
LMDeploy本地部署轻松玩转DeepSeek
本文主要介绍了LMDeploy 是如何本地部署大模型,并且以deepseek为例,从环境搭建,模型选择,推理,部署,量化全流程保姆级从0到1详细记录了每个过程。它是一个专为大语言(LLMs)和视觉-语言模型(VLMs)设计的高效部署工具箱,可以帮我们轻松玩转各种大模型,让我们对于大模型应用游刃有余,如鱼得水,挥洒自如。
LMDeploy本地部署DeepSeek
前言
LMDeploy 是一个专为大语言模型(LLMs)和视觉-语言模型(VLMs)设计的高效且友好的部署工具箱。它集成了多种先进的技术和功能,有着卓越的推理性能、可靠的量化支持、便捷的服务部署以及极佳的兼容性
一、环境搭建
版本要求,CUDA 11+(>=11.3),python要求3.8 - 3.12之间.
获取代码,下面2种方法都可以.
1. pip
conda create -n lmdeploy python=3.8 -y
conda activate lmdeploy
pip install lmdeploy
2. git
git clone https://github.com/InternLM/lmdeploy.git
cd lmdeploy
pip install -e .
二、模型准备
1. 下模地址
1,huggingface
https://huggingface.io
需要梯子
2,魔塔社区
https://www.modelscope.cn
可直接访问
2. 选模
1,LLM(文本生成)
先来看看全球热度爆表的两款有着性价比之王赞誉的DeepSeek-R1和DeepSeek-V。

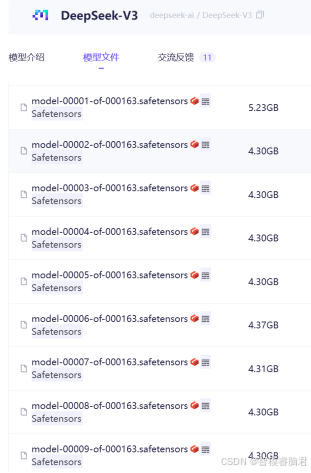
这两款大小几乎一样,一共切了163块,每块4.3G,还有个别一些事5-6G,总大小超过163*4.3=700.9G.要是企业级应用可以试试,自己玩的话,光下载至少3天,关键硬盘也没那么大,推理的话GPU要求也极高,综上所述,还是先放弃这两款。幸运的是,经过查找发现了一个小一点的,和他们都有血缘关系的deepseek,蒸馏过的1.5B参数的模型。
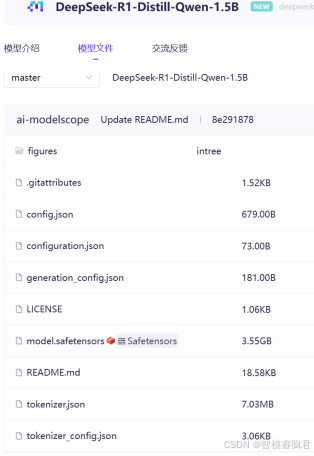
这个就很小了,只有3G多了,后面就拿这款测试了。
2,VLM(图像识别)
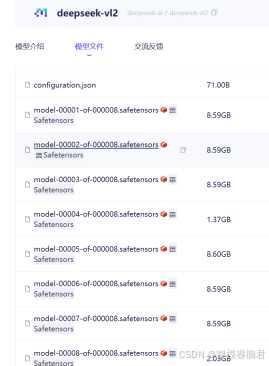
哥哥70G左右,弟弟30G,那就用弟弟。

3,T2I(文生图)
这是一款近期最近发布的,经过多家测评机构,一致认为在文生图的表现已经超过DALL·E 3,而且模型也不大.Janus-Pro-1B大概4G多点.
3. 下模
1, LLM
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B')
2, VLM
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/deepseek-vl2-small')
3, T2I
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/Janus-Pro-1B')
魔塔社区的网站给了下载地址,直接复制到代码即可。
然后安装modelscope包。
唯一注意一点就是包下哪去了。
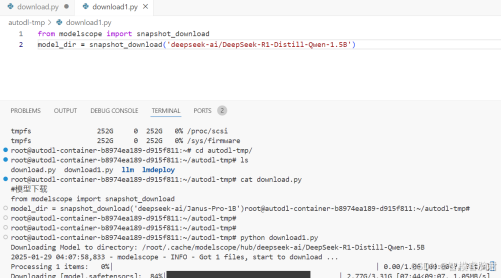
主要第一个模型没给参数,一般默认是根目录下.cache文件的modelscope下,如果是从huggingface下的,默认也是在这个目录,同样也会建一个huggingface目录,模型都保存在这里面.
