官方文档:deepseek-ai /awesome-deepseek-coder & CPU运行 6.7b / 14b / 33b 测试记录 (****)
官方文档:deepseek-ai /awesome-deepseek-coder & CPU运行 6.7b / 14b / 33b 测试记录 (****)
deepseek-ai /awesome-deepseek-coder awesome-deepseek-coder/README_CN.md at main · deepseek-ai/awesome-deepseek-coder · GitHub
Deepseek-code 才是代码专用的。Deepseek-R1虽好,但编程请慎用! Deepseek-R1虽好,但编程请慎用!_哔哩哔哩_bilibili
*** DeepSeek R1 推理模型 一键包答疑 DeepSeek R1 推理模型 一键包答疑2 完全本地部署 保姆级教程 断网运行 无惧隐私威胁 大语言模型推理时调参 3050显卡4G显存本地32B模型跑通_哔哩哔哩_bilibili
DeepSeek R1 推理模型 完全本地部署 保姆级教程 断网运行 无惧隐私威胁 大语言模型推理时调参 CPU GPU 混合推理 32B 轻松本地部署_哔哩哔哩_bilibili 此视频:
- 提到使用虚拟机:速度会慢?很慢吧?( 有开源专们用于加速模型的docker image?)
- 是 CPU 版,没有 GPU?
播放时间 04:35 ?
06:12 处又说本机有 4GB 的 GPU?
12:12 处又说电脑采用 纯 cpu 推理?
ollama : 支持 CPU,或 GPU版部署?是根据 shell 脚本来判断到底安装哪个版本? - 播放时间 15:03 :1.5B 在虚拟机上的运行速度?参数 B 越小,准确率越低:见官网。
----------------------------------------------------------
说明:
可本地部署 的 AI 代码助手:
- tabby:目前只开放出代码补全?
- deepseek-r1 :MIT ,免费,开源。国人制作,中文支持好?
- CodeGeeX4 :免费,不开源 ?
- codellama ,qwen2.5-coder .....免费,不开源
----------------------------------------------------------
关联参考:
DeepSeek-R1本地运行指南 https://blog.csdn.net/ken2232/article/details/145393458
官方文档:deepseek-ai /awesome-deepseek-coder 官方文档:deepseek-ai /awesome-deepseek-coder-CSDN博客
CodeGeeX4: 全能的开源多语言代码生成模型,可本地部署 (*****) https://blog.csdn.net/ken2232/article/details/145378748
=================================
deepseek-ai /awesome-deepseek-coder
awesome-deepseek-coder/README_CN.md at main · deepseek-ai/awesome-deepseek-coder · GitHub
📚 English | [中文]
awesome-deepseek-coder
与 DeepSeek Coder 相关的资源&开源项目的精选列表
快速体验 DeepSeek Coder
👉直达官网内测页面 coder.deepseek.com
deepseek 官方资源
已发布的模型
所有模型均可在 Hugging Face 官方主页(@deepseek_ai)进行下载
🔗huggingface.co/deepseek-ai
| Model Size | Base | Instruct |
|---|---|---|
| 1.3B | deepseek-coder-1.3b-base | deepseek-coder-1.3b-instruct |
| 5.7B | deepseek-coder-5.7bmqa-base | deepseek-coder-5.7bmqa-instruct(coming soon) |
| 6.7B | deepseek-coder-6.7B-base | deepseek-coder-6.7B-instruct |
| 33B | deepseek-coder-33B-base | deepseek-coder-33B-instruct |
------
> https://modelscope.cn/models/limoncc/deepseek-coder-6.7b-instruct-gguf
- huggingface.co 被墙,直接到 魔搭社区 下载?
- Instruct 模型:是一种通过监督微调或强化学习等方式训练而成的模型。选择 base 模型,一般还需要自己调矫,麻烦,除非必要。
- -?B:一般参数越大越好。但是,需要的内存也会增多,运算量增增加,所以需要根据自己电脑的性能,来选择参数 B 值。如果是采用 GPU 显存的话,比校贵,或采用算力租赁。
- 本地部署的原因,代码保密的需要。否则,如果是开源软件,则直接采用官网的好了,好像 B参数是大于 600B ?
如果将这种版本私有化部署,那么,一般公司恐怕是用不起的,某视频说,采用好多块 GPU 卡,好像1天要 1000RMB 左右的算力租赁?准确率高,但烧钱。
------
API 开放平台
轻松接入,让DeepSeek成为你高效的AI助手
🔗platform.deepseek.com
社区生态资源
基于 DeepSeek Coder 训练的模型
量化模型
- TheBloke - TheBloke 为 Deepseek Coder 1B/7B/33B 模型开发 AWQ/GGUF/GPTQ 格式模型文件
------------
- 不量化版本,准确率最高。但需要的内存最多,硬件成本贵。
- ollaman GGUF 默认采用 Q4 量化?
Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
|---|---|---|---|
| DeepSeek-Coder-V2-Lite-Instruct-Q8_0_L.gguf | Q8_0_L | 17.09GB | Experimental, uses f16 for embed and output weights. Please provide any feedback of differences. Extremely high quality, generally unneeded but max available quant. |
| DeepSeek-Coder-V2-Lite-Instruct-Q8_0.gguf | Q8_0 | 16.70GB | Extremely high quality, generally unneeded but max available quant. |
| DeepSeek-Coder-V2-Lite-Instruct-Q6_K_L.gguf | Q6_K_L | 14.56GB | Experimental, uses f16 for embed and output weights. Please provide any feedback of differences. Very high quality, near perfect, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q6_K.gguf | Q6_K | 14.06GB | Very high quality, near perfect, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q5_K_L.gguf | Q5_K_L | 12.37GB | Experimental, uses f16 for embed and output weights. Please provide any feedback of differences. High quality, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q5_K_M.gguf | Q5_K_M | 11.85GB | High quality, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q5_K_S.gguf | Q5_K_S | 11.14GB | High quality, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q4_K_L.gguf | Q4_K_L | 10.91GB | Experimental, uses f16 for embed and output weights. Please provide any feedback of differences. Good quality, uses about 4.83 bits per weight, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q4_K_M.gguf | Q4_K_M | 10.36GB | Good quality, uses about 4.83 bits per weight, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q4_K_S.gguf | Q4_K_S | 9.53GB | Slightly lower quality with more space savings, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-IQ4_XS.gguf | IQ4_XS | 8.57GB | Decent quality, smaller than Q4_K_S with similar performance, recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-Q3_K_L.gguf | Q3_K_L | 8.45GB | Lower quality but usable, good for low RAM availability. |
| DeepSeek-Coder-V2-Lite-Instruct-Q3_K_M.gguf | Q3_K_M | 8.12GB | Even lower quality. |
| DeepSeek-Coder-V2-Lite-Instruct-IQ3_M.gguf | IQ3_M | 7.55GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| DeepSeek-Coder-V2-Lite-Instruct-Q3_K_S.gguf | Q3_K_S | 7.48GB | Low quality, not recommended. |
| DeepSeek-Coder-V2-Lite-Instruct-IQ3_XS.gguf | IQ3_XS | 7.12GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| DeepSeek-Coder-V2-Lite-Instruct-IQ3_XXS.gguf | IQ3_XXS | 6.96GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| DeepSeek-Coder-V2-Lite-Instruct-Q2_K.gguf | Q2_K | 6.43GB | Very low quality but surprisingly usable. |
| DeepSeek-Coder-V2-Lite-Instruct-IQ2_M.gguf | IQ2_M | 6.32GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| DeepSeek-Coder-V2-Lite-Instruct-IQ2_S.gguf | IQ2_S | 6.00GB | Very low quality, uses SOTA techniques to be usable. |
| DeepSeek-Coder-V2-Lite-Instruct-IQ2_XS.gguf | IQ2_XS | 5.96GB | Very low quality, uses SOTA techniques to be usable. |
------------
Copilot
👉 refact
开源人工智能编码助手,具有极快的代码完成速度、强大的代码改进工具和聊天功能。它支持 deepseek-coder/1.3b/base, deepseek-coder/5.7b/mqa-base, deepseek-coder/6.7b/instruct, deepseek-coder/33b/instruct.
