排名 Top 5 的 DeepSeek 相关开源项目?
之前提到过,DeepSeek 发布的 R1 模型凭借低成本、高性能推理能力引发全球 AI 社区震动。在 GitHub 搜索 DeepSeek 关键词,除了深度求索官方的开源仓库外。我整理了排序最靠前的 5 个开源项目。01DeepSeek 复现狂潮DeepSeek 的核心思路是通过强化学习优化小模型性能,被多个开源项目成功复现。包括这三个代表性项目:Hugging Face的 Open-R1、港科

之前提到过,DeepSeek 发布的 R1 模型凭借低成本、高性能推理能力引发全球 AI 社区震动。
在 GitHub 搜索 DeepSeek 关键词,除了深度求索官方的开源仓库外。我整理了排序最靠前的 5 个开源项目。
01
DeepSeek 复现狂潮
DeepSeek 的核心思路是通过强化学习优化小模型性能,被多个开源项目成功复现。包括这三个代表性项目:Hugging Face的 Open-R1、港科大的 simpleRL-reason 与伯克利团队的 TinyZero。
① Hugging Face 的 Open-R1
HuggingFace 的 CEO 在 X 上宣布,要开源复现 DeepSeek-R1 模型过程中的所有内容,包括训练数据、脚本等。目前复现的开源项目 open-r1 已经获得了 17.2k 的 Star。
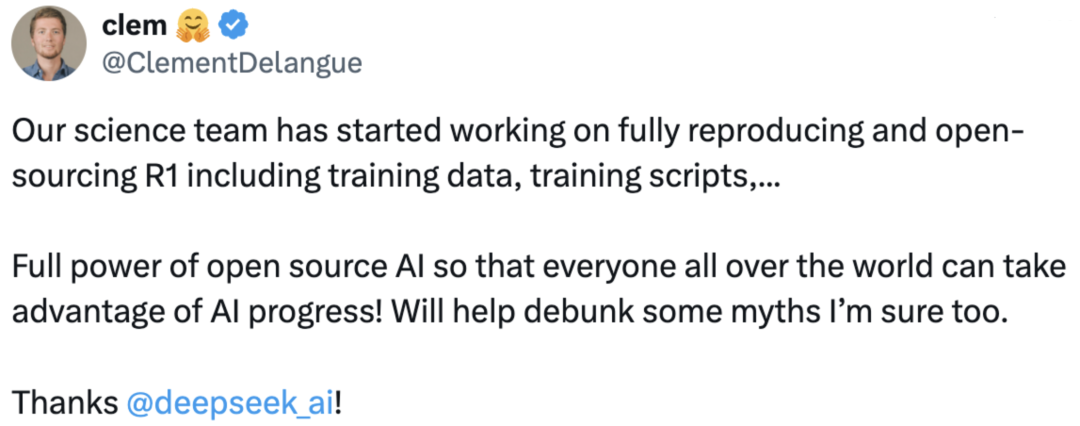
项目地址:https://github.com/huggingface/open-r1作为最受关注的复现项目,Open-R1 旨在完整复刻 DeepSeek-R1 的技术路径,并补齐未公开的细节。其计划分三阶段:
-
蒸馏高质量推理数据集:从 R1 提取知识,构建通用语料库。
-
验证 GRPO 算法:通过纯强化学习训练模型,无需监督微调(SFT)。
-
完整多阶段训练流程:基础模型、监督微调、强化学习多阶段
尝试跨领域迁移,将框架扩展至代码生成(优化代码结构)和医学诊断(症状推理链构建),验证推理能力的通用性。
② 港科大 simpleRL-reason
这是 DeepSeek-R1-Zero 和 DeepSeek-R1 在数据有限的小模型上进行训练的复制品。目前已经获得 2.2k 的 Star!
