2025年用deepseek改命,附保姆教程!
几乎一夜之间,所有人都在关注DeepSeek,甚至我在老家,完全没用过AI的七大姑八大姨,都在问我,DeepSeek是什么,怎么用。还有一些人体验了一下后,拿着8.11和8.9谁大谁小的截图跟我说,这玩意也不行啊。感觉市面上,关于DeepSeek的信息还是很乱。所以,今天除夕,龙年的最后一篇文章,献给DeepSeek,也献给我们自己。我想用8个问题和答案,来让大家详细的了解,DeepSeek-R1
几乎一夜之间,所有人都在关注DeepSeek,甚至我在老家,完全没用过AI的七大姑八大姨,都在问我,DeepSeek是什么,怎么用。
还有一些人体验了一下后,拿着8.11和8.9谁大谁小的截图跟我说,这玩意也不行啊。
感觉市面上,关于DeepSeek的信息还是很乱。
所以,今天除夕,龙年的最后一篇文章,献给DeepSeek,也献给我们自己。
我想用8个问题和答案,来让大家详细的了解,DeepSeek-R1这个模型,是什么,以及,提示词应该怎么写,到底怎么用。
话不多说,开始。
一. DeepSeek是什么?
DeepSeek,是一家在2023年7月17日成立的公司深度求索所开发的大模型名称。

