DeepSeek-R1 技术报告解读
打个小广告 ☻,知乎专栏的内容已经收录在新书中。感兴趣的朋友可以购买,多谢支持!♥♥2025年01月20日,deepseek 正式发布 DeepSeek-R1,并同步开源模型权重。模型开源的同时,技术报告也同步放出:下面,我们就来解读下这篇论文。
打个小广告 ☻,知乎专栏《大模型前沿应用》的内容已经收录在新书《揭秘大模型:从原理到实战》中。感兴趣的朋友可以购买,多谢支持!♥♥
2025年01月20日,deepseek 正式发布 DeepSeek-R1,并同步开源模型权重。
- 开源 DeepSeek-R1 推理大模型,与 o1 性能相近。
- 开源 DeepSeek-R1-Zero,预训练模型直接 RL,不走 SFT。
- 开源用 R1 数据蒸馏的 Qwen、Llama 系列小模型,蒸馏模型超过 o1-mini 和 QWQ。
模型开源的同时,技术报告也同步放出: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs viaReinforcement Learning
下面,我们就来解读下这篇论文。
背景
研究问题:如何通过强化学习(RL)有效提升大型语言模型(LLM)的推理能力?
问题背景:
- 近年来,LLM 在各个领域都取得了显著进展,但推理能力仍有提升空间。
- 之前的研究大多依赖于大量的 SFT 数据,但获取高质量的 SFT 数据成本高昂。
- OpenAI 的 o1 系列模型通过增加思维链(Chain-of-Thought, CoT)推理过程的长度来提升推理能力,但如何有效进行测试时(test-time)扩展仍是开放问题。
- 一些研究尝试使用基于过程的奖励模型(PRM)、强化学习和搜索算法(MCTS)来解决推理问题,但没有达到 OpenAI 的 o1 系列模型的通用推理性能水平。
论文动机: 探索是否可以通过纯强化学习来让 LLM 自主发展推理能力,而无需依赖 SFT 数据。
相关研究
- SFT:之前的研究通常依赖 SFT 来增强模型性能。然而,SFT 需要大量标注数据,成本高且耗时。
- 推理时扩展:OpenAI 的 o1 系列模型通过增加 CoT 推理长度来实现推理能力扩展,但测试时扩展的挑战仍然存在。
- 基于过程的奖励模型(PRM):一些研究采用过程奖励模型来引导模型进行推理。然而,这些模型在实际应用中存在局限性。
- 强化学习:强化学习已被用于提升推理能力,但通常与 SFT 数据结合使用,难以探索纯 RL 的潜力。
- 搜索算法:如蒙特卡洛树搜索(MCTS)等算法也被用于增强推理,但效果有限。
主要贡献
| 模型 | 方法 |
|---|---|
| DeepSeek-R1-Zero | 纯强化学习 |
| DeepSeek-R1 | 冷启动 SFT -> RL -> COT + 通用数据 SFT(80w)->全场景 RL |
| 蒸馏小模型 | 直接用上面的 80w 数据进行SFT |
- 首次验证了纯强化学习在 LLM 中显著增强推理能力的可行性(DeepSeek-R1-Zero),即无需预先的 SFT 数据,仅通过 RL 即可激励模型学会长链推理和反思等能力。
- 提出了多阶段训练策略(冷启动->RL->SFT->全场景 RL),有效兼顾准确率与可读性,产出 DeepSeek-R1,性能比肩 OpenAI-o1-1217。
- 展示了知识蒸馏在提升小模型推理能力方面的潜力,并开源多个大小不一的蒸馏模型(1.5B~70B),为社区提供了可在低资源环境中也能获得高推理能力的模型选择。
DeepSeek-R1-Zero
DeepSeek-R1-Zero 直接在基础模型上应用强化学习,不使用任何 SFT 数据。 为了训练 DeepSeek-R1-Zero,deepseek 采用了一种基于规则的奖励系统,该系统主要由两种奖励组成:
- 准确率奖励:准确率奖励模型评估响应是否正确。例如,在具有确定性结果的数学问题中,模型需要以指定的格式(box)提供最终答案,从而能够通过基于规则的验证来可靠地确认正确性。同样,对于 LeetCode 问题,可以使用编译器根据预定义的测试用例生成反馈。
- 格式奖励: 除了准确性奖励模型,还采用了一种格式奖励模型,要求模型将其思考过程放在 ‘’ 和 ‘’ 标签之间。
需要强调的是:deepseek 在训练 DeepSeek-R1-Zero 时没有使用结果奖励(ORM)或者过程奖励(PRM)。
在没有大量带「过程标签」(step-by-step annotation)的数据支撑下,模型如何知道自己的推理过程是否正确?
