震惊世界的DeepSeek-V3技术与其他主流模型的全面评估对比
近年来,大型语言模型(LLM)一直在进行快速迭代和进化,比如Openai,Anthropic,逐渐减少(AGI)的差距。除了封闭式模型,开源模型,比如DeepSeek系列,也正在取得长足的进步,努力与封闭源同行缩小差距。为了进一步推动开源模型功能的边界,deepseek团队扩大了模型并引入DeepSeek-V3,这是具有671B参数的大型专家(MOE)模型,每个 token 都激活了37B。从具有
简介
近年来,大型语言模型(LLM)一直在进行快速迭代和进化,比如Openai,Anthropic,逐渐减少(AGI)的差距。除了封闭式模型,开源模型,比如DeepSeek系列,也正在取得长足的进步,努力与封闭源同行缩小差距。为了进一步推动开源模型功能的边界,deepseek团队扩大了模型并引入DeepSeek-V3,这是具有671B参数的大型专家(MOE)模型,每个 token 都激活了37B。从具有前瞻性的角度来看,他们始终如一地努力争取强大的模型绩效和经济成本。因此,就体系结构而言,DeepSeek-V3仍然采用多头潜在注意力(MLA),为了有效的推理和DeepSeekmoe进行具有成本效益的培训。这两个架构已在DeepSeek-V2中得到了验证,证明其能力在实现有效的训练和推理的同时保持健壮的模型性能。除了基本体系结构之外,他们还实施了两种其他策略,以进一步增强模型功能。
首先,DeepSeek-V3先驱者是一种无辅助策略了使负载平衡,目的是最大程度地减少对模型性能的不利影响,这源于鼓励负载平衡的努力。其次,DeepSeek-V3采用了多句话的预测培训目标,观察到这是为了提高评估基准的总体性能。为了获得有效的培训,DeepSeek-V3支持FP8混合精度培训并实施培训框架的全面优化。低精度培训已成为有效训练的有前途的解决方案,其演变与硬件功能的进步紧密相关。在这项工作中,DeepSeek-V3引入了FP8混合精度训练框架,并首次验证其在极大的模型上的有效性。通过支持FP8计算和存储,DeepSeek-V3既实现了加速训练,又可以减少GPU内存使用量。至于训练框架,DeepSeek-V3设计了双管算法以进行有效的管道并行性,该管道平行性的管道气泡较少,并且在训练过程中通过计算通信重叠而隐藏了大部分通信。这种重叠可以确保,随着模型的进一步扩展,只要保持恒定的计算与通信比率,仍然可以在节点上使用细粒度的专家,同时实现接近零的全部全部交流开销。此外,还开发了有效的跨节点全体通信内核,以充分利用Infiniband(IB)和NVLink带宽。此外,精心优化了内存足迹,使得在不使用昂贵的张量并行性的情况下训练DeepSeek-V3成为可能。结合这些努力,达到了高训练效率。