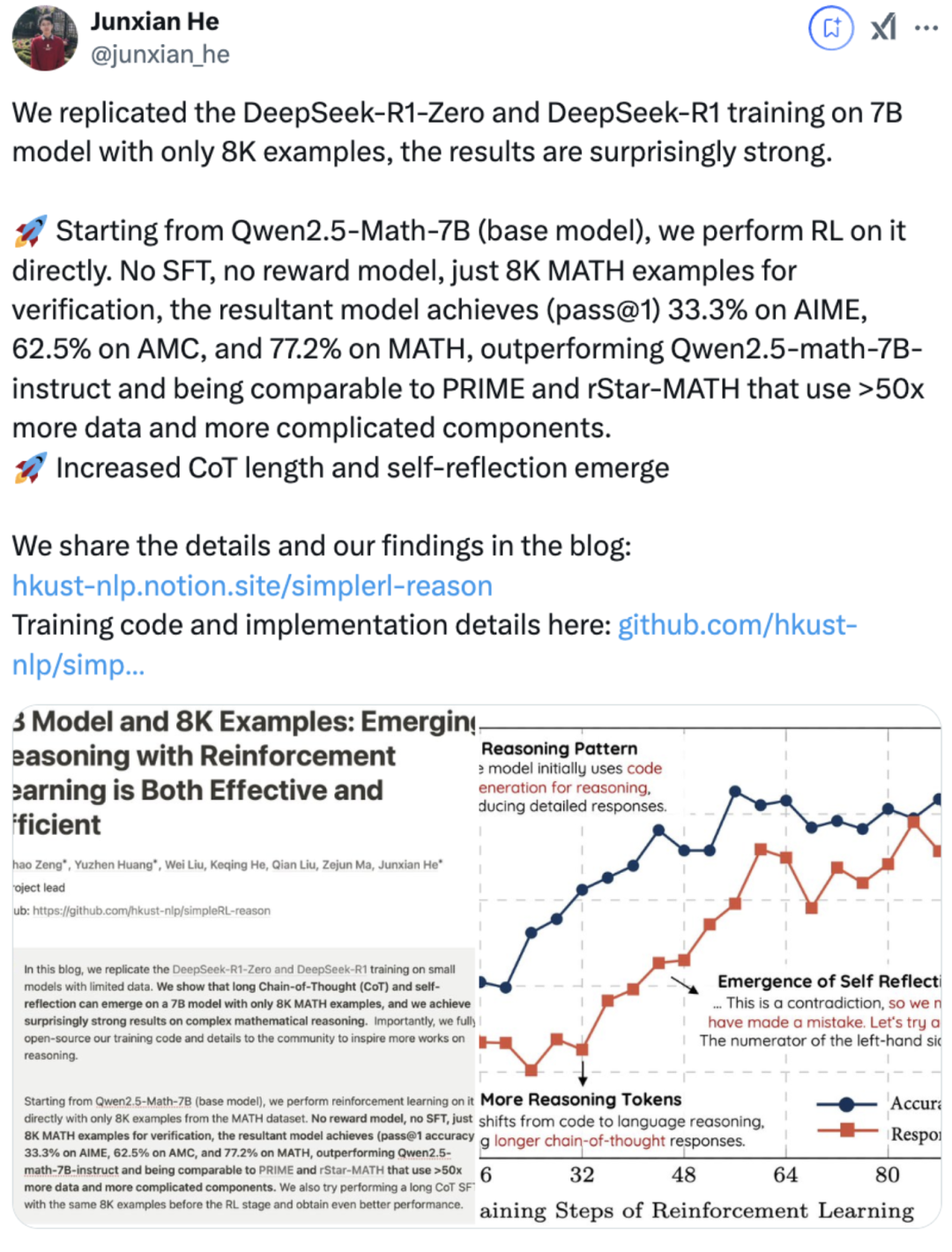
项目地址:https://github.com/hkust-nlp/simpleRL-reason港科大团队用 7B 参数的 Qwen2.5-Math 模型和仅 8000 个数学样本,验证了 R1 方法的有效性。其采用两种训练策略:
-
SimpleRL-Zero:直接对基础模型应用PPO强化学习。
-
SimpleRL:先通过监督微调冷启动,再结合强化学习。
③ TinyZero
伯克利团队以倒计时游戏为测试场景,用不到 30 美元成本复现了 R1-Zero。目前已经获得了 8.9K 的 Star。
项目地址:https://github.com/Jiayi-Pan/TinyZero实验发现:
-
参数规模决定能力:0.5B模型仅会猜测,而1.5B模型已能执行搜索、自我验证与修正。