这里主要通过「结果判定」的方式:对于数学题、编程题等有客观正确答案的任务,可以把最终答案与标准结果对比给出奖励。虽没有逐步的过程标注,但最终答案正确与否足以在 RL 中当作回报(Reward)来引导模型学会更好的推理。
部分中间也会酌情使用格式奖励,用来约束模型输出思考过程,这是一种「作弊少、易维护」的思路。
DeepSeek-R1-Zero 性能
下图展示了 DeepSeek-R1-Zero 在 AIME 2024 基准测试中的强化学习(RL)训练性能轨迹。随着 RL 训练的持续推进,DeepSeek-R1-Zero 的性能呈现出稳步提升的趋势。尤为引人注目的是,其 AIME 2024 的 pass@1 分数实现了显著飞跃,从最初的 15.6% 飙升至 **71.0%**,达到了与 OpenAI-o1-0912 相媲美的性能水平。
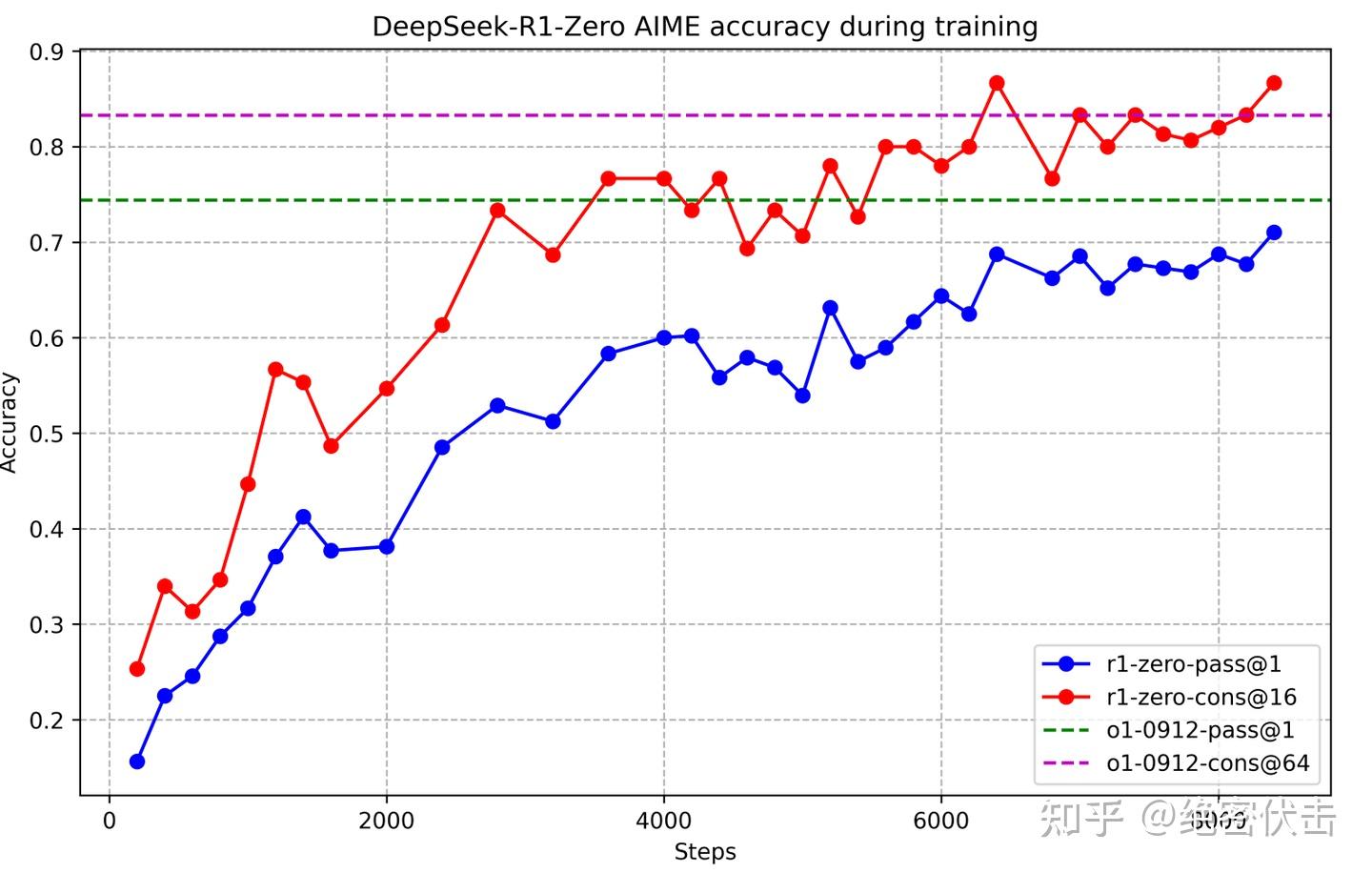
图1: DeepSeek-R1-Zero 训练期间 AIME 准确率
DeepSeek-R1-Zero 的自我演化过程
DeepSeek-R1-Zero 的自我演化过程生动地展现了强化学习(RL)如何自主推动模型提升推理能力。从基座模型直接开始 RL 训练,绕过了 SFT 阶段,从而能够紧密跟踪模型的成长轨迹。这种方法为我们提供了模型随时间推移不断演进的清晰视角,尤其是其在处理复杂推理任务方面的能力提升。
如下图所示,通过延长测试时间的计算,DeepSeek-R1-Zero 自然而然地获得了解决更复杂推理任务的能力,从生成数百个 token 到数千个 token,模型得以更深入地探索和优化其思维过程。
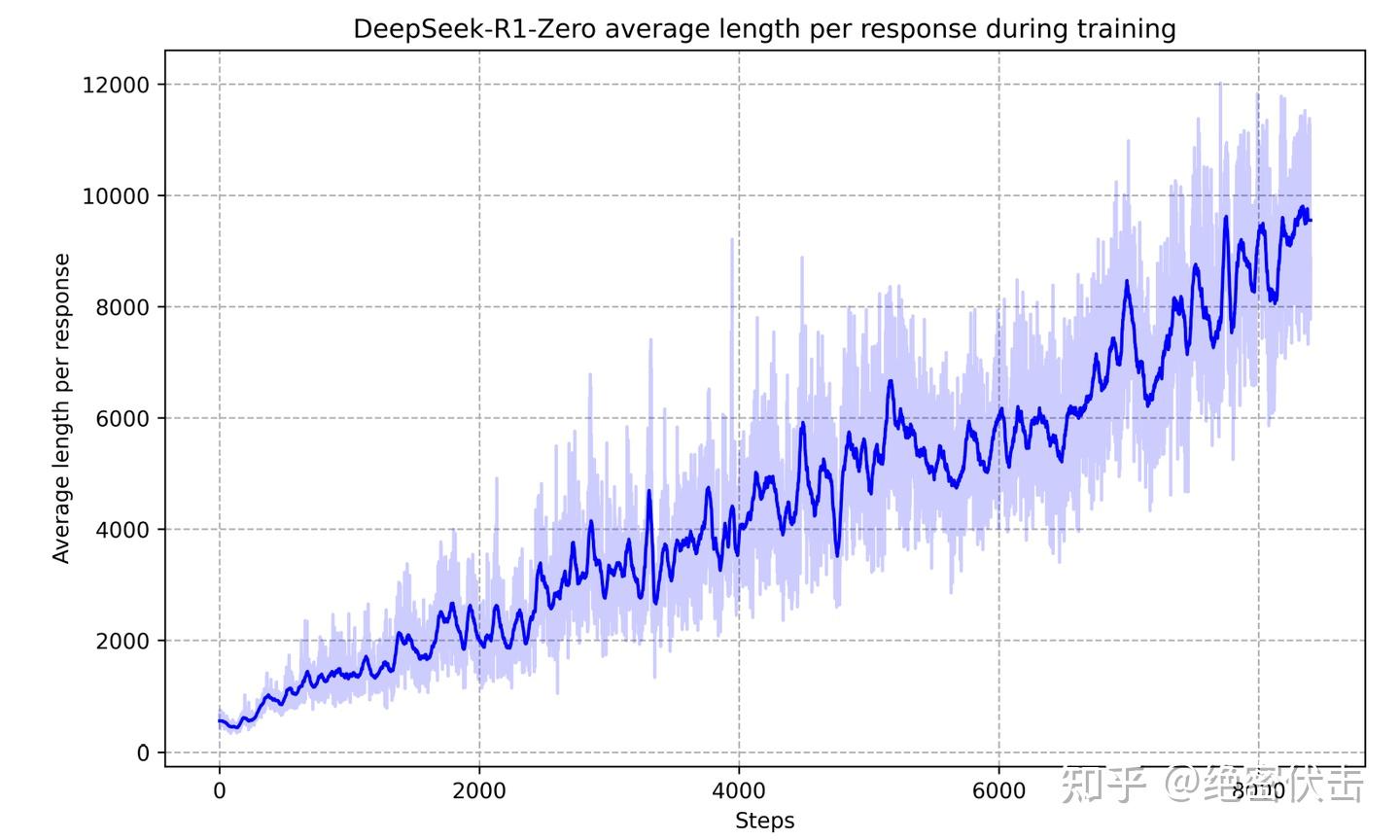
图2: DeepSeek-R1-Zero 在 RL 过程中的平均响应长度(输出长度不断增加)
DeepSeek-R1-Zero 的 “顿悟” 时刻
