ollama + deepseek + anythingllm + web前端 实现 个人小型企业私有化部署方案
deepseek ollamaanythingllm 部署
注意:仅供大家进行 个人或者小型企业私有化部署参考。因openwebUI无法做到 共享anythingllm的知识库,所有这边不做前端介绍,大家可以自行搭建前端页面调用 anythingllm接口即可。有兴趣的也可以自行研究下openwebUI、page assist 相关结合使用最主要得能共享知识库训练的数据
前言
前端web选型得满足(基于企业认可知识库方式对接大模型)
1.大文件多文件上传至知识库
2.文件解析精准度成功率
3.各种文件格式,图片等解析支持
目前实际验证比较推荐,类似ragflow比较适合,但是验证了下实际使用文件知识库上传容易各种解析失败其他都还好
如果自行开发web有办法实现ragflow还能解决多文件上传解析各种失败问题。那基本应该符合各大公司的部署需求。而且可行的企业级别部署方案。
以上部分后续有遇到更好的内容会在这边更新,有必要时会单独发帖子
===================
1.ollama下载安装
1.1点击download下载无脑安装ollama(示例windows版)
- 双击运行下载的安装程序。
- 如果需要更改默认安装路径,可以在CMD下对应文件夹使用以下命令:
OllamaSetup.exe /DIR=“d:\some\location” - 按照安装向导完成安装
- 打开命令提示符(CMD)或 PowerShell,输入以下命令
ollama --version 如果返回版本号,表示安装成功。
或者访问ollama服务器http://localhost:11434 如果放回ollama is running 那就成功了
