快速搭建DeepSeek本地RAG应用
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。的条件,当然前面也提到了,在大模型框架如此成熟的当下,轮子必然不需要重复制造,我们只需要提供想法和场景,然后合理的将大模型能力。给到大模型,那么大模型在推理时,我们在数据库里搜索到的信息就作为辅助信息帮助大模型完成推理,从而让
前言
由 深度求索 开源的DeepSeek-R1推理模型在性能上已经能够对标OpenAI-o1正式版,正巧马上大年初四轮到我值班处理告警,突发奇想能不能让DeepSeek-R1来帮我识别告警并结合之前同事们处理告警时的记录信息来合理给出处置建议。
因为告警信息属于公司机密数据,所以肯定不能直接调用deepseek-reasoner的API,其次因为告警信息随着需求的开发会逐渐增多以及每次相同的告警可能会有不同的处置方式,所以需要有一种方式让大模型能随时扩充 告警知识库,所以最终选择如下实现形式。
- 大模型本地部署;
- 基于RAG实现告警信息检索增强。
其中本地部署大模型的方式有很多种,例如LM Studio和Ollama都可以简单方便的本地部署大模型,但是LM Studio没有开源,所以从数据安全的角度出发,这里选择Ollama。
至于RAG的实现,如果自己手动搭建一套RAG系统那简直要了老命了,所以这里选择使用AnythingLLM来傻瓜式的实现RAG。
最终本文基于Ollama + AnythingLLM + DeepSeek-R1来实现告警信息处理的RAG应用,鉴于只是一个入门,所以AnythingLLM选择桌面版,可以实现全程零代码开发,操作起来也十分简单。

正文
一. 基于Ollama本地部署DeepSeek-R1
Ollama是一款开源的大模型 管理底座,主要用于解决AI大模型在本地的 硬件配置 和 环境搭建,AI非专业人士可以快速基于Ollama完成大模型的下载和部署,同时Ollama也对外暴露统一协议的API,极大方便在本地搭建自己的大模型应用,无论是学习还是生产,Ollama绝对是本地部署大模型的 首选,毕竟谁不爱努力工作的小羊驼呢。

Ollama的官网地址是https://ollama.com/ ,不需要魔法就能访问,下载速度也是一流,进入官网点击Download就能完成下载与安装,如下图所示。

Ollama安装完成后,此时本地默认是没有大模型的,我们需要下载相关的大模型,Ollama支持的大模型可以在官网左上角的Models里进行查询,如下图所示。

我们找到DeepSeek-R1模型,并选择8B的参数量,如下图所示。

这里除了671B参数量的模型,其它模型都是基于DeepSeek-R1蒸馏出来的小模型,模型性能在基准测试中也是十分出色,大家可以根据自己电脑显卡的显存来决定使用哪种参数量的模型。
选定好模型后,需要打开对应操作系统的终端,并执行如下指令使用Ollama运行对应模型。
shellollama run deepseek-r1:8b
如果是第一次执行,Ollama会帮助我们先下载对应模型再运行,所以第一次下载的时候需要先等待模型下载好,这里有一点需要注意,Windows操作系统下,模型默认是下载到C盘,需要注意一下C盘的剩余空间。
模型下载完毕后,就可以开始聊天了,如下图所示。

Ollama将模型加载到内存中后默认会保持5分钟,我们可以使用如下命令立即将模型从内存中卸载。
shellollama stop deepseek-r1:8b
关于Ollama的FAQ可以见https://github.com/ollama/ollama/blob/main/docs/faq.md#faq,基本会遇到的问题都可以找得到解决答案。
最后Ollama是监听在本地的11434端口上,相应的API也是通过该端口暴露出来的,后续可以基于SpringAI等框架可以方便的调用Ollama的接口来实现自己的大模型应用,到这里是不是发现Ollama真的就是大模型新手的福音,那么赶紧去给Ollama加个星吧,这小羊驼现在看着真是眉清目秀的。