在 DeepSeek-R1-Zero 的训练历程中,出现了一个特别引人注目的现象——“顿悟时刻”(aha moment)。如下图所示,这一关键时刻发生在模型的中间发展阶段。在这个阶段,DeepSeek-R1-Zero 通过重新审视其初始策略,学会了为问题分配更多思考时间。这一行为不仅彰显了模型推理能力的显著提升,也是强化学习如何催生意外且复杂成果的一个生动例证。
在大规模强化学习中,模型的「思考过程」会不断与最终的正确率奖励相互作用。当模型最初得出的答案并未得到较高奖励时,它会在后续的推理中「回头反省」,尝试补充或修正先前的思路,从而获得更高的奖励。随着强化学习的迭代,这种「主动回溯、推翻先前想法并重新推理」的行为逐渐巩固,便在输出中表现为所谓的「aha moment」。本质上,这是 RL 为模型「留出了」足够的思考和试错空间,当模型自行发现更优思路时,就会出现类似人类「恍然大悟」的瞬间。
这也展示了 RL 的强大潜力,它可以让模型在没有明确指导的情况下,自主学习并改进。

图3: DeepSeek-R1-Zero 的“顿悟时刻”。模型学会了用拟人化的语气重新思考。
DeepSeek-R1: 冷启动强化学习
DeepSeek-R1 使用了冷启动 + 多阶段训练的方式:
- 阶段1:使用少量高质量的 CoT 数据进行冷启动,预热模型。
- 阶段2:进行面向推理的强化学习,提升模型在推理任务上的性能。
- 阶段3:使用拒绝采样和监督微调,进一步提升模型的综合能力。
- 阶段4:再次进行强化学习,使模型在所有场景下都表现良好。
DeepSeek-R1 使用冷启动数据的主要目的是为了解决 DeepSeek-R1-Zero 在训练早期出现的训练不稳定问题。相比于直接在基础模型上进行 RL,使用少量的 SFT 数据进行冷启动,可以让模型更快地进入稳定训练阶段:
- 可读性:冷启动数据使用更易于理解的格式,输出内容更适合人类阅读,避免了 DeepSeek-R1-Zero 输出的语言混合、格式混乱等问题。
