了解DeepSeek技术概念和术语
DeepSeek是由深度求索公司在2023年7月推出的一款大模型搜索引擎。它旨在通过理解用户意图、上下文以及多模态数据(如文本、图像、视频等),为用户提供更智能的搜索结果和推荐服务。与传统的搜索引擎相比,DeepSeek不再仅仅依赖关键词匹配,而是利用深度学习模型对用户查询进行更深层次的语义理解,从而提供更加精准的搜索结果。此外,DeepSeek还广泛应用于电商、医疗、教育、娱乐等多个领域,展现了
在当今这个科技日新月异的时代,人工智能(AI)技术正以前所未有的速度改变着我们的生活和工作方式。其中,DeepSeek作为一款基于深度学习技术的智能搜索引擎,凭借其强大的自然语言处理(NLP)、计算机视觉(CV)、强化学习(RL)以及多模态融合能力,为用户提供了更加精准、高效和个性化的搜索体验。为了更好地理解DeepSeek的工作原理和应用场景,本文将详细介绍DeepSeek中的几个核心概念和术语,包括输入命中缓存、输入未命中缓存、输出以及Tokens。
一、DeepSeek简介
DeepSeek是由深度求索公司在2023年7月推出的一款大模型搜索引擎。它旨在通过理解用户意图、上下文以及多模态数据(如文本、图像、视频等),为用户提供更智能的搜索结果和推荐服务。与传统的搜索引擎相比,DeepSeek不再仅仅依赖关键词匹配,而是利用深度学习模型对用户查询进行更深层次的语义理解,从而提供更加精准的搜索结果。此外,DeepSeek还广泛应用于电商、医疗、教育、娱乐等多个领域,展现了其强大的应用潜力。
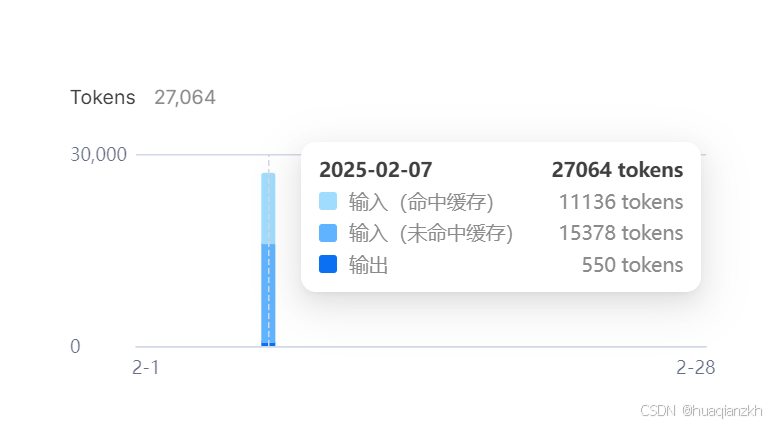
二、输入命中缓存与输入未命中缓存
在DeepSeek的API服务中,输入数据会根据是否命中缓存而被区别对待。理解这两个概念对于优化API使用成本和提升处理速度至关重要。
1. 输入命中缓存
当用户输入的数据与DeepSeek缓存中的数据相匹配时,即称为输入命中缓存。这意味着DeepSeek可以迅速地从缓存中检索出之前已经处理过的结果,而无需重新进行计算。这一机制极大地提高了处理速度,并降低了计算成本。
在实际应用中,输入命中缓存的情况非常普遍。例如,在多轮对话场景中,用户的提问往往具有一定的连续性和重复性。如果DeepSeek能够识别出这些重复的内容,并利用缓存中的结果来快速响应,那么就可以显著提升用户体验。
此外,DeepSeek还采用了上下文硬盘缓存技术,将预计未来会重复使用的内容缓存在分布式的硬盘阵列中。这样一来,即使面对大规模的输入数据,DeepSeek也能够高效地处理并快速返回结果。
2. 输入未命中缓存
与用户输入命中缓存相对的是输入未命中缓存。当用户输入的数据与DeepSeek缓存中的数据不匹配时,即称为输入未命中缓存。此时,DeepSeek需要对输入数据进行全新的处理,以生成相应的结果。
由于输入未命中缓存需要重新进行计算,因此其处理速度相对较慢,且计算成本较高。然而,在实际应用中,输入未命中缓存的情况也是不可避免的。毕竟,用户的输入数据是多种多样的,DeepSeek无法预测到所有的可能性。
尽管如此,DeepSeek仍然通过不断优化算法和提升硬件性能来降低输入未命中缓存的处理成本和时间。同时,DeepSeek还提供了合理的定价策略,以确保用户在使用API时能够获得性价比最高的服务。
三、输出
在DeepSeek中,输出是指模型处理完输入数据后生成的结果。这些结果可以是文本、图像、音频等多种形式,具体取决于所使用的模型和输入数据的类型。