1.2配置 Ollama
1) 更改下载模型的默认位置
要更改模型存储位置,请设置环境变量 OLLAMA_MODELS:
打开“启动设置”(Windows 11)或“控制面板”(Windows 10)。
搜索并编辑用户账户的环境变量。添加或编辑变量名为 OLLAMA_MODELS,值为希望存储模
型的路径。点击“确定/应用”保存。
如果 Ollama 已在运行,请退出托盘应用程序并重新启动,或者关闭终端并重新打开。
移动已下载的模型直接将 C:\Users{用户名}.ollama\models\ 文件夹下的 blobs 和 manifests 复
制到新路径后重启 Ollama 即可。
Ollama 提供以下主要命令以满足不同功能需求:
serve: 启动 Ollama 服务。
create: 基于 Modelfile 创建一个模型。
show: 查看模型的详细信息。
run: 执行指定模型的推理任务。
stop: 停止一个正在运行的模型。
pull: 从注册表下载一个模型。
push: 将本地模型上传到注册表。
list: 列出所有本地模型。
ps: 显示当前正在运行的模型。
cp: 复制一个模型。
rm: 删除一个模型。
help: 获取帮助文档
Ollama可配置环境变量:
OLLAMA_DEBUG: 显示额外的调试信息(例如:OLLAMA_DEBUG=1)。
OLLAMA_HOST: Ollama 服务器的 IP 地址(默认值:127.0.0.1:11434)。
OLLAMA_KEEP_ALIVE: 模型在内存中保持加载的时长(默认值:“5m”)。
OLLAMA_MAX_LOADED_MODELS: 每个 GPU 上最大加载模型数量。