- 潜在性能:通过精心设计冷启动数据的模式,可以引导模型产生更好的推理能力。
- 稳定训练:使用 SFT 数据作为起始点,可以避免 RL 训练早期阶段的不稳定问题。
阶段1: 冷启动
冷启动阶段使用少量高质量的 CoT 数据对基础模型进行微调,作为 RL 训练的初始起点。侧重点是让模型掌握基本的 CoT 推理能力,并使模型的输出更具可读性。
为了获取这些数据,deepseek 探索了几种策略:利用长思维回答作为 few-shot 示例,直接提示模型生成包含反思和验证步骤的详细答案,以及收集 DeepSeek-R1-Zero 的输出并通过人工标注者进行细化。最终收集了数千条冷启动数据,用以微调 DeepSeek-V3-Base 作为 RL 训练的起点。DeepSeek-R1 创建的冷启动数据采用了一种可读模式,明确将输出格式定义为:|special_token|<reasoning_process>|special_token<summary>。
阶段2: 推理导向的强化学习
在冷启动模型的基础上进行 RL 训练,侧重点是提升模型在推理任务上的性能。在这个阶段,会引入语言一致性奖励,该奖励根据思维链(CoT)中目标语言单词的比例来计算,以减少推理过程中的语言混合问题。
尽管消融实验表明,语言一致性奖励会导致模型性能略有下降,但它更符合人类的偏好,提高了内容的可读性。最终,通过将推理任务的准确性与语言一致性奖励直接相加,形成了综合的奖励函数。随后,对微调后的模型进行了强化学习(RL)训练,直至其在推理任务上达到收敛。
阶段3: 拒绝采样和 SFT
使用上一阶段的 RL 模型进行拒绝采样,生成高质量的推理和非推理数据,并用这些数据对模型进行微调。侧重点是提升模型的综合能力,使其在写作、事实问答等多种任务上表现良好。
