基于ollama的deepseek r1 32b离线模型的本地部署
想利用空余时间进行大模型的离线部署微调与开发的学习,相关经验积累于博客中,与君共勉。
想利用空余时间进行大模型的离线部署微调与开发的学习,相关经验积累于博客中,与君共勉。
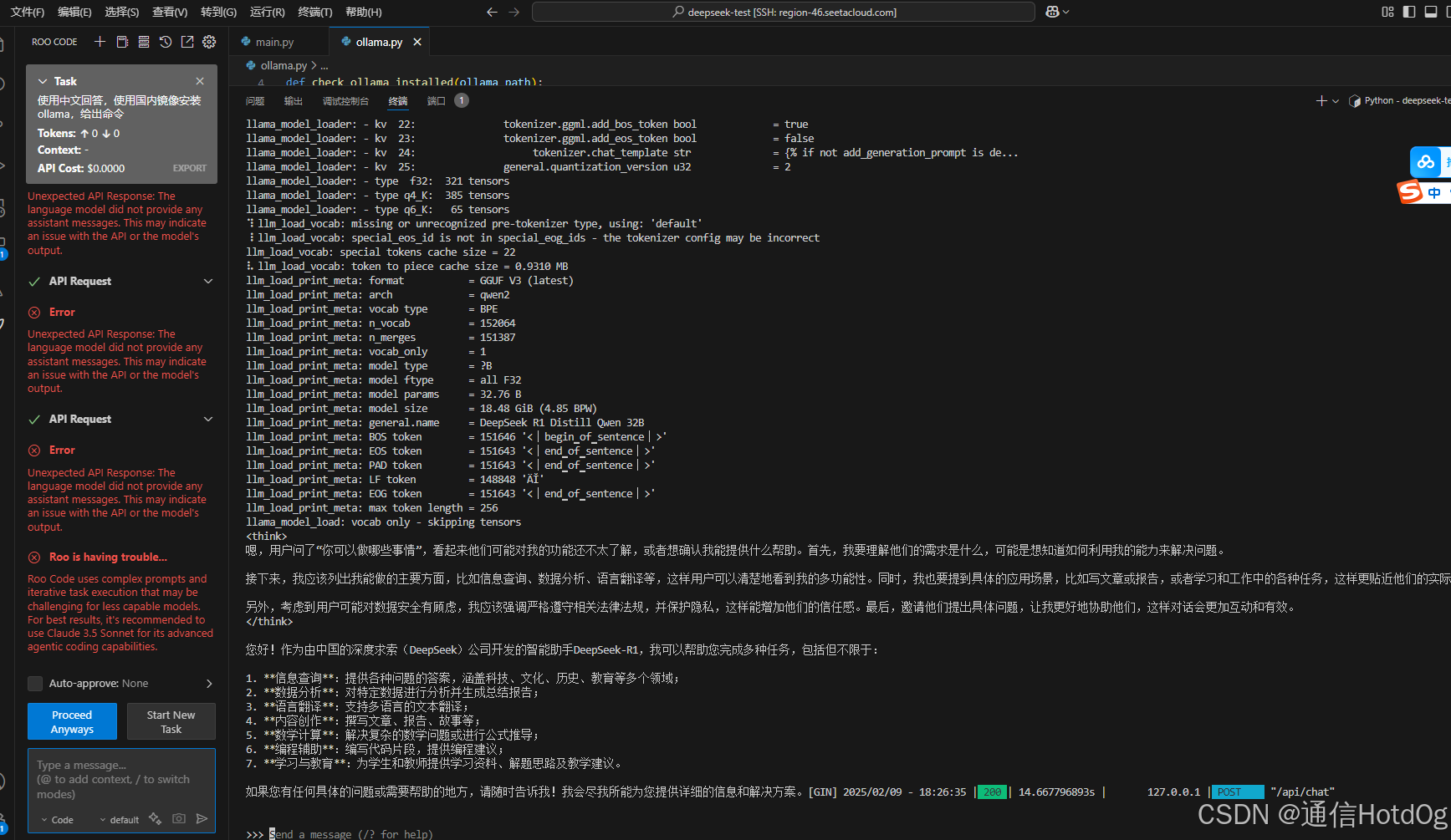
GPU云服务器的选择
市面上的各类云GPU服务器太多,我认为基本上分两类:
一类是用于稳定部署模型进行应用搭建的,腾讯云、阿里云就是这一类。这一类的特点就是:
出售的是运行稳定的ECS云服务器,价格比较昂贵,无论是从硬件成本还是流量成本上,都不咋便宜。但是资料保存的比较好,适合搭建一些应用进行上线。个人认为不适合做微调。