OLLAMA_MAX_QUEUE: 请求队列的最大长度。
OLLAMA_MODELS: 模型目录的路径。
OLLAMA_NUM_PARALLEL: 最大并行请求数。
OLLAMA_NOPRUNE: 启动时不修剪模型 blob。
OLLAMA_ORIGINS: 允许的源列表,使用逗号分隔。
OLLAMA_SCHED_SPREAD: 始终跨所有 GPU 调度模型。
OLLAMA_TMPDIR: 临时文件的位置。
OLLAMA_FLASH_ATTENTION: 启用 Flash Attention。
OLLAMA_LLM_LIBRARY: 设置 LLM 库以绕过自动检测。
2.模型下载(deepseek部署)
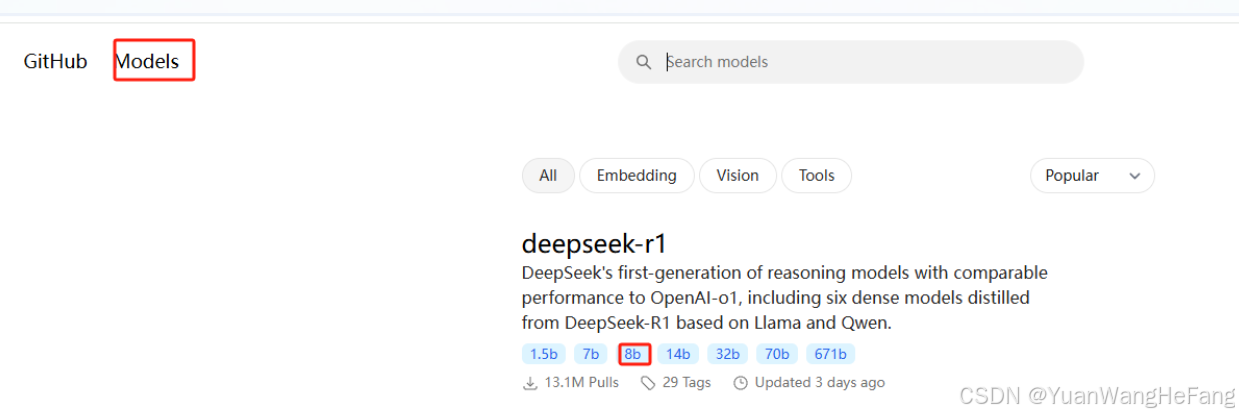
选择对应模型 复制下载模型命令 ollama run deepseek-r1:8b 如果不想跑,可以用ollama pull deepseek-r1:8b (这边我笔记本跑的是8b的)
刚开始尝鲜的建议 下载1.5b测试,比较小 下载比较快。 如果rtx3060 12g + 内存16g/32g 可以至少能跑 14b 如果rtx4090可以试试32b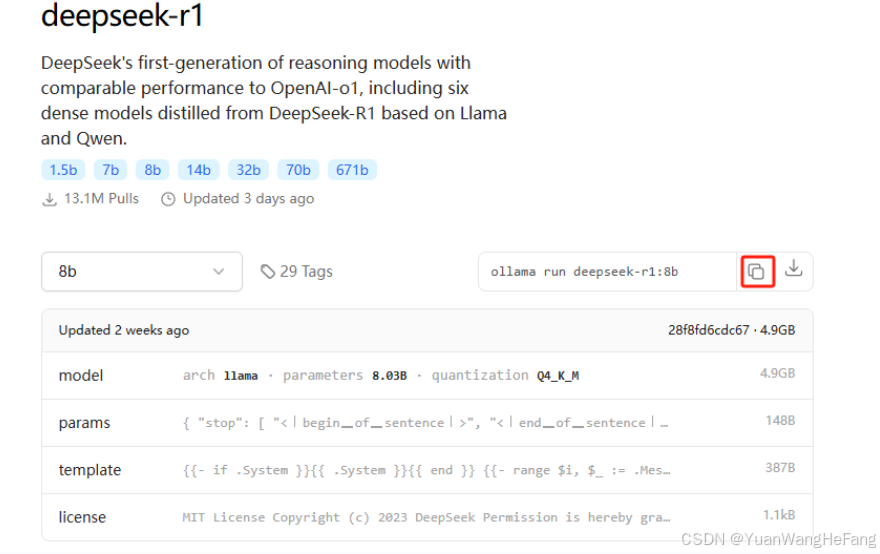
run完成后,cmd界面会显示success 这是你可以进行 简单的对话 以下截图因为已经下载过所以没有sucess标志
**
3.anythingllm安装部署(示例windows版)
**
下载界面链接:https://docs.useanything.com/installation-desktop/windows#install-using-the-installation-file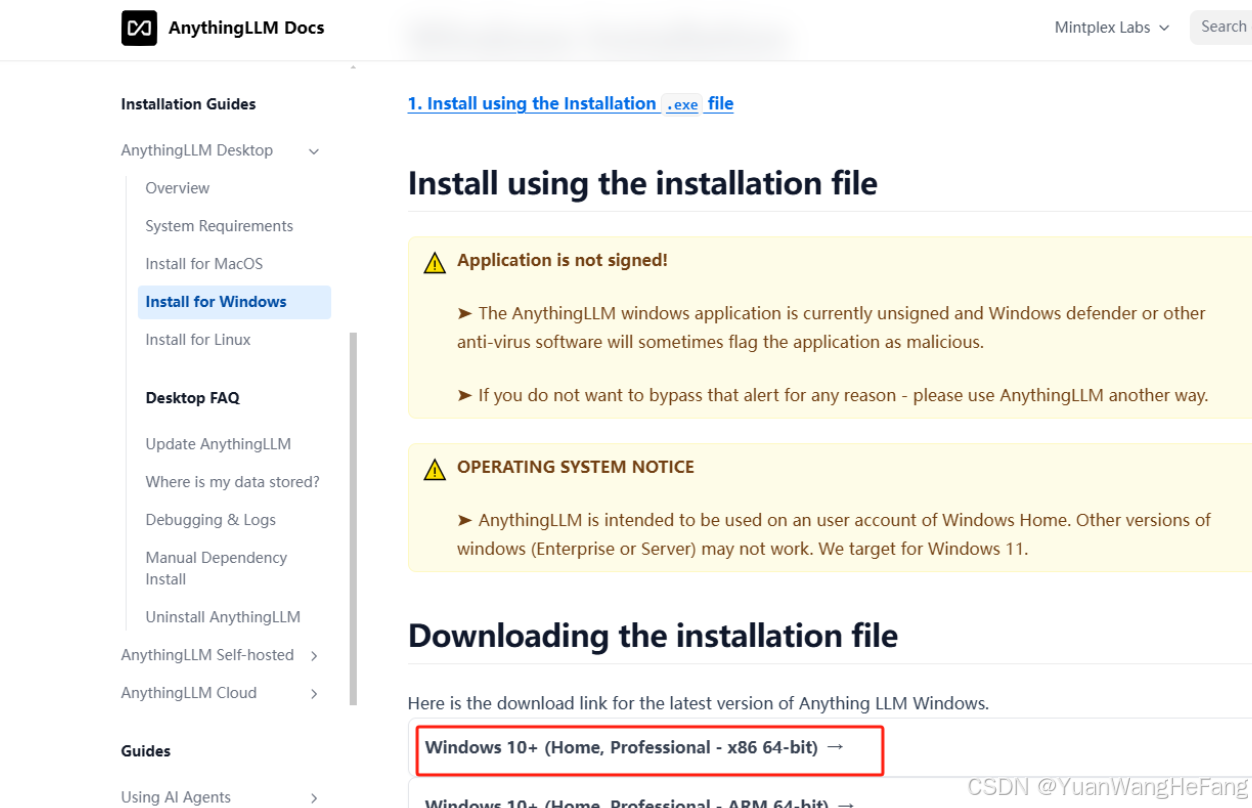
