【DeepSeek-R1背后的技术】系列三:强化学习(Reinforcement Learning, RL)
【DeepSeek-R1背后的技术】系列博文:
第1篇:混合专家模型(MoE)
第2篇:大模型知识蒸馏(Knowledge Distillation)
第3篇:强化学习(Reinforcement Learning, RL)
第4篇:本地部署DeepSeek,断网也能畅聊!
第5篇:DeepSeek-R1微调指南
第6篇:思维链(CoT)
第7篇:冷启动
第8篇:位置编码介绍(绝对位置编码、RoPE、ALiBi、YaRN)
第9篇:MLA(Multi-Head Latent Attention,多头潜在注意力)
第10篇:PEFT(参数高效微调——Adapter、Prefix Tuning、LoRA)
第11篇:RAG原理介绍和本地部署(DeepSeek+RAGFlow构建个人知识库)
第12篇:分词算法Tokenizer(WordPiece,Byte-Pair Encoding (BPE),Byte-level BPE(BBPE))
第13篇:归一化方式介绍(BatchNorm, LayerNorm, Instance Norm 和 GroupNorm)
第14篇:MoE源码分析(腾讯Hunyuan大模型介绍)
目录
1 简介
1.1 强化学习(RL)简介
强化学习(Reinforcement Learning, RL)是一种智能体在与环境互动过程中,通过试错和奖励机制学习如何达成目标的算法。在这个过程中,智能体会不断探索环境,采取行动,并根据环境反馈的奖励或惩罚调整自己的行为策略,最终学习到最优策略。因此,反复实验(trial and error) 和 延迟奖励(delayed reward) 是强化学习最重要的两个特征。
强化学习已在多个领域得到应用,例如游戏(例如围棋AlphaGo)、机器人(例如波士顿动力机器狗)、金融(例如量化交易策略)和大模型(例如语言大模型训练范式RLHF)等。
如下图所示,强化学习的基本要素包括:
- 智能体 (Agent):指 LLM/Stable Diffusion 等大模型。
- 环境 (Environment):指用户使用和反馈。
- 状态 (State):环境中所有可能状态的集合。
- 动作 (Action):智能体所有可能动作的集合。
- 奖励 (Reward):智能体在环境的某一状态下所获得的奖励。
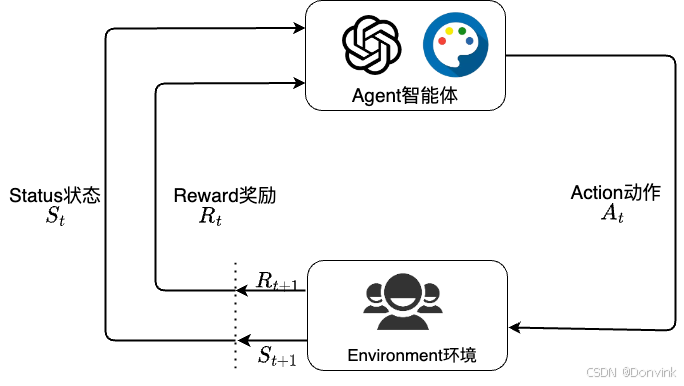
强化学习基本概念:

智能体的目标是找到一个策略,根据当前观测到的环境状态和奖励反馈,选择最大化预期奖励的最佳动作。
1.2 基于人类反馈的强化学习 (RLHF) 简介