在预训练期间,DeepSeek-V3在14.8T高质量和多样的 Token 上训练DeepSeek-V3。训练过程非常稳定。在整个培训过程中,我们没有遇到任何无法恢复的损失尖峰或不得不退缩。接下来,我们为DeepSeek-V3进行了两阶段的上下文长度扩展。在第一阶段,最大上下文长度延长至32K,在第二阶段,将其进一步扩展到128K。此后,DeepSeek-V3进行培训后,包括对DeepSeek-V3基础模型的监督微调(SFT)和增强学习(RL),以使其与人类的偏好保持一致,并进一步释放其潜力。在训练后阶段,DeepSeek-V3将推理能力从DeepSeek-R1系列模型中提炼出来,同时仔细维持模型准确性和发电长度之间的平衡。
在全面的基准测试中评估了DeepSeek-V3。尽管经济培训成本,但全面的评估表明,DeepSeek-v3基础已成为当前可用的最强开源基础模型,尤其是在代码和数学方面。它的聊天版本还胜过其他开源模型,并在一系列标准和开放式的基准测试中,具有与领先的封闭源模型相当的性能,包括GPT-4O和Claude-3.5-Sonnet。
下面是DeepSeek-V3的培训成本,假设H800的租金为每GPU小时2美元。
下面这张图展示了DeepSeek-V3及其对应物的基准性能。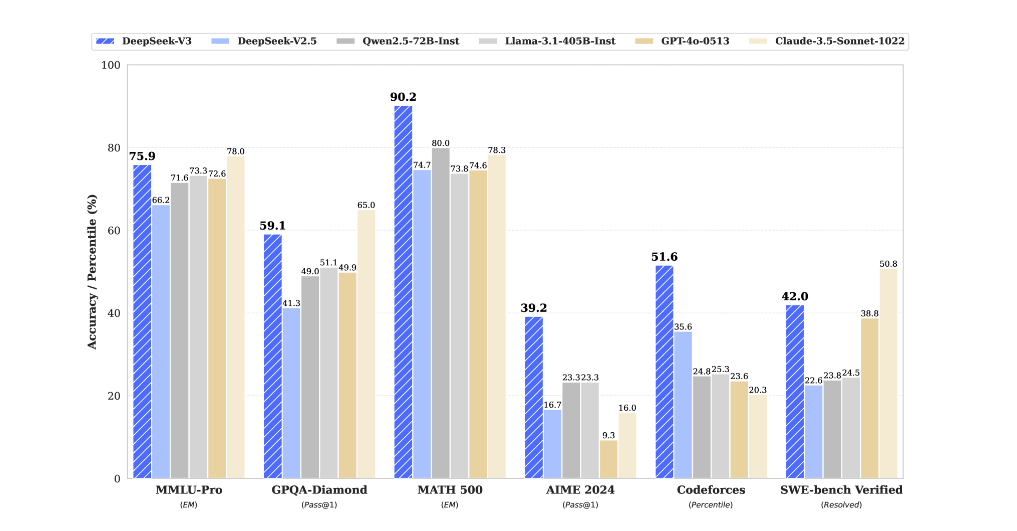
评估基准
除我们用于基础模型测试的基准外,我们还进一步评估了有关Ifeval的指示模型,我们对聊天模型进行全面评估,以针对多个强大的基线,包括DeepSeek-V2-0506,DeepSeek-V2.5-0905,Qwen2.5 72B指示,Llama-3.1 405B指令,Claude-Sonnet-3.5-1022和GPT-4O-0513。对于DeepSeek-V2模型系列,我们选择了最具代表性的变体进行比较。对于封闭式模型,评估是通过其各自的API进行的。
对于包括MMLU,Drop,GPQA和SimpleQA在内的标准基准测试,我们采用了Simple-Evals Framework 的评估提示。我们在零拍设置中利用MMLU-REDUX的零评级提示格式(LIN)。对于其他数据集,我们按照数据集创建者提供的默认提示遵循其原始评估协议。对于代码和数学基准,HumaneVal-Mul数据集包括8种主流编程语言(Python,Java,CPP,C#,JavaScript,Typescript,Typescript,PHP和Bash)。