2024年1月5日,他们正式发布DeepSeek LLM,这是深度求索第一个发布的AI大模型。
2024年5月7日,他们发布DeepSeek-V2,正式打响中国大模型价格战,当时新发布的 DeepSeek-V2 的API价格只有 GPT-4o 的 2.7%,随后一周时间,国产厂商全部跟进,字节、阿里、百度、腾讯全部降价。
2024年12月26日,DeepSeek-V3正式发布且直接开源,而且训练成本仅为557.6万美元,剔除掉Meta、OpenAI等大厂的前期探索成本,大概是别人的三分之一,并且整体模型评测能力媲美闭源模型,震惊海外,自此,东方的神秘力量彻底坐实。
2025年1月20日,全新的推理模型DeepSeek-R1发布,同样发布并开源,效果媲美OpenAI o1,同时API价格仅为OpenAI o1的3.7%,再一次震惊海外,让Meta连夜成立四个研究小组,让全球算力暴跌,英伟达的神话都岌岌可危。
就是这么一家公司,而深度求索的背后,是著名量化私募幻方基金,而基金的盈利模式非常简单,跟管理规模绑定,固定收取管理规模的管理费和收益部分的提成资金,无论基金涨跌都能赚钱,真正的旱涝保收的行业。
所以,幻方不缺钱,当年赚了钱,在英伟达还没向中国禁售的时候,幻方直接能掏钱搭一个万卡A100集群。
这也让深度求索,让DeepSeek,不以盈利为导向,目标,就是AI的星辰大海。
二. DeepSeek-R1是什么?
DeepSeek-R1,就是最近爆火的主角了。
也是直接让各路美国AI大佬破防的始作俑者。
给奥特曼都在X上开始阴阳了。
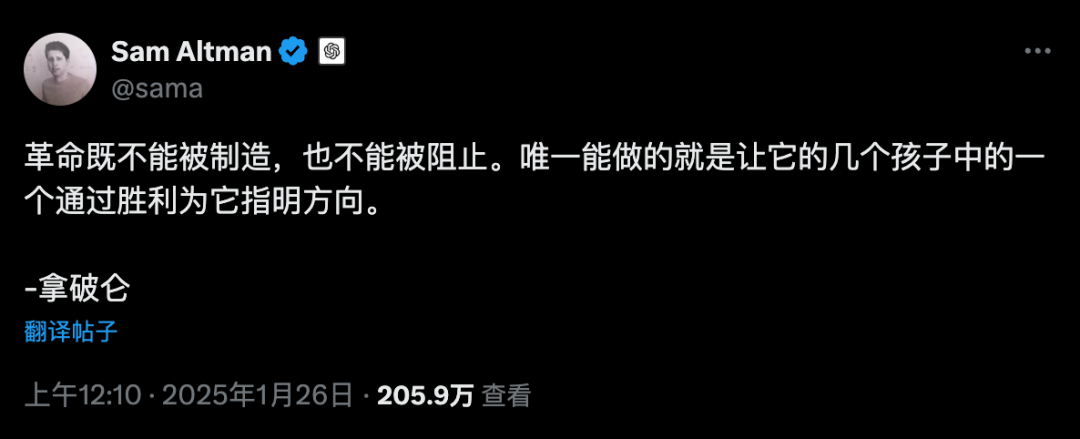
很多人拿DeepSeek-R1和GPT4o比,其实是不对的。
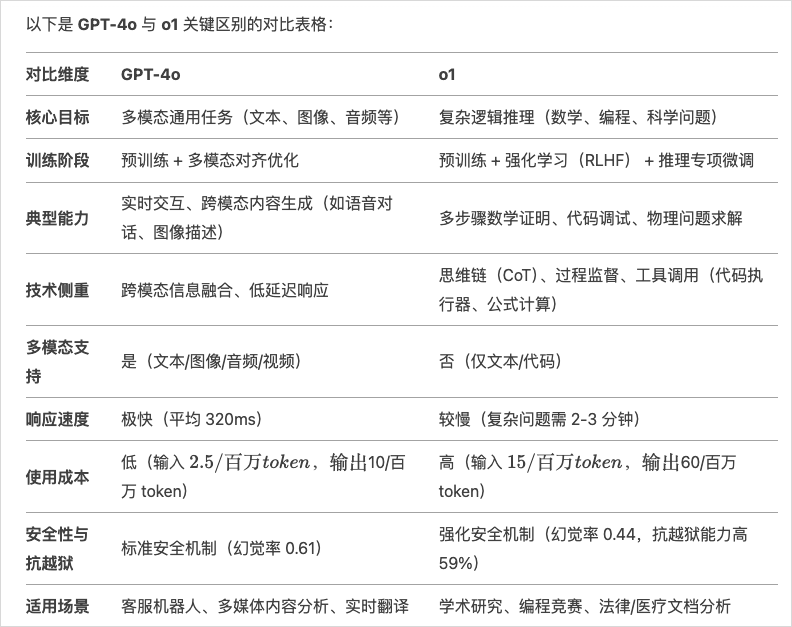
首先,GPT4o是个多模态通用模型,可以理解图片、语音、视频,也可以输出语音。多模态往后做,更像Gemini 2,是一个多模态大一统模型,可以理解一切模态,也可以输出一切模态。
而DeepSeek-R1是一个深度推理模型,对标OpenAI的应该是OpenAI o1,而不是GPT4o,关于OpenAI o1曾经我首发写过一篇文章,可以去看,就不过多赘述了:OpenAI全新发布o1模型 - 我们正式迈入了下一个时代。
现在回头看,当时这个副标题,还是很有前瞻性的。
我也让DeepSeek列个了4o和o1的对比表格,大家应该也能一目了然。
而R1,可以直接类比o1,两者在跑分上,几乎相同。
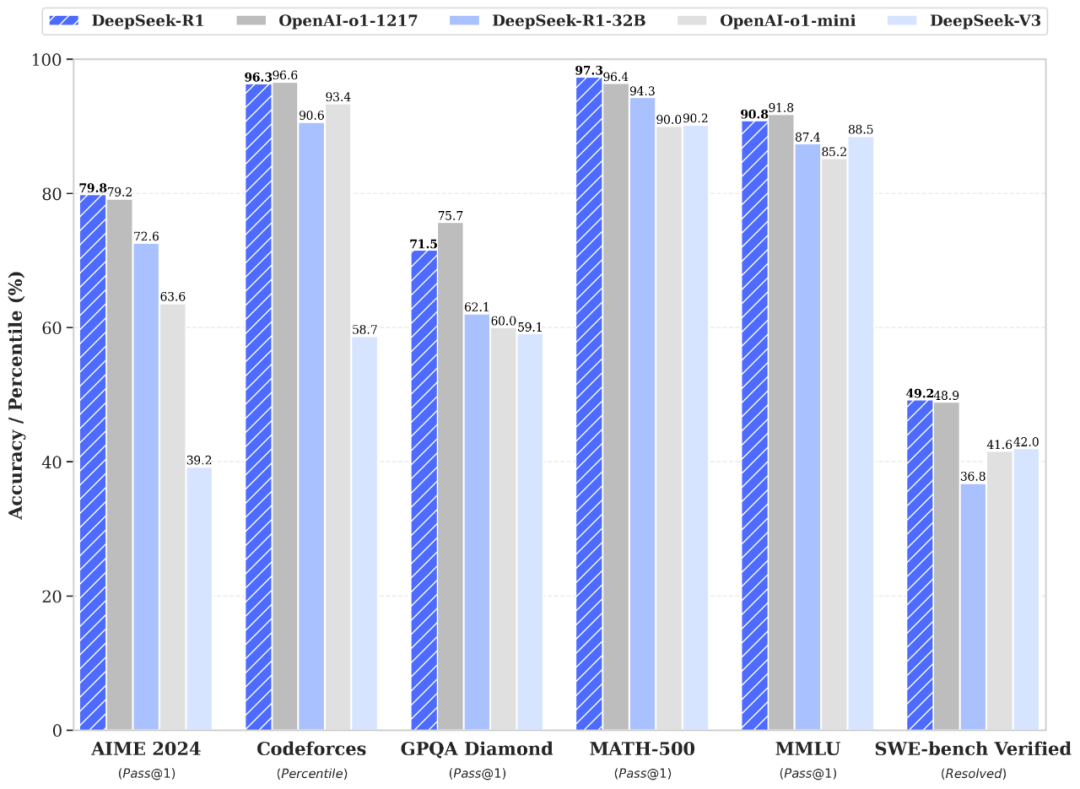
并且已经开源。
HuggingFace 链接:https://huggingface.co/deepseek-ai
论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
三. DeepSeek-R1在哪用?
DeepSeek-R1除了面向开发者的开源模型和API,也有面向普通用户的C端版本。
网页版:https://chat.deepseek.com/
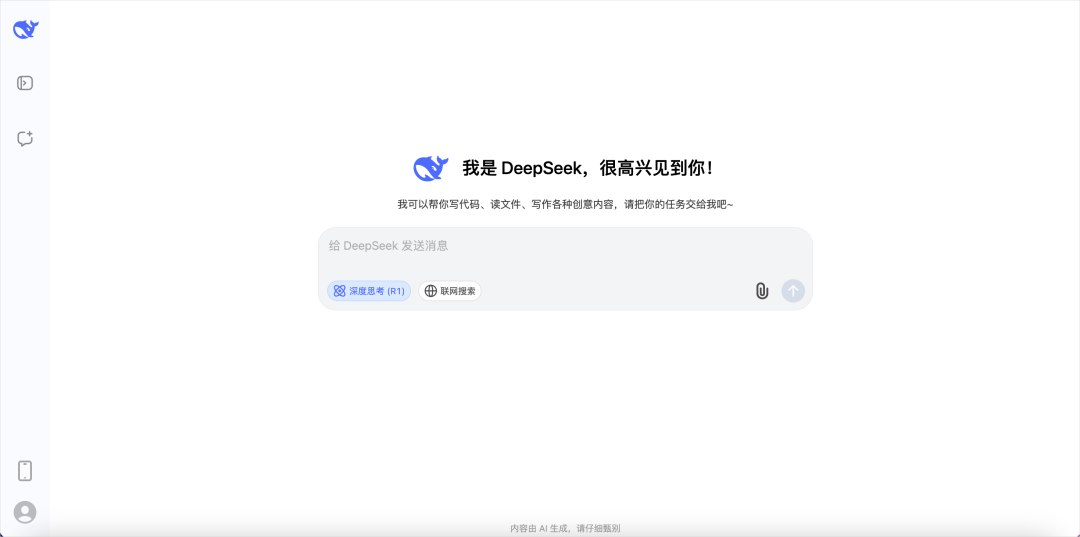
当你勾上深度思考功能,此时就是使用R1模型,当你不勾的时候,使用的是类GPT4o的v3模型。
当然他们也有APP版本,你直接在应用商店搜索DeepSeek就好。
跟网页端交互基本一致。目前免费,就是用户增速过快,所以偶尔会有崩溃断网连不上问题,你可以在这个地方,来看DeepSeek的服务器状态。
https://status.deepseek.com/