-
任务决定行为模式:在倒计时任务中,模型倾向搜索;在数值乘法中,则分解问题(如利用分配律)。
-
算法无关性:PPO、GRPO、PRIME 等不同强化学习算法均能激发长链思维,且指令微调非必需。
该项目验证了低成本复现R1的可行性,为资源有限的开发者提供了实践范本。
02
DeepSeek iOS 客户端高仿版
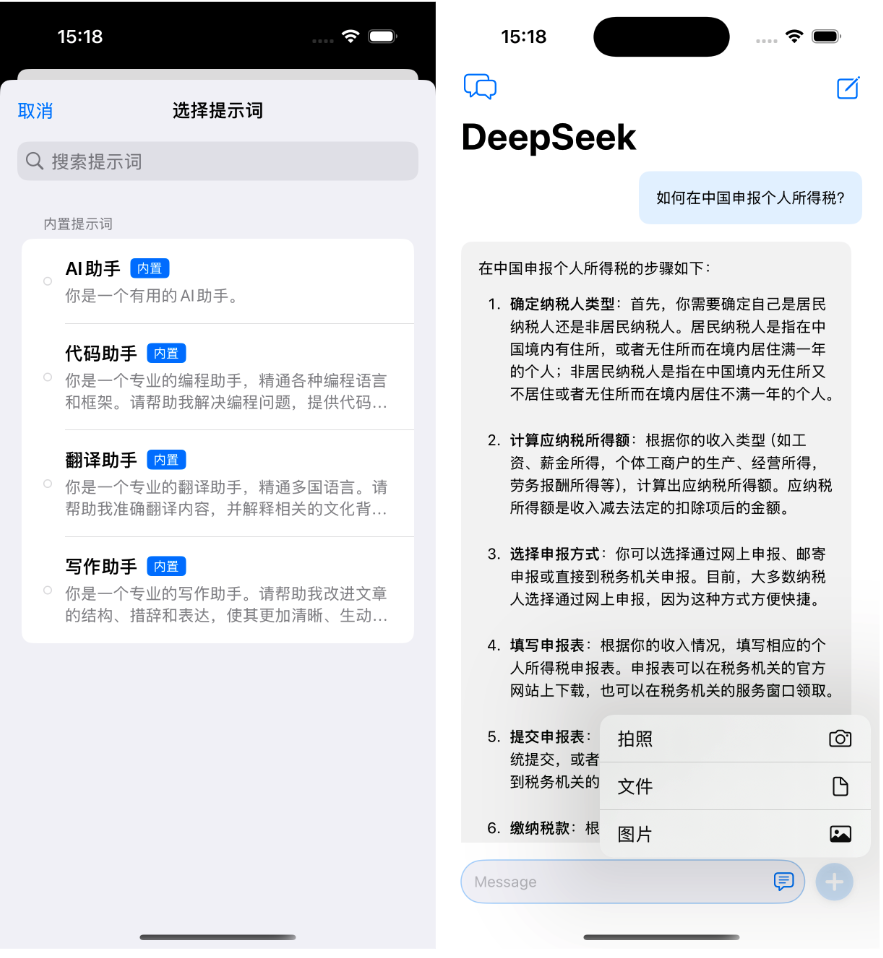
基于 SwiftUI 开发的 DeepSeek API 移动端 AI 应用。通过 DeepSeek 强大的大语言模型能力, 为用户提供流畅的 AI 对话体验。
支持实时对话、多轮交互、历史记录管理、自定义提示词等功能,让您随时随地享受智能对话服务。
