DeepSeekv3强势来势,低成本暴打chatGPT-4o
DeepSeek 是由中国人工智能公司深度求索(DeepSeek)独立开发的大语言模型系列。最近推出DeepSeek-v3在性能测试上超过一众开源模型、与chatGPT-4o等闭源大模型相当,然而DeepSeek-v3的训练成本与训练时间远低于传统大模型,一经推出就引发AI圈的热议。深度求索(DeepSeek)是一家专注于人工智能(AI)大模型研发的创新科技公司,成立于2023年7月17日,总部位
DeepSeek官网:DeepSeek
背景介绍
DeepSeek 是由中国人工智能公司深度求索(DeepSeek)独立开发的大语言模型系列。最近推出DeepSeek-v3在性能测试上超过一众开源模型、与chatGPT-4o等闭源大模型相当,然而DeepSeek-v3的训练成本与训练时间远低于传统大模型,一经推出就引发AI圈的热议。
深度求索(DeepSeek)是一家专注于人工智能(AI)大模型研发的创新科技公司,成立于2023年7月17日,总部位于中国浙江省杭州市。DeepSeek的创始团队具有深厚的技术背景,并在量化交易领域积累了丰富的经验。该公司由知名量化资管巨头幻方量化创立,并依托其强大的技术团队和硬件资源,迅速在AI领域崭露头角。幻方量化作为DeepSeek的母公司,为其提供了强大的硬件支持,包括万张A100芯片的储备,这使得DeepSeek在AI硬件部署上处于行业领先地位。由于美国的制裁,国内公司无法获取先进GPU进行大模型训练,转向采用别的方式去训练大模型,DeepSeek的MoE架构就是其中的一种。

DeepSeek的优势
DeepSeek-V3 是 DeepSeek 系列的最新版本,于 2024 年 12 月 26 日发布。其核心性能与优势如下:
- 参数规模与架构:DeepSeek-V3 采用混合专家(MoE)架构,总参数达 6710 亿(目前最大的开源模型),每个 token 仅激活 370 亿参数(推理速度会很快),实现了高效的资源利用。
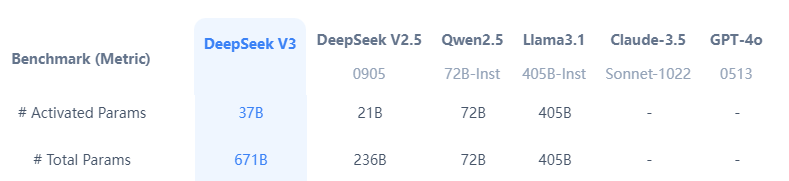
- 训练成本与效率:训练成本仅为 557 万美元,远低于 GPT-4 等模型的 1 亿美元(相当于1/20),同时训练计算量仅为 280 万 GPU 小时,显著提升了效率。
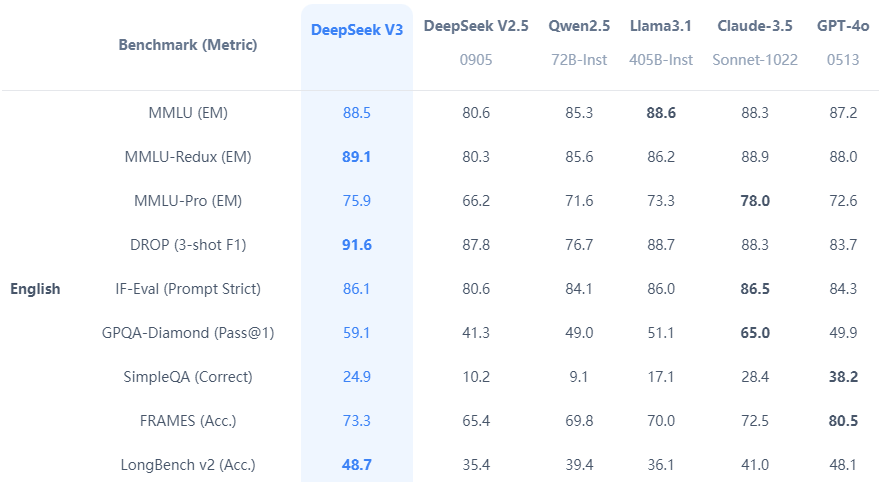
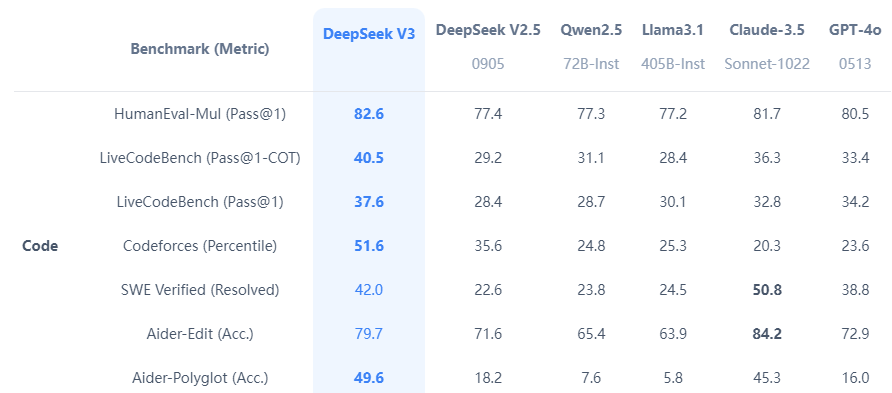
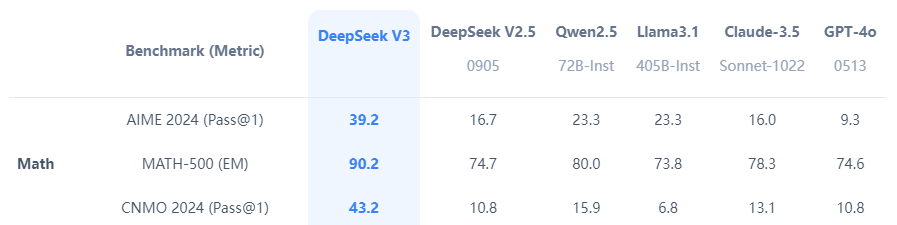
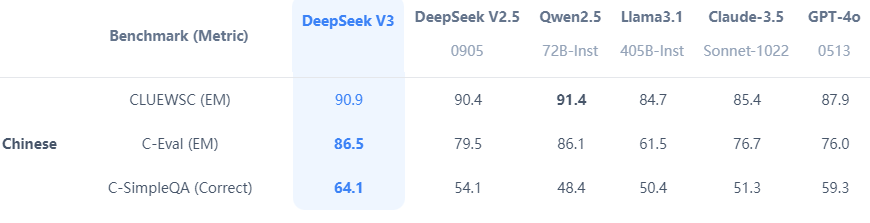
- 性能表现:在多项基准测试中,DeepSeek-V3 超越了 Qwen2.5-72B 和 Llama-3.1-405B 等开源模型,并在代码生成、数学推理、中文理解等方面与 GPT-4o 和 Claude-3.5-Sonnet 等闭源模型相当。