下载下来后可以无脑安装(不多做介绍,可以百度很多相关内容讲解)
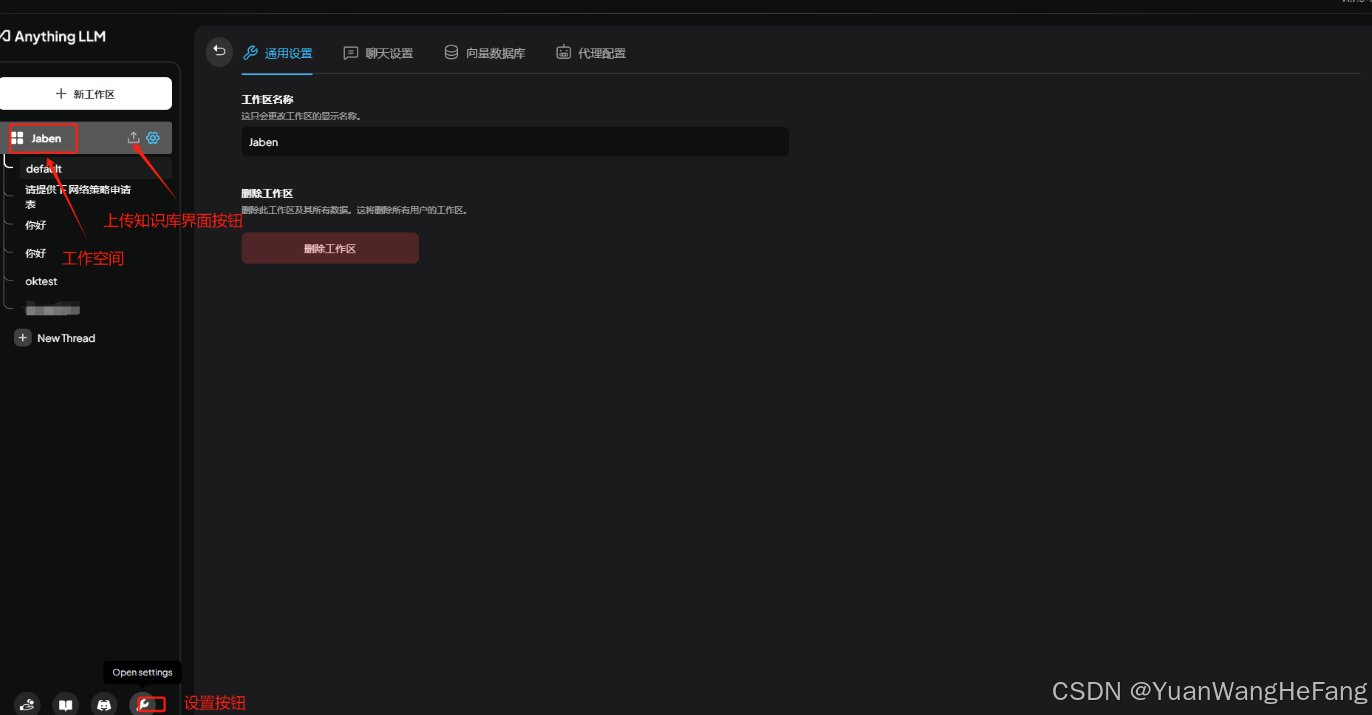
3.1重要项设置
按截图: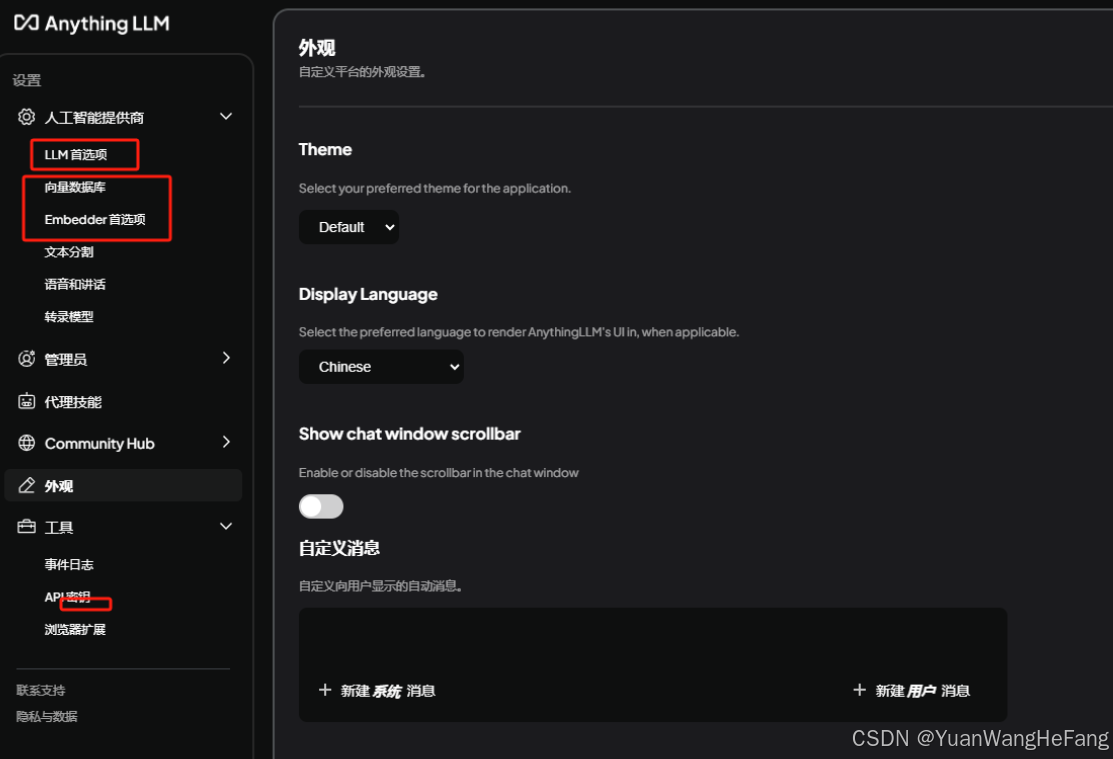
LLM首选项设置: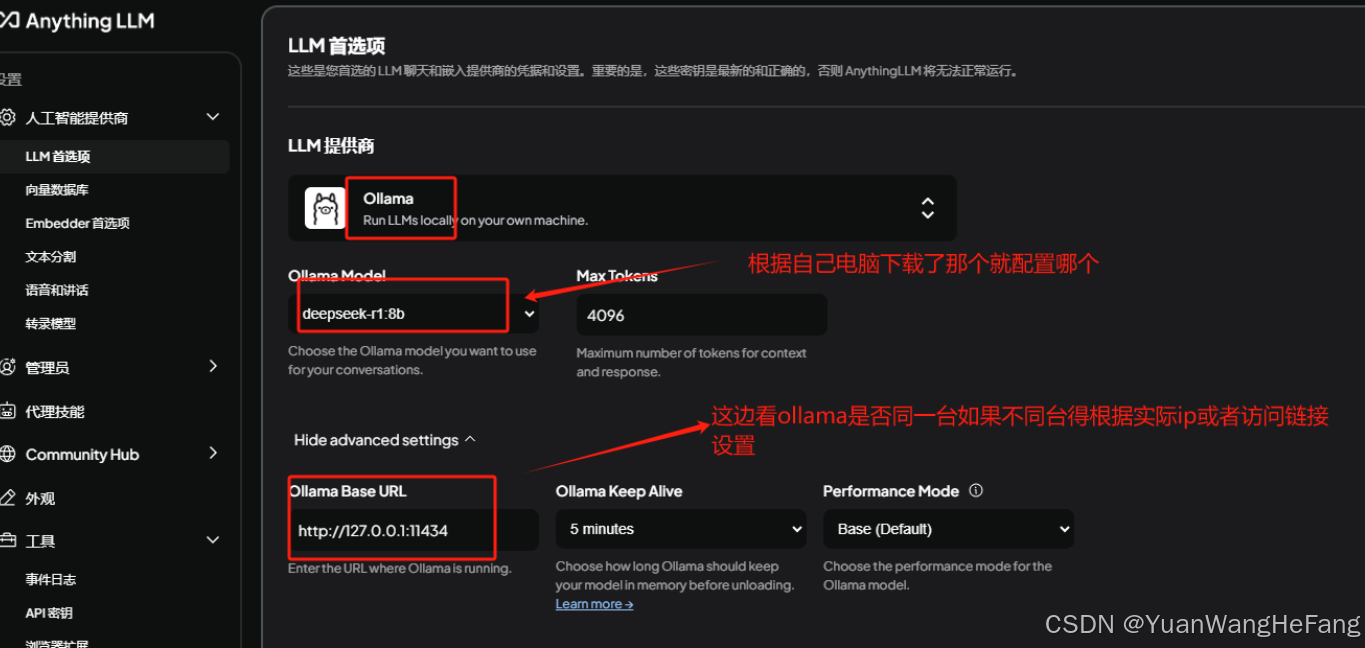
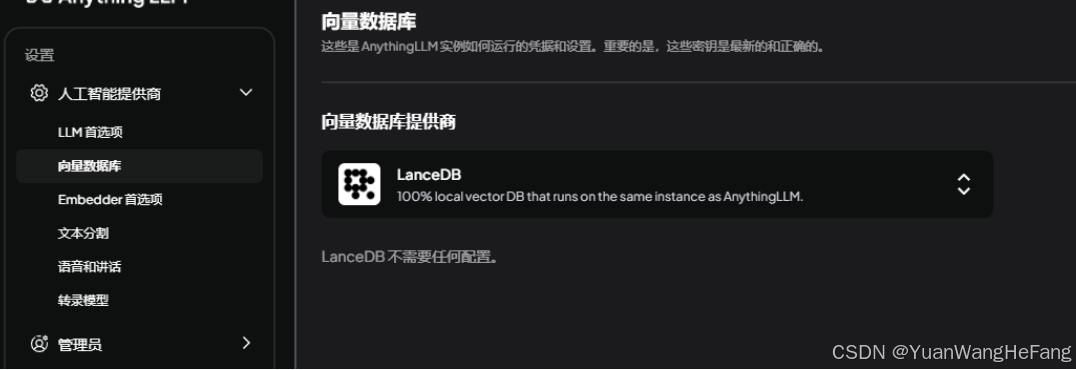
向量数据库提供商设置(默认不动)
Embedder首选项(默认不动,如果有更好的可以尝试修改 有人推荐使用ollama里面的 nomic-embed-text:latest ,我本地是默认的验证的)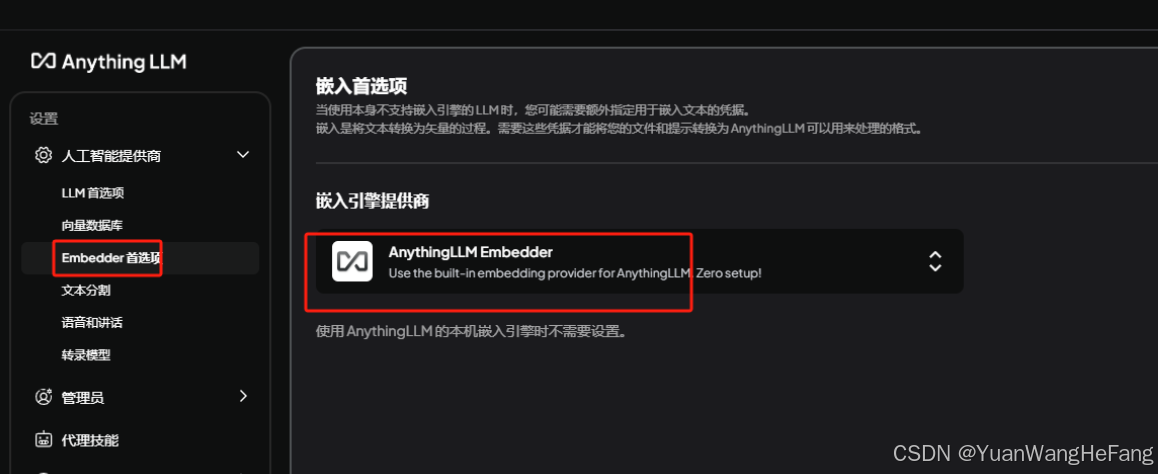
生成api密钥方便后续提供给前端调用共享本地化部署大模型的魅力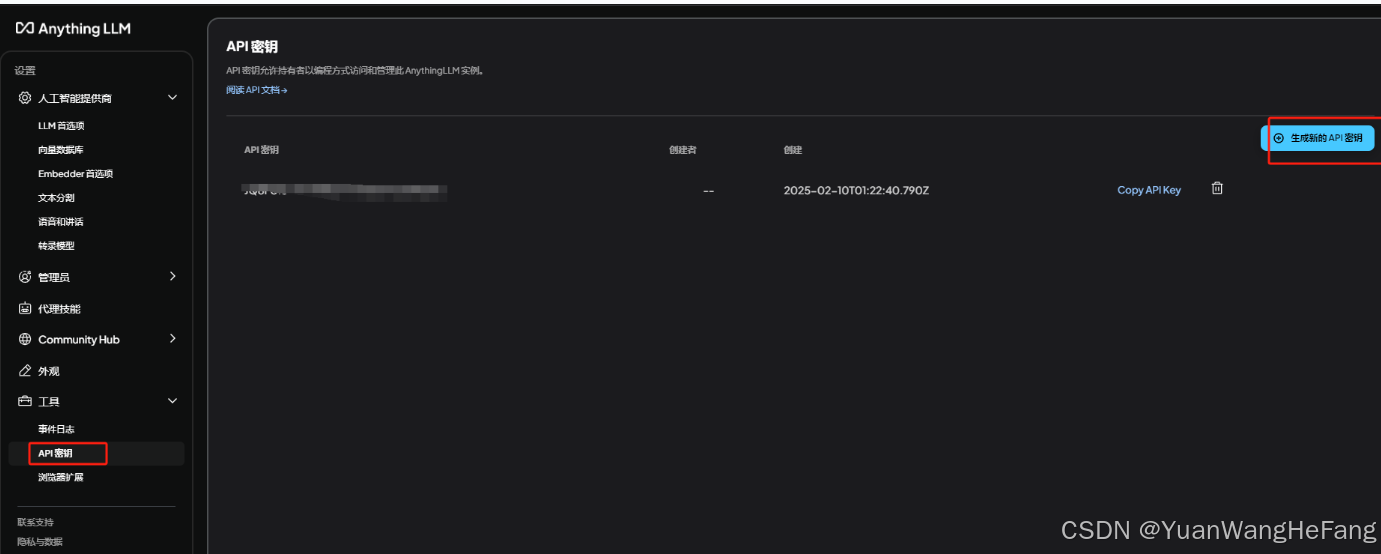
新建工作区 建议不要大写(容易误导后面接口调用就会知道) 这边创建的是Jaben
下面点击 New thread就可以进行对话了
3.2 进入对话界面
以上就已经可以进行通用大模型内容调用共享了
**
4.anythingllm知识库设置
**
如何进行专业知识的训练? 目前看暂时我们局外人暂时适合通过知识库建立私有化数据从而达到我们想要的所谓的训练的结果当然你也可以尝试轻量微调这个我没去试不做过多阐述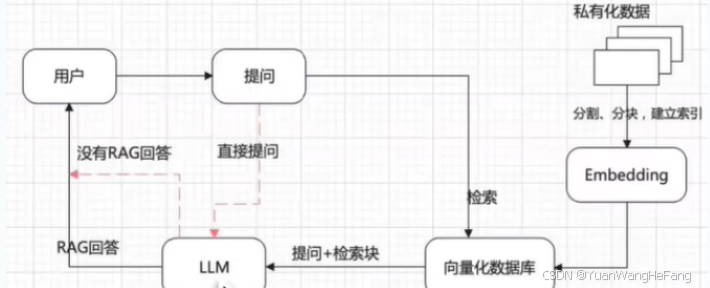
目前构建的本地化部署,都是通过向量化数据库检索那么如何进行数据录入呢?
