大家热议的 Deepseek v3 究竟好不好用?
(注:本文为小报童精选文章。已订阅小报童或加入知识星球「玉树芝兰」用户请勿重复付费)从成本到性能的全方位解析。火热你知道的,最近 Deepseek 推出了 v3 版本,挺火的。这款模型因其低成本、高性能而备受关注。但是这款模型到底怎么样,都能帮你做什么呢?今天咱们就系统地讲讲它有哪些厉害之处。我们会从搜索、翻译、知识库综合和文本润色等多项任务入手,给你详细介绍它的能力。成本我们先聊聊,它为什么让大
(注:本文为小报童精选文章。已订阅小报童或加入知识星球「玉树芝兰」用户请勿重复付费)
从成本到性能的全方位解析。

火热
你知道的,最近 Deepseek 推出了 v3 版本,挺火的。这款模型因其低成本、高性能而备受关注。
但是这款模型到底怎么样,都能帮你做什么呢?今天咱们就系统地讲讲它有哪些厉害之处。我们会从搜索、翻译、知识库综合和文本润色等多项任务入手,给你详细介绍它的能力。
成本
我们先聊聊,它为什么让大伙儿那么感兴趣。最直观的一点,就是便宜。
当然了,如今的大模型,价格都卷成啥样了,想必你有切身感受 —— 别说便宜,免费的都有不少。