四. 应该怎么跟R1对话?
首先,我想明确一点的是,DeepSeek-R1是推理模型,不是通用模型。
在几个月前OpenAI o1刚刚发布时,我用通用模型的方式跟o1对话,写了一堆的结构化提示词,得到了极差的效果,那时候我一度觉得这玩意是个垃圾。
而后面,我才发现,其实是我自己的思维惯性,这玩意跟4o不一样,这不是一个很傻的聊天模型。
这是一个能力很牛逼但不知道你想要什么的真实员工。
今年1月也有一篇海外的文章很火,叫《o1 isn’t a chat model (and that’s the point)》。
跟我是完全一样的看法。
所以,有一个点一定要注意,明确你的目标,而不是给模型任务。
例如我们以前在写prompt的时候,总是会写你是一个XXX,现在我的任务是XXX,你要按照1、2、3步来给我执行balabala。
但是现在,请抛弃那些写法。
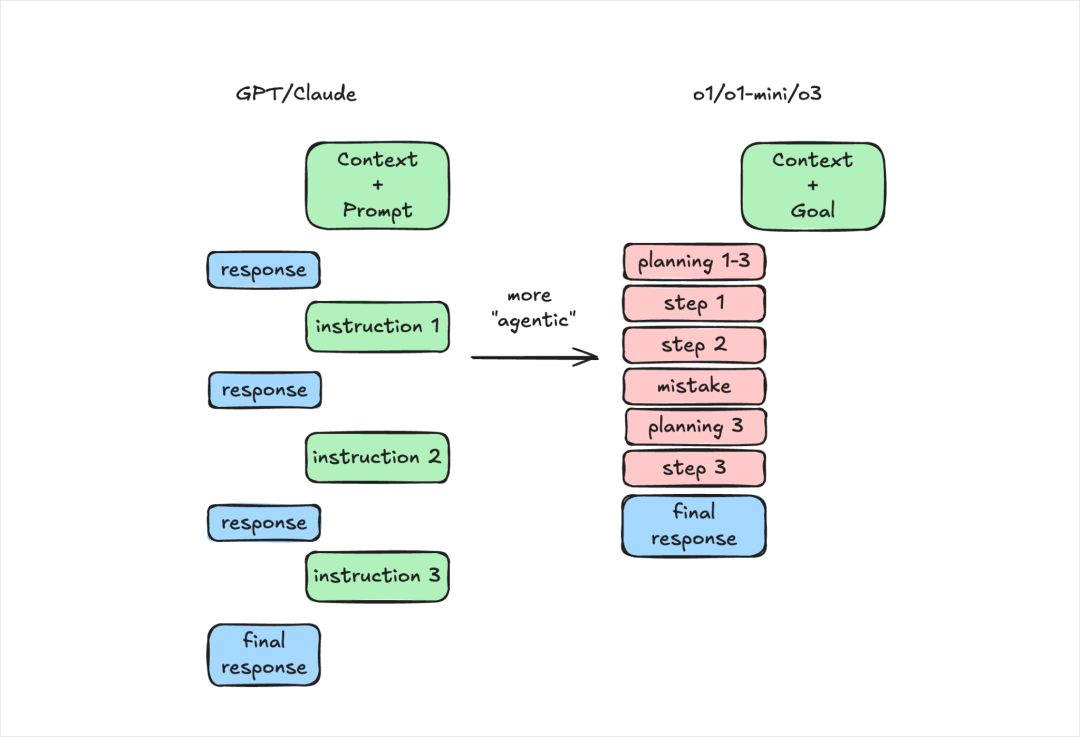
把你的一切,交给AI,让它去进行自我推理,效果会更好。AI会自动填上那些你没说出口的话,会给你想出可能更好的解决方案。
有一个不得不承认的事实是,我是一个很普通的普通人,而像我一样的很多普通人们,现在大概率是不如AI博学和聪明的。
所以,不如说出你的目标,把他当作一个很牛逼的员工,让他,放手去做。
比如这个case。

只需要表达你是谁+你的目标就OK。
特别是你是谁这个背景信息,非常非常的有用。
所以请抛弃掉一起过往所学习的结构化框架,如果真的需要有一个万能Prompt模板,那就是:
你是谁 + 背景信息 + 你的目标
背景信息给的越多越能让R1理解你的需求帮助你更好的完成任务。
时刻把他当成:
这是一个能力很牛逼但不知道你想要什么的员工。
最牛逼的提示词技巧,就是没有技巧。
大道至简,重剑无锋。
所以,千言万语汇聚成一句话就是:用人话清晰的表达出你的需求,这就够了。
五. R1输出的内容看不懂?
很多人在用“说人话”这三个字,来表达推理模型和通用模型不一样,这其实有点奇怪。
不过从实用角度来说,这确实是一个能让普通人看懂AI输出专业内容的小技巧。
不过这并不是一个推理模型才有的技巧,因为一直就存在,本质上就是对方不知道你是谁,不知道你的理解能力和你的学识能力是什么水平。
所以我也想分享一个我自己这两年跟AI对话时用的最多的一个小技巧,也是我自己最常用的“人话”prompt:
我是一个小学生。
当你在跟AI对话时,把这句话往前一摆,自降身位,你就会发现,一切都通了,一切都能看的懂了。
比如我想让R1给我解释一下什么叫大模型中的RL用法。
如果不用这句话的话,就会得到这样的解释。

我相信你看到一定脑壳疼。你就是不懂才需要让它给你解释,结果解释了个这。
但是,如果把那个神句加上呢?


最重要的秘密:扔掉你的提示词模板
如果你还在用各种"专业提示词"和"模板",那就是走错了方向。
DeepSeek根本不吃这一套。
为什么?
因为它的核心是推理型大模型,不是指令型大模型。
这就像两个实习生:
-
一个小书呆子,需要你事无巨细地安排任务步骤。(指令型)
-
一个小机灵鬼,只要你说明目的,他就能自己思考怎么做。(推理型)
让我用一个真实案例来说明,
我们社群一位运营同学的实测,进行新能源行业分析,用于准备与比亚迪供应商谈判。
传统方式:
请你扮演一位新能源行业分析师,按照以下步骤分析:``1. 市场规模``2. 竞争格局``3. 技术路线``4. 未来趋势``要求:每部分800字,引用权威数据...
结果:得到一份干巴巴的报告,一眼AI。

一眼AI,除了正确一点用没有。
正确方式:
我下周要和比亚迪的供应商谈判,但对动力电池一窍不通。帮我用最通俗的语言说明:``1. 他们的技术优势在哪``2. 可能要价多少``3. 有什么谈判时能用的专业术语``重点是让我听得懂,能装得像内行
结果:DeepSeek直接给出接地气的分析,还附带谈判话术。