二. 基于AnythingLLM实现RAG
基于Ollama在本地将DeepSeek-R1跑起来之后,我们此时已经具备了通过本地11434端口来调用大模型接口的能力,也就已经具备实现RAG的条件,当然前面也提到了,在大模型框架如此成熟的当下,轮子必然不需要重复制造,我们只需要提供想法和场景,然后合理的将大模型能力 缝合 进我们的应用,就大功告成了。
这里实现RAG的轮子我们选择AnythingLLM,在开始实践之前,首先了解一下什么是RAG。
RAG(Retrieval Augmented Generation) 叫做 检索增强生成,都知道向大模型提问时,其实我们的问题是作为Prompt提示词给到大模型,那么简单理解RAG的话就是基于我们的提问,去提前准备好的数据库里搜索相关的信息,将得到的信息注入进我们的提问生成更完备的Prompt给到大模型,那么大模型在推理时,我们在数据库里搜索到的信息就作为辅助信息帮助大模型完成推理,从而让大模型给出更准确的答案。
如下是RAG的通用架构图,结合RAG的通用架构图,一眼就能理解RAG了。
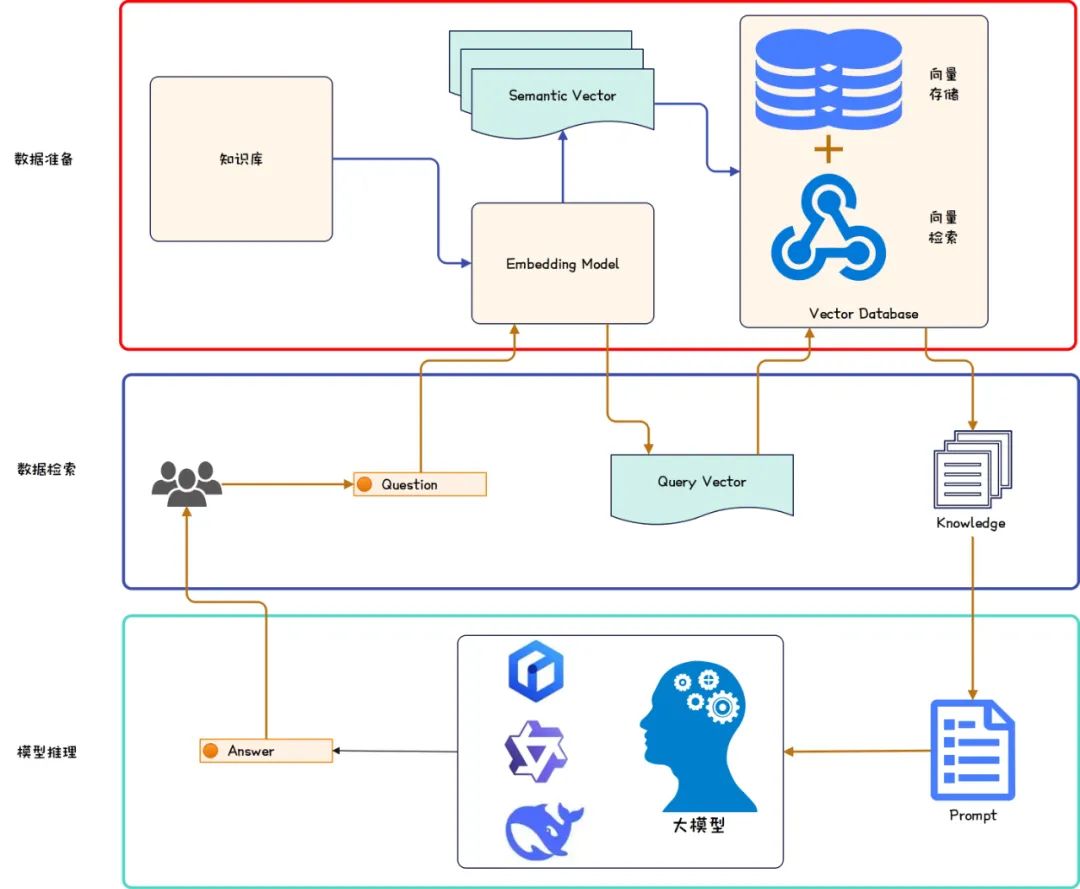
数据准备 阶段。
- 知识库通过**Embedding Model**完成向量化。选择例如ChatGPT-Embedding或M3E等Embedding模型完成将知识库(*文本数据*)转变为语义向量;
- 将向量化后的数据存储到向量数据库。选择例如Pinecone或LanceDB等向量数据库完成对语义向量的存储,从而构建起了我们的向量知识库。
数据检索 阶段。
- 提问信息通过**Embedding Model**完成向量化。使用选定的Embedding模型将提问信息转变为查询向量;
- 基于一种或多种检索方式在向量数据库中检索与提问信息相关的信息。
模型推理 阶段。
- 将检索得到的信息注入提问信息合并得到Prompt。此时Prompt至少包含背景信息(向量数据库中检索得到的信息)和提问信息,此时大模型的推理会结合背景信息给出更加符合预期的回答。
上述就是对RAG的一个概念的简单介绍,不用想都知道自己去实现一个RAG框架肯定是少不了折腾的,好在现在有现成的框架可以使用,就是下面即将登场的AnythingLLM,简单说来AnythingLLM就是一个可以在本地创建AI知识库以及打造属于自己的Agent的All-In-One的AI应用程序。
The all-in-one AI application. Any LLM, any document, any agent, fully private.
AnythingLLM支持的能力可以见https://docs.anythingllm.com/features/all-features,是绝对新手向友好的AI应用程序,强烈建议大家下载来体验一下。
使用AnythingLLM构建RAG应用,只需要选定使用的大模型并上传知识库就行了,下面我们就一起来实现下。
- 下载并安装AnythingLLM。
注意选择下载桌面版,相较于Ollama,AnythingLLM的下载速度会更慢,并且在安装的时候会安装向量数据库等,所以下载加安装的时间是以小时为单位的。
安装完成后首次打开有引导界面,随便选即可,后续可以在设置中重新选择。
- 配置大模型和向量数据库。
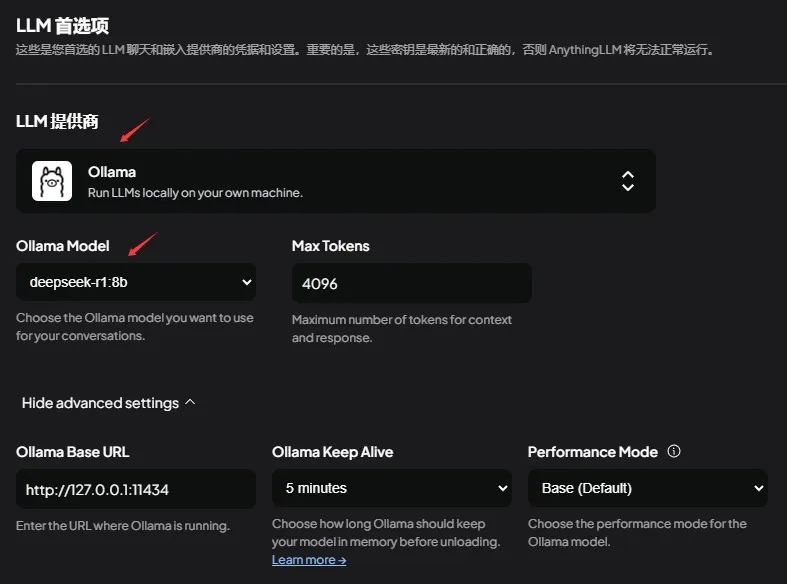
打开进入AnythingLLM后,在界面左下角打开设置。

