DeepSeek本地部署
DeepSeek由国内大模型公司“深度求索”开发,以极低的训练成本,实现了与GPT-4o等顶尖模型相媲美的性能。1月27日,随着DeepSeek推出新模型DeepSeek-R1,Deepseek应用登顶苹果中国地区和美国地区应用商店免费App下载排行榜,在美区下载榜上超越了ChatGPT。很多人在聊DeepSeek,但是很多人不知道DeepSeek为什么这么火?我想有几点原因,由国内大模型公司开发
DeepSeek由国内大模型公司“深度求索”开发,以极低的训练成本,实现了与GPT-4o等顶尖模型相媲美的性能。1月27日,随着DeepSeek推出新模型DeepSeek-R1,Deepseek应用登顶苹果中国地区和美国地区应用商店免费App下载排行榜,在美区下载榜上超越了ChatGPT。

很多人在聊DeepSeek,但是很多人不知道DeepSeek为什么这么火?我想有几点原因,由国内大模型公司开发、极低的训练成本、媲美GPT-4o等顶尖模型。但是问题是你现在去使用会非常的卡,即便调用API也是限流,使用体验非常不好,一些私密的问题还是本地好。今天就给大家带来简单的DeepSeek本地部署保姆级教程,小白也可以上手,建议电脑配置好的可以试一试。
第一步:Ollama平台安装
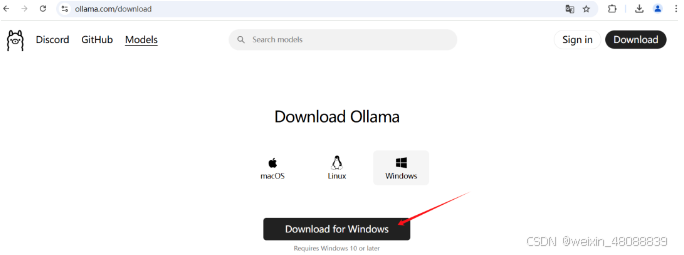
官网下载地址:https://ollama.com/download/,支持Windows、Linux和macOS。选择适合你的电脑系统平台,点击Download进行下载。注意一定要下载安装完毕之后进行下一步。(下载完成之后任务栏出现了ollama羊驼的图标,说明软件安装成功)
第二步,安装DeepSeek-R1模型
在ollama官网(https://ollama.com),搜DeepSeek,选择第一个deepseek-r1,然后选择不同参数的模式,大部分普通电脑都是1.5B或者7B、8B、14B,我这边电脑是4G显存的3050显卡,选择7B还勉强可以。
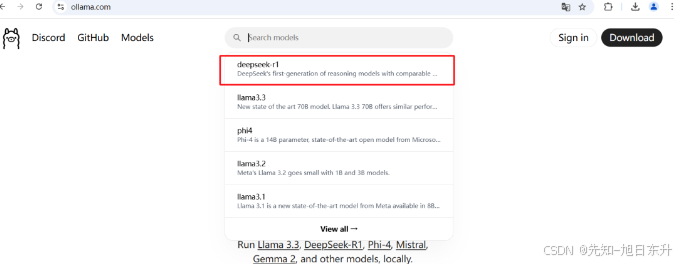
不同的模型不同的需求,可以对应选择(以下配置仅供参考):
1、DeepSeek-1.5B模型
- GPU单卡:NVIDIA GTX 1660(6GB)、RTX 3050(8GB)、T4(16GB)
- CPU:4核以上(如Intel i5/Ryzen 5)
- 内存:16GB系统内存
- 适用场景:单卡轻量级推理,适合个人开发者或小型应用(如文本生成、简单问答)
2、DeepSeek-8B模型
- GPU单卡:NVIDIA RTX 3090(24GB)、RTX 4090(24GB)、A10(24GB)