以阿里云为例,和客服沟通,我说我想租用个服务器用来进行大模型微调,他给的建议是算力类型的ECS和GPU类型的ECS,我看了下价格,至少我负担不起。几千一个月,按照小时用量也差不多10+元以上一小时,成本很高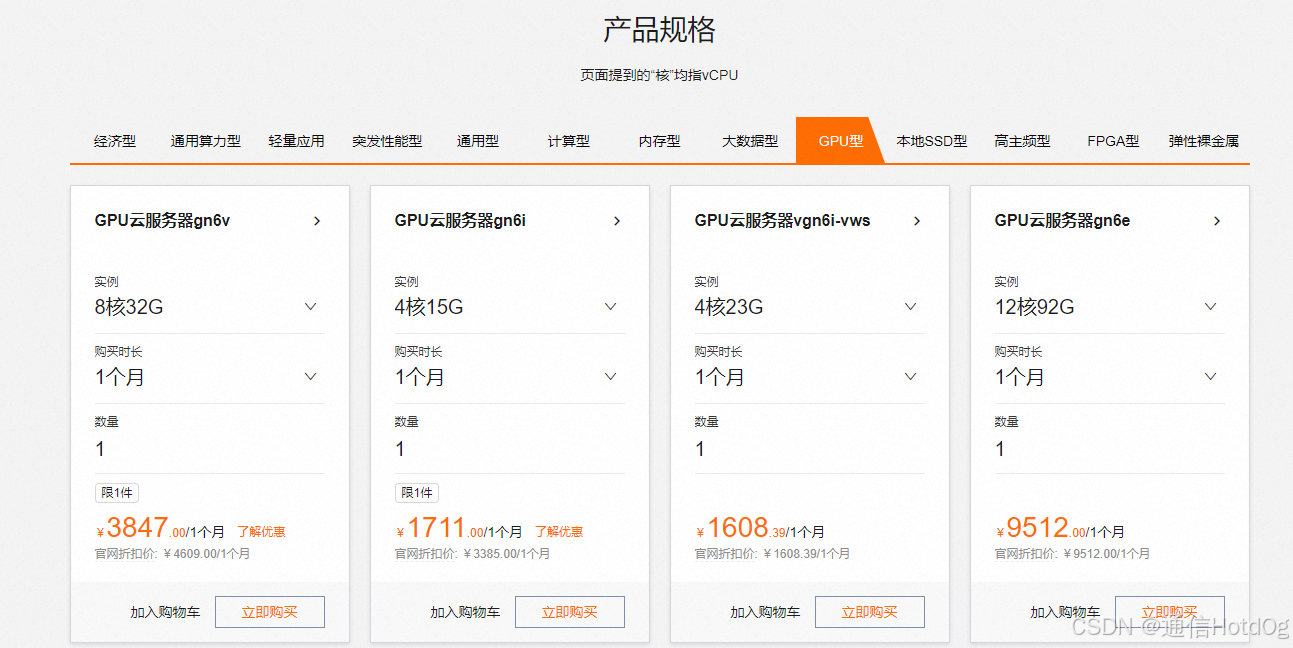
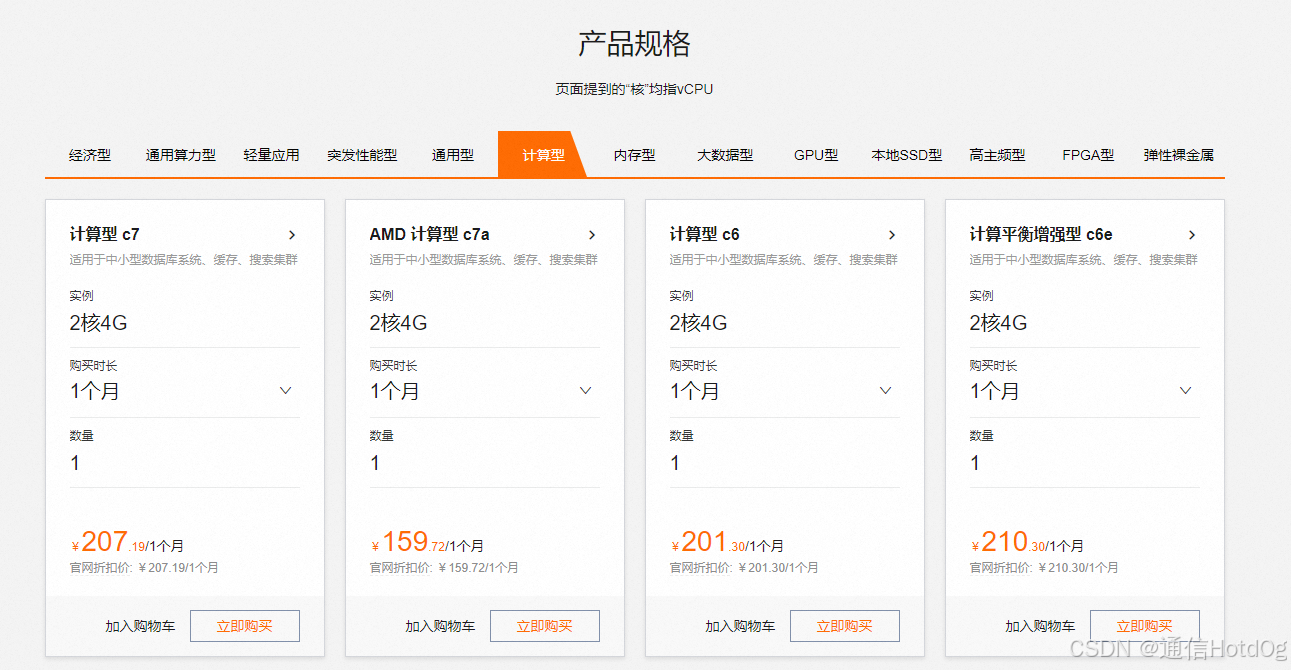
计算型的看起来很便宜,但是其硬件配置个人觉得跑deepseek 7b都费劲。
因此我选择了下面这种类型的GPU租赁方式,也就是另一种关于短时间微调模型的容器。这种配置较高,收费便宜,但是一般都是Linux系统,使用Pycharm或者vscode搭建ssh进行远程操作。