在【人工智能提供商-LLM首选项】中配置大模型为基于Ollama本地部署的DeepSeek-R1模型。
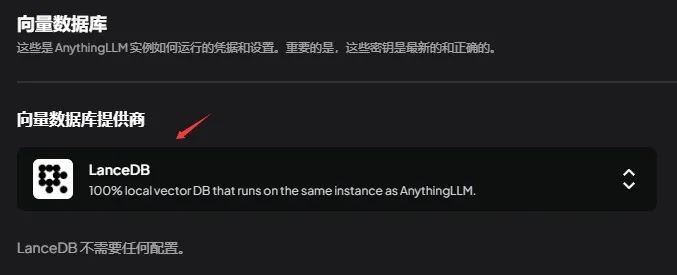
在【人工智能提供商-向量数据库】中将向量数据库配置为LanceDB。
- 创建Workspace。
点击【新工作区】创建一个Workspace。

这个Workspace就是我们配置知识库的一个最小单元,并且我们可以单独针对Workspace配置大模型和向量数据库,默认情况下使用全局配置,也就是我们在【人工智能提供商-LLM首选项】和【人工智能提供商-向量数据库】中配置的大模型和向量数据库,因为全局配置我们已经配置好了,所以这里就不再单独针对Workspace做配置了。
- 创建一个Thread开启聊天。
开始聊天之前需要先创建一个Thread。
default是默认Thread,这里演示聊天就使用default。
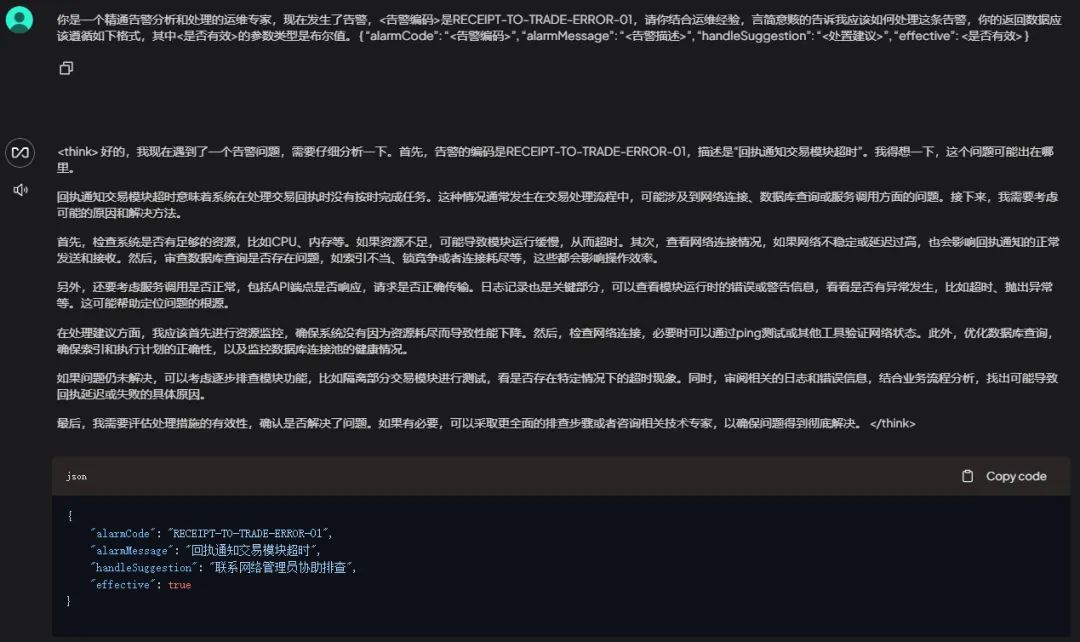
还记得本文要解决的问题的 场景 是什么吗,就是我希望大模型帮助我分析组内的告警信息,假设我一条告警关键数据如下所示。
txt告警编码:RECEIPT-TO-TRADE-ERROR-01
告警描述:回执通知交易模块超时
集群:交易集群
发生时间:2025-01-30 20:30:00
那么此时我如果直接问大模型告警编码为RECEIPT-TO-TRADE-ERROR-01的告警,大模型肯定会开始自由发挥,例如我使用如下的Prompt。