当 RL 训练接近收敛时,使用中间的 checkpoint 来采样监督微调(SFT)数据。与初期主要关注推理能力的冷启动数据不同,这一阶段加入了其他领域的数据,旨在增强模型在写作、角色扮演以及其他通用任务上的表现。具体的数据生成和模型微调步骤如下:
- 对于推理数据,构建推理 prompt,并从上述 RL 训练的 checkpoint 中进行拒绝采样,以生成推理轨迹。在之前的阶段,仅使用了基于规则的奖励来评估数据。然而,在这个阶段,通过添加其他数据来丰富数据集,其中部分数据使用了生成奖励模型,通过将真实值和模型预测输入 DeepSeek-V3 进行判断。同时,为了提升数据质量,过滤掉混合语言、长段落和代码块的思维链。对于每个提示,采样多个响应,并仅保留正确的响应。最终,收集了大约60万个与推理相关的训练样本。
- 对于非推理数据,如写作、问答、翻译等任务,使用 DeepSeek-V3 SFT 数据集的一部分。对于简单的 query,如“你好”,不使用思维链作为回答。经过筛选和整理,最终收集了大约20万个与推理无关的训练样本。
最终,使用大约80万个样本(60w推理+20w通用)对 DeepSeek-v3-Base 模型进行了两轮的 SFT。
阶段4: 所有场景下的强化学习
在上一阶段 SFT 模型的基础上进行 RL 训练,侧重点是使模型在所有场景下都能表现良好,包括推理任务和非推理任务,并且保证模型的安全性和无害性。
蒸馏小模型
为了获得更高效的小模型,并使其具有 DeekSeek-R1 的推理能力,直接对 Qwen 和 Llama 等开源模型进行了微调,使用的是上面 SFT DeepSeek-R1 的80万数据。研究结果表明,这种直接蒸馏方法显著提高了小模型的推理能力。在这里使用的基座模型是 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。
对于蒸馏模型,只进行 SFT,不包括 RL 阶段,尽管加入 RL 可以显著提高模型性能。
为什么在蒸馏到小模型时,直接用 RL 在小模型上训练不如先做大模型再蒸馏?