- CPU:6核以上(如Intel i7/Ryzen 7)
- 内存:32GB系统内存
- 适用场景:单卡轻量级推理,适合个人开发者或小型应用(如文本生成、简单问答)
- 优化方案:若显存不足,可使用量化(如LLM.int8())或卸载部分计算到CPU
3、DeepSeek-32B模型
- GPU单卡:NVIDIA A100 80GB(需4位量化)
- GPU多卡:2 * RTX4090(通过NVLink桥接)或2*A10(24GB)
- CPU:8核以上(如Intel Xeon Silver)
- 内存:64GB以上系统内存
- 适用场景:日常推理,适合个人开发者或小型应用(如文本生成、简单问答)
- 部署建议:使用模型并行,如:DeepSpeed、Megatron-LM 或 量化技术。
4、DeepSeek-70B模型
- GPU单卡:NVIDIA H100 80GB(4位量化 + 内存优化)
- GPU多卡:2 * A100 80GB(4位量化 + 模型并行)或 4 * RTX4090(通过4位量化 + 张量并行)
- CPU:16核以上(如 AMD EPYC/Intel Xeon Gold)
- 内存:128GB以上系统内存
- 适用场景:日常推理,适合个人开发者或小型应用(如文本生成、简单问答)
- 部署建议:需结合模型并行+量化+显存优化技术(如vLLM、FlexGen)。
选择了之后复制对应的模型指令,例如:“ollama run deepseek-r1:7b”(后面有用)。
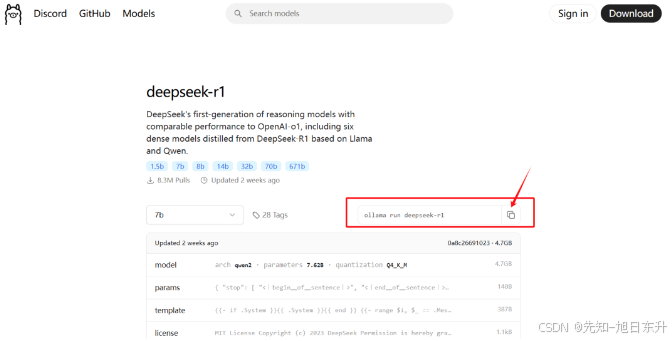
第三步,下载模型并部署
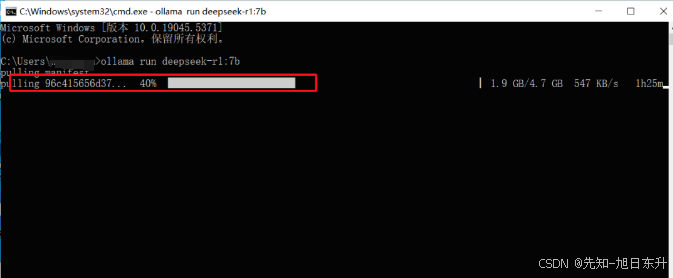
以Windows电脑为例,同时按WIN+R后,输入cmd,并确定,粘贴刚才复制的指令并回车:ollama run deepseek-r1:7b,耐性等待模型下载完毕(红色圈为100%)。
跑完之后我们就可以直接在命令窗口对话了,这是最简单的本地安装,界面使用比较粗糙简单。
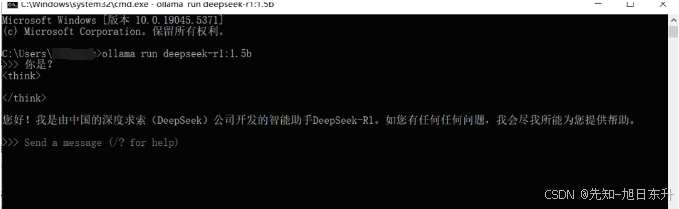
当然如果你想体验更好可以下载一个【Chatbox】软件(https://chatboxai.app/zh),在软件的设置界面选择Ollama API,下面会自动带出你安装好的本地模型,然后就可以在Chatbox流畅体验了。
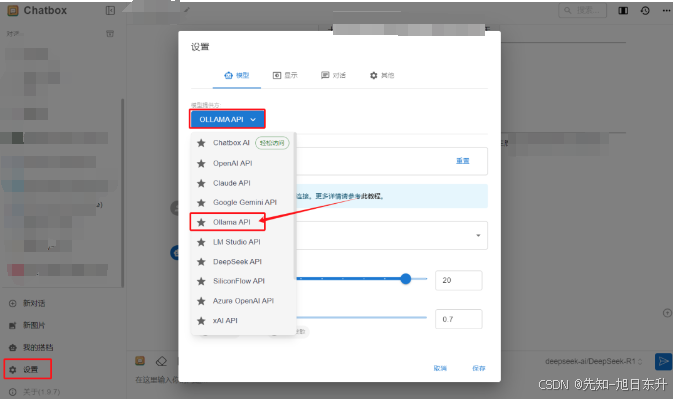
完成!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)