我用的是autodl。价格很便宜,学生党更友好。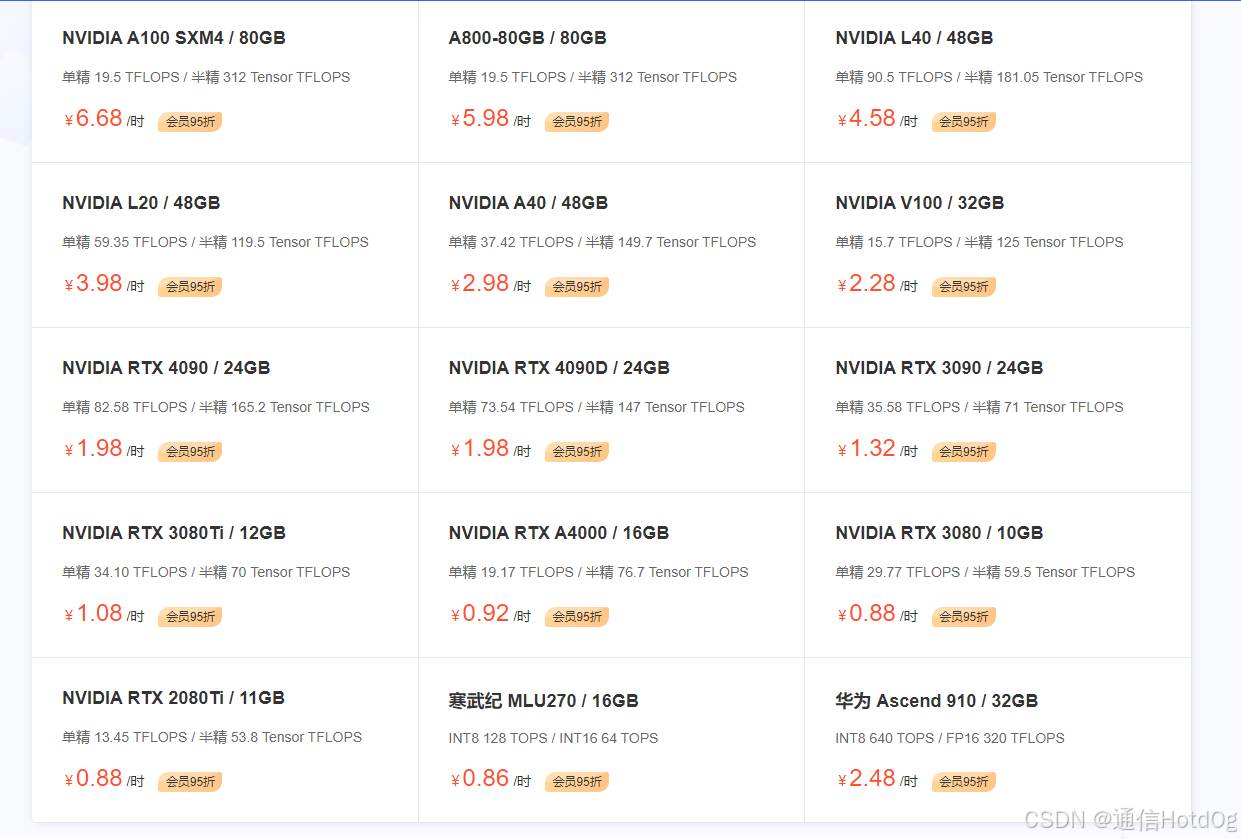
我租了一个V100-32GB * 2卡的机型,不到4元一小时,部署了deepseek r1-32b的模型,非常流畅。
VScode配置ssh
这个配置方法是通用的,我这里不再详细介绍,下面是autodl的配置方法,
https://www.autodl.com/docs/vscode/
总体而言就是下载一个 Remote-ssh插件。
下载OLLAMA
Ollama 是什么?
Ollama 是一个开源的大型语言模型(LLM)运行框架,旨在让用户能够在本地设备上轻松运行和管理各种大语言模型。它简化了在本地计算机上运行、部署和交互大型语言模型的流程,支持多种模型,如 DeepSeek、Mistral、Gemma 等
官网页面:
https://ollama.com/download/linux
下载也很有意思,mac和win的都是直接下载安装包,下载速度很快。
唯独这个linux,是一个命令。我linux开发经验较少,看到很多github项目的Linux下载都是一个命令。不太清楚原因。但是,这个命令下载速度非常慢,而且国内不管是ECS还是容器,反正对于国外网站的支持基本没有.