竟然还带话术的
这就是最大的区别:
DeepSeek不需要你写"专业提示词",
它需要的是真实场景和具体需求。
送您一个通用公式:
我要xx,要给xx用,希望达到xx效果,但担心xx问题…
就像你跟一个聪明的下属说话:
-
不要说"请按照STAR法则写周报"
-
而要说:
我要写周报,老板周一要看,希望重点放在xxx上,重点是让咱们部门在老板面前能达到装逼效果,力压隔壁研发部,但担心研发质疑我们产品文档写得不够详细……"

最被低估的功能:让它"说人话"
很多人抱怨DeepSeek的回复太抽象,像是在读天书。

比如这个,别信
但你可能不知道,只要一个简单的提示词,就能彻底改变这个问题。
这个神奇的提示词是:
说人话。
没错,就这三个字。
我的学员第一次试时还不信,结果…
原始回答:

抽象,真TM抽象
加上"说人话"后的回答:

人话后
瞬间就接地气了,对吧?
因为DeepSeek对“说人话”这个词语很敏感。
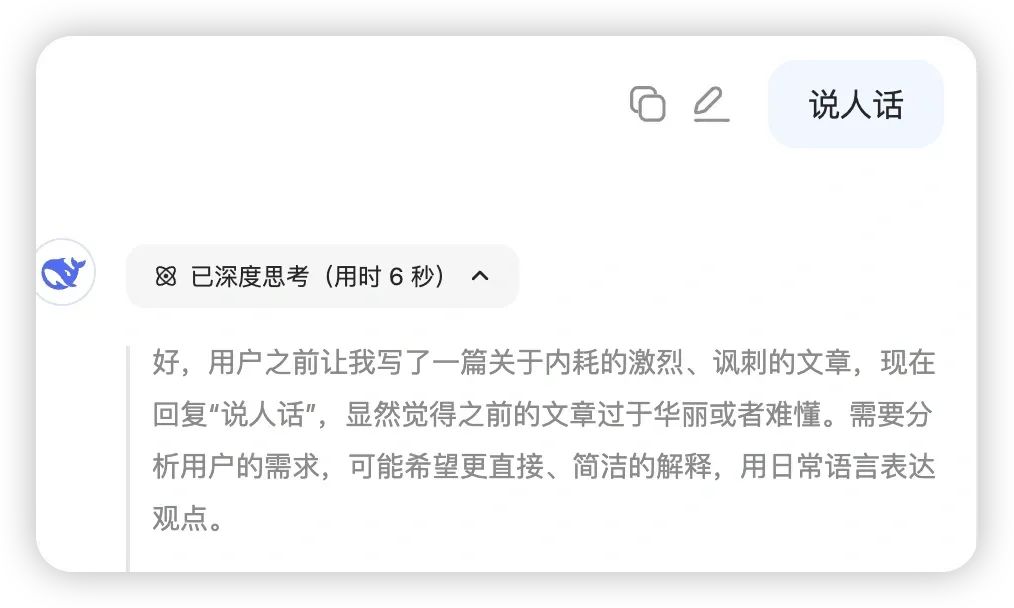
当然,有时候这三个字不够用,还可以用这个详尽版提示词,直接复制过去即可:
【请用以下规范输出:1.语言平实直述,避免抽象隐喻;2.使用日常场景化案例辅助说明;3.优先选择具体名词替代抽象概念;4.保持段落简明(不超过5行);5.技术表述需附通俗解释;6.禁用文学化修辞;7.重点信息前置;8.复杂内容分点说明;9.保持口语化但不过度简化专业内容;10.确保信息准确前提下优先选择大众认知词汇】

最强大的技能:深度思考
这是我不得不说的事:
一个免费的国产AI,正在让月付200美金的GPT-o1坐不住了。
为什么?
因为DeepSeek的思维方式,比GPT-o1更智慧。
让我用一个真实案例来对比:
_OpenAI o1_的回答:

图来自@D&roi老师
_DeepSeek_的回答:

推理,而不是线性罗列
这就是最大的区别:
-
GPT-o1线性罗列,像个高级文档工具
-
DeepSeek深度思考,像个思考伙伴
免费的DeepSeek,直接让整个硅谷AI公司的牛马连夜加班,
幸亏他们不用过春节。
但最近,我发现一个现象:
由于用户暴增,DeepSeek明显调整了响应策略:
-
思考时间从20秒降到5秒
-
回答深度明显下降
-
反思能力受限

算力紧张,只给5秒
这是可以理解的临时措施,毕竟算力就是烧钱。
但对于我们用户来说,如何继续激发它的深度思考能力?
我整理了三个核心提示词,为了装逼,称为深度思考三件套:
-
请在你的思考分析过程中同时**进行**_批判性思考_至少10轮,务必详尽
-
请在你的思考分析过程中同时**从反面考****虑你__的__回答**至少10轮,务必详尽
-
请在你的思考分析过程中同时**对你的回答进行复盘**至少10轮,务必详尽
如此一来,深度思考将从5秒恢复为20秒左右。
斜体的部分,可以自由替换成你所擅长的形式,也可以组合叠加,
但核心是反思。

深度思考变回20秒

最强大的文风转换器
昨天,我用DeepSeek,写了一篇汉赋。
赞扬一下王星有情有义、智勇双全的女友。王星就是前阵子被卖到缅北的演员。

我自己读得特别爽
这用典,这骈文,真的没谁了。
发在群里后,直接炸出了三个语文老师…
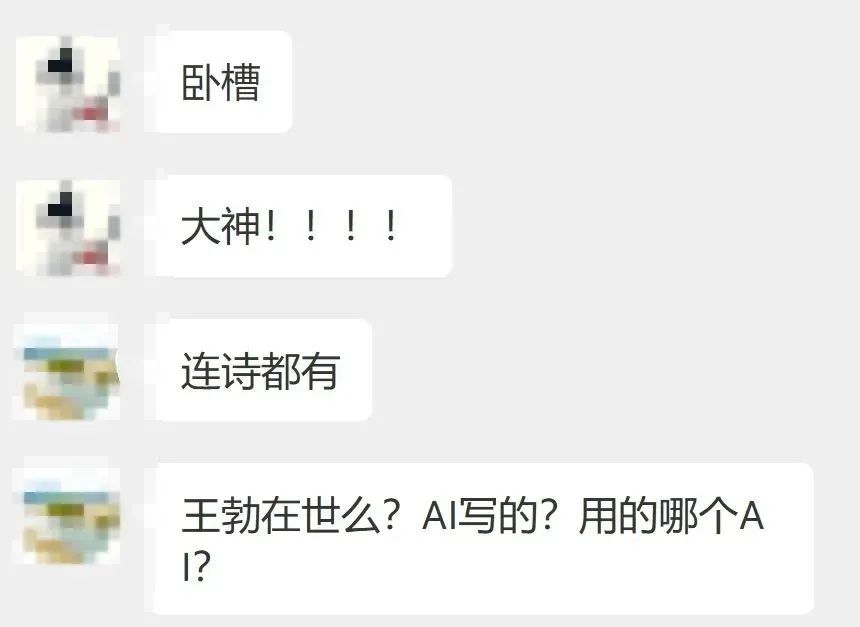
炸人神器
还有的朋友,写出的文字连专业编剧都说老到。