4.1设置知识库
点击上传
上传文件,后默认选中文件 然后点击 Move To Workspace 上传的知识库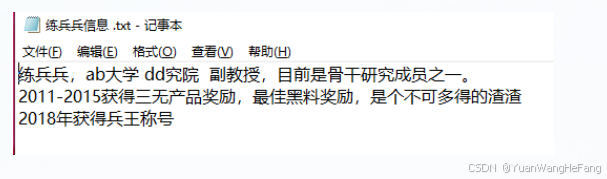
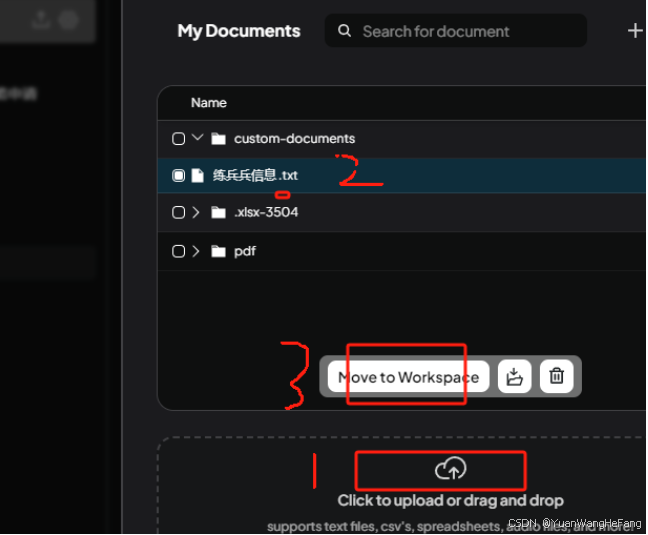
点击 Save and Embed 保存向量化数据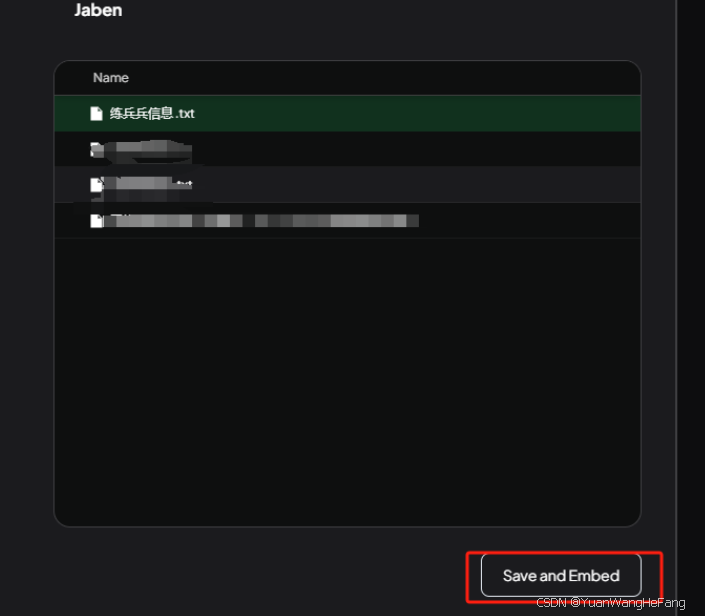
然后返回可以接着问答了: 下面进行 没有知识库前和有只是库后的 对比截图
4.2 设置知识库前后回答对比