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 是一种新颖的人工智能训练方法,它结合了强化学习和人类反馈,通过融入用户智慧和经验,引导智能体学习和进化。该技术已在 GPT-4、Gemini、Claude 等自然语言大模型中得到广泛应用,并取得了显著成效。
如下图所示,自然语言大模型RLHF训练过程包含四个重要角色和三个步骤。
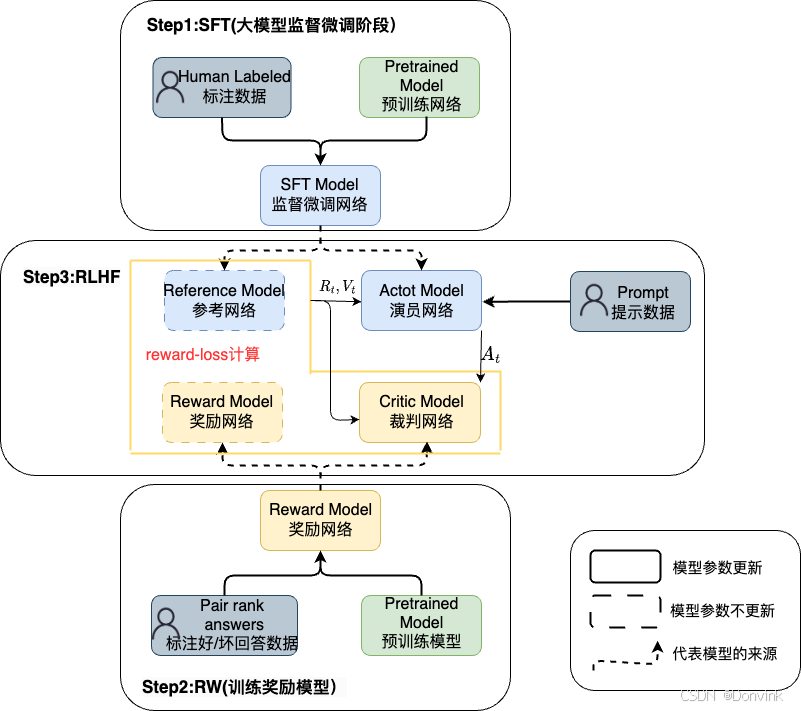
1.2.1 四个重要角色
- Actor Model(演员模型):待训练的语言模型。
- Critic Model(评论家模型):预测语言模型输出的奖励。
- Reward Model(奖励模型):计算语言模型在当前状态下的奖励。
- Reference Model(参考模型):为Actor Model参数更新提供“约束”,防止其过度偏离。
其中,Actor/Critic Model在RLHF阶段是需要训练(参数更新),而Reward/Reference Model是参数冻结的。
其他角色:
- Pretrained Model (预训练模型):是指大量文本数据上进行训练的语言模型。预训练模型已经学习了语言的基本知识,例如词法、句法和语义等。
- SFT Model (监督微调模型):使用人类标注高质量数据对Pretrained Model的监督训练得到,在RLHF阶段用于初始化Actor模型和Reference模型。
- Reward Model 奖励网络:使用人类标注候选文本排序数据集对Pretrained Model的监督训练得到,能够提供LLM输出文本的‘好坏’奖励信号。在RLHF阶段用于初始化Reward模型和Critic模型。
1.2.2 三个步骤
- SFT(大模型监督微调)阶段:使用人工标注数据集对预训练模型进行监督微调,得到SFT Model(监督微调模型)。
- RW(奖励模型训练)阶段:使用SFT模型生成多个回答,人工标注回答的‘好坏’得到排序标注数据集,对预训练模型进行训练,得到Reward Model(奖励模型)。
- RLHF阶段:Actor模型生成文本,利用Critic/Reward/Reference Model(图中黄色框区域)共同组成了一个“reward-loss”计算体系,产生奖励信号,对Actor和Critic Model进行更新,直到 Actor 模型达到理想状态。
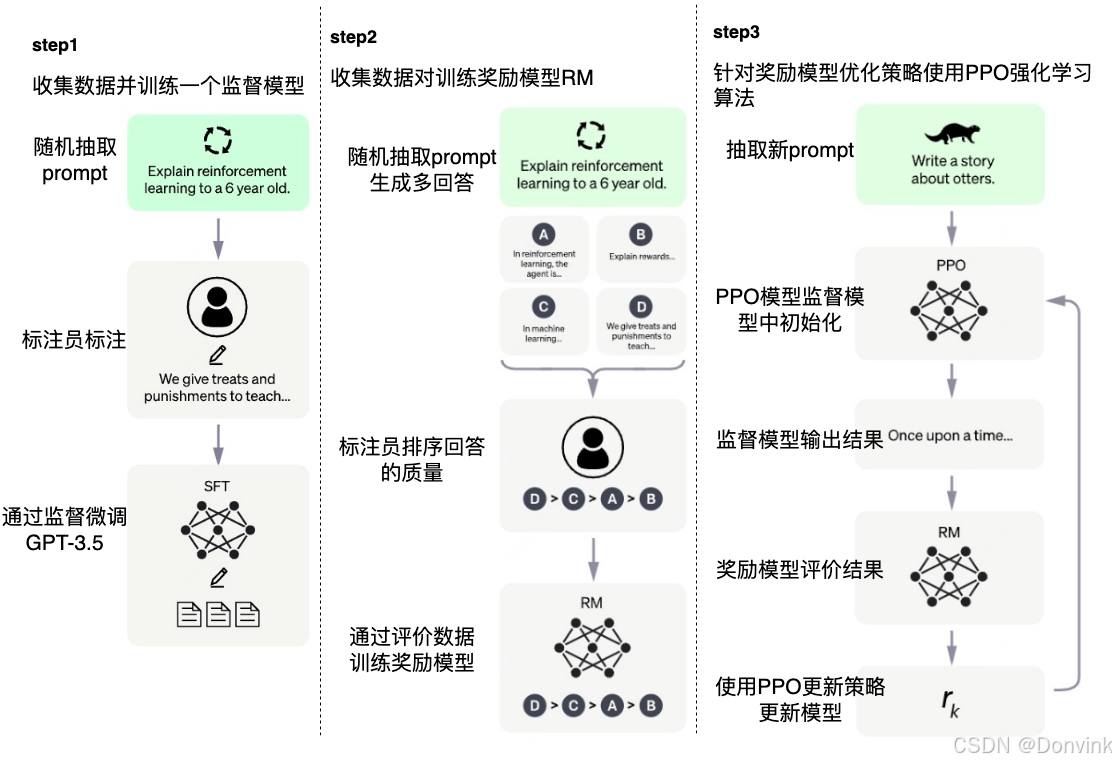
下图为OpenAI发布的GPT-3.5的RLHF的过程。
2 强化算法
下面介绍一些常用的RL算法:PPO、GRPO和PRIME。DeepSeek使用的是GRPO算法。