json你是一个精通告警分析和处理的运维专家,现在发生了告警,<告警编码>是RECEIPT-TO-TRADE-ERROR-01,请你结合运维经验,言简意赅的告诉我应该如何处理这条告警,你的返回数据应该遵循如下格式,其中<是否有效>的参数类型是布尔值。
{
"alarmCode":"<告警编码>",
"alarmMessage":"<告警描述>",
"handleSuggestion":"<处置建议>",
"effective": <是否有效>
}
大模型的回答如下。
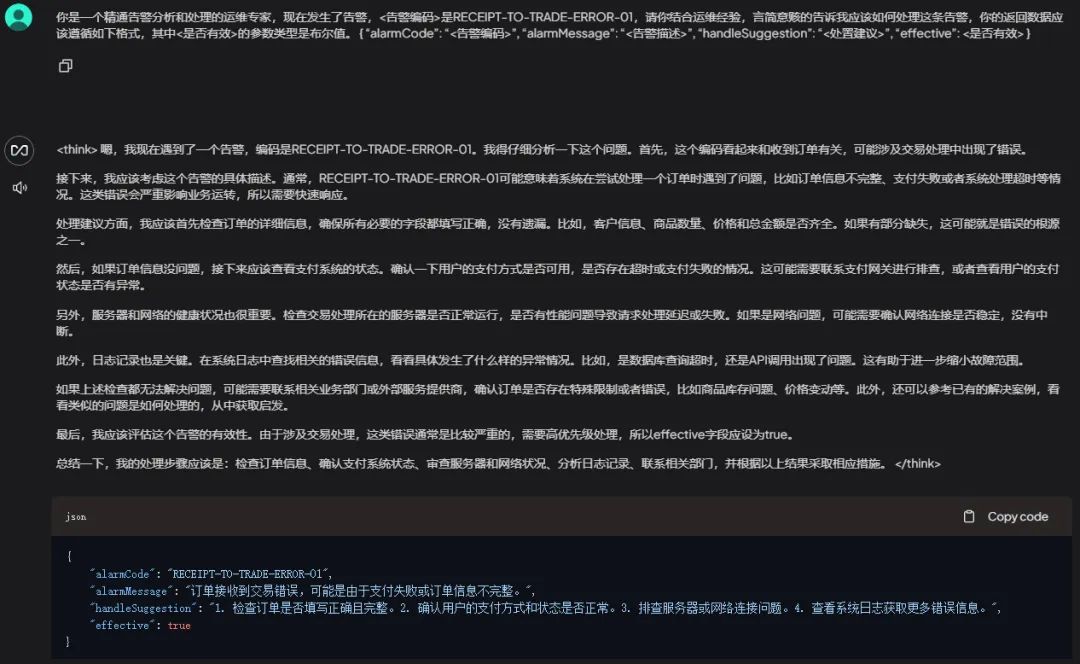
很明显的可以发现强如DeepSeek-R1,也在一本正经的胡说八道,这是因为组内告警这种很 私域化 的信息和场景,基座大模型是不可能有这些训练数据的,无法正确回答也是情理之中,这种时候要么微调,要么使用RAG,我们这里是使用RAG。
- 为Workspace添加知识库。
通常组内每周的值班人员会将发生的告警信息记录在在线文档中,因此为Workspace添加知识库时,只需要将在线文档的网页地址给到AnythingLLM,AnythingLLM会将对应地址的HTML文件向量化并添加到向量数据库中。
知识库的添加除了指定网页地址,还可以通过指定txt文本,csv文件或音频文件等,我们点击Workspace的如下按钮打开添加页面。
添加页面如下所示。

