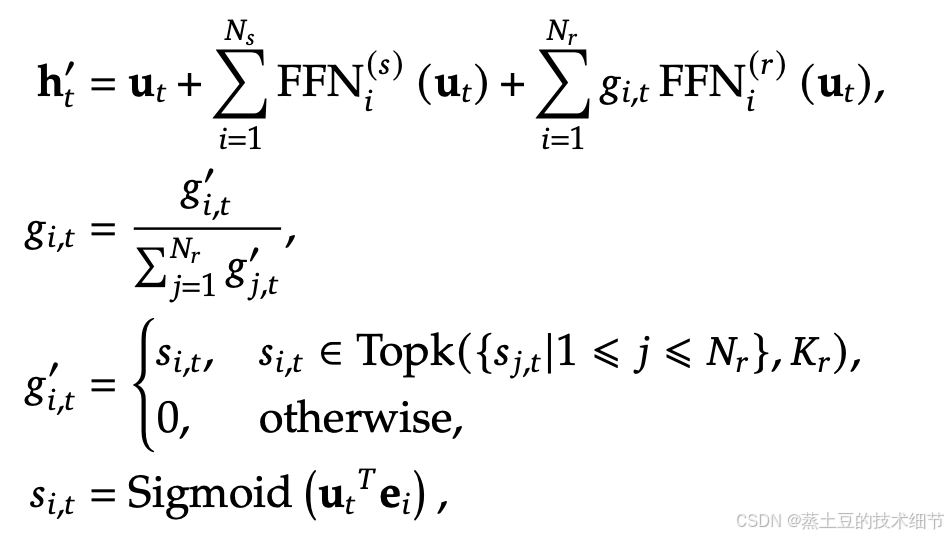
DeepSeek-v3笔记(1)
直接从第二章Architecture开始。
v3链接
直接从第二章Architecture开始
2.1 Basic Architecture
基本方法就是v2的那一套,仍然是moe架构,采用MLA降显存, 常驻专家和路由专家的混合使用。与v2不同的是,这里用了更加强力的路由平衡算法,叫Auxiliary-Loss-Free Load Balancing。它主要解决不同route expert训练不平衡问题,思路就是谁训得少了就把谁被选中的概率抬高。
至于MLA,略。
2.1.2 DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
这是v3的路由算法
ht的第二项是常驻专家,第三项是路由专家。可以看到,路由专家有权重,且多个路由专家权重和为1,也就是说常驻专家+1个攒起来的专家构成了专家团队。
Sigmoid得到route expert的得分,这点和v2不一样。v2是这样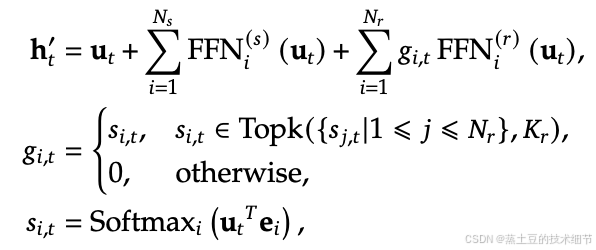
归一化方法略有变化,这里我考虑是因为sigmoid让不同专家之间的权重差距变小,利于后面auxiliary-loss-free权重调整的敏感性。
下面就是 auxiliary-loss-free load balancing strategy的核心改动:
在排序的时候给权重加个能变的bias bi。对它的描述如下:
Note that the bias term is only used for routing. The gating value, which will be multiplied with the FFN output, is still derived from the original affinity score 𝑠𝑖,𝑡. During training, we keep monitoring the expert load on the whole batch of each training step. At the end of each step, we will decrease the bias term by 𝛾 if its corresponding expert is overloaded, and increase it by 𝛾 if its corresponding expert is underloaded, where 𝛾 is a hyper-parameter called bias update speed. Through the dynamic adjustment, DeepSeek-V3 keeps balanced expert load during training, and achieves better performance than models that encourage load balance through pure auxiliary losses.
TL.NR.bias会在某个route expert训练过载时,给权重s减去一个 γ \gamma γ超参数,反之加上。然而我并不知道什么叫训练过载,是训练哪个就给对应的route expert减去一个 γ \gamma γ吗?
