:大幅提升了数学和编程相关数据在整体数据中的占比,这直接增强了模型在相关领域的推理能力,使其在 MATH 500、AIME 2024 等数学基准测试和 HumanEval、LiveCodeBench 等代码基准测试中表现突出。
-
扩展多语言数据覆盖范围:进一步扩展了多语言数据的覆盖范围,超越了传统的英语和中文,提升了模型的多语言处理能力。
-
最小化数据冗余:开发了一套完善的数据处理流程,着重于最小化数据冗余,同时保留数据的多样性。
-
文档级打包方法:借鉴了近期研究中提出的文档级打包方法,将多个文档拼接成一个训练样本,避免了传统方法中由于截断导致的上下文信息丢失,确保模型能够学习到更完整的语义信息。
-
Fill-in-Middle (FIM) 策略:针对代码数据,DeepSeek-V3 借鉴了 DeepSeekCoder-V2 中采用的 FIM 策略,以 0.1 的比例将代码数据构造成 <|fim_begin|> pre<|fim_hole|> suf<|fim_end|> middle<|eos_token|> 的形式。这种策略通过“填空”的方式,迫使模型学习代码的上下文关系,从而提升代码生成和补全的准确性。
unsetunset(二)优化训练过程unsetunset
分词器与词表
DeepSeek-V3 采用了基于字节级 BPE 的分词器,并构建了一个包含 128K 个 token 的词表。为了优化多语言的压缩效率,DeepSeek 对预分词器和训练数据进行了专门的调整。
与 DeepSeek-V2 相比,新的预分词器引入了将标点符号和换行符组合成新 token 的机制。这种方法可以提高压缩率,但也可能在处理不带换行符的多行输入时引入 token 边界偏差。
为了减轻这种偏差,DeepSeek-V3 在训练过程中以一定概率随机地将这些组合 token 拆分开来,从而让模型能够适应更多样化的输入形式,提升了模型的鲁棒性。
模型配置与超参数:
模型配置
DeepSeek-V3 的 Transformer 层数设置为 61 层,隐藏层维度为 7168。所有可学习参数均采用标准差为 0.006 的随机初始化。
在 MLA 结构中,注意力头的数量 (nh) 设置为 128,每个注意力头的维度 (dh) 为 128,KV 压缩维度 (dc) 为 512,Query 压缩维度 (d’) 为 1536,解耦的 Key 头的维度 (dr) 为 64。
除了前三层之外,其余的 FFN 层均替换为 MoE 层。每个 MoE 层包含 1 个共享专家和 256 个路由专家,每个专家的中间隐藏层维度为 2048。每个 Token 会被路由到 8 个专家,并且最多会被路由到 4 个节点。
多 Token 预测的深度 (D) 设置为 1,即除了预测当前 Token 之外,还会额外预测下一个 Token。此外,DeepSeek-V3 还在压缩的潜变量之后添加了额外的 RMSNorm 层,并在宽度瓶颈处乘以了额外的缩放因子。
训练超参数
-
优化器:DeepSeek-V3 采用了 AdamW 优化器,β1 设置为 0.9,β2 设置为 0.95,权重衰减系数 设置为 0.1。最大序列长度设置为 4K。
-
**学习率方面:**采用了组合式的调度策略:在前 2K 步,学习率从 0 线性增加到 2.2 × 10^-4;然后保持 2.2 × 10^-4 的学习率直到模型处理完 10T 个 Token;接下来,在 4.3T 个 Token 的过程中,学习率按照余弦曲线逐渐衰减至 2.2 × 10^-5;在最后的 500B 个 Token 中,学习率先保持 2.2 × 10^-5 不变,然后切换到一个更小的常数学习率 7.3 × 10^-6。梯度裁剪的范数设置为 1.0。
-