很有味道
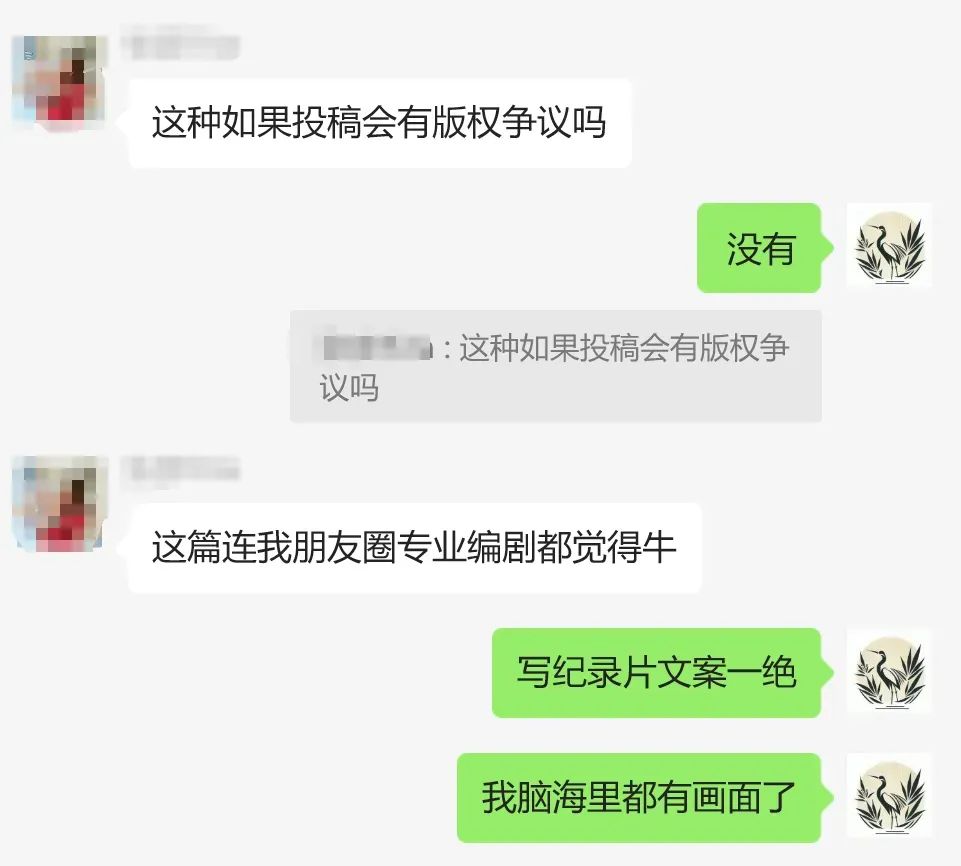
专业编剧都说牛
事实上,这正是DeepSeek的第四个秘密武器:文风转换器
提示词很简单,哪怕口述就行:
模仿xxx的文风,撰写关于xxxxx的一篇xx文体。
但要注意两点局限:
一方面,它更适合模仿经典作家,因为训练数据充足,风格特征明显。
另一方面,不要期待100%还原,80%相似度已经很厉害,重点是能抓住神韵。
我觉得deepseek肯定是训练了大量的文学语料,尤其是中国古典文学。
比如鲁迅、莫言,都是惟妙惟肖。

仿写鲁迅风格
记住那个万能公式:
我要xx,要给xx用,希望达到xx效果,但担心xx问题…
例如:
我要写一篇关于赞颂王星女友机智勇敢用心的赋,用来小红书上面炫技,希望重点放在模仿王勃的篇文上,重点是让我本人的文采装逼,在小红书获得一个亿的赞,但担心别人看不懂太晦涩了……"
类似的风格迁移,也可以放在当代作家上,比如我们模仿刘润老师的跨年演讲:

仿写提示词,可以随意
注意要先提供内容原文(尽量详尽,一般不少于8000字),然后直接要求其模仿即可。

仿写刘润老师效果
当然,为了更好的效果,最好用上万能公式。

使用禁区:什么情况不要用它
说了这么多优点,也必须说说它的局限性。
以下场景不建议使用DeepSeek:
1.长文本写作
超过4000字的文章容易出现逻辑断裂,建议用Claude200k。
因为DeepSeek默认是64k,长文不够用。

长文本目前确实不够用
2.敏感内容
毕竟是国产AI,内置审核尺度丧心病狂。

凡是这样回复的时候,就是触发审核
很多时候你不知道哪句话就触发审核了。
这种情况怎么解决呢?
因为DeepSeek是后置审核,所以有以下三种方案:
1.在你的提问处点击修改,再提交几次,总有一次是不触发审核的。
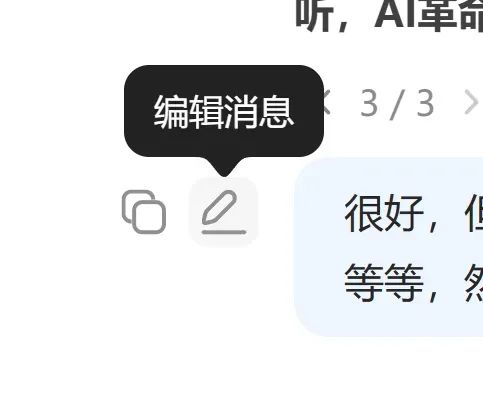
在提问处点击编辑
2.在生成回答的时候,狂点复制回答按钮。这样确保触发审核的时候,你的剪贴板上面拥有前面回答的内容
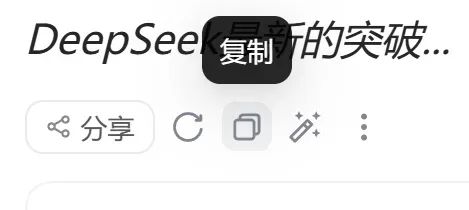
点回答按钮
3.一劳永逸,换御三家。(GPT,Claude,Gemini)
3.个人风格写作
这个就不赘述了,这是个推理模型,适合解决问题、模仿。
但很难通过精确控制来确保你想要的风格写作效果。
这其实不算DeepSeek的缺点,只能算特性。
具体的,我下一篇再来论述吧。