除了上面的,还使用了一个loss为专家的均衡训练兜底。Complementary Sequence-Wise Auxiliary Loss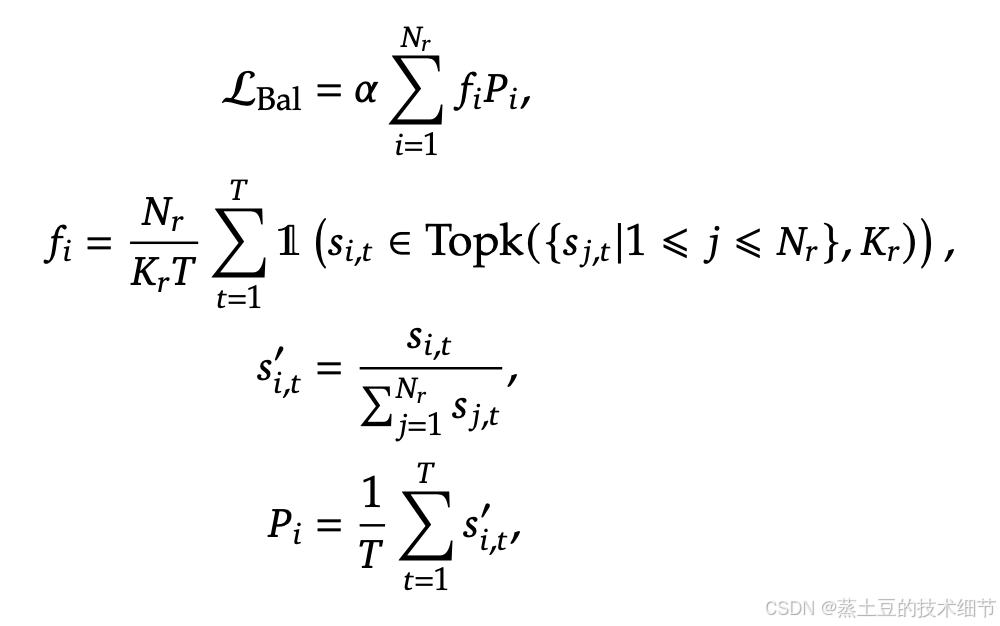
从下往上捋。一个sequence的每个token都要过route,我们期望所有expert能在整个sequence的尺度用得差不多均衡,于是先计算每个expert在整个sequence上的平均概率Pi,倒数第二句就是计算概率的方式,即基于sigmoid吐出的score sit。第二句,长得像1一样的是示性函数,也就是后面的条件符合,它就是1,否则是0。这个fi不好理解,如果去掉Nr和Kr,可以理解为“统计某个route expert i在当前这个sequence的所有token上被采纳的平均次数”,加上Nr和Kr,由于这两个值对于固定的模型是固定的,所以只是权重放缩。最后的loss L_Bal, α \alpha α是一个极小的超参数,后者的累加元素是route expert i的平均被采纳次数✖️平均概率。我对loss的理解如下:如果是极端不均衡情况下,设只有前Kr个专家平分概率,所以每次选都选它们。对于这些极端专家:
P i = 1 / K r P_i=1/K_r Pi=1/Kr f i = N r / K r f_i=N_r/K_r fi=Nr/Kr L B a l = α N r 2 / K r 2 L_{Bal}=\alpha N_r^2/K_r^2 LBal=αNr2/Kr2
对于那些理想均匀的情况:
P i = 1 / N r P_i=1/N_r Pi=1/Nr f i = 1 f_i=1 fi=1 L B a l = α L_{Bal}=\alpha LBal=α
且 N r > K r N_r>K_r Nr>Kr,所以均匀情况loss很小,函数凸不凸就不知道了。
Node-Limited Routing. 很怪,看起来上面的训练方法让每个route expert的功能大同小异,因此即使采用“只允许token选择某几个计算节点上的route expert”这种阉割策略,也没有影响性能。
我找到了它在deepseek-v2上的解释,在deepseek-v2论文的2.2.2节:
写得很暧昧,什么叫亲和分数?我贪心地推举每个device里的max(expert score)作为选择M个device的标准,可以吗?