可以上传文件,也可以指定网页地址,成功添加的内容会出现在My Documents栏目中,选中My Documents栏目中的内容,点击Move to Workspace可以将添加的内容加入到当前Workspace中,如下所示。
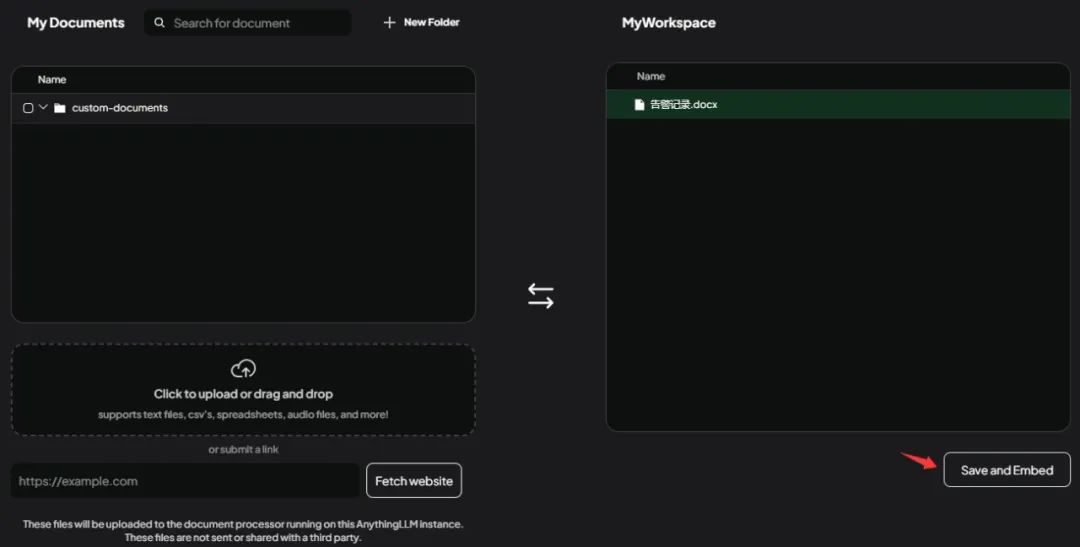
最后点击Save and Embed即可将选中内容向量化。
我添加的docx文件里只有两行内容,如下表所示。
| 告警编码 | 告警描述 | 处置建议 | 是否有效 |
|---|---|---|---|
| RECEIPT-TO-TRADE-ERROR-01 | 回执通知交易模块超时 | 联系网络管理员协助排查 | 有效 |
| RECEIPT-TO-TRADE-ERROR-02 | 回执通知交易模块失败 | 联系交易值班人员协助排查 | 有效 |
此时再使用相同Prompt询问大模型,得到的答案明显靠谱多了。
随着告警信息的越来越丰富,以及我们可以不断调整Prompt做优化,大模型最后给出的告警处置建议会越来越准确。
总结
本地部署DeepSeek-R1依赖大模型管理底座应用Ollama,可以说是只要是Ollama支持的大模型,那都可以一键安装和部署。
而实现RAG可以依赖于AnythingLLM,只需要将配置大模型和配置向量数据库两步,就能实现RAG。
AI生态现在已经趋于成熟,各种层次的人都能在AI趋势下创造自己的价值,相信在不久的未来,掌握如何使用AI和应用AI,就像研发要掌握数据库和消息中间件一样,是一个基本要求了。
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
那么应该如何学习大模型
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【
保证100%免费】
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)