大模型在 RL 阶段可能出现许多高阶推理模式。而小模型因为容量和表示能力有限,很难在无监督或纯 RL 情境下学到相似水平的推理模式。
蒸馏可将「大模型的推理轨迹」直接转移给小模型,小模型只需要模仿大模型相对完备的推理流程,可以在较小训练/推理开销下取得远胜于自身独立强化学习的效果。
在蒸馏模型的实现中,仅采用了 SFT 阶段,而未包含 RL 阶段,尽管 RL 的加入能显著提升模型性能。按照 deepseek 的说法,本工作的核心目的在于展示蒸馏技术的有效性,而将 RL 阶段的深入探索留给更广泛的研究社群去完成。
为什么PRM和MCTS没有成功?
论文中提到,基于过程奖励模型(PRM)和蒙特卡洛树搜索(MCTS)并不适合 LLM 的推理。
PRM 的挑战
- 难以定义通用的、细粒度的推理步骤。
- 难以准确判断中间步骤的正确性,且自动标注方法效果不佳,人工标注又难以扩展。
- 模型化的 PRM 容易导致奖励黑客(Agent 利用奖励函数或环境中的漏洞来获取高奖励,而并未真正学习到预期行为。)行为,并且会增加额外的训练成本。
MCTS 的挑战
- LLM 的 token 生成搜索空间巨大,远远超出棋类游戏,容易陷入局部最优解。
- 价值模型的训练非常困难,导致难以迭代提升。
实验
实验设置
基准测试:论文在多种数学推理(AIME 2024、MATH-500)、代码题(LiveCodeBench、Codeforces)、知识问答(MMLU、GPQA Diamond、SimpleQA)和开放生成场景(AlpacaEval2.0、ArenaHard)等上进行了系统评测。