如果不想考来考去,也可以指定下载目录,就是参数中加一个cache_dir,后面跟路径即可.2个模型分别用默认和指定下载,然后看看下哪了.这时候可以去干别的,可以开2个窗口同时下,过会再来看.
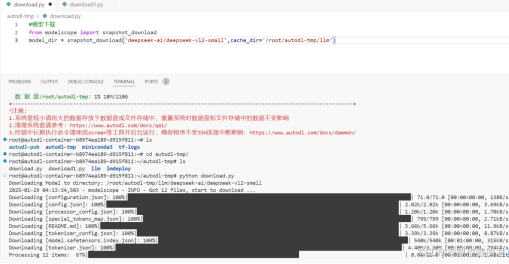
三、推理
1. 代码
只需要把模型路径改位自己的即可,问题可以随便写自己感兴趣的话题.这样,就可以不需要下任何app,不需要上网,本地就可以玩转大模型,也可以部署到自己服务器上.
下面举例演示过程.
1,文本
from lmdeploy import pipeline
pipe = pipeline('/root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B')
response = pipe(['Hi, pls intro yourself', 'Shanghai is'])
print(response)
也可以使用调用OpenAI格式的prompts形式调用,关于相关更详细的调用,可以参考
https://blog.csdn.net/weixin_41688410/article/details/145378798
from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(tp=2)
gen_config = GenerationConfig(top_p=0.8,
top_k=40,
temperature=0.8,
max_new_tokens=1024)
pipe = pipeline('internlm/internlm2_5-7b-chat',backend_config=backend_config)
prompts = [[{'role': 'user',
'content': 'Hi, pls intro yourself'}],
[{'role': 'user', 'content': 'Shanghai is'}]]
response = pipe(prompts, gen_config=gen_config)
print(response)
2,视觉
把模型路径,和需要加载的图片换成自己的即可。
from lmdeploy import pipeline
from lmdeploy.vl import load_image
pipe = pipeline('/root/autodl-tmp/llm/deepseek-ai/deepseek-vl2-small')
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response)
2. 输出
下面是输出,可以看到,我们先让它介绍一下自己,它说它是DeepDeep-R1,然后 详细的描述了它可以干什么。第二个问题,是一个补全句子,我们只给了主谓语,后面宾语模型自由发挥。
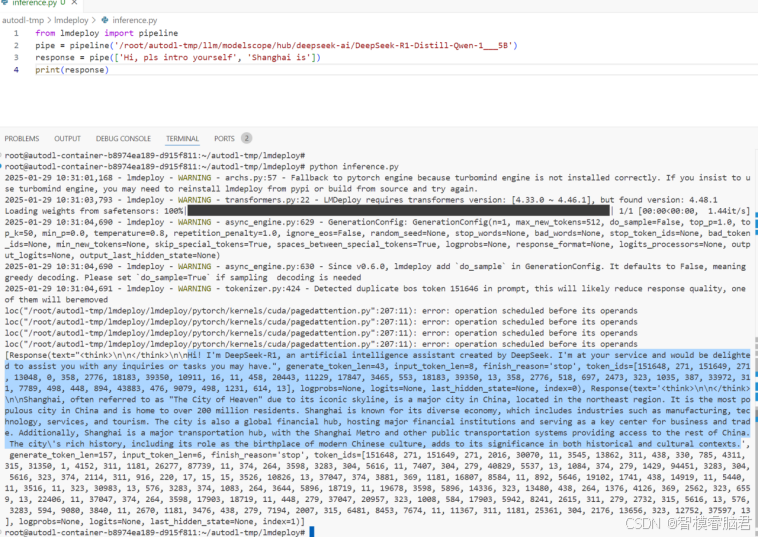
除了回答问题,对应的token_ids也一块输出了,这个就是每个torken,可以简单理解位每个单词,在向量表里查询对应值。为了方便看它的输出,我们翻译一下
Hi! I'm DeepSeek-R1, an artificial intelligence assistant created by DeepSeek. I'm at your service and would be delighted to assist you with any inquiries or tasks you may have
你好!我是 DeepSeek-R1,由 DeepSeek 创建的人工智能助手。我随时为你服务,很乐意协助你解决任何问题或完成任何任务。
------------------------------------------------------------
Shanghai, often referred to as "The City of Heaven" due to its iconic skyline, is a major city in China, located in the northeast region. It is the most populous city in China and is home to over 200 million residents. Shanghai is known for its diverse economy, which includes industries such as manufacturing, technology, services, and tourism. The city is also a global financial hub, hosting major financial institutions and serving as a key center for business and trade. Additionally, Shanghai is a major transportation hub, with the Shanghai Metro and other public transportation systems providing access to the rest of China. The city\'s rich history, including its role as the birthplace of modern Chinese culture, adds to its significance in both historical and cultural contexts
上海,因其标志性的天际线常被称为“天堂之城”,是中国东北地区的一个主要城市。它是全中国人口最多的城市,拥有超过2亿居民。上海以其多元化的经济而闻名,涵盖了制造业、技术、服务业和旅游业等行业。这座城市还是一个全球金融中心,拥有众多大型金融机构,并作为商业和贸易的关键中心。此外,上海是一个重要的交通枢纽,上海地铁和其他公共交通系统为前往中国的其他地区提供了便利。这座城市丰富的历史,包括其作为现代中国文化发源地的角色,增加了它在历史和文化背景下的重要性。
四、大语言模型(LLMs)部署
此命令将本地主机上的端口23333启动一个与OpenAI接口兼容的推理服务.Ollama也是一样,开一个端口.