开源地址:https://github.com/DargonLee/DeepSeek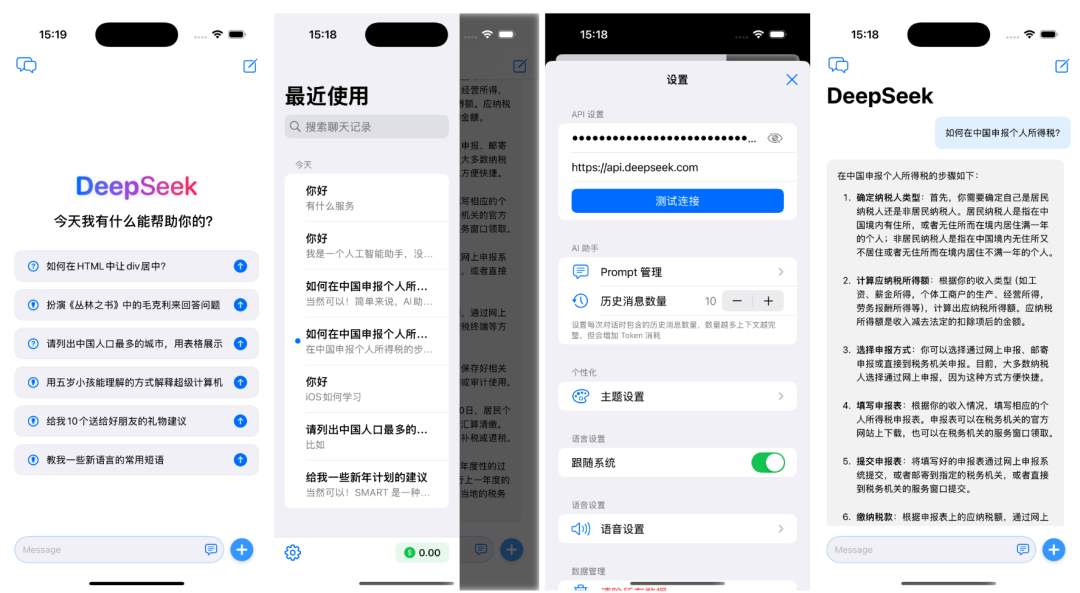
03
gpt4free:免费调用多款顶尖大模型
国外一位大神 xtekky 最近开源的,目前已经获得了 63.4k 的 Star!支持 DeepSeek V3/R1等主流大模型,用户无需支付 API 费用即可体验。
GitHub地址:https://github.com/xtekky/gpt4free
04
点击下方卡片关注我
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接和逛逛 GitHub 对话聊天就行了:
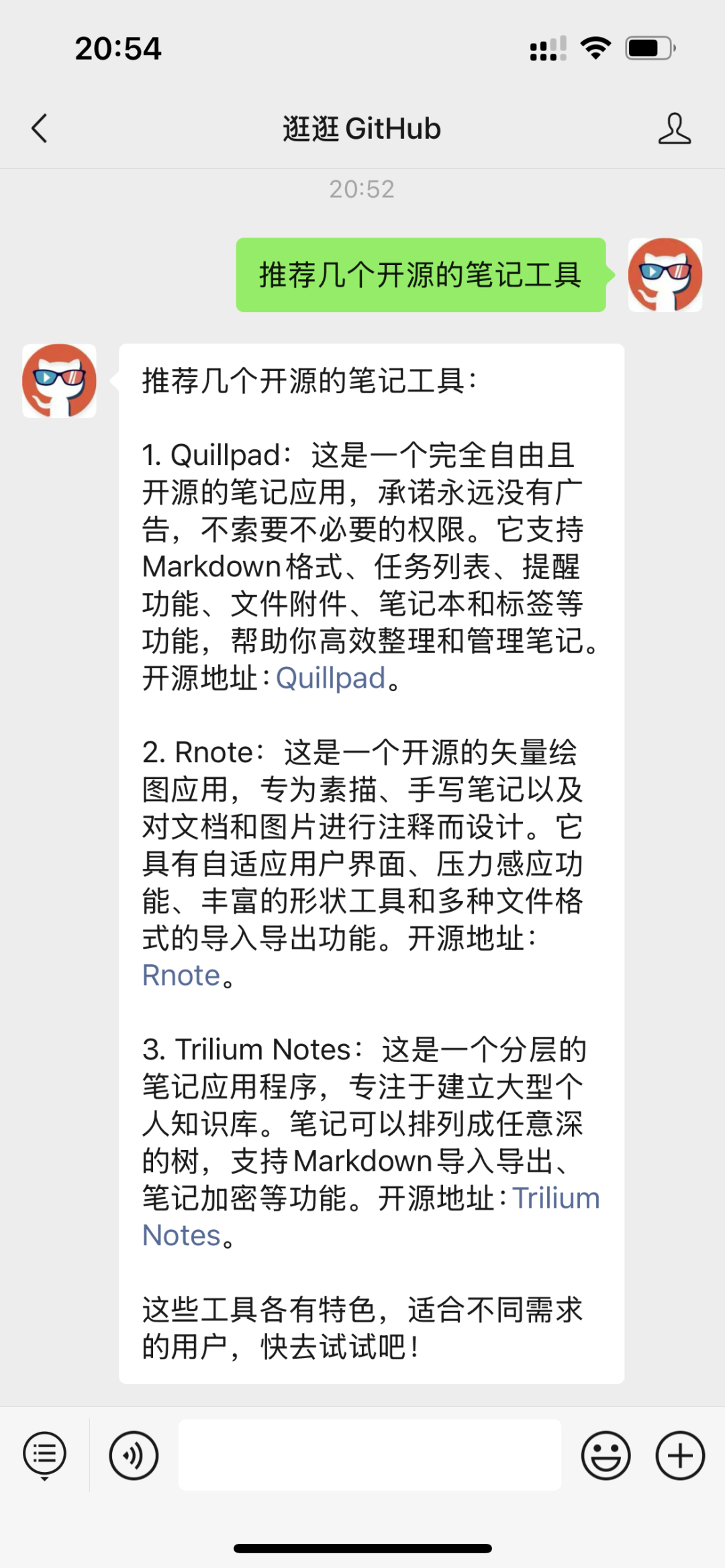

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)