知识库录入前回答的结果: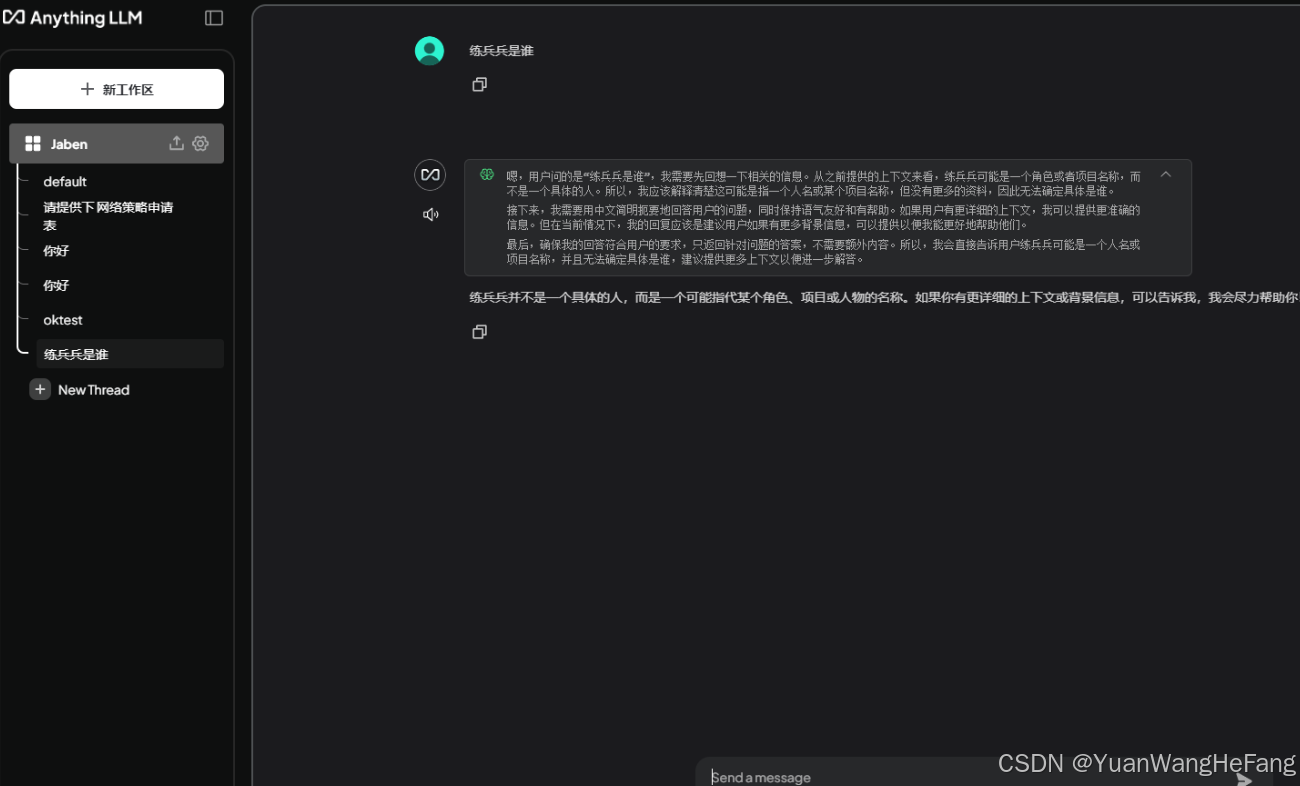
上传信息:
上传后问答结果: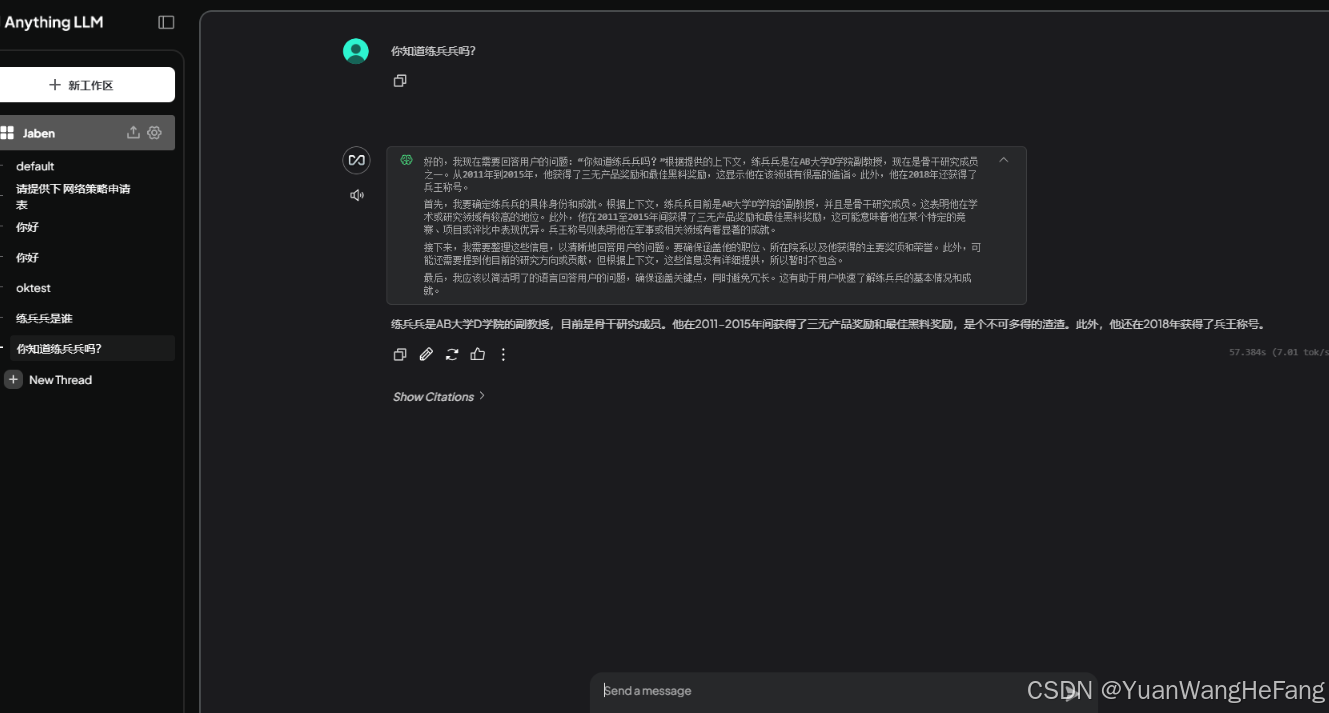
前后对比明显看出,知识库起作用了
鼓掌
**
5.anythingllm接口调用(便于本地化部署后第三方应用调用例如web应用 方便非it部门使用)
**
这边通过 anythinllm的api 测试截图为例子,web应用可以自行搭建开发
首选第三步骤拿到了 apikey后,就可以调用了
5.1进入接口文档