👉 Tabby
开源、自托管的 AI 编码助手,是 GitHub Copilot 的有力替代品。 可以在 Tabby 上深入探索 DeepSeek Coder 强大的代码补全功能✨ (link)。
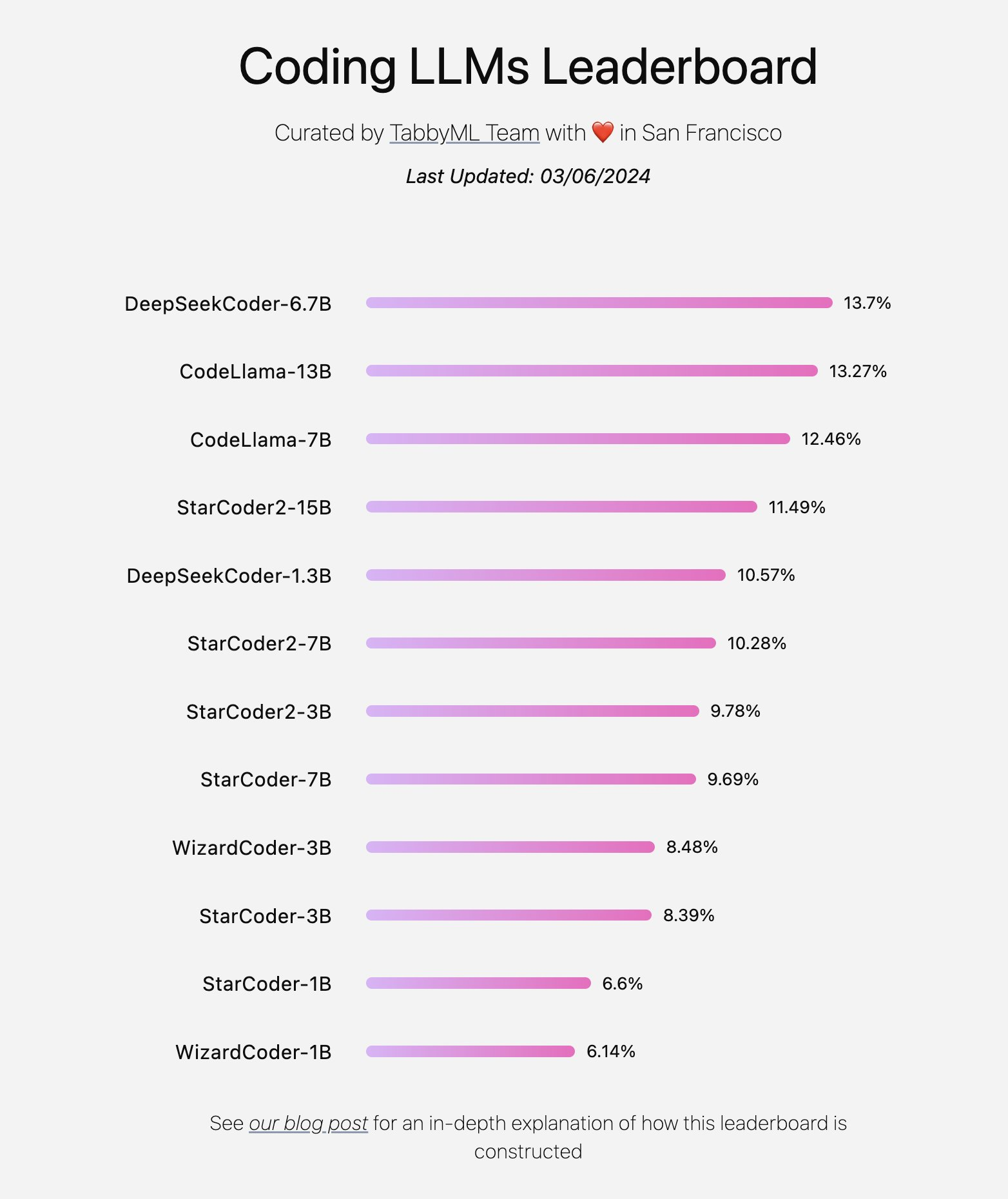
其最新排行榜显示 deepseek-coder-6.7B 在代码完成方面表现最佳 (Coding LLMs Leaderboard).
👉 🧙AutoDev
开源的AI辅助编程工具,可以与Jetbrains系列IDE无缝集成。 它提供 Deepseek Coder 6.7B 微调数据工具Unit Eval, 与 AutoDev 提示相关的 datasets 和 finetuned model, 以及 API server example
APIs
- limcheekin/deepseek-coder-6.7B-instruct-GGUF: limcheekin 为“deepseek-coder-6.7B-instruct-GGUF”模型提供 API
------
refact
![]()
This repo consists Refact WebUI for fine-tuning and self-hosting of code models, that you can later use inside Refact plugins for code completion and chat.
Supported models
| Model | Completion | Chat | Fine-tuning | Deprecated |
|---|---|---|---|---|
| Refact/1.6B | + | + | ||
| starcoder2/3b/base | + | + | ||
| starcoder2/7b/base | + | + | ||
| starcoder2/15b/base | + | + | ||
| deepseek-coder/1.3b/base | + | + | ||
| deepseek-coder/5.7b/mqa-base | + | + | ||
| magicoder/6.7b | + | + | ||
| mistral/7b/instruct-v0.1 | + | + | ||
| mixtral/8x7b/instruct-v0.1 | + | |||
| deepseek-coder/6.7b/instruct | + | + | ||
| deepseek-coder/33b/instruct | + | |||
| stable/3b/code | + | |||
| llama3/8b/instruct | + | + | ||
| llama3.1/8b/instruct | + | + | ||
| llama3.2/1b/instruct | + | + | ||
| llama3.2/3b/instruct | + | + | ||
| qwen2.5/coder/0.5b/base | + | + | ||
| qwen2.5/coder/1.5b/base | + | + | ||
| qwen2.5/coder/3b/base | + | + | ||
| qwen2.5/coder/7b/base | + | + | ||
| qwen2.5/coder/14b/base | + | + | ||
| qwen2.5/coder/32b/base | + | + | ||
| qwen2.5/coder/1.5b/instruct | + | + | ||
| qwen2.5/coder/3b/instruct | + | + | ||
| qwen2.5/coder/7b/instruct | + | + | ||
| qwen2.5/coder/14b/instruct | + | + | ||
| qwen2.5/coder/32b/instruct | + | + |
FAQ
Q: Can I run a model on CPU?