- 生成速度:生成速度从 20 TPS 提升至 60 TPS,为用户提供了更流畅的使用体验。
TPS(Tokens Per Second,每秒处理的 token 数量)
定义:TPS 是衡量大语言模型生成速度的指标,表示模型每秒能够生成多少个 token(即单词或子词单元)。
意义:TPS 越高,模型的响应速度越快,用户体验越流畅。例如,DeepSeek-V3 的 TPS 从 20 提升到 60,意味着其生成速度显著提高。
影响因素:模型架构、硬件性能、优化技术(如并行计算、量化)等都会影响 TPS。
- 多语言与多模态能力:支持多语言处理,并在中文任务中表现尤为突出,同时在视觉语言处理和多模态推理方面展现了卓越的能力。
低成本训练的方法
DeepSeek 取得显著成绩的关键在于其创新的技术方法和高效的资源利用策略:
- 混合专家架构(MoE):通过动态选择专家模块,显著降低了计算资源需求,同时保持了高性能。(将大模型的参数分模块进行专家化训练,类似于大脑的分区处理专项任务的功能)
- 无辅助损失负载均衡:创新性地实现了负载均衡,避免了传统方法中因辅助损失导致的性能下降。
无辅助损失负载均衡(Auxiliary Loss-Free Load Balancing)
- 定义:在 MoE 架构中,负载均衡是指确保各个专家模块的计算负载均匀分配。传统方法通过引入辅助损失函数来实现负载均衡,但这种方式可能导致性能下降。无辅助损失负载均衡则通过创新技术实现均衡,无需引入额外的损失函数。
- 优势:
- 避免性能损失:无需辅助损失函数,保持模型性能。
- 高效均衡:通过动态调整专家模块的激活策略,实现负载均衡。
- 多 token 预测(MTP):MTP(多Token预测)是一种训练技术,它让模型在预测下一个Token的同时,尝试预测后续多个Token,仿佛一次望见未来的多个步骤。这种并行预测不仅提升了模型对上下文关系的理解,提高了生成质量,还通过减少生成过程中的迭代次数,加速了文本生成,使模型更加高效。
- FP8 混合精度训练:FP8混合精度训练以8位浮点数进行计算,大幅降低内存和计算需求,如同在高精度与低资源之间找到了完美的平衡点。这种方法在保持模型精度的同时,显著提升了训练效率,使复杂模型的训练更加轻盈迅捷。
- 分布式训练优化:采用 DualPipe 流水线并行策略和高效的跨节点通信技术,最大限度地提高了硬件利用率。
MoE架构的缺点
MoE(混合专家模型)虽然在效率和性能上很能打,但也有一些让人头疼的地方:
1. 复杂性爆表:
- 不光要设计多个专家模块,还得搞个路由机制(比如门控网络),开发难度直线上升。
- 训练起来更麻烦,专家模块动态选择和负载均衡的问题,得精心调参才能搞定。
2. 负载均衡 headache:
- 有些专家太受欢迎,活儿太多,有些专家则很少被使用,资源浪费严重。
