
当下性价比最高的大语言模型DeepSeek-V2-Chat
前一段时间,DeepSeek宣布1M的token只需要1块钱(人民币),率先打响了LLM价格战的第一枪,紧随其后,智谱宣布其旗下的GLM-3-Turbo也只需要1块钱(批处理只需要5毛),然后前两天字节开发布会,宣布豆包只需要8毛钱/M,国内几家公司纷纷卷大模型的价格,要知道现在OpenAI的gpt-4o需要36¥(5$),而gpt-3.5-turbo还需要3.6¥(0.5$),同水平的模型Ope
前一段时间,DeepSeek宣布1M的token只需要1块钱(人民币),率先打响了LLM价格战的第一枪,紧随其后,智谱宣布其旗下的GLM-3-Turbo也只需要1块钱(批处理只需要5毛),然后前两天字节开发布会,宣布豆包只需要8毛钱/M,国内几家公司纷纷卷大模型的价格,要知道现在OpenAI的gpt-4o需要36¥(5$),而gpt-3.5-turbo还需要3.6¥(0.5$),同水平的模型OpenAI算比较便宜的。另外国内像阿里的Qwen1.5-110B,fireworks.ai提供的报价是6.5¥(0.9$)。
当然像gpt-4o代表着目前全球最先进的大模型,价格贵点可以说一分钱一分货,但从性价比上来说肯定是排不进前面的。今天我们就来看下目前仅有的价格低到1块钱/M的模型,DeepSeek-V2-Chat、GLM-3-Turbo和豆包,不过目前豆包API还未开放给个人使用,而且字节方面也从未公布过其相关性能指标,豆包也未参与过CompassRank的打榜,我们姑且认为它和gpt-3.5-turbo性能相当吧(大概率性能不如gpt-3.5-turbo,要不然这也会成为发布会的一个亮点之一)。
这三者里当前是豆包价格最低,性能的话我们就参考CompassRank的评分榜。其中DeepSeek-V2-Chat位于榜单第8,gpt-3.5-turbo和glm3-6b分别位于23和36名。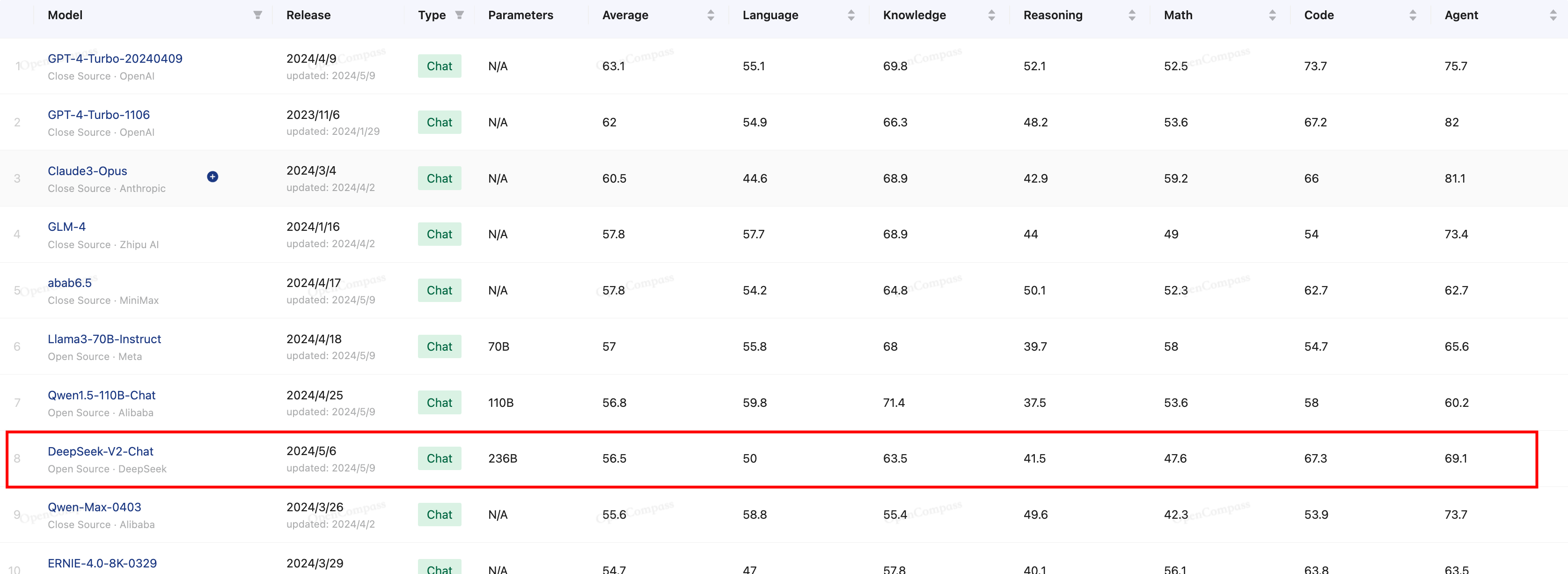
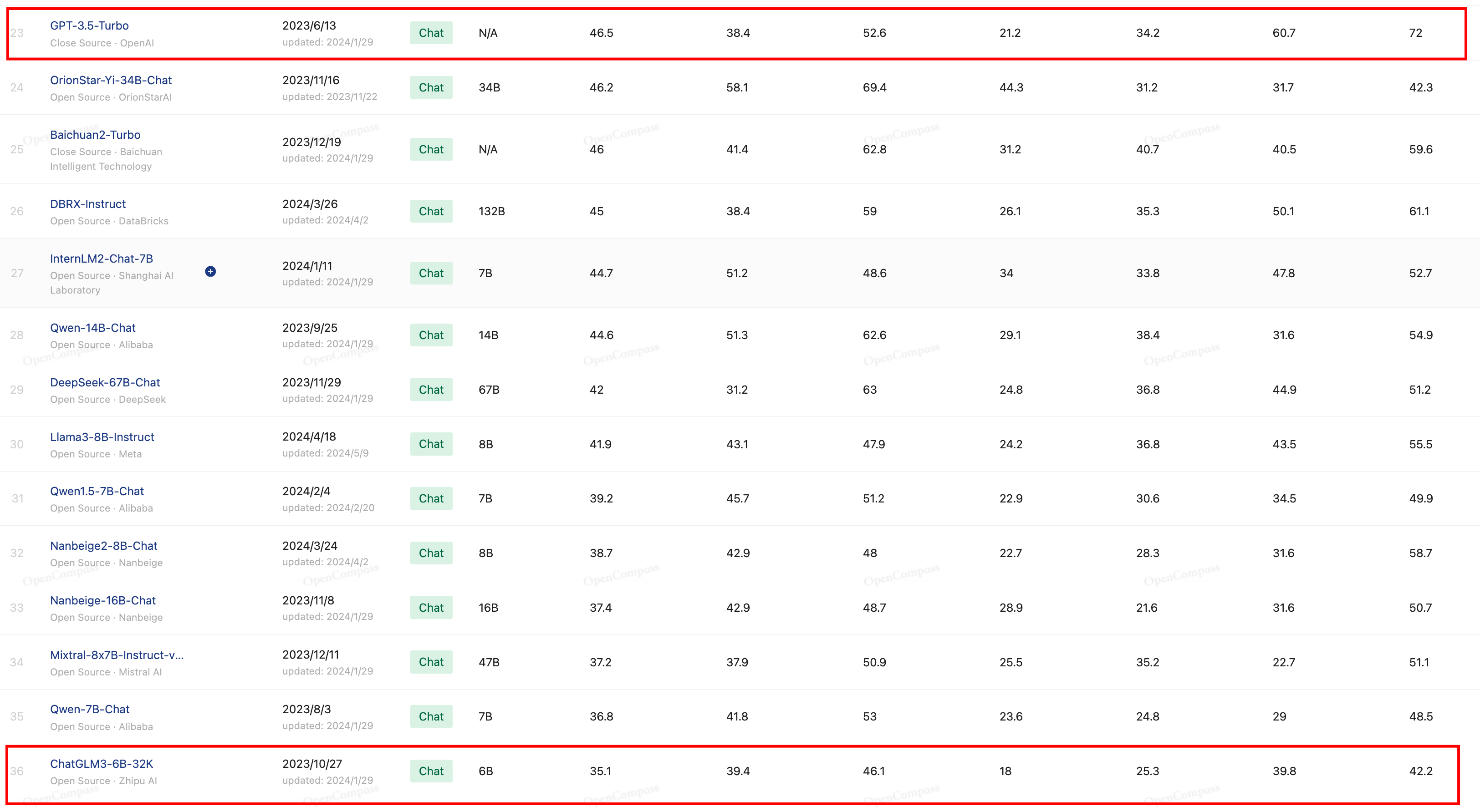
从上面的图中可以看出DeepSeek-V2-Chat在多个维度上是强于其他两个模型的,甚至DeepSeek-V2-Chat在编码上与GPT-4-Turbo-