这是我在 Openrouter 里面设定过滤器为「免费」,能找到 26 个模型,而且还包括 Gemini 2.0 这样的绝对主力。
那么 Deepseek 的便宜为什么让人印象深刻?
因为,在目前的价格定位上,它居然能盈利。
这是我让大语言模型做的分析,你对比看看就知道,这是价格量级的差异。
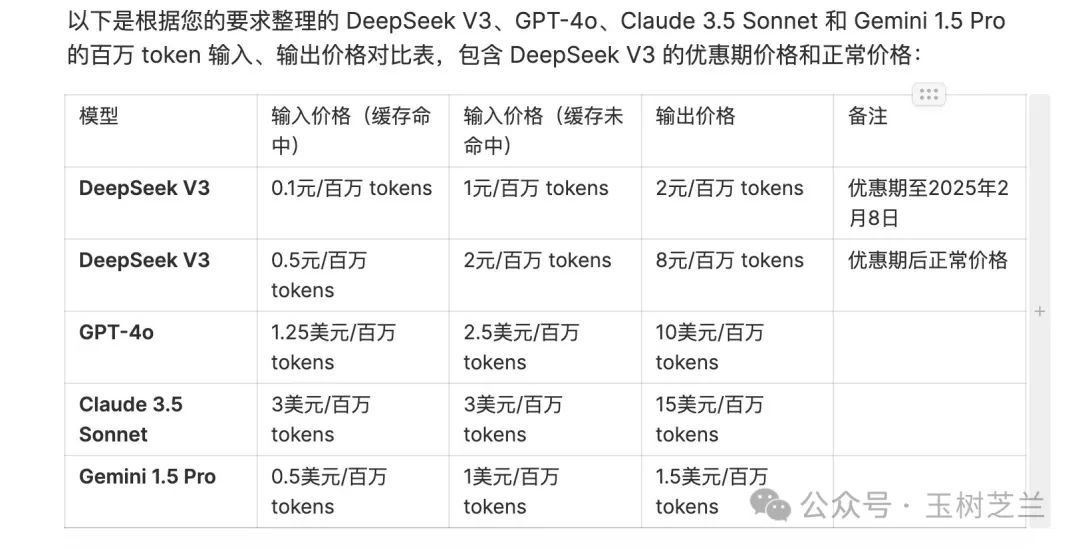
那么为什么 Deepseek 把价格定到同等级模型的 1/10 ,还能盈利呢?
因为它的训练和推断,那是真省钱啊。
DeepSeek V3 是一款具有 6710 亿参数(671B)的混合专家模型(MoE),其训练成本仅为 557.6 万美元,使用了 280 万个 GPU 小时。这一成本显著低于其他同等级的大模型。例如 Llama 3 405B 的训练成本约 3080 万 GPU 小时,是 DeepSeek V3 的训练成本的大约 11 倍。而 OpenAI 的 CEO Sam Altman 也提到,GPT-4 的训练成本超过 1 亿美元。
DeepSeek-V3 把训练费用降低得这么夸张,主要依靠多项技术创新和优化策略的有效协同,让它在性能与资源投入之间找到了理想的平衡点。
咱们找重点简单说说。
在训练精度上,DeepSeek-V3 引入了「FP8 混合精度训练」—— 这是一种将计算精度降低到 8 位浮点数的方式。它能显著减少 GPU 内存和计算量,让数据处理更高效。与传统浮点精度相比,FP8 在保证模型稳定性的同时,也有效降低了对硬件的负担。
在模型架构上,DeepSeek-V3 使用了「混合专家(MoE)」机制。简单来说,每个输入 token 在模型内部只会激活一部分专家网络(总共有 37B 参数,但每次只用到其中的一部分),这样就能大幅降低实际计算需求,同时依然维持高水平的性能。稀疏激活策略让模型充分利用参数,却不会让系统承担过重的计算负担。
另外,DeepSeek-V3 还融合了「多头潜在注意力(MLA)」方案,这是在传统多头注意力基础上,对「键」和「值」进行压缩的方法。这样不仅能加快注意力计算过程,在处理相隔较远的文本上下文时也更具针对性,从而兼顾训练速度与理解深度。
当然了,除此之外,Deepseek 还综合使用了「多令牌预测(MTP)」和「DualPipe 双向流水线」等黑科技。鉴于相关技术细节有些复杂,咱们就不赘述了。
当计算资源被限制时,Deepseek 居然独立自主从技术上突破,这不得不让很多拥有充足资源的国际同行们刮目相看。
成本降低,并没有以能力的妥协为代价。在 Chatbot Arena LLM Leaderboard 上,Deepseek v3 妥妥位列第一梯队。
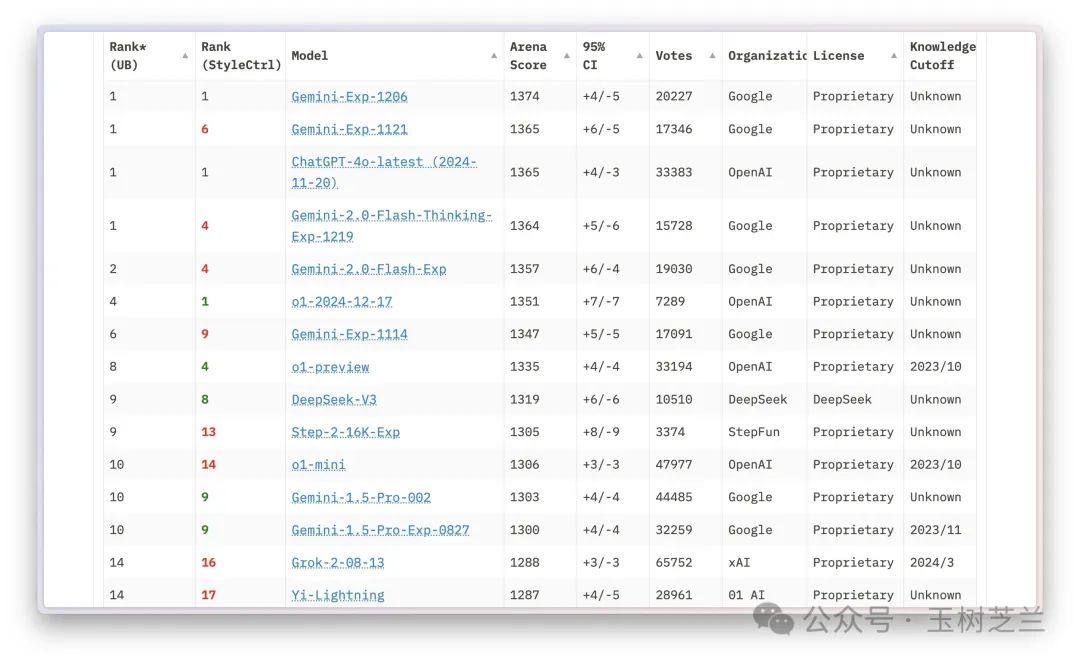
只不过,我们普通用户更关心的,其实并非评分,而是用起来怎么样。
下面咱们就看几个具体的应用。
先看搜索。
搜索

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)