DeepSeek,中国AI创业公司的火了
其于2024年12月发布的大语言模型DeepSeek-V3,以550万美元和2000块英伟达H800 GPU(专为中国市场设计的低配版GPU)的投入,训练出了开源模型,在多项评测中超越了Qwen2.5-72B、Llama-3.1-405B等顶级开源模型,甚至与GPT-4o、Claude 3.5-Sonnet等世界顶级闭源模型不相上下,而后者训练成本高达数亿美元和几十万块英伟达H100 GPU。它选

看看世界AI大佬如何评价DeepSeek-V3的
大神卡帕西说:中国的DeepSeek轻而易举的发布了AI大模型
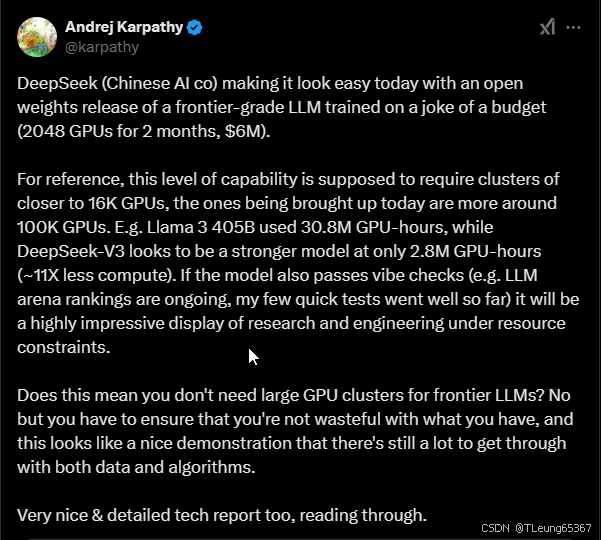

英伟达高级工程师说:他们(DeepSeek)去年就是最好的开放模型之一。
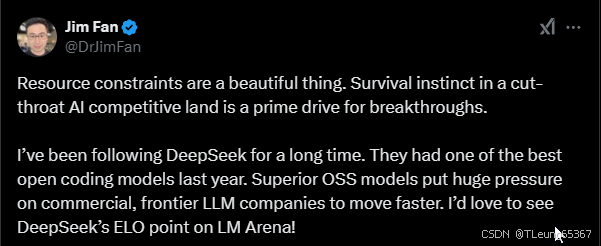

山姆奥特曼都开始阴阳怪气了:
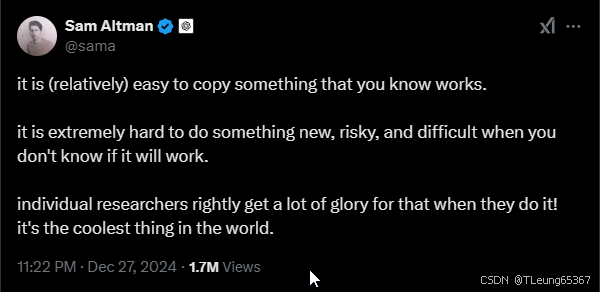

那么DeepSeek-V3到底有没有那么强大?到底强在哪里?