我们使用COT和非COT方法来评估LiveCodebench上的模型性能,该数据是从2024年8月到2024年11月收集的。使用竞争对手的百分比测量了CodeForces数据集。使用无代理框架(Xia et al。)评估了经过验证的SWE基础。我们使用“差异”格式评估与AIDE相关的基准测试。对于数学评估,AIME和CNMO 2024的温度为0.7,结果平均16次运行,而Math-500则采用贪婪的解码。我们允许所有型号为每个基准测试最多输出8192个Token。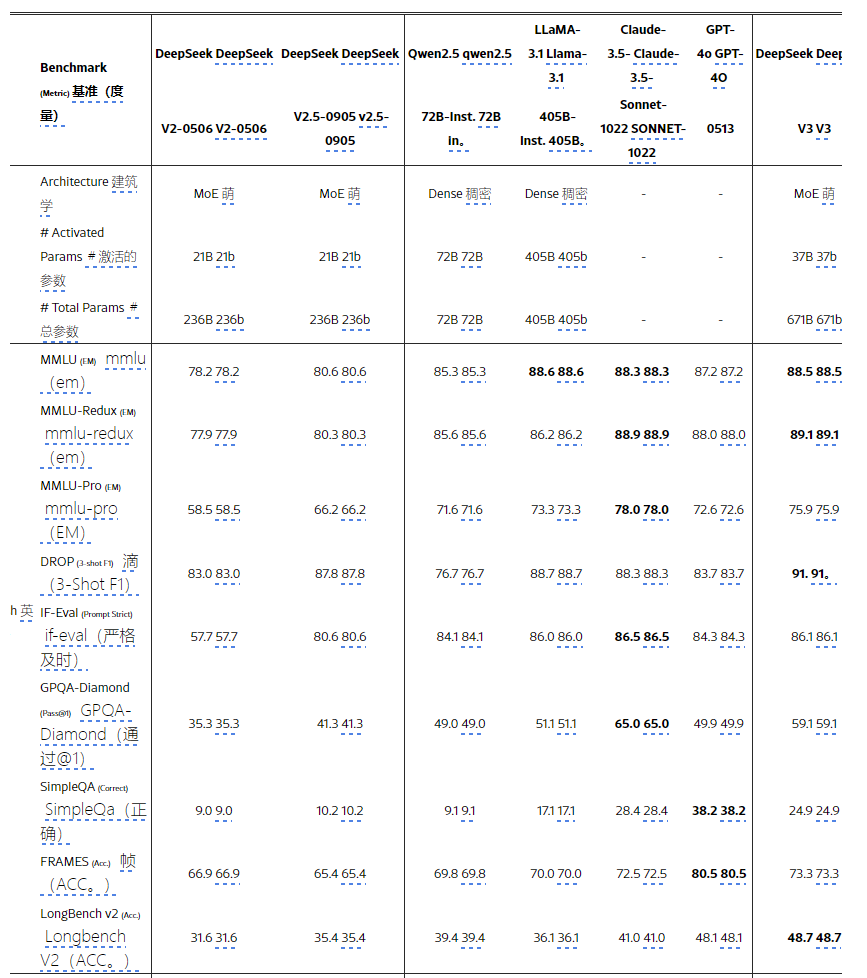
上面列出了评估结果,展示了DeepSeek-V3是表现最好的开源模型。此外,它与诸如GPT-4O和Claude-3.5-sonnet之类的Frontier封闭式模型具有竞争力。
标准评估
MMLU是一个公认的基准,旨在评估各种知识领域和任务跨越大型语言模型的性能。 DeepSeek-V3表现出竞争性能,与顶级型号(例如Llama-3.1-405b,GPT-4O和Claude-Sonnet 3.5)保持一致,而Qwen2.5 72b的表现明显优于QWEN2.5 72B。此外,DeepSeek-V3在MMLU-PRO中表现出色,这是一个更具挑战性的教育知识基准,它仔细跟踪Claude-Sonnet 3.5。在MMLU-REDUX(具有校正标签的MMLU)的MMLU-REDUX上,DeepSeek-V3超过了其同龄人。此外,在GPQA-Diamond上,DeepSeek-V3的博士评估测试台取得了非凡的成绩,仅次于Claude 3.5十四行诗,并以大量优于所有其他竞争对手。
在长篇小说中,理解诸如Drop,Longbench V2和框架之类的基准,DeepSeek-V3继续证明其作为顶级模型的地位。在下降时,它在3次设置中取得了令人印象深刻的91.6 F1得分,超过了此类别中所有其他模型。在框架上,一个基准,需要超过100K令牌上下文的问题,DeepSeek-V3紧紧抓住GPT-4O,同时超过所有其他模型的差距很大。这表明了DeepSeek-V3在处理极其长期的任务方面具有强大的能力。 DeepSeek-V3的长期文化能力通过其在Longbench V2上的一流性能进一步验证,Longbench V2是一个数据集,该数据集在DeepSeek V3推出前几周发布。在事实知识基准上,SimpleQA,DeepSeek-V3落后于GPT-4O和Claude-Sonnet,这主要是由于其设计重点和资源分配。 DeepSeek-V3分配了更多的培训令牌来学习中国知识,从而在C-Simpleqa上表现出色。在遵循指令的基准测试中,DeepSeek-V3显着胜过其前身DeepSeek-V2系列,突出了其改善的理解和遵守用户定义格式约束的能力。
