当你使用deepseek网页版上传文件提示“超出字数限制,deepseek只阅读了前30%”,你应该怎么办?
在实际使用deepseek过程中,发现官方网站分析内容有限制,向deepseek提问,是否可以通过api调用方式分析长文本。

当你使用deepseek上传文件提示“超出字数限制,deepseek只阅读了前30%”,你应该怎么办?
背景
当你使用deepseek上传文件提示“超出字数限制,deepseek只阅读了前30%”,你应该怎么办?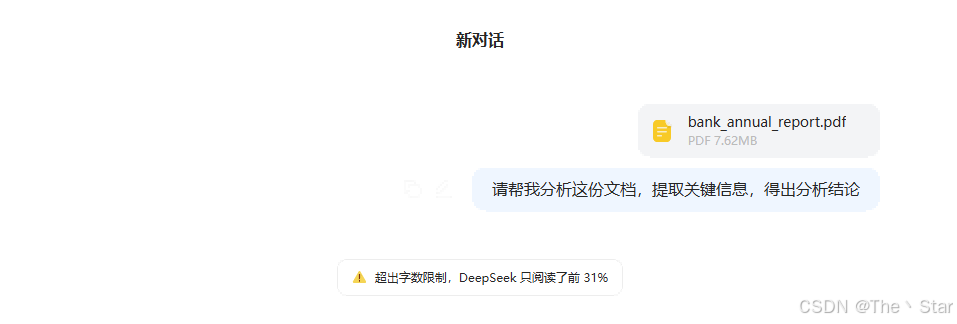
解决方案
向deepseek提问如下内容:
我是一名金融分析师,主要分析商业银行经营业绩及经营亮点,从分析结果中总结分析经营特点并在自己的工作岗位中找到工作思路,请你用python帮我编写一段代码,主要实现使用deepseek分析商业银行PDF版本年报的代码,实现deepseek调用与交互
deepseek的解决方案
嗯,用户是金融分析师,需要分析商业银行的年报PDF,然后用DeepSeek来交互。首先,我需要明确用户的需求。他们想要一个Python脚本,能够读取PDF年报,调用DeepSeek的API进行分析,然后总结经营特点和亮点,最后将这些分析应用到工作中。
首先,PDF处理是关键。Python里常用的库有PyPDF2、pdfplumber或者PyMuPDF。用户可能需要提取文本,所以得选一个可靠的库。PyPDF2有时候对复杂格式支持不够好,可能pdfplumber更好,因为它能提取更详细的文本,包括表格。
然后,调用DeepSeek的API。用户提到的是DeepSeek,所以需要查阅它的API文档,看如何发送请求,处理响应。可能需要使用requests库发送HTTP请求,传递API密钥,以及构造正确的请求体。例如,可能需要将提取的文本分成块,因为API可能有输入长度限制。
接下来是交互部分。用户可能需要一个循环,让用户输入问题,然后调用API获取回答。同时,要考虑如何处理较长的PDF文本,可能需要分块处理,或者先总结各部分再综合。
还要考虑错误处理,比如API调用失败,PDF读取错误等。需要添加try-except块来捕捉异常,确保程序健壮性。
另外,用户可能需要保存处理后的文本或分析结果,可能需要添加文件写入功能,比如将提取的文本保存为txt文件,方便后续查看。
然后,代码结构大致分为几个部分:读取PDF并提取文本,调用DeepSeek API进行分析,交互式问答循环。每个部分需要模块化处理,比如函数分开,方便维护。
可能遇到的问题包括PDF加密、格式复杂导致文本提取不全,或者API的速率限制。需要提醒用户注意这些潜在问题,并在代码中添加相应的处理,比如处理加密PDF,分块发送请求避免超过token限制。
最后,测试代码是否能够正确运行,确保API密钥正确配置,PDF路径正确,以及响应处理无误。可能需要提供示例用法,让用户清楚如何替换API密钥和PDF路径。
总结下来,步骤是:安装必要库,读取PDF文本,调用DeepSeek分析,交互式提问。需要处理文本分块、API调用、错误处理,以及用户交互的循环。
代码特点说明:
专业PDF处理:
使用pdfplumber处理复杂版式PDF
保留文本布局信息(对表格数据解析很重要)
自动分块处理长文本(适应API限制)
金融分析增强:
内置专业分析提示模板
强调财务指标分析和监管要求
结构化输出要求确保分析深度
工程化设计:
错误处理机制
上下文感知的交互问答
温度值调优平衡创造性与准确性
工作流整合:
完整分析报告生成
交互式深入探讨
结果持久化存储
使用建议:
安装依赖:
bash
复制
pip install pdfplumber requests
需要准备:
DeepSeek API访问权限
商业银行年报PDF文件(推荐使用可复制文本的版本)
典型应用场景:
快速提取关键财务指标
识别业务转型趋势
对比多期年报变化
生成演示材料所需的数据支撑
扩展方向:
添加多文档对比功能
集成自动化图表生成
添加监管指标预警系统
对接内部财务数据库
deepseek设计代码
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "我是一名金融分析师"},
{"role": "user", "content": "我是一名金融分析师,主要分析商业银行经营业绩及经营亮点,从分析结果中总结分析经营特点并在自己的工作岗位中
找到工作思路,请你用python帮我编写一段代码,主要实现使用deepseek分析商业银行PDF版本年报的代码,
