DeepSeek从本地部署到无限调用API
总结来说上述的方式不仅针对deepseek,更确切的来说是针对ollama的,只要ollama能安装的大模型都可以用,参考ollama官网。技术层面:降低开发难度,开发者不用了解模型内部复杂架构和训练过程,只需关注应用。还便于集成扩展,能与各类系统、平台和编程语言轻松集成,为业务添加智能功能。同时,可及时获取模型更新,享受优化改进。资源管理层面:节省计算资源,无需购置和维护昂贵计算设备,按需使用云

本文聚焦于 DeepSeek 模型本地部署后 API 的无限调用。文章开篇点明 DeepSeek 官方 API 不稳定,引出本地部署实现无限调用 API 的需求,且强调方法适用于 ollama 安装的多种模型。接着介绍部署步骤,参考相关文章可快速完成。随后分别以 http 和 python SDK 两种方式进行演示,详细展示测试过程、代码示例,还对涉及的参数进行解释,方便读者深入理解和灵活运用。文章最后总结该方法的通用性,并从技术、资源管理、业务应用三个层面阐述使用 API 调用大模型的优势,为开发者提供了实用的技术指引。
2. 背景
由于众所周知的原因,DeepSeek官方的API一直不稳定。好在ds已经开源了,既然开源又支持本地部署,所以他肯定能无限使用。上一篇《基于DeepSeek打造团队知识库》已经能实现无限使用了,不过在一些集成应用中还是使用API会更加方便。
下文的案例,不仅适用于DeepSeek,以及ollama安装的模型都适用
3. 部署
部署的方式很简单,参考《基于DeepSeek打造团队知识库》的第二章、第三章,很快就能实现deepseek的部署,要注意的是 要保证你的模型在运行,以 deepseek-r1:8b 为例
ollama run deepseek-r1:8b
4. http方式
先以http的方式实验一下,随便找个api工具进行测试。这里要注意model的参数要与你实际部署的模型一致,否则会报错。如下图,进行post请求。
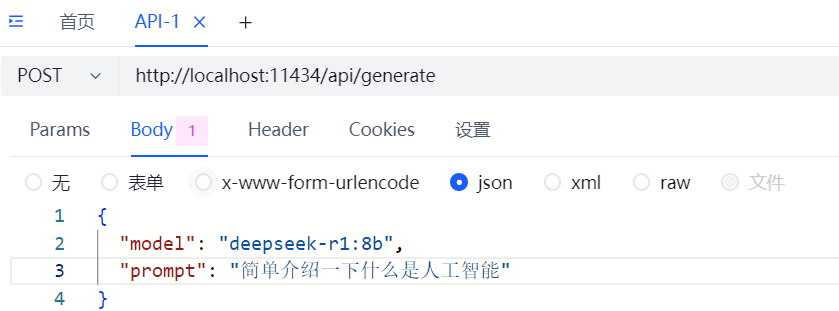
会出现如下图的响应。
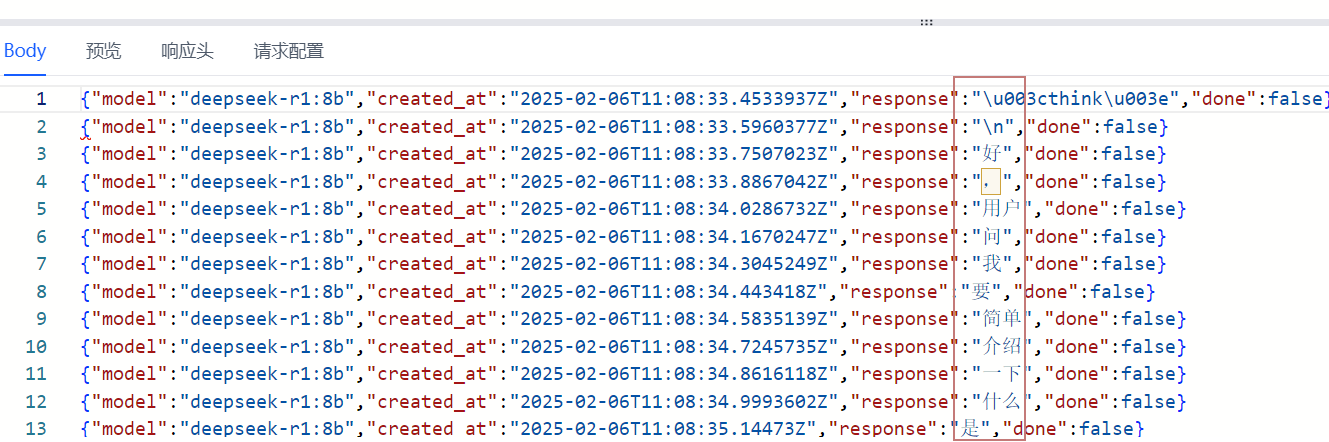
看上去还以为出了什么错误,其实仔细看reponse是正常的文字,其实是因为这里默认使用了流式方式,所以他是一条条的。
下面换python http的方式来演示一下,顺便不使用流式的方式。
import requests
# 基础初始化设置
base_url = "http://localhost:11434/api"
headers = {
"Content-Type": "application/json"
}
def generate_completion(prompt, model="deepseek-r1:8b"):
url = f"{base_url}/generate"
data = {
"model": model,
"prompt": prompt,
"stream": False
}
response = requests.post(url, headers=headers, json=data)
return response.json().get('response', '')