api密钥界面点击 浏览API文档 里面可以直接测试 并且有接口例子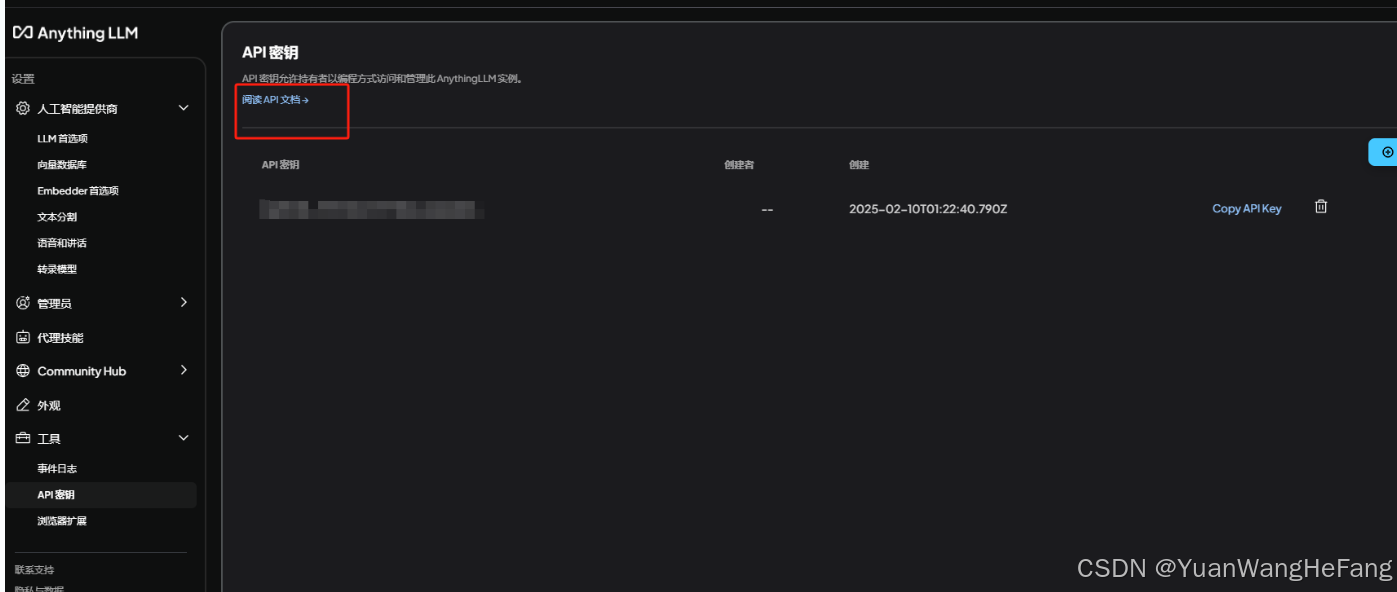
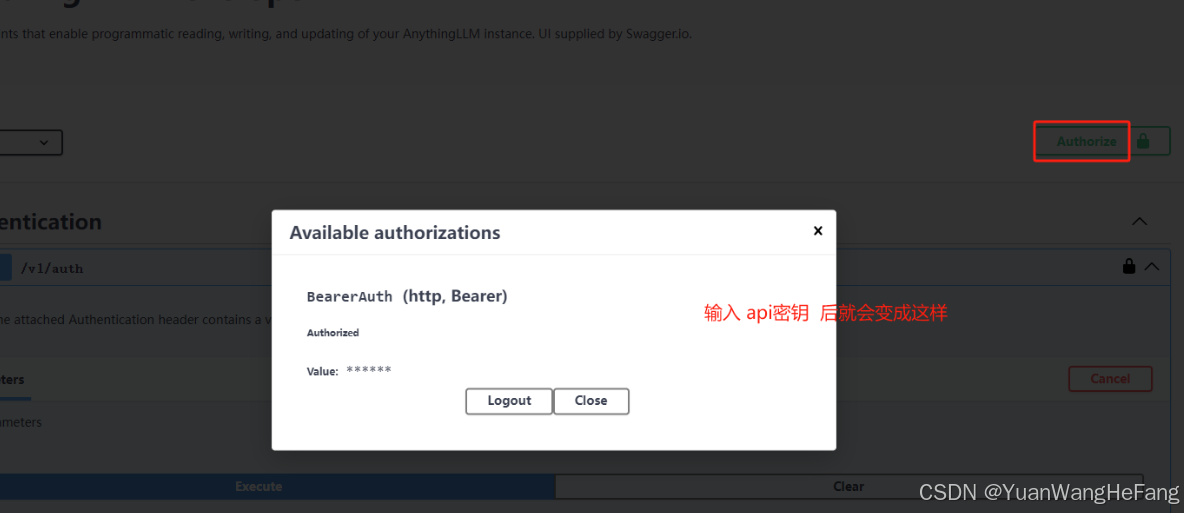
5.2输入密钥(必须填否则后续 无法进行)
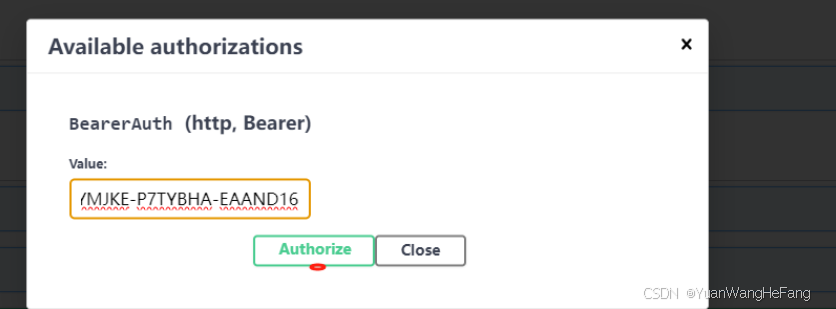
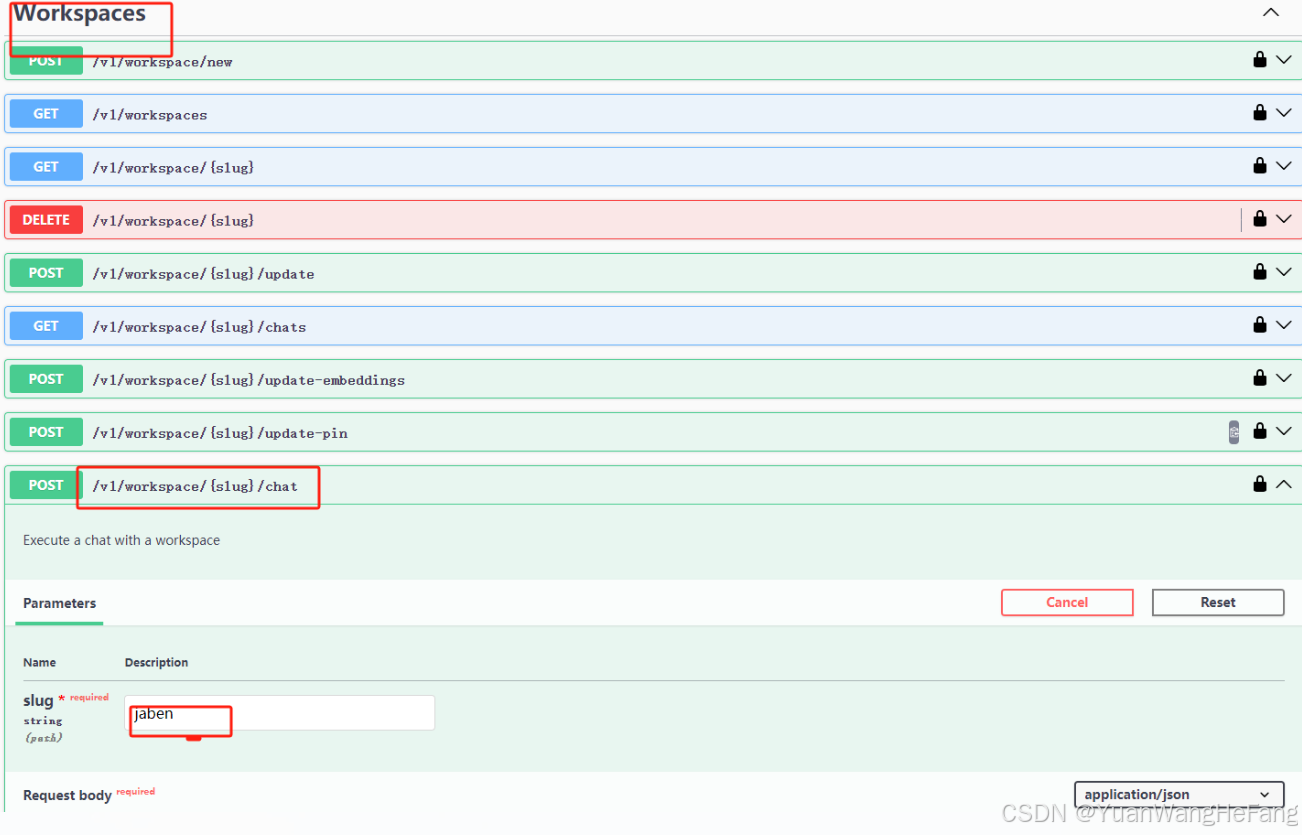
5.3选中对应接口,输入对应参数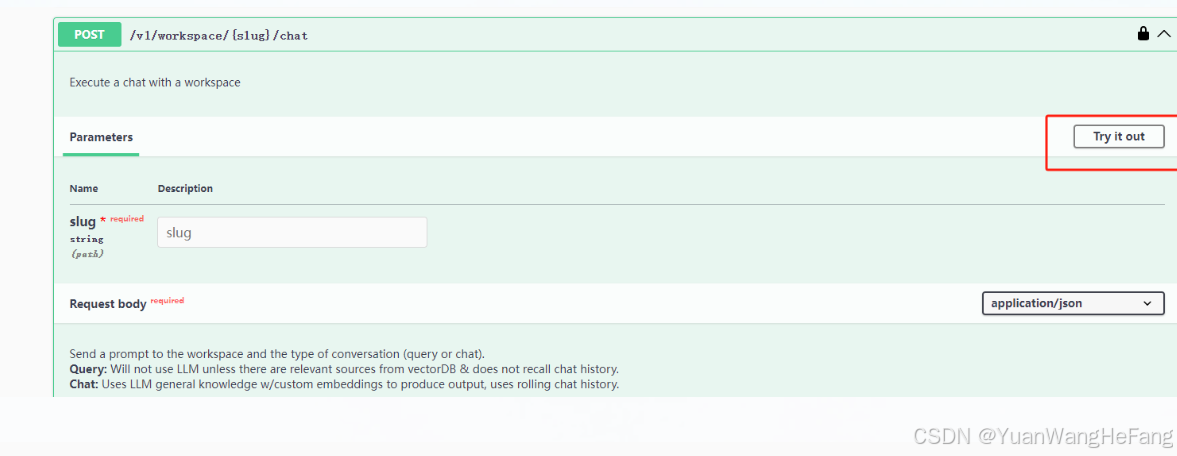