它将如何改变我们的AI时代?
经过几天的密集测试,我越来越确信:
DeepSeek代表了AI的未来方向——更懂人话,更会思考。
你不需要学习它的语言,它在学习理解你的语言。
这意味着什么?
AI的使用门槛正在快速降低。
为了保障稳定和数据安全同时可以本地化部署
0.1为什么要部署到本地而不是直接用在线版?
-
模型管理和本地使用
:部署在本地可以让模型更专注于特定任务,减少与云端环境的干扰,提高训练和推理速度。
-
私密性
:部署在本地可以让模型更易理解和维护,我使用大模型就是不断的与它进行对话,这个过程难免会有很多涉及隐私的东西,我不希望上传到大模型云端,本地部署确保了个人对话的私密性,
-
安全性
:本地部署,那就摆脱了对网络的依赖,可以在无网络的情况下进行操作,从而也提高安全性。
0.2物料准备
0.2.1实施方案:
-
方案:使用自己的电脑,
这个方案全部依靠本地电脑,这台电脑性能就需要满足最低要求;
-
独立显卡,最低RTX3050 4G显卡
-
硬盘尽量大一点,系统盘最少要留有20G的余量
-
内存16G
0.2.2软件准备
-
Ollama:(大型语言模型服务工具软件)
Ollama是一个开源的大型语言模型服务工具,旨在简化在本地计算机上部署和管理大型语言模型(LLMs)的过程; 安装包可以到官网https://ollama.com 下载 -
Chatbox AI