近期,中国杭州的AI创业公司DeepSeek在硅谷引起了广泛关注。其于2024年12月发布的大语言模型DeepSeek-V3,以550万美元和2000块英伟达H800 GPU(专为中国市场设计的低配版GPU)的投入,训练出了开源模型,在多项评测中超越了Qwen2.5-72B、Llama-3.1-405B等顶级开源模型,甚至与GPT-4o、Claude 3.5-Sonnet等世界顶级闭源模型不相上下,而后者训练成本高达数亿美元和几十万块英伟达H100 GPU。
这一成就在AI界掀起了巨大波澜,尤其是在硅谷这个AI领域的研究、创业、资金、算力和资源高度集中的地区。许多硅谷AI界的重要人物纷纷对DeepSeek表示赞赏,如OpenAI联合创始人Andrej Kaparthy和Scale.ai创始人Alexandr Wang。尽管OpenAI CEO Sam Altman曾发推文暗示DeepSeek抄袭借鉴了其他先进成果(很快遭到反驳),但DeepSeek收获的赞誉广泛而真诚,尤其在开源社区,开发者们用行动表达了支持。
许多中国人将DeepSeek-V3视为“国货之光”,认为它代表了中国式创新。中国研究人员和工程师擅长在资源有限的情况下,通过技术创新和精进,实现超预期成果。DeepSeek-V3对高性能算力依赖小,将训练和推理视为一个系统,提供了诸多新技术思路,注重用工程思维高效解决算法和技术问题,集中力量办大事,这确实是中国公司、团队和研究人员的强项。Alexandr Wang总结DeepSeek经验时说:“美国人在休息,中国人在奋斗,以更低的成本、更快的速度和更强大的战斗力追赶。”
有趣的是,一些对中国友好的美国科技界人士,如马斯克,常总结中国在某些领域的成功经验为聪明、勤奋和有方法,这在AI领域却难以解释一个问题:中国其他大模型公司和AI人才同样具备这些品质,技术方法创新也颇有成就,为何未引发如此轰动的世界级效应?至少目前,DeepSeek独占鳌头。
将DeepSeek比作“AI界的拼多多”并不准确,认为其秘方仅是多快好省也不全面。中国多数AI公司因缺卡而努力搞架构创新,DeepSeek在硅谷受关注非一朝一夕之事。早在2024年5月,DeepSeek-V2发布时,其多头潜在注意力机制(MLA)架构创新就在硅谷引起小范围轰动,论文在AI研究界广泛传播和讨论。当时,国内舆论却将其视为“大模型价格战的发起者”,仿佛身处平行时空。
这或许说明,DeepSeek与硅谷有更多对话和交流的“密码”,其秘方颇具硅谷风味。
**DeepSeek与早期OpenAI、DeepMind的相似之处**
若要在全球AI玩家中为DeepSeek找对标,不妨看看2022年之前的OpenAI和DeepMind。那时的OpenAI,尽管被微软投资转型为营利性公司,但工作方式仍具非营利机构性质,无正式对外产品,2020年公布的GPT-3是学术研究成果且开源。DeepMind也类似,无论是独立时期还是被Google收购但未与Google Brain整合前,都更像研究机构,AlphaGo、AlphaFold是研究项目非产品。
DeepSeek有“产品”吗?普通用户可与其模型聊天,它还向开发者售卖低价API,但没有移动APP,不搞运营、流量广告、社交媒体营销或为用户准备prompt模板,仅有个网站供普通人使用。从这点看,DeepSeek不似中国AI公司。在企业与开发者侧,除了架构创新降低成本猛砸API价格,也未见“加速计划”、“开发者大赛”、“产业生态基金”等常见项目,说明其目前无意做生意。
DeepSeek研究人员密度显而易见。量子位对DeepSeek-V3论文作者梳理显示,团队主力是清华、北大、北航等中国顶级高校应届博士毕业生、顶刊论文发表者、信息竞赛获奖者,甚至包括硕博在读生,团队极其年轻。创始人梁文锋透露招人标准:看能力不看经验,核心技术岗位以应届和毕业一两年为主,为研究人员而非产品、市场、工程等岗位定制。这与OpenAI、DeepMind早期人才结构相似:用最年轻、聪明、不受拘束的头脑,创造前人未有成果。
DeepSeek营造的氛围是:聪明年轻人进入看似公司的机构,延续学术生涯,可调动比高校实验室多得多的计算资源和研究数据。科技公司研究机构成科学家“国中之国”,取代高校成学术成果主要贡献者趋势明显。它越不受商业目标干扰,产生颠覆性学术成果机会越大。Google研究人员提出Transformer架构是在2017年AI商业化目标尚不清晰时,近两年鲜有成果。OpenAI的GPT-3和GPT-3.5诞生于聚光灯外,而其越来越像公司时,一切变得混乱。
这也是DeepSeek区别于中国多数AI创业公司、更似研究机构之处。这轮AI创业创始人多是科学家和研究人员,但拿了VC和PE多轮融资后,不能随心所欲搞研究和发paper,需聚焦产品化和商业化(这可能非他们所长)。科技巨头养得起研究机构和科学家,但一旦要求研究成果迅速应用于产品和商业,团队会更复杂,不再有纯研究人员的简单和清澈。美国一些科技巨头有不受商业目标干扰的研究机构,但时间一长,又难免沾染学术界论资排辈气息。由最聪明年轻人组成的商业公司研究机构,只在关键时间点出现过——几年前的OpenAI和DeepMind,以及现在的DeepSeek。
证据是:DeepSeek最好的“产品”除了模型,还有论文。V-2和V-3发布时,两篇对应论文都获全球研究者仔细阅读、分享、引用和推荐。相比之下,GPT-4发布后OpenAI公布的论文几乎不能算论文。如今做模型的都在抢benchmark名次,注重论文质量的已不多。详尽、规范、实验细节丰富的论文,仍能获业界额外尊重。
当然,DeepSeek有钱,有不输于巨头、远多于创业公司的资源。但并非所有巨头都愿有自家DeepMind。