A: it doesn't run on CPU yet, but it's certainly possible to implement this. (以后可能有 cpu 版?什么时候?)
说明:
- 需要足够快的速度时,则要使用 GPU 版。GPU 太贵,而且硬件更新快,自己购买说不定很快就砸在手里了(就是 AI 模型更新了,结果现有的 GPU 不支持了;或者需要运行某些其他的 AI 大模型,结果现有的 GPU 并不支持?)?个人使用,似乎还是直接购买云 GPU 划算?
- 除非需要特别保密的代码。否则,直接使用官方免费的,在 VSCode 中就有许多免费的 AI 代码插件。
- 自己部署,硬件成本高。非 GPU 电脑,可能生成的速度太慢,只能在某些场景里使用;并且,支持 CPU 版本的 AI 大模型,似乎并不多见?
- 当保密代码、只是想做一些验证,或注释时,慢一点也是没有关系的,因此,CPU版似乎也是有价值的?毕竟不是人人都私有 GPU,购买云 GPU 有时也麻烦?
在多人同时使用 CPU 版时,可能运行速度就不可接受了?
============
- awesome-deepseek-coder : 最小 1.3B。5.7B在 8GB内存的电脑上,勉强可运行?官方目前的 Instruct版还在等待中。。
- DeepSeek-Coder-V2 : 最小 16B
deepseek-ai / DeepSeek-Coder-V2
2. Model Downloads
We release the DeepSeek-Coder-V2 with 16B and 236B parameters based on the DeepSeekMoE framework, which has actived parameters of only 2.4B and 21B , including base and instruct models, to the public.
| Model | #Total Params | #Active Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Base | 236B | 21B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 128k | 🤗 HuggingFace |
deepseek-ai / awesome-deepseek-coder awesome-deepseek-coder/README_CN.md at main · deepseek-ai/awesome-deepseek-coder · GitHub
已发布的模型
所有模型均可在 Hugging Face 官方主页(@deepseek_ai)进行下载
🔗huggingface.co/deepseek-ai
| Model Size | Base | Instruct |
|---|---|---|
| 1.3B | deepseek-coder-1.3b-base | deepseek-coder-1.3b-instruct |
| 5.7B | deepseek-coder-5.7bmqa-base | deepseek-coder-5.7bmqa-instruct(coming soon) |
| 6.7B | deepseek-coder-6.7B-base | deepseek-coder-6.7B-instruct |
| 33B | deepseek-coder-33B-base | deepseek-coder-33B-instruct |
田ji赛马:一个模型,同时给出多种不同的量化版本。
美方刚要封杀DeepSeek,一个更大噩耗传来,白宫:这下真的完了!_哔哩哔哩_bilibili

07:50 一条视频搞清楚DeepSeek为什么这么火?【含本地部署】_哔哩哔哩_bilibili


ollama cpu 运行 deepseek-coder:6.7b / 14b / 33b 测试记录
https://blog.csdn.net/ken2232/article/details/145410479
# 测试环境
- 8GB内存,双核,云 VPS
- Ubuntu 22.04 x64 服务器版,没有安装桌面,及其他非测试软件vps。
# 结果:
- 6.7b:可运行,但速度慢。
- 14b:可运行,10分钟才蹦出一个单词。终止了测试。
- 33b:无法安装,Error: model requires more system memory (17.6 GiB) than is available (11.7 GiB) << 也许将磁盘的虚拟内存调大,就可以安装了吧?但由于速度问题,已经没有价值了。
结论:
- 在 ollama 下,采用 cpu 运行大模型,理论上,如果模型支持的话?采用任何一种参数 B值都可以运行?但可能会由于运算速度太慢,而失去价值。
- 采用 8GB 内存的 cpu 来运行大模型,7B 可能很勉强,毕竟还要运行图形桌面,以及其他的 gui app。也许 6B 以下的大模型合适?这需要考虑在电脑上同时运行的其他软件所扣除的内存了?
- 采用大 B参数,即使可以运行。但是,速度问题,在浪费时间,除非在不考虑速度的特别场景力。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)