对于LLM来说,编码是一项具有挑战性且实用的任务,包括以工程为中心的任务,例如SWE-Bench Verified和Aider,以及HumaneVal和LiveCodeBench等算法任务。在工程任务中,DeepSeek-V3在Claude-Sonnet-3.5-1022后面落后,但显着优于开源模型。预计开源DeepSeek-V3有望在与编码相关的工程任务中促进进步。通过提供对其强大功能的访问,DeepSeek-V3可以推动软件工程和算法开发等领域的创新和改进,从而赋予开发人员和研究人员的能力,以突破开放源代码模型在编码任务中可以实现的目标的边界。在算法任务中,DeepSeek-V3表现出卓越的性能,在Humananeval-Mul和LiveCodebench等基准上表现出色。这种成功可以归因于其先进的知识蒸馏技术,从而有效地增强了以算法为中心的任务中的代码生成和解决问题的能力。
在数学基准上,DeepSeek-V3表现出出色的性能,显着超过了基线,并为非O1型模型设定了新的最新技术。具体而言,在Aime,Math-500和CNMO 2024上,DeepSeek-V3的表现优于第二好的模型QWEN2.5 72B,绝对得分的大约10%,这对于此类具有挑战性的基准来说是一个很大的利润。这种非凡的能力凸显了DeepSeek-R1蒸馏技术的有效性,该技术已被证明对非O1样模型非常有益。
Qwen和DeepSeek是两个代表性的模型系列,对中文和英语都有强有力的支持。在事实基准中文SimpleQA上,DeepSeek-V3超过QWEN2.5-72B,尽管QWEN2.5接受了较大的语料库的培训,但损害了较大的18T token,比DeepSeek-V3的14.8T token 高20%,该token高20%。 - 训练。
关于中国教育知识评估的代表性基准,以及ClueWSC(中国Winograd架构挑战),DeepSeek-V3和Qwen2.5-72B在C-Eval上,表现出相似的性能水平,这表明这两个模型都经过精心设计,以挑战中文语言。推理和教育任务。
下面是英语开放式对话评估。对于Alpacaeval 2.0,我们使用长度控制的胜率作为度量。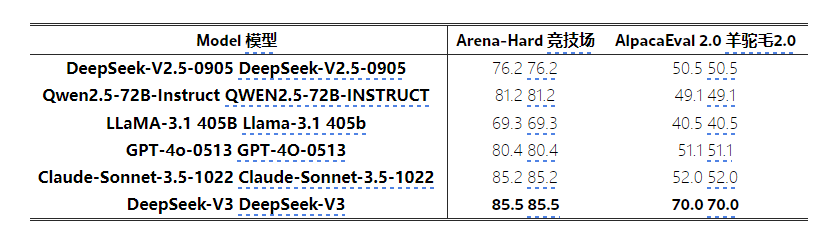