- 虽然可以用辅助损失函数来平衡,但可能影响模型性能;不用辅助损失,又实现起来很困难。
3. 通信开销太大:
- 分布式训练时,专家模块的激活信息在设备或节点间传递,通信瓶颈明显。
- 还得高性能的网络硬件(如 InfiniBand)来减少延迟,成本更高。
4. 推理效率也不高:
- 动态选择专家模块会增加计算开销,影响推理速度。
- 内存占用更高,得存储多个专家模块的参数。
5. 泛化能力一般般:
- 由于MoE架构是对模型参数针对不同任务分开进行训练,推理时只选择部分参数进行推理,虽然提高模型的效率,但是这也会导致部分交叉性的任务比较难解决(模型泛化能力一般)。
- 路由机制如果设计不好,模型表现可能不稳定。
6. 饿死专家or撑死专家:
- 对训练数据分布敏感,数据不均可能导致有些专家训练不足。
- 发挥MoE潜力,通常需要更大规模的数据集。
7. 调试和解释起来真麻烦:
- 模型结构复杂,调试和定位问题比传统模型难得多。
- 动态路由机制让模型决策过程难以解释,可解释性差。
DeepSeek的用武之地
DeepSeek-v3性能媲美GPT-4o,还开源,可以在本地训练和推理,用户可以根据需要修改模型。相比LLaMa3,DeepSeek有以下优点:
1. 低成本AI解决方案:
- 推理成本极低(每百万 token 仅 1 元),适合预算有限的中小企业,或需要高性价比方案的大规模部署场景,如智能客服、自动化报告生成等。
2. 中文任务处理一把手:
- 在中文理解和生成任务中表现突出,适合中文智能问答(如客服、教育、医疗等领域)和中文内容创作(如文章生成、广告文案、社交媒体内容等)。
3. 代码生成与编程辅助:
- 在代码生成、补全和纠错任务中表现优异,适合代码补全与纠错(提高开发效率)、代码解释与文档生成(帮助新手理解代码)。
4. 数学与科学计算小能手:
- 在数学问题求解和数据分析任务中表现卓越,适合数学教育(解题指导和练习)和科研与工程(解决复杂问题)。
5. 多模态任务处理:
- 支持视觉语言处理和多模态推理,适合图像理解与生成(如电商平台的图像描述、设计领域的图像生成)和视觉问答(如智能助手、教育等领域)。
6. 企业应用的理想选择:
- 高效性和低成本,适合智能客服(自动回答用户问题,降低运营成本)和知识管理(整理和检索企业内部知识库,提升信息利用效率)。
7. 开源生态与开发者支持:
- 开源策略为开发者提供了灵活的工具和模型,适合学术研究(进行实验和创新)和技术开发(构建定制化 AI 应用)。
8. 实时性与高吞吐量场景:
- 生成速度(60 TPS)显著高于 LLaMA 3,适合实时对话系统(如聊天机器人、虚拟助手)和大规模内容生成(如新闻摘要、社交媒体内容批量生成)。
更多信息,欢迎关注公众号DThruster


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)