**Batch Size 方面:**采用了动态调整的策略,在前 469B 个 Token 的训练过程中,Batch Size 从 3072 逐渐增加到 15360,并在之后的训练中保持 15360 不变。
-
负载均衡:为了实现 MoE 架构中的负载均衡,DeepSeek-V3 采用了无额外损耗的负载均衡策略,并将偏置项的更新速度 (γ) 在预训练的前 14.3T 个 Token 中设置为 0.001,在剩余的 500B 个 Token 中设置为 0.0。序列级平衡损失因子 (α) 设置为 0.0001,以避免单个序列内的极端不平衡。多 Token 预测损失的权重 (λ) 在前 10T 个 Token 中设置为 0.3,在剩余的 4.8T 个 Token 中设置为 0.1。
长上下文扩展与多 Token 预测:
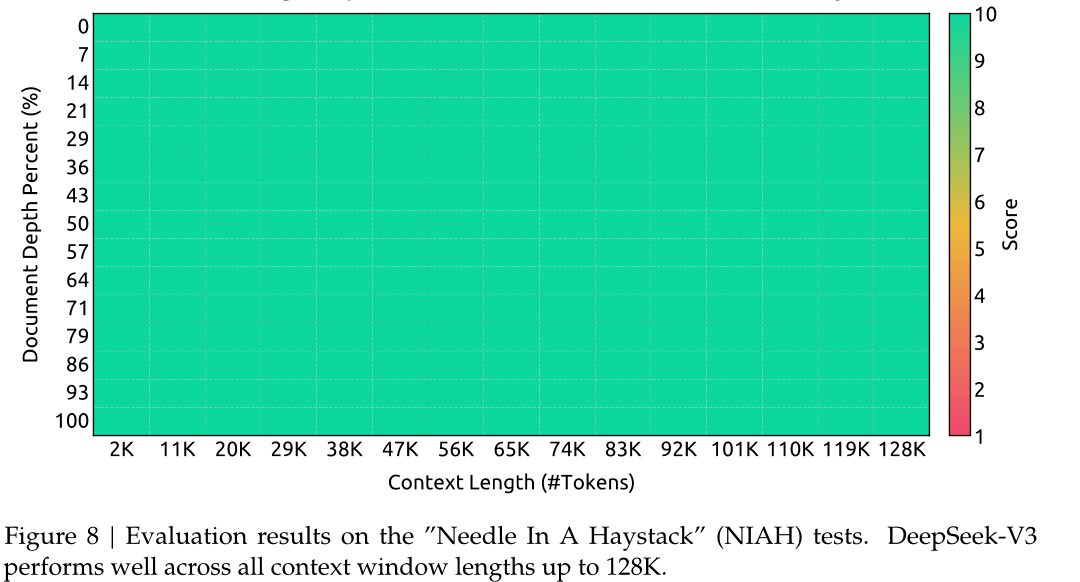
长上下文扩展
为了使 DeepSeek-V3 具备处理长文本的能力,DeepSeek 采用了两阶段的训练策略,将模型的上下文窗口从 4K 逐步扩展到 128K。他们采用了 YaRN 技术,并将其应用于解耦的共享 Key (k)。
-
**在长上下文扩展阶段:**DeepSeek-V3 的超参数保持不变:scale 设置为 40,β 设置为 1,ρ 设置为 32,缩放因子设置为 0.1 ln n + 1。
-
**第一阶段 (4K -> 32K):**序列长度设置为 32K,Batch Size 设置为 1920,学习率设置为 7.3 × 10^-6。
-
**第二阶段 (32K -> 128K):**序列长度设置为 128K,Batch Size 设置为 480,学习率设置为 7.3 × 10^-6。上图的 “Needle In A Haystack” (NIAH) 测试结果清晰地展示了 DeepSeek-V3 在处理长文本方面的卓越能力。
-
多 Token 预测:DeepSeek-V3 还采用了多 Token 预测策略,要求模型在每个位置预测未来的多个 Token,而不仅仅是下一个 Token。
这种策略增强了模型的预见能力,并提供了更丰富的训练信号,从而提升了训练效率。
四、后训练:知识蒸馏与强化学习的强化
在预训练阶段之后,DeepSeek-V3 进入了后训练阶段,这一阶段主要包括监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL),通过这两个阶段的训练,DeepSeek-V3 的性能得到了进一步的提升,使其能够更好地理解和生成符合人类偏好的文本。
unsetunset(一)监督微调(SFT)unsetunset
监督微调是后训练阶段的第一步,其目的是通过大量标注数据对模型进行微调,使其能够更好地理解人类的语言和指令。
DeepSeek-V3 的 SFT 数据集包含了 150 万条来自多个领域的标注数据,这些数据涵盖了数学、编程、逻辑推理、创意写作、角色扮演和简单问答等多个领域。为了生成高质量的 SFT 数据,DeepSeek 团队采用了以下方法:
-