2.1 PPO(Proximal Policy Optimization)
2.1.1 核心思想
PPO是一种基于策略梯度(Policy Gradient)的强化学习算法,旨在通过限制策略更新的幅度来保证训练稳定性,避免传统策略梯度方法中因更新过大导致的性能崩溃。
2.1.2 算法步骤
- 目标函数设计

- 优势估计

- 更新策略
通过多轮小批量梯度上升优化目标函数,避免单步更新过大。
2.1.3 优点
- 训练稳定,无需复杂的信任区域计算(如TRPO)。
- 样本利用率高,适用于连续和离散动作空间。
2.1.4 缺点
- 超参数(如剪切阈值( \epsilon ))对性能敏感。
- 对优势函数估计的准确性依赖较高。
2.1.5 应用场景
游戏AI(如Dota 2、星际争霸II)、机器人控制、自然语言生成。
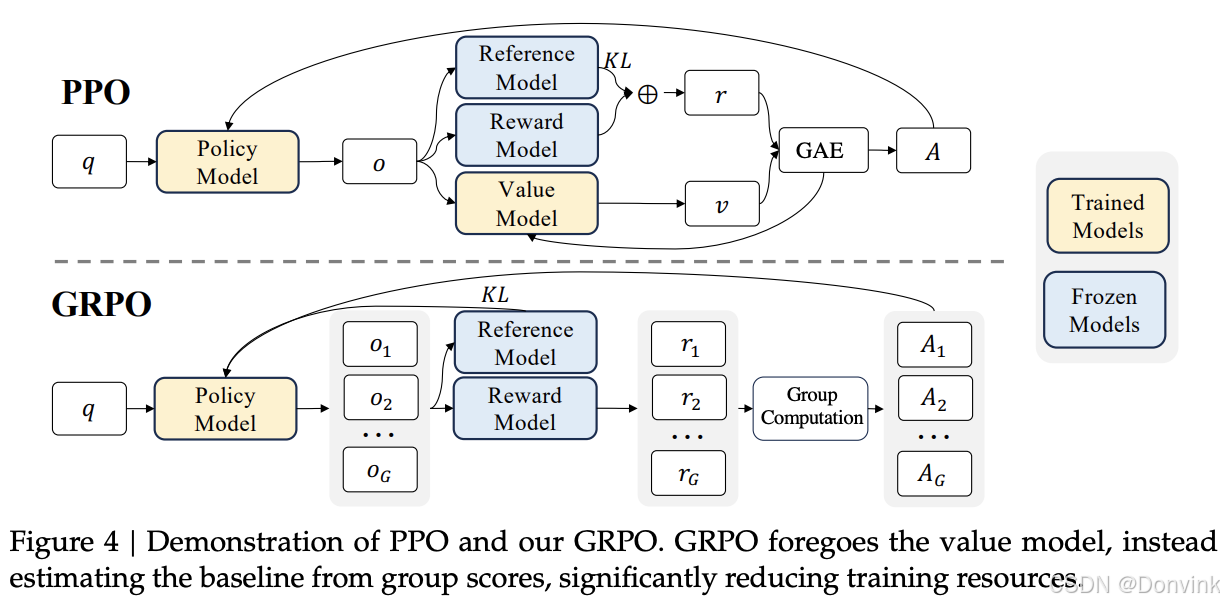
2.2 GRPO(Group Relative Policy Optimization)
GRPO(Group Relative Policy Optimization) 是一种基于群体相对性能的策略优化方法,旨在通过比较不同策略组(Group)的表现来指导策略更新,提升训练的稳定性和多样性。该方法通常用于多任务学习或多智能体强化学习场景,通过组间相对评估避免局部最优。
论文:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
2.2.1 核心思想
- 群体分组(Grouping):将策略划分为多个组(例如不同策略参数初始化或不同任务分配),每个组独立与环境交互。
- 相对性能评估:根据组的相对表现(如平均回报)动态调整策略更新方向。
- 策略更新约束:通过组间比较,抑制低性能组的更新幅度,促进高性能组的探索。
2.2.2 算法步骤

伪代码如下:
2.2.3 优点
- 避免局部最优:组间竞争促进策略多样性,减少早熟收敛。
- 适应多任务:天然支持多任务学习,各组可专注于不同子任务。
- 资源分配高效:动态调整组间权重,集中资源训练高性能策略。
2.2.4 缺点
- 计算开销大:维护多个策略组增加内存和计算成本。
- 超参数敏感:组数 ( K ) 和温度 ( \tau ) 需精细调节。
- 组间干扰:低效组可能拖累整体训练速度。
2.2.5 应用场景
- 多任务强化学习:每组处理不同任务(如机器人抓取不同物体)。
- 多智能体协同:各组代表不同智能体策略,通过相对评估优化协作。
- 超参数搜索:将不同超参数配置视为组,快速筛选最优组合。
2.2.6 对比其他算法
| 算法 | 核心机制 | 适用场景 | 与GRPO的区别 |
|---|---|---|---|