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API。安装了这个软件,可以摆脱命令行的界面,实现了常见的人机对话界面。
安装包可以到官网https://chatboxai.app/zh 下载
以上两款软件都可以在官网自行下载,如果觉得官网下载速度慢,可以留言,为你提供百度网盘下载地址
一、安装步骤
1.Ollama的安装
1.1下载Ollama
1.2点击安装Ollama,等一会就自动完成了安装
1.3检测Ollama是否安装成功。
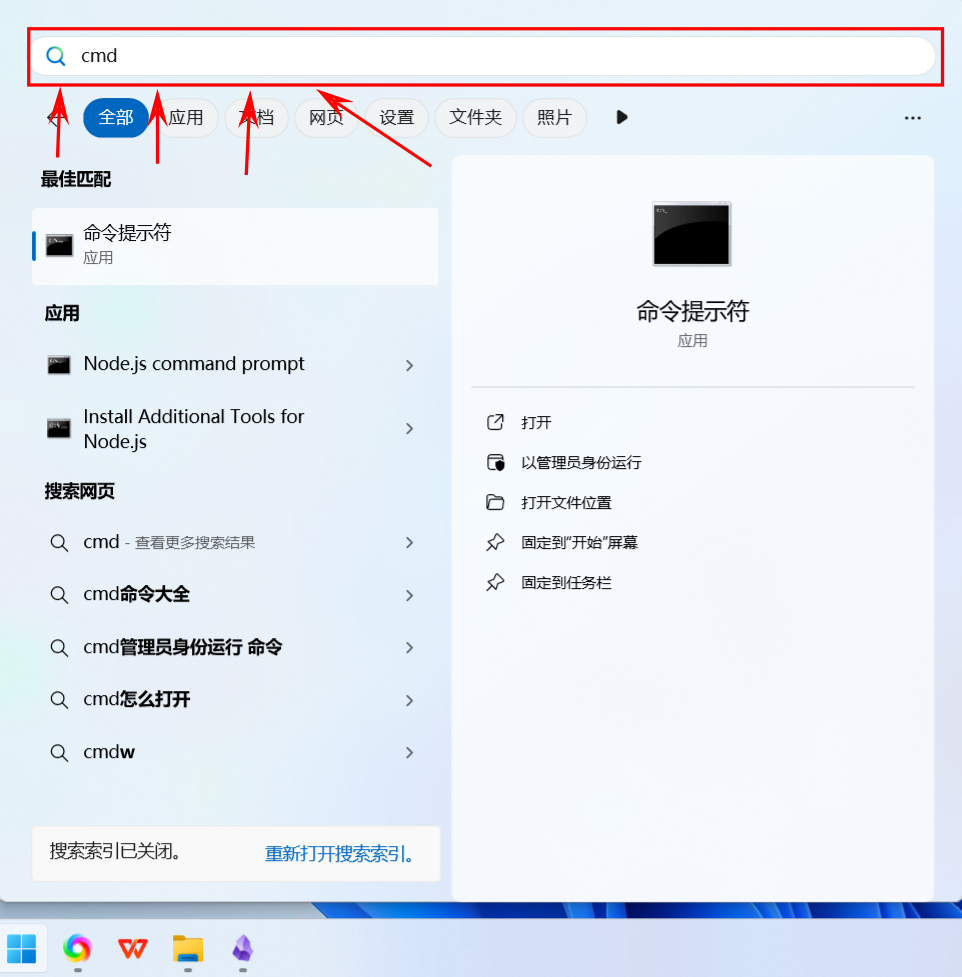
-
点击开始菜单,
-
在搜索框里输入“cmd”,进入“命令提示符”界面
- 在“命令提示符”输入ollama
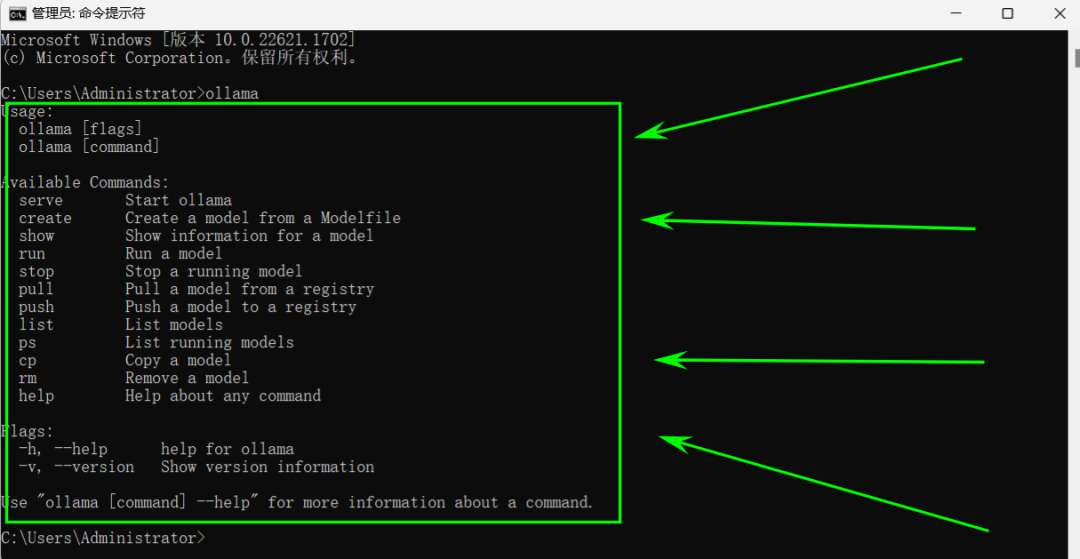
- 当出现下面的内容时,证明ollama已经安装成功;
2.Deepseek-R1模型的安装
2.1打开ollama官网,点击deepseek-r1模型
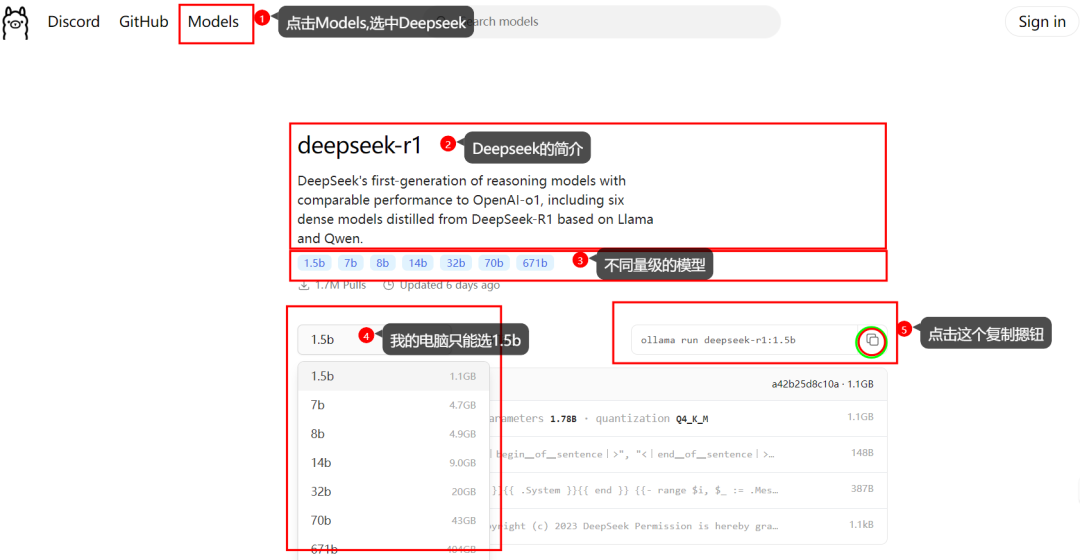
2.2选中1.5b模型。如下图所示复制那一行命令
2.3回到“命令提示符”页面,粘贴上一步的内容
2.4等待ollama从后台将deepseek下载到本地