5.4参数输入完后 点击 Execute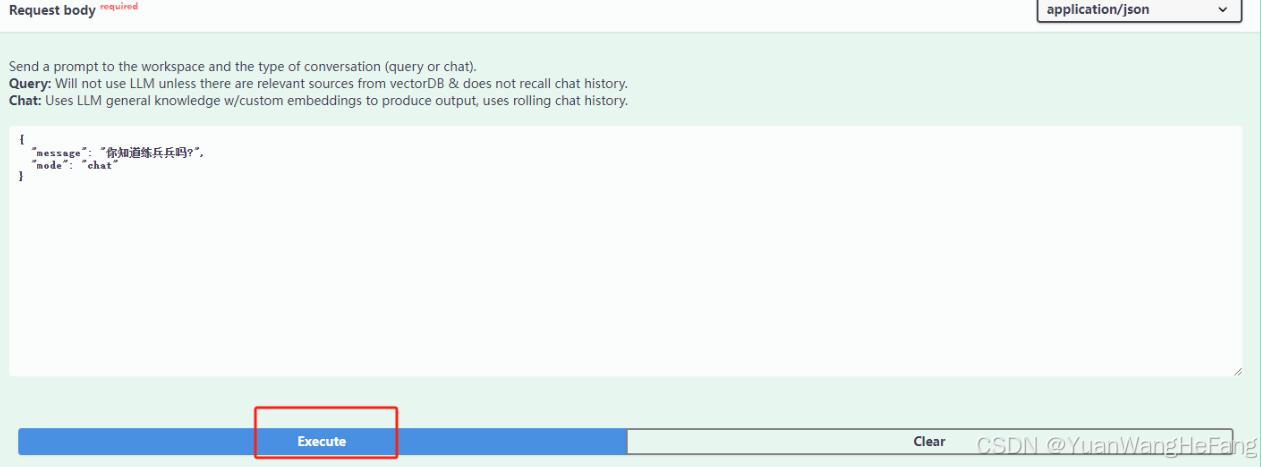
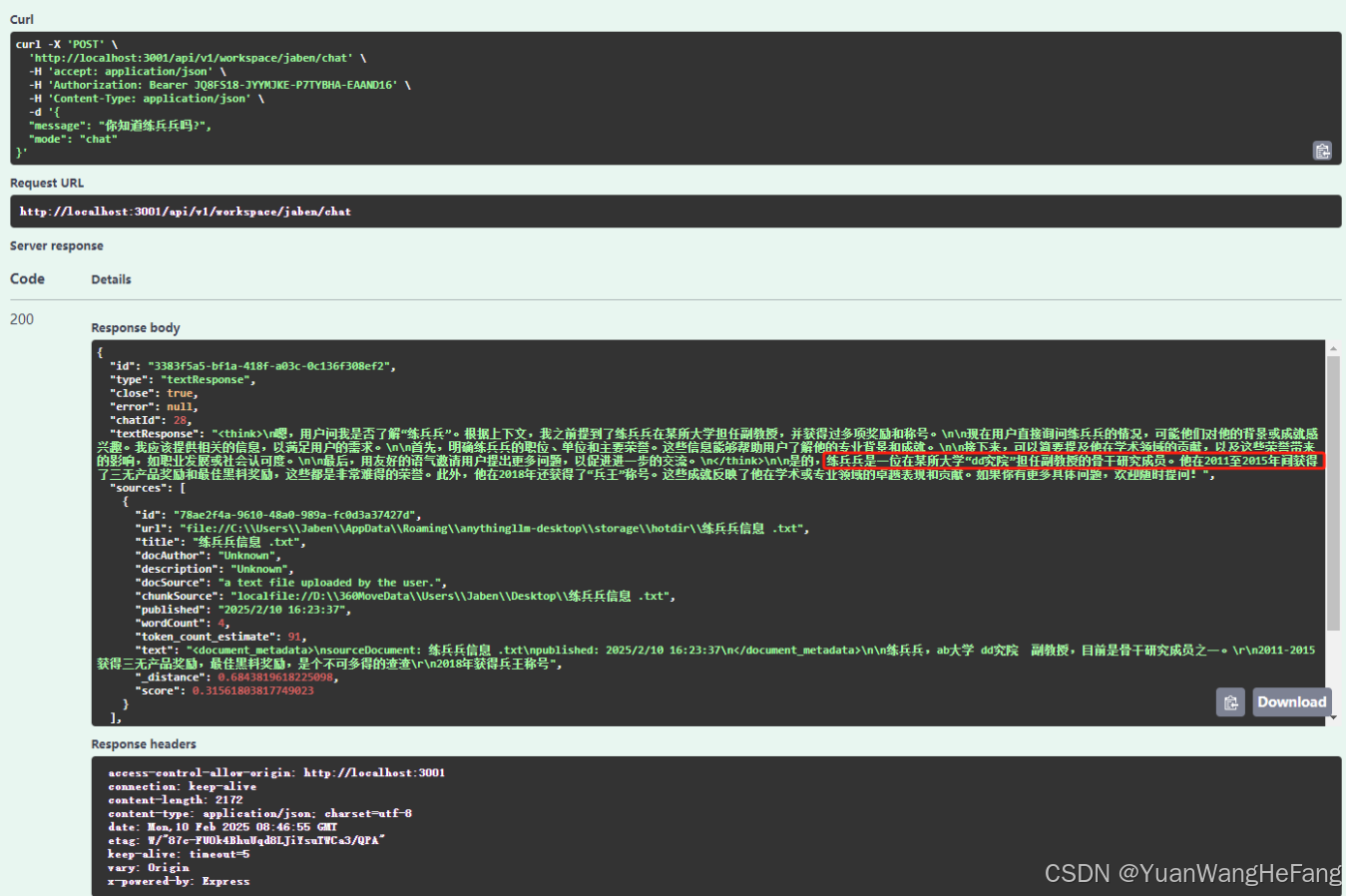
调用结果截图如下:
以下自行研究:
轻量级微调:https://zhuanlan.zhihu.com/p/22420251023
低显卡满血跑模型,比较麻烦:https://github.com/kvcache-ai/ktransformers

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)