对于蒸馏模型,测试了在 AIME 2024、MATH-500、GPQA Diamond、Codeforces 和 LiveCodeBench 上的结果。
DeepSeek-R1的输出对每个基准限制在32,768个标记内。
对比模型:评估了 DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini 和 OpenAI-o1-1217 等模型。
实验设置:所有模型的最大生成长度设置为 32k。temperature=0.6,top-p=0.95,每次生成64回答以估计pass@1。
DeepSeek-R1 评估
- 教育知识基准性能卓越:DeepSeek-R1 在 MMLU、MMLU-Pro 和 GPQA Diamond 等教育知识基准上相比 DeepSeek-V3 显示出卓越性能。
- IF-Eval基准结果令人印象深刻:DeepSeek-R1 在 IF-Eval 基准上取得令人印象深刻的结果,该基准评估模型遵循格式指令的能力。改进归因于 SFT 和 RL 训练最后阶段包含的指令遵循数据。
- 摘要简洁,避免长度偏差:DeepSeek-R1 生成的摘要简洁,在 ArenaHard 和 AlpacaEval 2.0 上长度分别为 689 个 token 和 2,218 个字符。
- 数学推理和OpenAI-o1-1217持平:DeepSeek-R1 在数学任务上的性能与 OpenAI-o1-1217 相当,远超其他模型。