1106有一拼之力,依据上面的榜单,我说DeepSeek-V2-Chat、GLM-3-Turbo和豆包在性能是最强模型没毛病吧,其价格也相差无几,所以间接说其性价比是目前最高的也能说通吧。
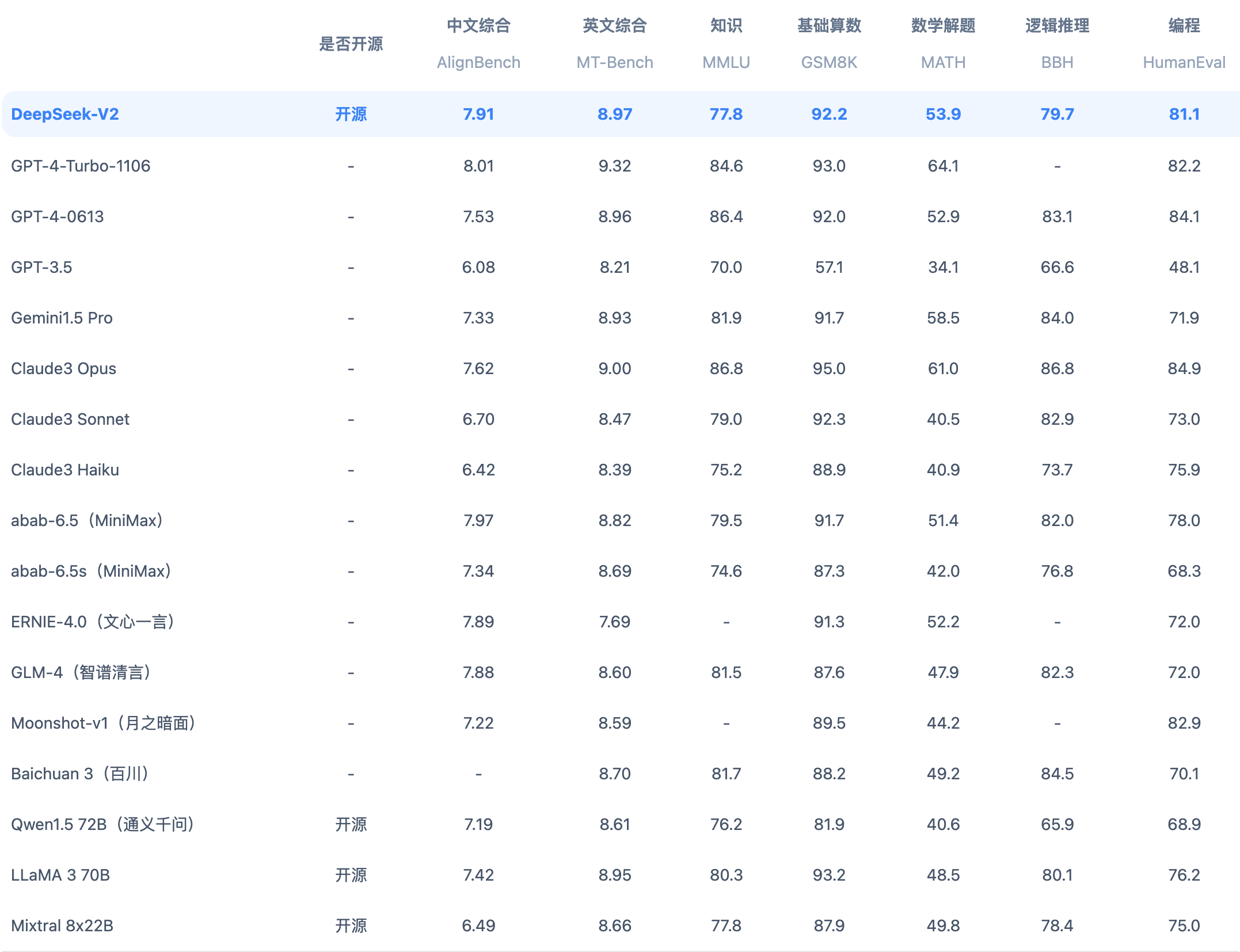
从DeepSeek-V2-Chat官方放出来的测评结果来说, 其性能也是一众模型中也是很优秀的,目前价格也是最低的。
当然上文中说的1块钱1M token的DeepSeek-V2-Chat是官网了上下文长度为32k的版本,128k的版本目前官网并没有提供。豆包pro也是32k的最大上下文,而glm3虽然各项评分偏弱,但他提供了128k的上下文长度,这算是它一个优势吧。
最后如果大家想用deepseek-v2的话可以去官网注册账号,然后实名下即可,没有太多门槛。 https://platform.deepseek.com/api-docs/zh-cn/
声明:没有收deepseek的广告费,就是单纯个人推荐。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)