实现deepseek调用与交互"},
],
stream=False
)
print(response.choices[0].message.content)
import os
import requests
import pdfplumber # 推荐使用pdfplumber处理复杂PDF格式
from typing import List
class BankReportAnalyzer:
def __init__(self, api_key: str):
self.api_key = api_key
self.api_url = "https://api.deepseek.com/v1/chat/completions" # 根据实际API地址修改
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
def extract_text_from_pdf(self, pdf_path: str) -> str:
"""
从PDF文件中提取文本内容
"""
full_text = []
try:
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
# 提取文本并保留布局信息
text = page.extract_text(layout=True)
if text:
full_text.append(text)
return "\n".join(full_text)
except Exception as e:
print(f"PDF提取错误: {str(e)}")
return ""
def chunk_text(self, text: str, max_length: int = 8000) -> List[str]:
"""
将长文本分割成适合API处理的片段
"""
return [text[i:i+max_length] for i in range(0, len(text), max_length)]
def analyze_with_deepseek(self, prompt: str, text_chunk: str) -> str:
"""
调用DeepSeek API进行分析
"""
full_prompt = f"{prompt}\n\n需要分析的文本内容:\n{text_chunk}"
payload = {
"model": "deepseek-chat", # 根据实际模型名称修改
"messages": [
{"role": "user", "content": full_prompt}
],
"temperature": 0.3 # 降低随机性以保证分析稳定性
}
try:
response = requests.post(self.api_url, json=payload, headers=self.headers)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"]
except Exception as e:
print(f"API调用失败: {str(e)}")
return ""
def generate_analysis_report(self, pdf_path: str):
"""
生成完整分析报告
"""
# 步骤1:提取PDF文本
print("正在提取PDF文本...")
full_text = self.extract_text_from_pdf(pdf_path)
if not full_text:
return
# 步骤2:分块处理文本
text_chunks = self.chunk_text(full_text)
# 步骤3:定义专业分析提示词
analysis_prompt = """作为资深金融分析师,请对商业银行年报进行以下分析:
1. 识别关键财务指标(NIM、ROE、不良率等)及其变化趋势
2. 分析资产负债结构变化特点
3. 总结业务发展亮点(公司金融、零售转型、数字化进展等)
4. 识别风险管理措施有效性
5. 提炼战略发展方向和经营特色
要求:
- 使用专业金融术语
- 结合银行业监管指标
- 突出同比/环比显著变化
- 输出结构化分析结果(含数据支持)"""
# 步骤4:分块分析并汇总结果
full_analysis = []
for i, chunk in enumerate(text_chunks):
print(f"正在分析第 {i+1}/{len(text_chunks)} 部分...")