推理数据生成:对于数学、编程和逻辑推理等需要复杂推理的任务,DeepSeek 团队利用内部的 DeepSeek-R1 模型生成数据。R1 模型虽然在推理准确性方面表现出色,但存在思考过多、格式不佳和回答过长等问题。为了平衡 R1 模型的高准确性和清晰简洁的格式,DeepSeek 团队开发了一种专家模型,通过 SFT 和 RL 训练流程,生成高质量的 SFT 数据。具体来说,对于每个实例,专家模型会生成两种类型的 SFT 样本:一种是将问题与原始回答配对,格式为 <问题,原始回答>;另一种是在系统提示、问题和 R1 回答之间插入系统提示,格式为 <系统提示,问题,R1 回答>。系统提示经过精心设计,旨在引导模型生成具有反思和验证机制的响应。
-
非推理数据生成:对于创意写作、角色扮演和简单问答等不需要复杂推理的任务,DeepSeek 团队使用 DeepSeek-V2.5 生成回答,并由人工标注员验证数据的准确性和正确性。在 SFT 训练过程中,DeepSeek-V3 使用了 AdamW 优化器,学习率采用余弦衰减策略,从 5 × 10^-6 逐渐降低到 1 × 10^-6,并进行了两个 epoch 的训练。为了确保每个序列中的样本相互独立,DeepSeek 团队采用了样本掩码策略。
unsetunset(二)强化学习(RL)unsetunset
强化学习是后训练阶段的第二步,其目的是通过奖励信号进一步优化模型的性能,使其能够生成更符合人类偏好的文本。DeepSeek-V3 的强化学习过程包括以下几个关键部分:
-
奖励模型(Reward Model, RM):奖励模型是强化学习的核心,它负责评估模型生成的文本的质量。DeepSeek-V3 使用了基于规则的奖励模型和基于模型的奖励模型。基于规则的奖励模型适用于那些可以通过特定规则验证的问题,例如某些数学问题和编程问题。基于模型的奖励模型则用于评估那些没有明确答案的问题,例如创意写作和开放式问答。为了提高奖励模型的可靠性,DeepSeek 团队构建了偏好数据,这些数据不仅提供了最终的奖励,还包含了导致奖励的思考过程。
-
群体相对策略优化(Group Relative Policy Optimization, GRPO):GRPO 是一种强化学习算法,它通过比较同一组内不同输出的奖励来优化策略。在 GRPO 中,对于每个问题,模型会生成一组输出,然后通过计算每个输出的奖励来优化策略。
GRPO(Group Relative Policy Optimization)的目标是最大化以下目标函数:其中:
-
,它是用于衡量策略模型 与参考策略 之间差异的KL散度(Kullback-Leibler divergence)。
-
是优势函数,由每个组内输出对应的奖励 计算得出:
在这个目标函数中,通过从旧策略模型 中采样一组输出 ,对策略模型 进行优化。其中包含了对优势函数 的运用,并且对重要性采样比率 进行了裁剪(clip)操作,以平衡学习过程中的更新幅度,避免策略更新过大导致模型不稳定。同时,引入了参考策略 ,通过KL散度约束策略模型 与参考策略的差异,防止策略偏离参考策略太远,从而保证训练的稳定性和有效性。
在DeepSeek-V3的强化学习过程中,通过最大化这个目标函数,使得模型在不同领域的任务中能够更好地对齐人类偏好,提升在各类基准测试中的性能 。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 28
28 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)