开放式评估
我们将DeepSeek-V3与最先进的模型(即GPT-4O和Claude-3.5)进行比较。下面列出了这些模型在奖励基地(Lambert等人)中的性能。 DeepSeek-V3以GPT-4O-0806和Claude-3.5-Sonnet-1022的最佳版本的表现达到了同等的表现,同时超过了其他版本。此外,DeepSeek-V3的判断力也可以通过投票技术来增强。因此,我们采用DeepSeek-V3以及投票来对开放式问题提供自我反馈,从而提高了对齐过程的有效性和鲁棒性。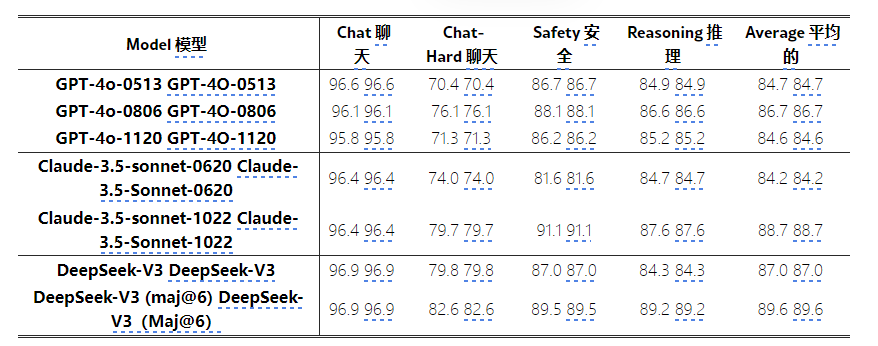
知识蒸馏
通过我们的研究表明,推理模型的知识蒸馏提出了训练后优化的有希望的方向。尽管我们当前的工作着重于从数学和编码域中提取数据,但该方法显示了在各个任务域中更广泛应用程序的潜力。在这些特定领域中所证明的有效性表明,长期蒸馏对于在需要复杂推理的其他认知任务中增强模型性能可能是有价值的。跨不同领域对这种方法的进一步探索仍然是未来研究的重要方向。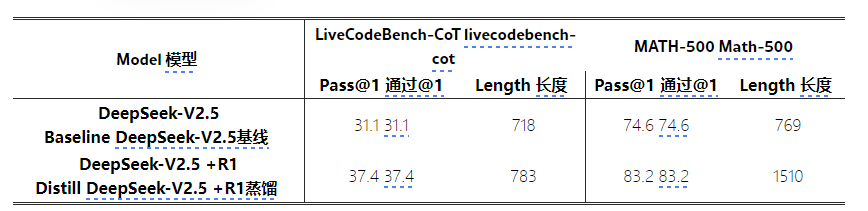
在本文中,我们介绍了DeepSeek-V3,这是一个大型MOE语言模型,具有671B总参数和37B激活参数,在14.8T代币进行了培训。除了MLA和DeepSeekmoe架构外,它还开创了无辅助损失策略,用于负载平衡,并设定了多token的预测训练目标,以实现更强的性能。 DeepSeek-V3的培训由于FP8培训和细致的工程优化而具有成本效益。训练后还成功地从DeepSeek-R1系列模型中提取推理能力。全面的评估表明,DeepSeek-V3已成为当前可用的最强开源模型,并且可以达到与GPT-4O和Claude-3.5-Sonnet等领先的封闭源模型相当的性能。尽管表现出色,但它还保持了经济的培训成本。它仅需要278.8万H800 GPU小时才能进行全面培训,包括训练前,上下文长度延长和培训后。
在承认其强大的绩效和成本效益的同时,我们也认识到DeepSeek-V3有一些局限性,尤其是在部署方面。首先,为了确保有效的推断,建议的DeepSeek-V3的推荐部署部门相对较大,这可能会给小型团队带来负担。其次,尽管我们对DeepSeek-V3的部署策略的端到端生成速度超过了DeepSeek-V2的两倍,但仍然有可能进一步增强。幸运的是,预计随着更高级硬件的开发,这些限制将自然解决。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)