analysis = self.analyze_with_deepseek(analysis_prompt, chunk)
full_analysis.append(analysis)
# 步骤5:综合最终报告
final_prompt = "请将以下分段分析结果整合为完整的年报分析报告:\n" + "\n".join(full_analysis)
final_report = self.analyze_with_deepseek(final_prompt, "")
# 保存分析结果
with open("analysis_report.txt", "w", encoding="utf-8") as f:
f.write(final_report)
print("分析报告已保存至 analysis_report.txt")
def interactive_qa(self):
"""
交互式问答模式
"""
print("进入交互问答模式(输入exit退出)")
context = []
while True:
question = input("\n请输入您的问题:")
if question.lower() == "exit":
break
# 添加上下文关联(最近3轮对话)
context.append({"role": "user", "content": question})
context = context[-3:] # 保持最近3条上下文
payload = {
"model": "deepseek-chat",
"messages": context,
"temperature": 0.5
}
try:
response = requests.post(self.api_url, json=payload, headers=self.headers)
response.raise_for_status()
answer = response.json()["choices"][0]["message"]["content"]
print("\nDeepSeek分析:\n" + answer)
context.append({"role": "assistant", "content": answer})
except Exception as e:
print(f"问答失败: {str(e)}")
if __name__ == "__main__":
# 使用示例
api_key = "<DeepSeek API Key>" # 替换为实际API密钥
pdf_path = "D:\\Users\\BANKQH\\Desktop\\bank_annual_report.pdf" # PDF文件路径
analyzer = BankReportAnalyzer(api_key)
# 生成完整分析报告
analyzer.generate_analysis_report(pdf_path)
# 启动交互问答
analyzer.interactive_qa()
运行结果
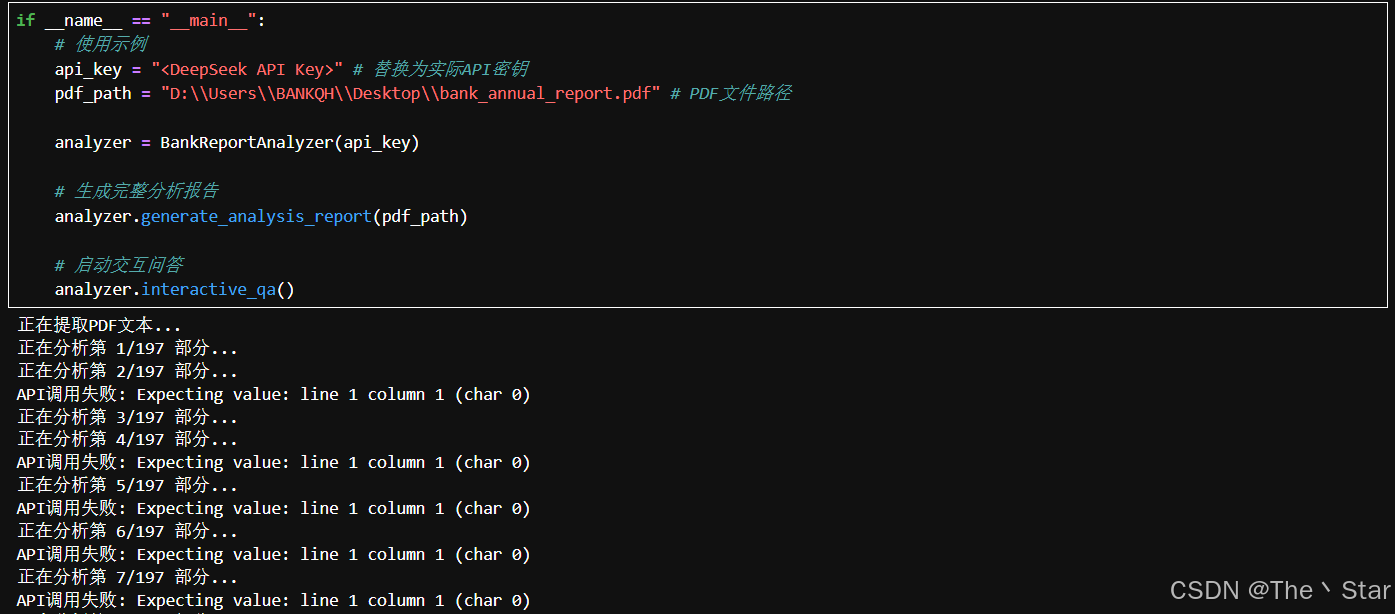
ps:明天看看验证结果,哈哈哈!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)