我在SSH上敲过这个命令,基本上连接不上。我看敲完命令的下载链接是个github,所以尝试了下autodl给的学术资源加速方案,但是直接ban掉了端口。
学术资源加速方案链接:https://www.autodl.com/docs/network_turbo/
找到了一个linux的网络资源,传到云盘上,大家可以下载后上传到容器上。
通过网盘分享的文件:ollama
链接: https://pan.baidu.com/s/1IaQD7L50mp0WnZuvUodhGw?pwd=j64x 提取码: j64x
–来自百度网盘超级会员v7的分享
几个命令记录:
我的ollama安装目录为:/root/autodl-tmp/ollama/bin
(1)将 Ollama 的可执行文件链接到系统路径
sudo ln -sf /root/autodl-tmp/ollama/bin/ollama /usr/local/bin/ollama
(2)确保符号链接已正确创建
ls -l /usr/local/bin/ollama
运行结果:
(3)启动 Ollama 服务
ollama serve &

到了这里ollama已经是启动成功了,接下来需要加载模型了。
下载并启动deepseek 模型
下载模型对应的命令在ollama官网上有,可以自行根据硬件下载对应参数量的模型。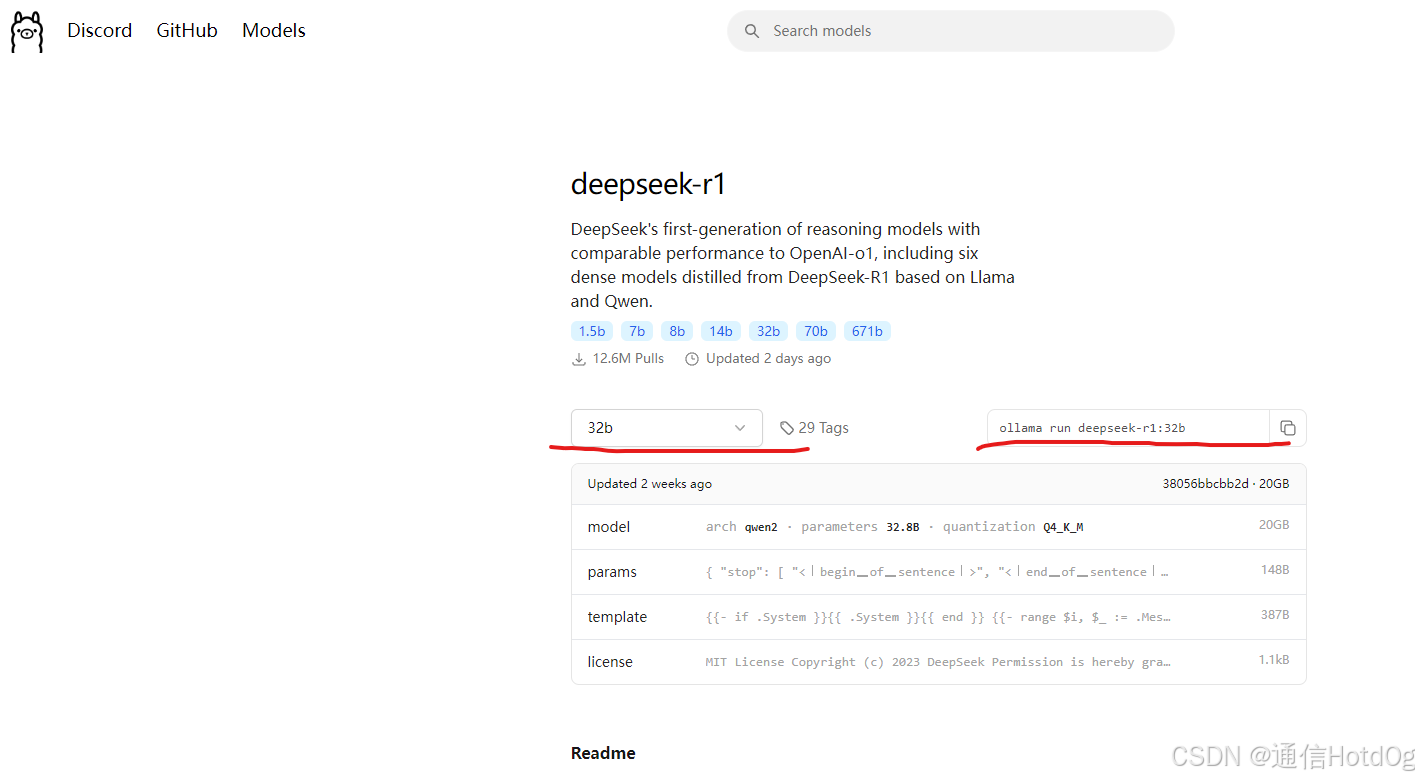
还是因为远程容器下载的太慢了,我是在本地的windows电脑上同步安装了一个ollama,在本地下载模型,然后使用FileZilla上传模型后运行。这种方法可能快一点。
下载模型命令:
ollama pull deepseek-r1:32b
启动模型:
ollama run deepseek-r1:32b
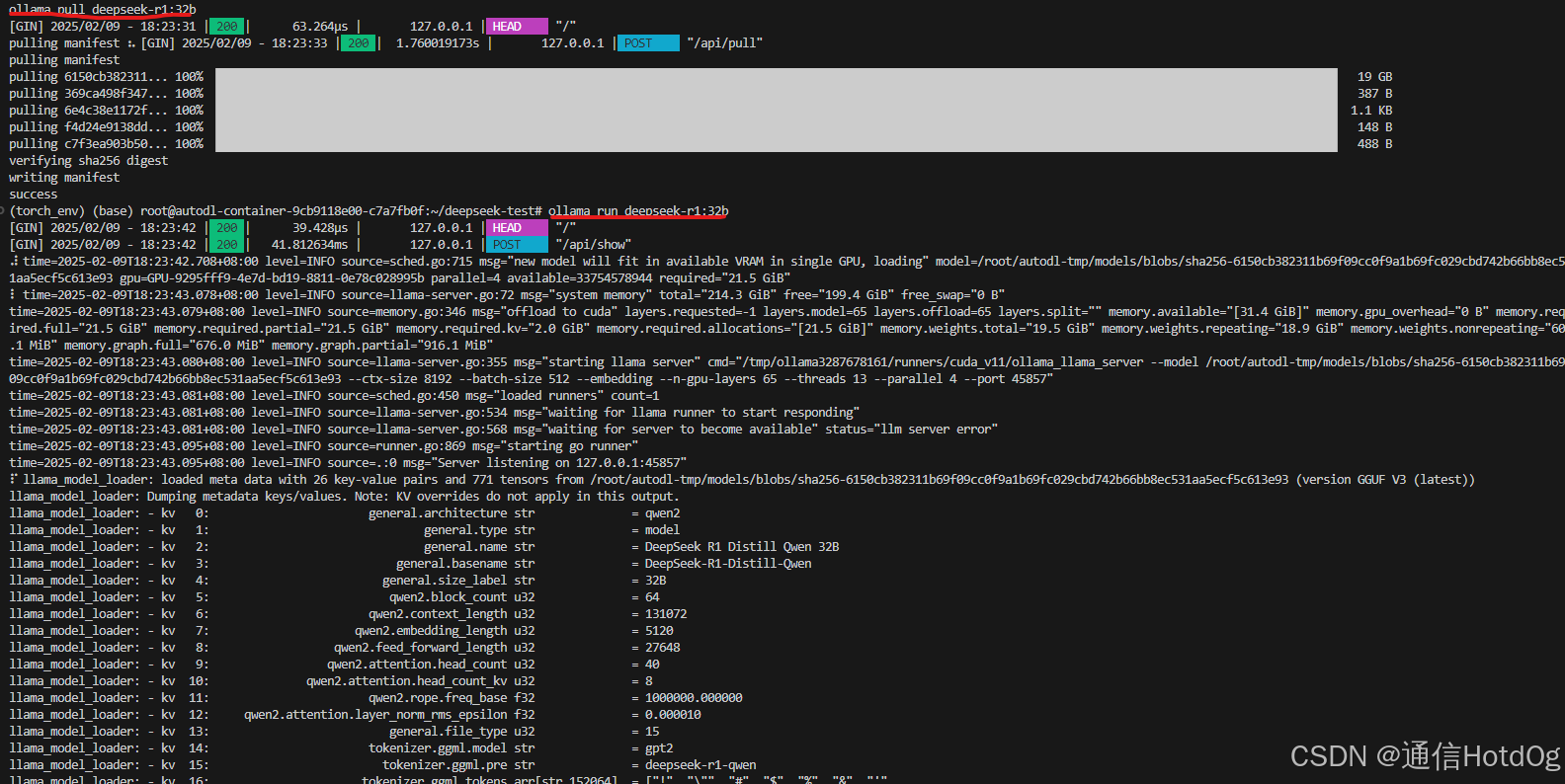
启动大约半分钟后成功。从打印来看,似乎是千问的蒸馏模型。
出现>>>的时候,就可以做问答了。
其中: 与/ 之间的打印是模型的推理过程
下面这个截图是我问了他:你可以做哪些事情。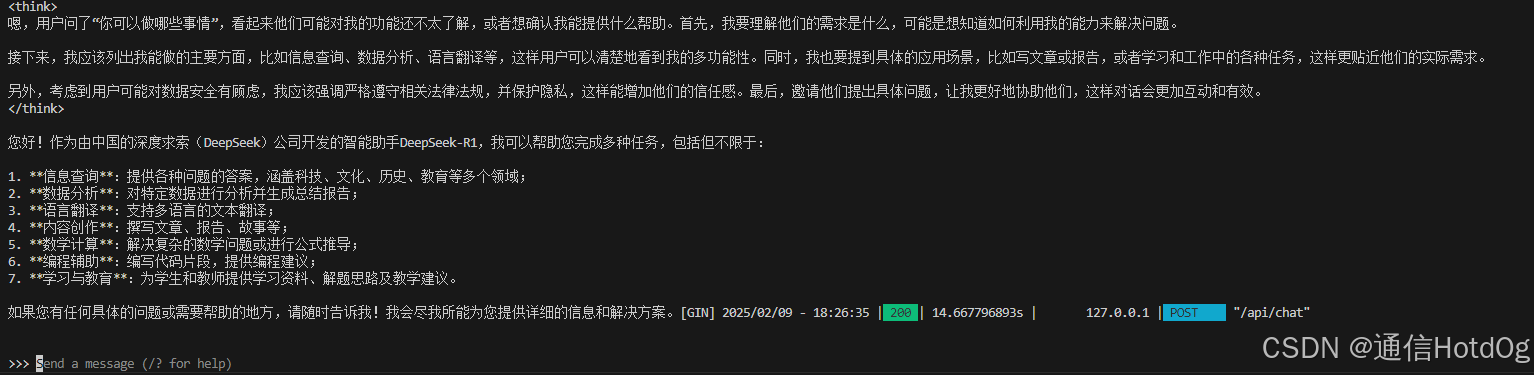
总体而言,运行速率很快,下一步研究如何微调。
退出模型使用Ctrl + d 或者 /bye
碎碎念:
这段时间deepseek被各路人士吹得无所不能,导致目前deepseek无论是api还是网页端,无论是V3还是R1,能否使用基本处于抽奖状态。
之前用过vscode + Roo cline +deepseek组合,感觉比较好用。但是还是不能完全依赖大模型,因为这玩意无论怎么说都有一定概率胡说八道。所以还是要自己分析一下问题,最起码能够准确指出问题之后,再让模型去解决的效率更高,而不是一味问模型比如“现在运行结果不对,请解决” 这种模糊的问题,问死了它也不见得能准确给出解决方案。
Kimi也新出了一个能够推理的模型,这个模型问专业相关的问题感觉还是有很大的问题。有一定概率会推理到鸡生蛋还是蛋生鸡这样的逻辑,但是deepseek目前没出现。个人体验下来deepseek确实是当下最好用的模型。最起码胡说八道的概率以及鸡生蛋蛋生鸡的概率比较低。
通用大模型目前感觉优点也是通用,但是缺点也是通用。可能各行各业最后的归宿就是利用一个基模型做出自己垂直行业的模型,既好用又专业。
后续的研究计划是
1、微调;
2、基于大模型的私人知识库
3、在2的基础上增加数据库,来解决上下文记忆过短,导致部分需要超长线性思维的问题(狗熊掰棒子)。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)