Ubuntu 折腾满参数版 DeepSeek-R1 671B
Ollama 是一个开源的容器软件,专为运行大模型而设计。开源免费: Ollama 和支持的模型都是开源的,用户可以自由使用、修改和分发。简单易用: 只需几条命令即可启动和运行,无需复杂配置。模型丰富: 提供一键下载和切换功能,支持多种热门模型。资源占用低: 相比商业 LLM,Ollama 对硬件要求较低,可以在普通笔记本电脑上流畅运行。社区活跃: 拥有庞大且活跃的社区,用户可以轻松获取帮助和分享
0. 简介
关于UCloud(优刻得)旗下的compshare算力共享平台
UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。
Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。
使用下方链接注册可获得20元算力金,免费体验10小时4090云算力,此外还有3090和P40,价格每小时只需要8毛,赠送的算礼金够用一整天。
https://www.compshare.cn/?ytag=GPU_lovelyyoshino_Lcsdn_csdn_display
关于本地部署,大多数人使用的是蒸馏后的 8B/32B/70B 版本,本质是微调后的 Llama 或 Qwen 模型,并不能完全发挥出 DeepSeek R1 的实力。
然而,完整的 671B MoE 模型也可以通过针对性的量化技术压缩体积,从而大幅降低本地部署门槛,乃至在消费级硬件(如单台 Mac Studio)上运行。
那么,如何用 ollama 在本地部署 DeepSeek R1 671B(完整未蒸馏版本)模型呢?一篇在海外热度很高的简明教程即将揭晓。
目前相关镜像已经存入https://www.compshare.cn/images-detail?ImageID=compshareImage-188dr7voc2bu&ImageType=Community中了。此外还有Ollama-DeepSeek-R1-32B和Ollama-DeepSeek-R1-70B可供选择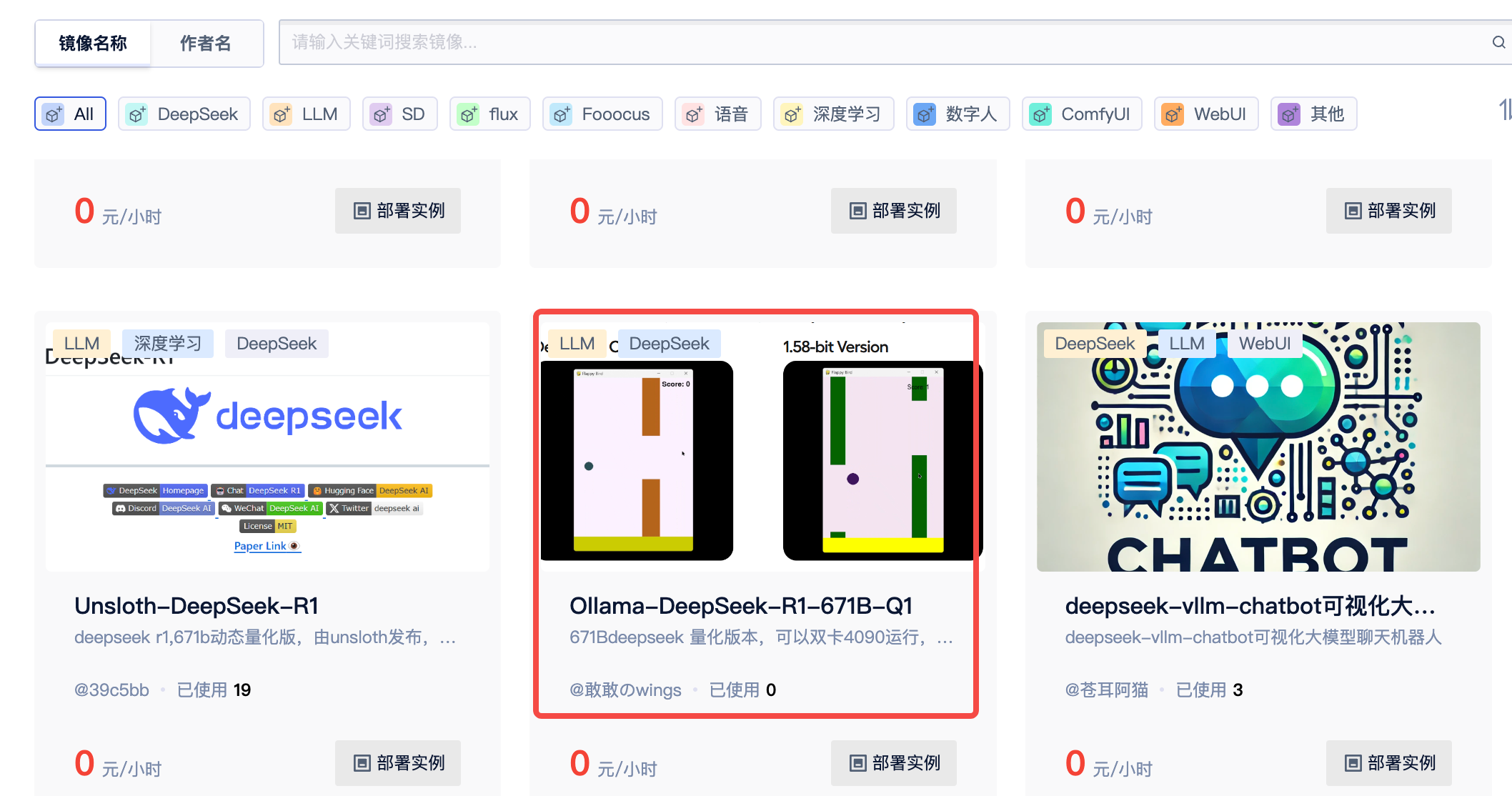