lmdeploy serve api_server /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B --server-port 23333
此命令将本地主机上的端口23333启动一个与OpenAI接口兼容的推理服务.启动后打印如下
root@autodl-container-b8974ea189-d915f811:~/autodl-tmp/lmdeploy# lmdeploy serve api_server /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B --server-port 23333
2025-01-29 12:11:12,474 - lmdeploy - WARNING - archs.py:57 - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
Loading weights from safetensors: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.04it/s]
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
INFO: Started server process [62994]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:23333 (Press CTRL+C to quit)
服务端口加载模型启动后,查看显存的占用情况,大概在13G左右。所以2080的是跑不起来了,至少3080以上,3080ti,3090等,才可以。
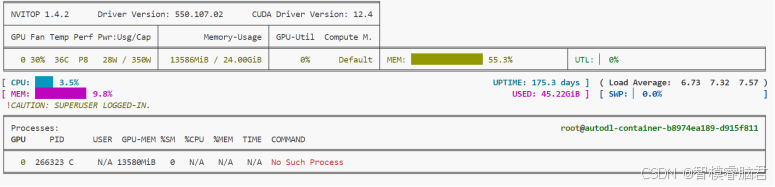 启动以后可以调用OpenWebUI工具,也可以直接用代码调用 .下面用代码接口方式演示调用.写一个OpenAI调用接口.服务器端启动后,我们启动客户端
启动以后可以调用OpenWebUI工具,也可以直接用代码调用 .下面用代码接口方式演示调用.写一个OpenAI调用接口.服务器端启动后,我们启动客户端
from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY',
base_url="http://0.0.0.0:23333/v1"
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好,请介绍下你自己,你是谁发明的,你能干什么?"},
],
temperature=0.8,
top_p=0.8
)
print(response)
root@autodl-container-b8974ea189-d915f811:~/autodl-tmp# python OpenAICall.py
ChatCompletion(id='4', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='<think>\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))], created=1738158904, model='/root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=74, prompt_tokens=24, total_tokens=98, completion_tokens_details=None, prompt_tokens_details=None))
root@autodl-container-b8974ea189-d915f811:~/autodl-tmp#
temperature,top_p值越大,模型回答越收敛,每次回答也极为相似。值越小,回答越发散,自由度也越高,每次回答的差异也大。另外一个注意,这个 api_key并不需要填写具体值,可以忽视这个参数.如果是调用OpenAI服务器上的,那是必须的。
五、视觉语言模型(VLMs)部署
把模型和图片路径换成自己的即可。
from lmdeploy import pipeline
pipe = pipeline('/root/autodl-tmp/llm/deepseek-ai/deepseek-vl2-small')
prompts = [
{
'role': 'user',
'content': [
{'type': 'text', 'text': 'describe this image'},
{'type': 'image_url', 'image_url': {'url': 'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg'}}
]
}
]
response = pipe(prompts)
print(response)
六、LoRA推理服务
LoRA(Low-Rank Adaptation)目前仅支持 PyTorch 后端。其部署过程与其他模型类似,你可以通过运行命令 lmdeploy serve api_server -h 来查看相关命令。关于如何使用自己数据集训练自己的LoRA权重模型,可参考
https://blog.csdn.net/weixin_41688410/article/details/145367602
同时,lmdeploy serve可支持一个base模型,加载多个自己训练的LoRA模型。
lmdeploy serve api_server /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B --adapters mylora=DeepSeek-R1-Distill-Qwen-1___5B-chat-LoRA
七、量化
主要是用于减少模型的存储大小和计算复杂度,同时尽量保持模型的性能。量化通常应用于模型的权重(weights)和激活值(activations),将其从浮点数(如32位浮点数,即FP32)转换为低精度的表示形式(如8位整数,即INT8,还有4位,INT4)。
下面就是量化,–work-dir后面跟输出路径即可。
1. INT4
lmdeploy lite auto_awq /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B --work-dir /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B-4bit
下面是lmdeploy官网给的默认参数,根据需要做修改,默认是量化4位的。如不要修改,直接运行上面命令即可。ptb是一个校准数据集。数据集的查找还是huggingface和modelscope去找。
export HF_MODEL=internlm/internlm2_5-7b-chat