| PPO | 剪切策略更新幅度 | 单任务通用场景 | GRPO通过组间比较提升多样性 |
| MAPPO | 多智能体策略优化 | 协作型多智能体 | GRPO强调组间竞争而非协作 |
| ES | 进化策略全局搜索 | 高维参数空间优化 | GRPO基于梯度更新而非进化 |
总结:
GRPO 通过分组策略的相对性能评估和动态资源分配,平衡探索与利用,适用于需要多样性和多任务协同的场景。尽管计算成本较高,但其在复杂任务中的全局搜索能力显著优于传统单组策略优化方法。
2.2.7 R1技术报告相关细节
- GRPO
GRPO与 PPO、RLHF 具有相似之处,但它摒弃了传统需要大规模价值网络 (Critic) 的范式,改为在同一个问题上采样多条回答:
- 假设对某个问题 q,采样了 G 个回答:o1, o2, …, oG;
- 给每个回答打出奖励 ri(可能包含正确性、格式得分等),接着计算标准分型的优势函数 Ai;
- 在训练新策略时,只看这些回答的相对排名(谁好谁差),不用像传统 PPO 那样用一个单独的价值网络去预测状态价值,减少了大量参数与不稳定因素;
- 同时,GRPO 也会在损失中加入 KL 惩罚,避免更新过猛导致策略崩溃。
- 奖励设计:正确性、格式、语言一致性等
在 DeepSeek R1 论文里,对奖励函数的设计有如下重点:
- 正确性奖励:对数学题看答案是否正确,对编程题可用编译与单测来判定。
- 格式奖励:必须按 … 和 … 输出,如果缺失或混乱则减分。
- 语言一致性:如果指定需要英文/中文,就以一定策略统计 中的语言,语言杂糅严重则扣分。这点在 DeepSeek-R1-Zero 经常出现,如出现“英文+中日韩字符杂糅”的写法。
- 部分对齐奖励:用于惩罚可能不安全或明显侮辱性的回答。
- 多阶段迭代:从推理能力到全场景对齐
为兼顾通用能力,论文中提到在 RL 近乎收敛后,会再采集一批语料(包括生成正确答案的推理数据),再做一次 SFT,合并如写作、角色扮演等非推理数据集,以防只剩下“会做题,不会对话”这种极端状态。然后进行第二轮 RL,对全场景进行调优。
最终得到的 DeepSeek R1 兼具强推理力与通用对话处理能力,达成了在各种 benchmark 上高分的结果。
2.2.8 示例代码
# 请注意这只是简化的示例,忽略了各种超参数细节
# GRPO 伪代码 (结果监督)
for iteration in range(N_iterations):
# 1) 设置参考模型 pi_ref <- pi_theta
pi_ref = clone(pi_theta)
for step in range(M_steps_per_iter):
# 2) 从训练集中取一批问题 D_b
D_b = sample_batch(train_dataset, batch_size=B)