# test
completion = generate_completion("介绍一下人工智能。")
print("生成文本补全:", completion)
下面就是收到的回复,还能看到deepseek标志性的think标签,要注意的是因为我关掉了流式方式,所以一开始会等待一段时间,他是直接给出所有思考和答案。

5. python SDK方式
直接使用python sdk的方式会比较简单,先安装依赖
pip install ollama
一下是简单的代码演示
from ollama import chat
stream = chat(
model='deepseek-r1:8b',
messages=[{'role': 'user', 'content': '简单描述一下深度学习'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
这次是使用的流式方式,和官网使用是一个感觉,一个字一个字的往外碰。
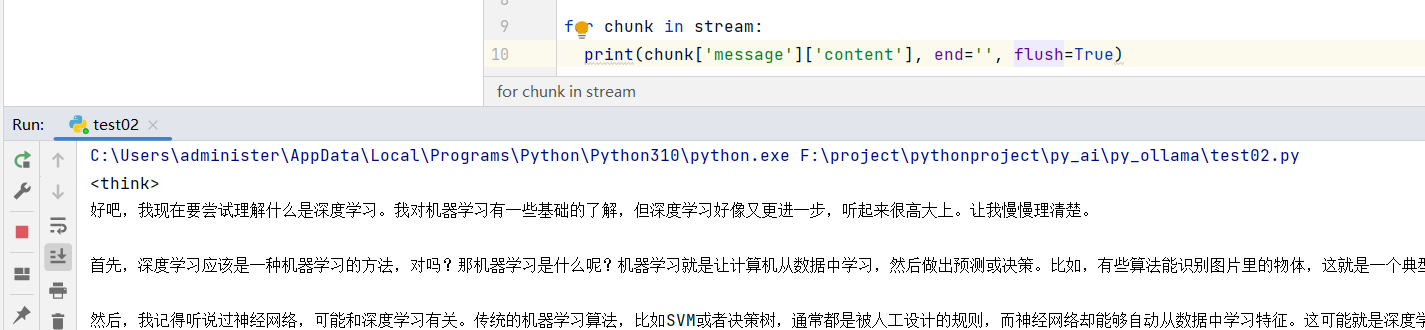
6. 参数解释
上面的演示只是比较简单的一些案例,他还支持更多的参数。
参数
model: (必需)模型名称prompt: 生成响应的提示suffix: 模型响应后的文本images: (可选)一个 base64 编码的图像列表(适用于多模态模型,如llava)
高级参数(可选):
format: 返回响应的格式。目前唯一接受的值是jsonoptions: 文档中列出的 Modelfile 中的其他模型参数,例如temperaturesystem: 系统消息(覆盖Modelfile中定义的内容)template: 使用的提示模板(覆盖Modelfile中定义的内容)context: 从先前请求/generate返回的上下文参数,可用于保持简短的对话记忆stream: 如果为false,响应将作为单个响应对象返回,而不是一系列对象raw: 如果为true,不会对提示进行任何格式化。如果你在请求 API 时指定了完整的模板提示,可以选择使用raw参数keep_alive: 控制请求后模型在内存中保持加载的时间(默认:5m)
更多的内容我推荐阅读ollama文档,有更多更详细的内容,如上传图片、携带历史记录等。
7. 总结
总结来说上述的方式不仅针对deepseek,更确切的来说是针对ollama的,只要ollama能安装的大模型都可以用,参考ollama官网 。
使用API的方式来调用大模型有很多便利之处:
- 技术层面:降低开发难度,开发者不用了解模型内部复杂架构和训练过程,只需关注应用。还便于集成扩展,能与各类系统、平台和编程语言轻松集成,为业务添加智能功能。同时,可及时获取模型更新,享受优化改进。
- 资源管理层面:节省计算资源,无需购置和维护昂贵计算设备,按需使用云端服务即可。成本控制也更灵活,能按需付费,避免资源浪费。
- 业务应用层面:快速验证业务想法,开发初期用 API 搭建原型,评估功能价值。能提升用户体验,提供智能、便捷、个性化服务。还能让企业专注核心业务,将精力放在自身优势领域,提升竞争力 。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 34
34 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)