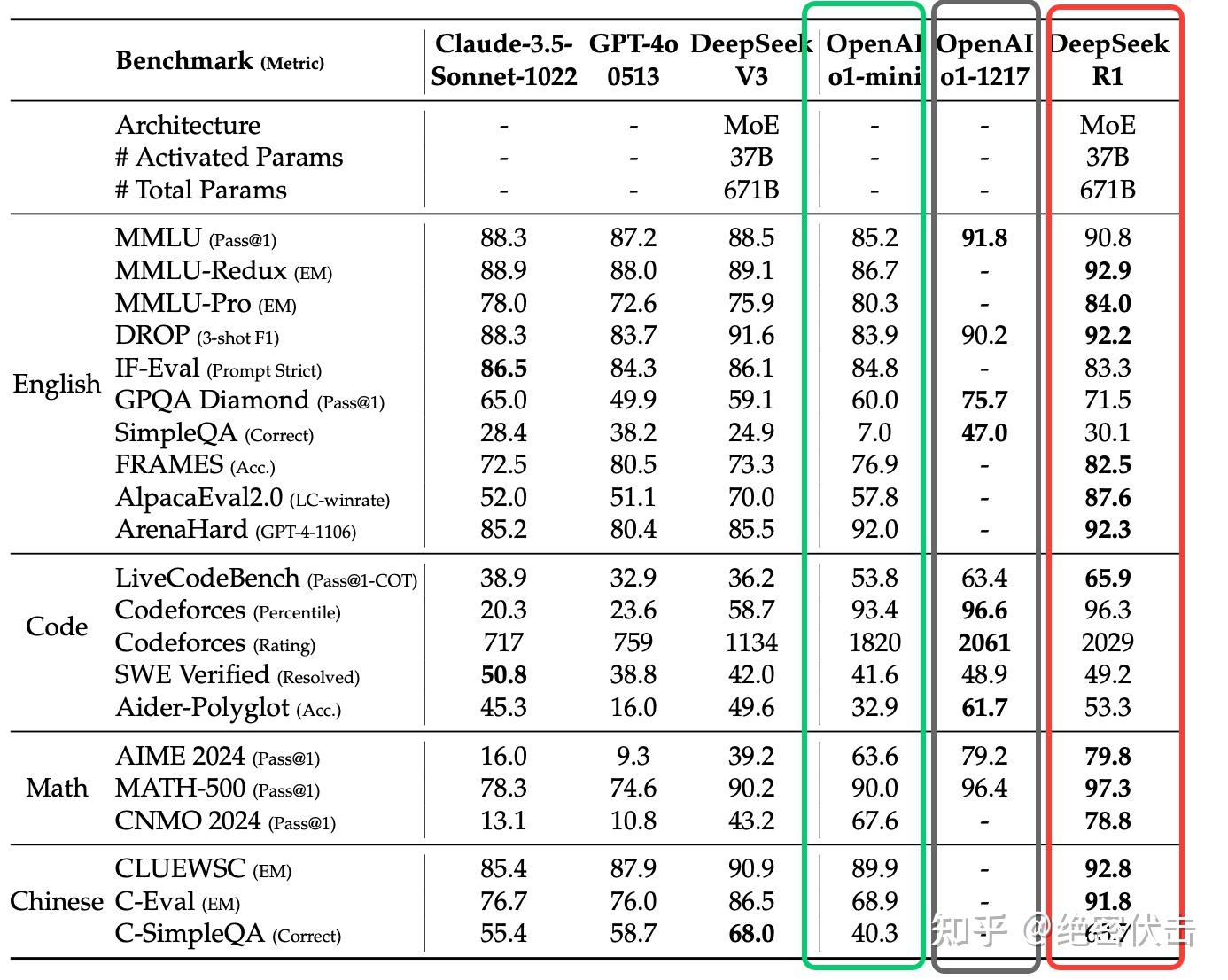
图4: DeepSeek-R1实验结果
蒸馏模型评估
- 通过简单蒸馏 DeepSeek-R1 的输出,得到 DeepSeek-R1-Distill-Qwen-7B,其在所有方面均优于非推理模型 GPT-4o-0513。
- DeepSeek-R1-14B 在所有评估指标上均超越了 QwQ-32BPreview。
- DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多数基准测试中均显著优于 o1-mini。
此外,将强化学习(RL)应用于这些蒸馏模型能够带来显著的额外提升,这一方向值得进一步探索。deepseek 仅展示了蒸馏模型的结果。
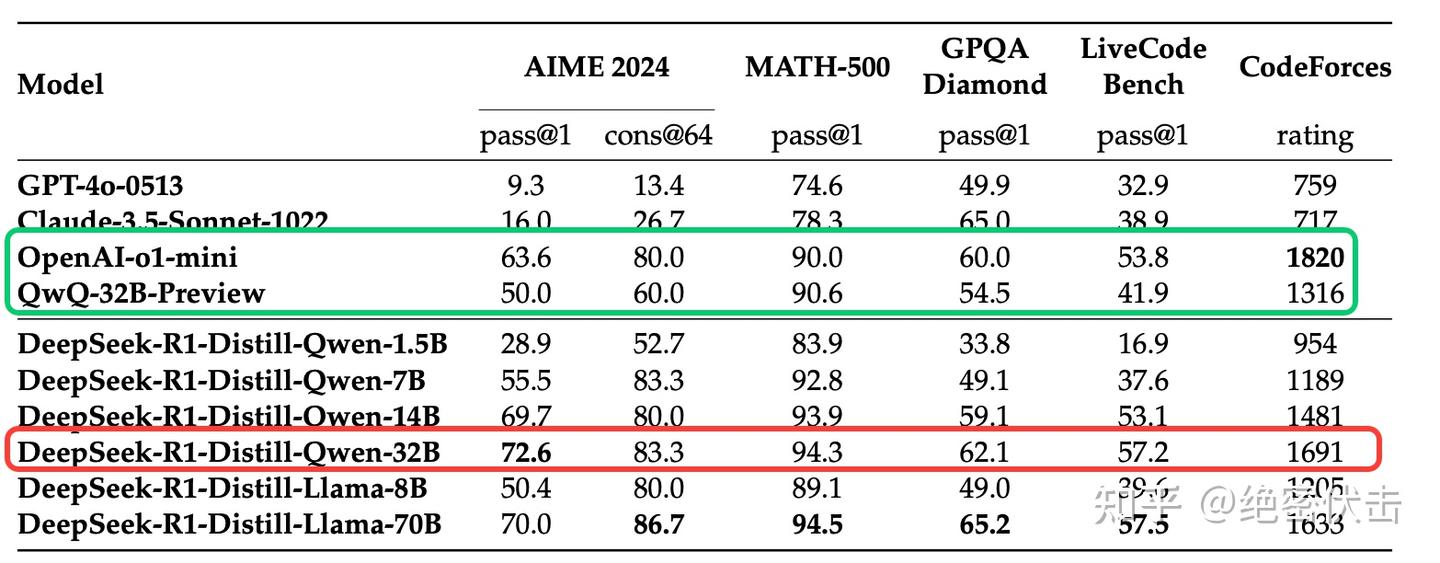
图5: 蒸馏模型效果
参考
DeepSeek-R1 发布,性能对标 OpenAI o1 正式版
https://github.com/deepseek-ai/DeepSeek-R1/tree/main?tab=readme-ov-file
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs viaReinforcement Learning

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)