# 3) 让旧策略 pi_theta 生成 G 个输出
# o_i 表示第 i 个候选答案
batch_outs = []
for q in D_b:
outs_for_q = []
for i in range(G):
o_i = sample(pi_theta, q)
outs_for_q.append(o_i)
batch_outs.append(outs_for_q)
# 4) 对每个输出用奖励模型 RM 打分
# r_i = RM(q, o_i)
# 同时做分组归一化
# r_i_tilde = (r_i - mean(r)) / std(r)
# 赋值给 A_i (整条序列的优势)
# 这里只是一种写法:对 batch 内每个 q 都做
for outs_for_q in batch_outs:
# outs_for_q 大小是 G
r_list = [RM(q, o_i) for o_i in outs_for_q]
mean_r = mean(r_list)
std_r = std(r_list)
if std_r == 0: std_r = 1e-8 # 避免除0
for i, o_i in enumerate(outs_for_q):
r_tilde = (r_list[i] - mean_r) / std_r
# 把这个 r_tilde 记为 A(o_i) 用于后续计算
# 也可以存在某个 data structure 里
# 5) 根据 GRPO 目标函数做梯度更新
# 关键是每个 token 的优势都用 A(o_i)
# 并加上 KL 正则
loss = compute_grpo_loss(pi_theta, pi_ref, batch_outs, r_tilde_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
2.3 Long CoT(Long Chain-of-Thought for Decision-Making)
2.3.1 核心思想
Long CoT将自然语言处理中的“思维链”(Chain-of-Thought)扩展为多步推理机制,用于强化学习中的长期规划,通过显式建模推理路径提升决策质量。
2.3.2 算法步骤

2.3.3 优点
- 显式建模长期依赖,避免短视决策。
- 提升复杂任务中的规划能力(如战略游戏、机器人导航)。
2.3.4 缺点
- 推理链生成增加计算开销。
- 需要设计高效的推理路径生成机制。
2.3.5 应用场景
需要多步规划的复杂任务(如围棋、自动驾驶)。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)