1. 硬件要求
Unsloth AI 官方说明。原版 DeepSeek R1 671B 全量模型的文件体积高达 720GB,对于绝大部分人而言,这都大得太离谱了。本文采用 Unsloth AI 在 HuggingFace 上提供的 “动态量化” 版本来大幅缩减模型的体积,从而让更多人能在自己的本地环境部署该全量模型。
“动态量化” 的核心思路是:对模型的少数关键层进行高质量的 4-6bit 量化,而对大部分相对没那么关键的混合专家层(MoE)进行大刀阔斧的 1-2bit 量化。通过这种方法,DeepSeek R1 全量模型可压缩至最小 131GB(1.58-bit 量化),极大降低了本地部署门槛
DeepSeek-R1-UD-IQ1_M:内存 + 显存 ≥ 200 GB
DeepSeek-R1-Q4_K_M:内存 + 显存 ≥ 500 GB
2. Ollama 简介
Ollama 是一个开源的容器软件,专为运行大模型而设计。它支持多种流行的开源大语言模型(LLM),如 Llama 3、Mistral、Qwen2 等,并且具有以下优势:
- 开源免费: Ollama 和支持的模型都是开源的,用户可以自由使用、修改和分发。
- 简单易用: 只需几条命令即可启动和运行,无需复杂配置。
- 模型丰富: 提供一键下载和切换功能,支持多种热门模型。
- 资源占用低: 相比商业 LLM,Ollama 对硬件要求较低,可以在普通笔记本电脑上流畅运行。
- 社区活跃: 拥有庞大且活跃的社区,用户可以轻松获取帮助和分享经验。
3. 安装 Ollama
首先,我们需要安装 Ollama。可以通过以下命令进行安装:
curl -fsSL https://ollama.com/install.sh | sh
安装完成后,检查服务状态:
apt-get install systemctl
systemctl status ollama