**开源是DeepSeek的制胜法宝**
2023年初,The Information盘点中国可能的人工智能明星创业公司时,智谱、Minimax、百川智能、零一万物和光年之外在列,未提及DeepSeek。至少一年半前,没人真把DeepSeek当AI圈内人。尽管业界流传DeepSeek母公司幻方握有大量英伟达高性能显卡,仍少有人信其下场做大模型会有大动静。如今,DeepSeek成热议焦点,走的是“墙外开花墙内香”老路。
DeepSeek从一开始就选择与国内诸多大模型新秀不同战场。它不融资(至少起初不用),不争大模型座次,不比国内舆论声势(唯一接受暗涌采访,大概为招聘热血聪明科学家),不搞产品投放投流。它选择的是与研究机构本质最匹配的路径——走全球开源社区,分享模型、研究方法和成果,吸引反馈,再迭代优化,自我进益。
开源社区是AI学术研究、分享和讨论最热烈、充分、自由和无国界的地方,也是AI领域最不“内卷”的地方。DeepSeek从一开始就彻底开源,从模型权重、数据集到预训练方法,悉数公开,高质量论文也是开源一部分。年轻聪明研究人员在开源社区亮相、分享和活跃具有高能见度,看见他们的人不乏全球AI领域重要推动者。
聪明年轻AI研究人员+研究机构氛围(配大厂package)+开源社区分享交流,提升DeepSeek全球AI领域影响力和声望。对以产生AI研究成果而非发布商业化产品为主要目标的机构而言,Hugging Face和Reddit是最好的发布会会场,数据集和代码库是最好的demo,论文是最好的新闻稿。DeepSeek基本就是这么做的,且做得讲究。即便研究人员和CEO鲜少接受媒体采访,也几乎不在论坛和活动上分享技术经验和洞察,但不能说它没做营销。反之,以证明中国AI原创研究可引领全球趋势、招聘最聪明研究人员为目的来说,DeepSeek的“营销”极其精准有效。
过去一年,中国开源大模型主要玩家确在全球AI研究和产品方面赢得不少尊敬。越来越普遍的看法是:比起美国和欧洲一些开源模型,中国开源大模型在开源程度上更彻底,易被研究人员和开发者直接上手研究或优化模型。DeepSeek是典型代表,除它外,阿里巴巴的通义(Qwen)也被AI研究领域普遍认为开源态度较真诚,面壁智能的小模型Mini-CPM-Llama3-V 2.5因被斯坦福本科生团队直接套壳也意外走红。
所以有趣的是,国际AI界特别是硅谷认为中国大模型代表玩家是DeepSeek和阿里巴巴,而我们自己觉得是豆包、可灵和所谓AI六小龙。客观地说,就国际AI界特别是硅谷能公正、积极看待中国AI创新能力和对全球社区贡献方面,DeepSeek和阿里巴巴们做得更多。开源在任何时候都是一件正确的事。
**V-3是DeepSeek的“GPT-3时刻”**
V-3模型引发破圈国际反应,CNBC报道已把V-3及其背后的DeepSeek视作中国AI迎头赶上美国的标志。若仔细观察,不难发现:DeepSeek从隐秘低调到备受关注,以及它从Coder到V-3模型的三次迭代,与OpenAI从GPT-1到GPT-3的升级节奏和引发的反响非常接近。
先看OpenAI——
2018年,OpenAI放出GPT-1模型,是其第一个基于Transformer架构的预训练模型,证明了语言模型是有效的预训练目标,但质量和多样性有限,引发一定学界关注,整体反应平常。
2019年早些时候,OpenAI推出GPT-2,生成文本质量和多样性大幅跃迁,基本验证了语言模型这条路的有效性,也引发AI领域广泛讨论和关注。
2020年6月,OpenAI发布GPT-3,以1750亿参数成当时世界最大语言模型,除了生成文本内容,还能进行翻译、问答和持续对话和思考,成生成式人工智能发展里程碑。即便如此,GPT-3仍是实验室项目。
再看DeepSeek——
2023年11月,DeepSeek先后发布两款开源模型DeepSeek Coder和DeepSeek LLM,只有少数人关注,它们在计算效率和可扩展性上遇挑战。
2024年5月,DeepSeek发布V-2,以混合专家模型(MoE)和多头潜在注意力机制(MLA)技术结合,大幅降低模型训练特别是推理成本,且性能可在很多维度与世界顶尖模型相比较,开始引发AI学术界和开发者广泛讨论和推荐,这是DeepSeek走进更多人视野的开始。
2024年12月,DeepSeek发布V-3,以OpenAI、Anthropic和Google百分之一的成本,实现模型性能超越同类开源模型Llama 3.1和Qwen 2.5,媲美闭源模型GPT-4o和Claude 3.5 Sonnet的成绩,引发轰动,成世界大语言模型发展里程碑。
可以说,V-3就是DeepSeek的“GPT-3时刻”,一个里程碑。
当然,DeepSeek与OpenAI在实现里程碑式跃迁进程中区别在于——
OpenAI一直致力于实现计算资源规模与成本的无限扩张,而DeepSeek一直致力用尽可能低成本的计算资源实现更高效率。
OpenAI花两年时间达到GPT-3时刻,而DeepSeek用一年摘得V-3圣杯。
OpenAI在GPT路线上一直聚焦预训练进步,而DeepSeek训练与推理并重,这也是全球模型技术发展趋势要求。
如果V-3真是DeepSeek的GPT-3时刻,那接下来会发生什么?是DeepSeek的GPT-3.5——也就是ChatGPT时刻,或是其他?没人知道,但有趣的事儿应该还在后头。DeepSeek应不会永远是“计算机系Pro”的存在,它也理应为全人类的人工智能事业做出更大贡献。
无论如何,DeepSeek已是中国最全球化的AI公司之一,它赢得全球同行甚至对手尊重的秘方,也是硅谷味儿的。
具体的操作以及个人对其综合和编程的相关测试【点击前往】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)