对于文本类型的输出,DeepSeek可以根据用户输入的问题或指令生成相应的回答或建议。例如,当用户询问“地球的半径是多少”时,DeepSeek可以直接返回“6371公里”这一精确答案。这种基于知识图谱和预训练模型的问答系统极大地提高了搜索的效率和准确性。
对于图像或视频类型的输出,DeepSeek则可以利用计算机视觉技术对输入数据进行分析和理解,从而生成相应的搜索结果或推荐内容。例如,当用户上传一张商品图片时,DeepSeek可以识别出商品的类别、品牌等信息,并返回相关的购买链接或类似商品推荐。
值得注意的是,DeepSeek的输出并不是一成不变的。它会根据用户的实时反馈和输入数据的变化而动态调整。例如,如果用户对某个搜索结果不满意或需要更详细的信息,DeepSeek可以根据用户的反馈重新生成更加准确和有用的结果。
四、Tokens概念详解
在DeepSeek中,Tokens是一个非常重要的概念。它是文本数据中最小的处理单元,也是模型输入和输出的基本单位。了解Tokens的概念对于理解DeepSeek的工作原理和优化API使用至关重要。
1. Tokens的定义
Tokens是文本数据经过预处理后得到的最小处理单元。在大语言模型中,它们被用作输入和输出的基本单位。Tokens可以是一个单词、一个字符、一个子词(subword)或是其他任何形式的文本片段。
在DeepSeek中,Tokens的划分通常基于特定的分词策略。这些策略可以根据不同的应用场景和需求进行选择,以确保模型能够准确地理解输入数据并生成有用的输出。
2. Tokens的作用
Tokens在DeepSeek中扮演着至关重要的角色。它们不仅是模型输入和输出的基本单位,还是连接用户查询和模型处理结果的桥梁。
首先,Tokens化的过程将连续的文本序列转换为离散的、可被机器学习模型处理的形式。这使得模型能够准确地理解用户输入的数据,并根据上下文和语义关系生成相应的输出。
其次,Tokens的数量和质量直接影响着模型的性能和准确性。如果Tokens划分不准确或数量过多/过少,都可能导致模型无法正确理解输入数据或生成有用的输出。因此,在选择分词策略和划分Tokens时,需要充分考虑应用场景和需求,以确保模型能够达到最佳的性能。
3. Tokens的计算与定价
在DeepSeek的API服务中,Tokens的数量是计算处理成本和费用的重要依据。不同的输入数据和模型处理结果会产生不同数量的Tokens,因此需要根据实际情况进行精确的计算和定价。
DeepSeek提供了合理的定价策略来确保用户在使用API时能够获得性价比最高的服务。例如,对于输入命中缓存的情况,DeepSeek会给予优惠的定价;而对于输入未命中缓存的情况,则需要根据实际的计算成本和资源消耗进行定价。
此外,DeepSeek还提供了详细的费用计算方式和报告,以帮助用户了解API使用的成本和效益。用户可以根据这些报告来优化查询策略和调整使用方式,以降低处理成本和提升效率。
总结
DeepSeek作为一款基于深度学习技术的智能搜索引擎,凭借其强大的自然语言处理、计算机视觉、强化学习以及多模态融合能力,为用户提供了更加精准、高效和个性化的搜索体验。通过了解DeepSeek中的输入命中缓存、输入未命中缓存、输出以及Tokens等核心概念和术语,我们可以更好地理解其工作原理和应用场景,并优化API使用成本和提升处理速度。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)