接着,进入 ollama.service 文件进行如下修改:
- 修改端口:允许外部访问。
vim /etc/systemd/system/ollama.service
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
- 更改模型存放位置:指定模型存储路径。
# vim /etc/systemd/system/ollama.service
[Service]
Environment="OLLAMA_MODELS=/model_deepseek/ollama/models"
- 指定运行 GPU:如果有多张 GPU,可以通过
CUDA_VISIBLE_DEVICES配置运行的 GPU。
# vim /etc/systemd/system/ollama.service
Environment="CUDA_VISIBLE_DEVICES=0,1"
Environment="OLLAMA_FLASH_ATTENTION=1" # 启用 Flash Attention
Environment="OLLAMA_KEEP_ALIVE=-1" # 保持模型常驻内存
完成上述设置后,重启 Ollama 服务并查看信息,确保端口设置已生效:
systemctl daemon-reload
systemctl restart ollama

4.下载 gguf 文件
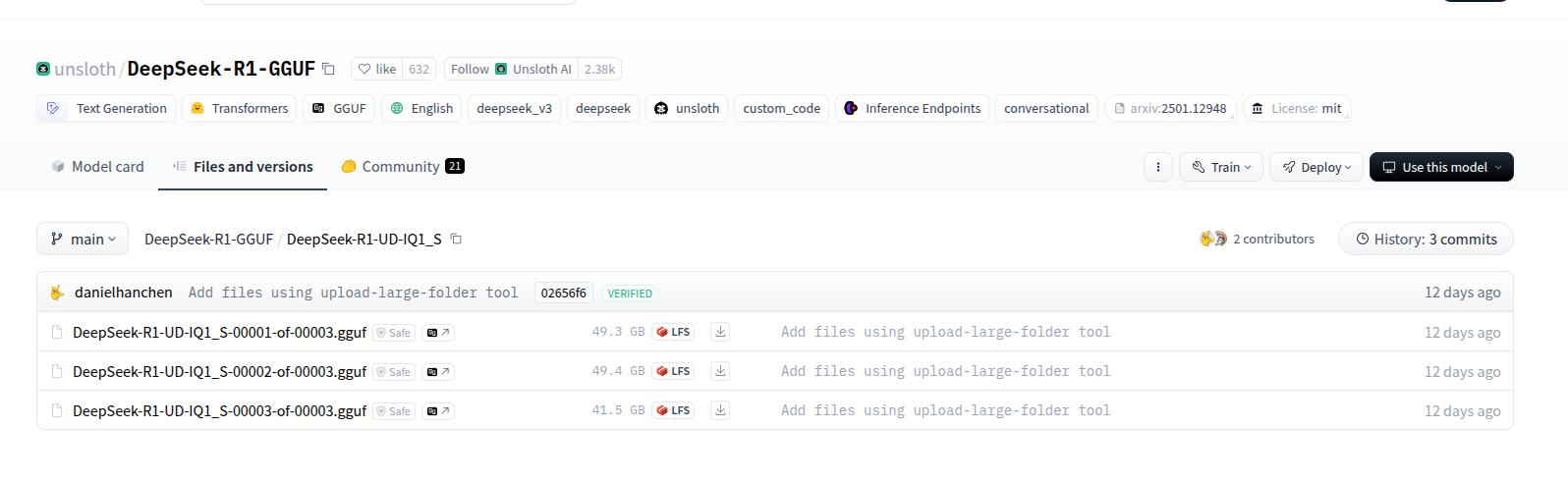
我们要下载剪版的 DeepSeek-R1 671B gguf 文件,由 Unsloth AI 提供,下载地址如下:
https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ1_S
下载可能需要一些时间,建议使用迅雷等工具加速。也可以通过脚本并行下载:
# pip install huggingface_hub hf_transfer
# import os # Optional for faster downloading
# os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # Select quant type UD-IQ1_S for 1.58bit
)
下载完成后,本地会存储为 3 个文件,分别是:
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf

请注意,下载的文件会占用约 131G 的空间,因此建议确保下载盘的空闲空间在 300G 以上。
5. 准备 llama.cpp 并配置环境变量
5.1 安装 llama.cpp
克隆仓库并进入该目录:
git config --global http.postBuffer 52428800
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
确保安装 CUDA 工具包,并验证设置是否正确:
mkdir build
apt-get update
apt-get install make cmake gcc g++ locate
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j4
cd build
make install
5.2 合并 gguf 文件
合并三个 gguf 文件需要用到 llama-gguf-split 工具。可以从 这里 下载。为了方便在命令行中调用,配置全局环境变量:
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/lib/"
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/bin/"
然后使用 llama-gguf-split 验证是否安装成功。
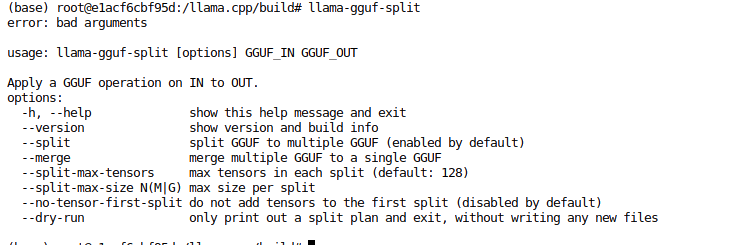
继续进入 gguf 文件所在目录,执行合并命令:
cd /model_deepseek/DeepSeek-R1-GGUF
llama-gguf-split --merge DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf DeepSeek-R1-UD-IQ1.gguf

在结束后删除分开的模型文件:
rm -rf DeepSeek-R1-UD-IQ1_S/
6. 制作 Ollama 配置文件并创建 Ollama 支持的模型格式
将合并完成的 gguf 文件移到指定目录,比如 /model_deepseek/DeepSeek-R1-GGUF,然后创建配置文件 DeepSeek-R1-UD-IQ1_Modelfile,内容如下:
FROM /model_deepseek/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1.gguf
PARAMETER num_gpu 16
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{{ .System }} {{ .Prompt }}<|Assistant|>"
你需要将第一行“FROM”后面的文件路径,改为你在第1步下载并合并的.gguf文件的实际路径。可根据自身硬件情况调整 num_gpu(GPU 加载层数)和 num_ctx(上下文窗口大小)。若提示内存不足或 CUDA 错误,需返回调整参数后,重新创建和运行模型。
下面我们将唤醒Ollama:
ollama serve
基于此文件创建 Ollama 支持的模型格式并导入 Ollama:
ollama create DeepSeek-R1-UD-IQ1 -f DeepSeek-R1-UD-IQ1_Modelfile

创建完成后,可以使用以下命令查看模型列表:
ollama list
接着使用以下命令测试模型:
ollama run DeepSeek-R1-UD-IQ1:latest --verbose

7. 安装 Open WebUI
最后,安装 Open WebUI 以便于与模型进行交互。创建用户名和密码,均设置为 123,邮箱为 pony@123.com:
pip install open-webui
启动 Open WebUI 服务,指定端口和主机:
open-webui serve --port 6080 --host 0.0.0.0
在启动 Open WebUI 后,您需要设置用户名和密码。然后就可以使用了
8. 参考链接

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 30
30 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)