No Token-Dropping. 按它说的,由于负载均衡,因此不需要drop token了。如果是老方法,不均衡的负载导致前推和反向的时候会集中在某几个计算节点负责的route expert上,此时负载过大,算不过来,我猜所谓的dropping就是删掉几个token处的loss,减小节点的压力。但是现在负载均衡了,就不需要dropping了。
Multi-Token Prediction
正常的transformer前推,每次生成新的token后,把新token再塞进input,该input经过几十层,预测下一个token。Multi-Token Prediction如下: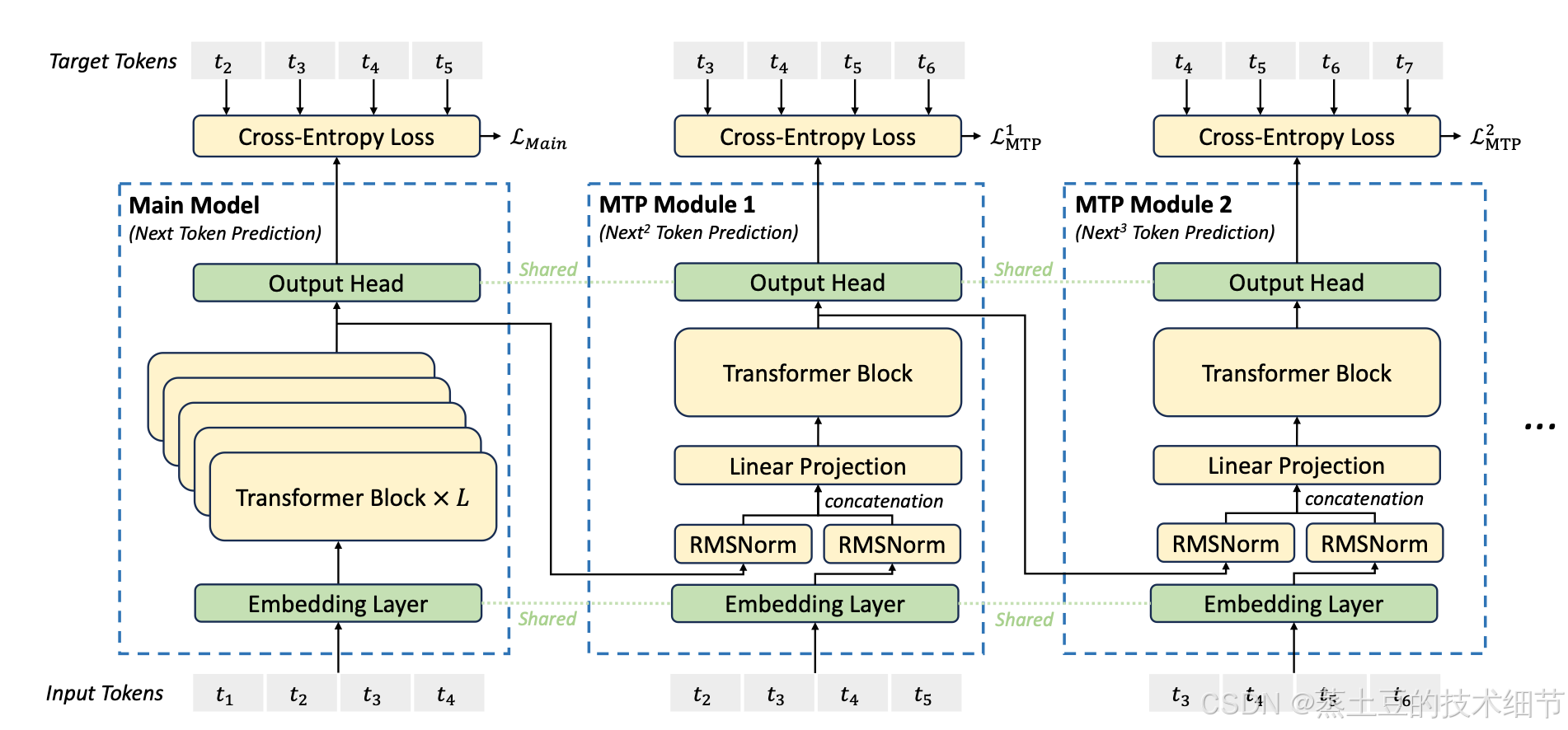
先说推理。首先,我们让promp是t1~t4,然后正常推出t5。为了推t6,我们拿出t1~t4的表示(如图),让t1~t4对应t2~t5,相应地,在MTP Module1,让输入为t2~t5,embedding后和对应的前述concat,拼接方法是dim拼接,拼后的矩阵尺寸是4*(2*hidden_dim)。线性映射是把dim压缩到hidden_dim的映射。然后这4个token representation正常过下一个transformer block,再正常output预测t6。对于MTP Module2,对应关系变为前一Module1的t2~t5对应t3~t6。
这套逻辑看起来是这样:prefill token有n个,则Module k的输入也得是n个。但是从对应关系看,我们也可以对应更少的token,例如prefill token有100个,你只取最后4个t97~t100,Module k对应上t98~t101,也能跑,就是不知道效果打折多少。理论上k可以无限大,但我猜还是得周期性地收集Module吐出的token,然后统一prefill,再继续下一轮。
对于训练。Main Model肯定正常训练,MTP Module也可以对所有输入输出进行训练,这样就会产生“t2训练不止一次”的情况,但是没事,t2在Model和Module的功能不同,即使预测了多次t3,也没事。
新增的对MTP的loss如下: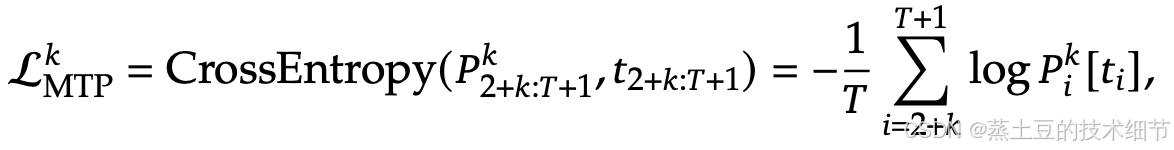
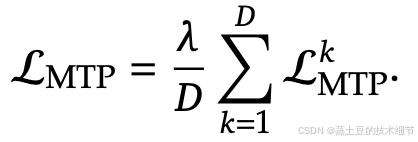
D是Module数量,也就是MTP Module一共往下D个token。loss是普通的交叉熵。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)