export WORK_DIR=internlm/internlm2_5-7b-chat-4bit
lmdeploy lite auto_awq \
$HF_MODEL \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--work-dir $WORK_DIR
也可以不用改任何参数,直接使用8位的量化命令
2. INT8
lmdeploy lite smooth_quant /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B --work-dir /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B-4bit --quant-dtype int8
推理,替换自己量化完的模型即可。
from lmdeploy import pipeline, PytorchEngineConfig
engine_config = PytorchEngineConfig(tp=1)
pipe = pipeline("/root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B-4bit", backend_config=engine_config)
response = pipe(["Hi, pls intro yourself", "Shanghai is"])
print(response)
3. KV Cache
最大优势就是不需要校准数据集。8位是无损的,4位是可接受范围。
lmdeploy serve api_server /root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B --quant-policy 8
八、测试对比
客户端不变,和之前一样
from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY',
base_url="http://0.0.0.0:23333/v1"
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好,请介绍下你自己,你是谁发明的,你能干什么?"},
],
temperature=0.8,
top_p=0.8
)
print(response)
使用KV Cache 8位的量化命令运行结果
root@autodl-container-b8974ea189-d915f811:~/autodl-tmp# python OpenAICall.py
ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='<think>\n嗯,用户让我介绍自己,包括我是谁发明的,我能干什么。首先,我得弄清楚用户的需求是什么。看起来他可能是在寻找自我介绍的信息,可能是用于某种展示或者测试。\n\n用户提到“我是谁发明的”,这让我想到可能是在问科学、技术、工程、数学领域的知识。但用户没有具体说明是哪个领域,所以需要做一个全面的回答。同时,他要求我能干什么,这可能意味着他希望了解我的能力或能力范围。\n\n接下来,我需要考虑用户的身份。他可能是一个学生、研究人员,或者是一个刚开始学习新知识的人。如果是学生,可能需要更基础的信息;如果是研究人员,可能需要更专业的回答。所以,我应该保持回答的全面性,同时适合不同的背景。\n\n用户的需求可能不仅仅是简单的介绍,还可能希望了解我的专业背景和相关领域。因此,我需要包括一些关于我的背景,比如我是哪个学科的专家,或者有什么相关领域的成就。\n\n另外,用户可能希望了解我的主要职责或贡献,但没有具体说明。所以,我需要假设用户可能需要了解我的主要领域,或者提供一些常见领域的信息,如数学、物理、工程等。\n\n我还需要注意不要过于技术化,因为用户可能没有明确的背景。所以,回答需要保持简洁明了,适合不同层次的需求。\n\n总结一下,用户需要一个全面且适合不同背景的回答,涵盖发明、能力等方面,同时保持专业但易懂的语气。因此,我应该提供一个涵盖发明、专业背景、贡献等方面的信息,帮助用户更好地了解自己。\n</think>\n\n你好!我是一位人工智能助手,由中国的深度求索(DeepSeek)公司独立开发,我清楚我的身份和使命。我能够通过多种方式帮助你解答问题,如果你有任何问题或需要了解的内容,随时告诉我!', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))], created=1738165403, model='/root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=374, prompt_tokens=24, total_tokens=398, completion_tokens_details=None, prompt_tokens_details=None))
不用量化的结果
root@autodl-container-b8974ea189-d915f811:~/autodl-tmp# python OpenAICall.py
ChatCompletion(id='4', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='<think>\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))], created=1738158904, model='/root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=74, prompt_tokens=24, total_tokens=98, completion_tokens_details=None, prompt_tokens_details=None))
root@autodl-container-b8974ea189-d915f811:~/autodl-tmp#
九、总结
通过量化和不量化结果对比,量化后的回答稍微啰嗦了一点,但总体上完整的回答了问题。所以呢,总的来说,LMDeploy 有着高效推理、可靠量化、便捷服务和卓越兼容性,为大语言模型和视觉-语言模型的部署提供了强大的支持。无论是在学术研究还是工业生产中,LMDeploy 都能够为用户提供高效、可靠的模型部署解决方案。简单易学,玩转各种模型。本文以deepseek的模型为例,详细阐述了使用过程,有时间的话也可以试试大点的,或者别的种类也可以,比如Qwen,Llama,GLM等等,只要能下载的都可以部署到本地,或者自己的服务器上,也可以自己写点漂亮的前端UI,调用起来更加赏心悦目。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)