2.5出现下面这个信息的时候,表明deepseek已经在本地安装成功
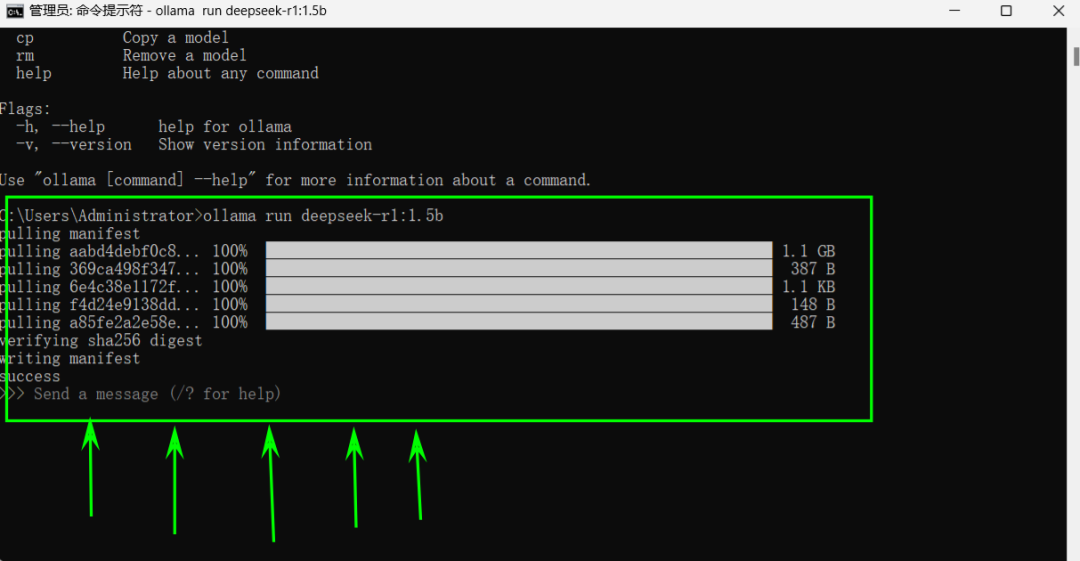
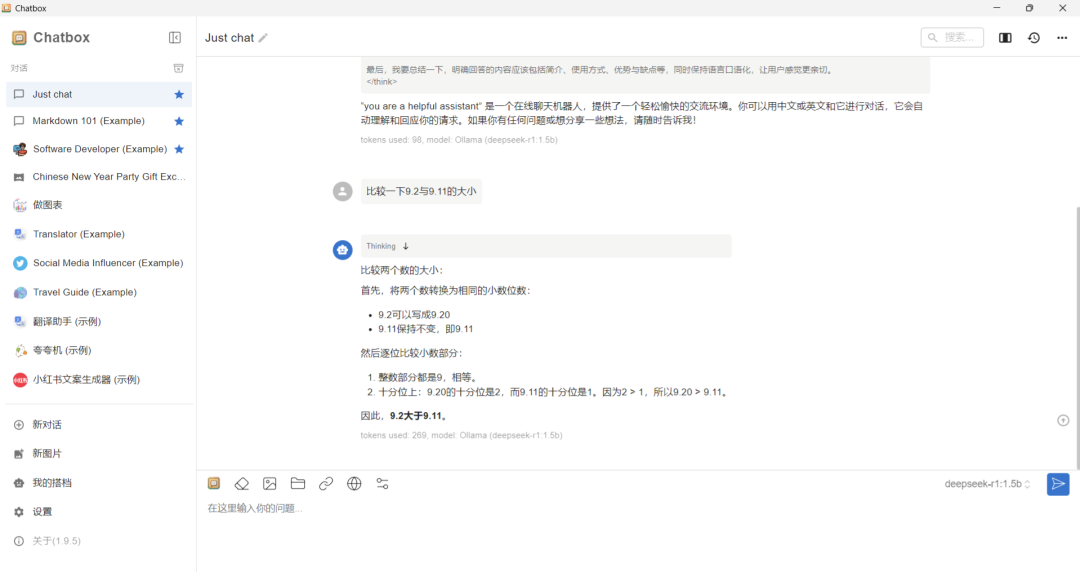
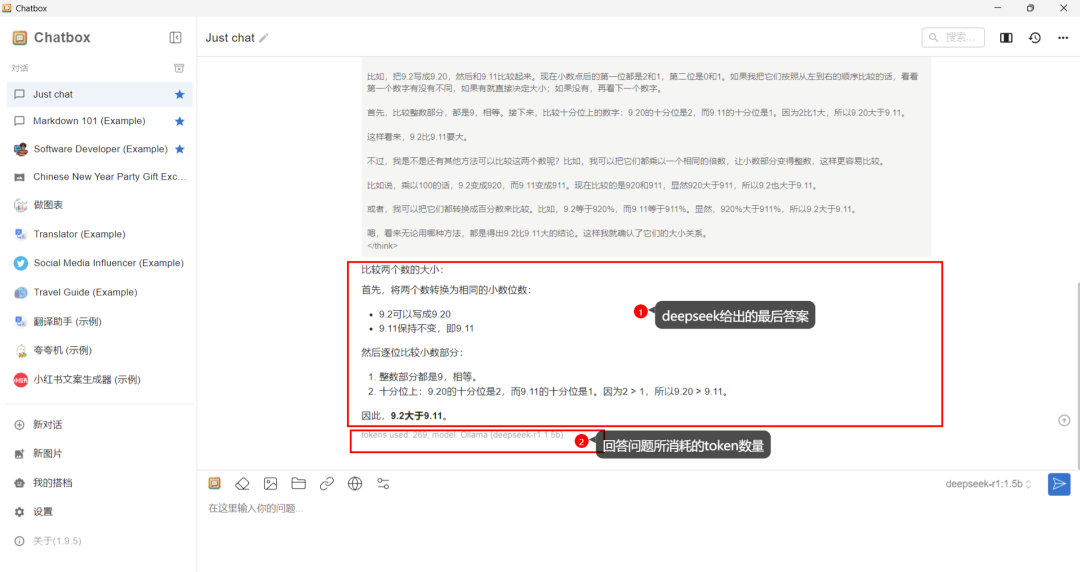
2.6赶紧输入一个比大小的问题,来测试一下deepseek-r1 1.5b的性能。
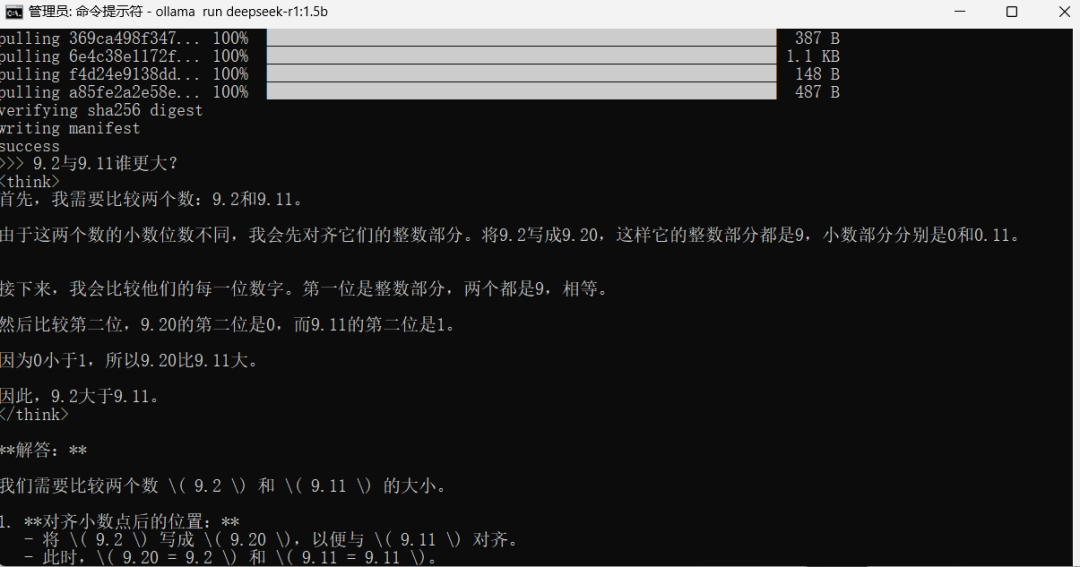
到此,deepseek-r1 1.5b的安装就已经成功。
但是,这种命令提示符的界面,很多人肯定不习惯。大家还是习惯了人机对话的UI界面。
3.Chatbox AI的安装
3.1下载Chatbox AI
- 选择它的原因,就是它在1月26号的版本就已经支持deepseek模型了。
3.2安装成功之后,选中「使用自己的API Key或本地模型」
3.3选中「Ollama API」
3.完成ChatboxAI的安装+deepseek模型的导入之后,就实现了漂亮的人际对话UI
4.测试
零基础如何学习AI大模型
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 18
18 0
0- 0



 已为社区贡献200条内容
已为社区贡献200条内容

所有评论(0)