deepseek系列学习
快来看看deepseek的黑科技
前言
春节期间,deepseek着实大火了一把,笔者也去试了一些case,确实很不错,真心为国产点个大大的赞!!希望后面出现更多类似qwen、deepseek这样优秀的工作~
今天我们要学习的deepseek系列包括R系列、V系列。
V系列最大的看点在于高效训练,所需训练资源大大降低,将训练大模型直接搞成了“白菜价”(和以前相比)。而R系列最大的看点在于强化学习。总之都是有干货的东西,一起学起来吧。
由于deepseek公布的技术内容过多,每一方向的优化工作都值得细细琢磨,笔者这里只是抛砖引玉,大家遇到某一块特别感兴趣的可以去读原论文,甚至去查更多相关文献,进而了解整个技术脉络。
全文较长,建议收藏慢慢看。
R系列
论文地址:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
git项目:https://github.com/deepseek-ai/DeepSeek-R1/tree/main
具体研发了两个模型DeepSeek-R1-Zero和DeepSeek-R1,前者是基于pretrain直接进行强化学习,而且是只进行强化学习,结果显示其展现出了强大的推理能力,但是由于没有进行sft,所以在可读性等方面较差,为了解决这一问题以及进一步提高模型的推理能力其研发了DeepSeek-R1。
(1)DeepSeek-R1-Zero
先来看R1-Zero,其直接在DeepSeek-V3-Base基座模型上用GRPO做强化学习(注意!没有SFT)。大家都知道做强化学习最难的其实就是reward model的获取,以往大部分做法是用另外一个llm大模型来做rm,但是这起码会存在两个基本问题,一个是训练后的rm本身就存在不准确的问题,其次是训练rm本身也需要监督数据,而这个数据通常获取成本较高,而且一旦要优化的policy model换了,rm有可能都要重新做数据跟着进行更新训练,所以整体搞下来就是又麻烦又不准确,这也是目前行业内较难攻克的一个技术方向了。
而deepseek R系列的最大贡献点就是要去尝试解决一下这个老大难问题,或者说给一个起码的探索方向吧(可见只有能真真的深入研究一个行业痛点才能收到大家的掌声啊)。其思路很质朴,既然llm有缺陷又很复杂,那就换一种方式做rm,那什么样的rm能同时规避上面两种问题呢?deepseek选择了基于规则。
比如对于数学问题,模型需要以指定的格式(例如在方框内)提供最终答案,由于其结果是唯一确定的,所以就可以基于规则来进行正确性验证,又比如对于LeetCode编程问题,可以使用编译器根据预先定义的测试用例来进行检验,可以看到基于规则的rm的准确率理论上能够做到100%!
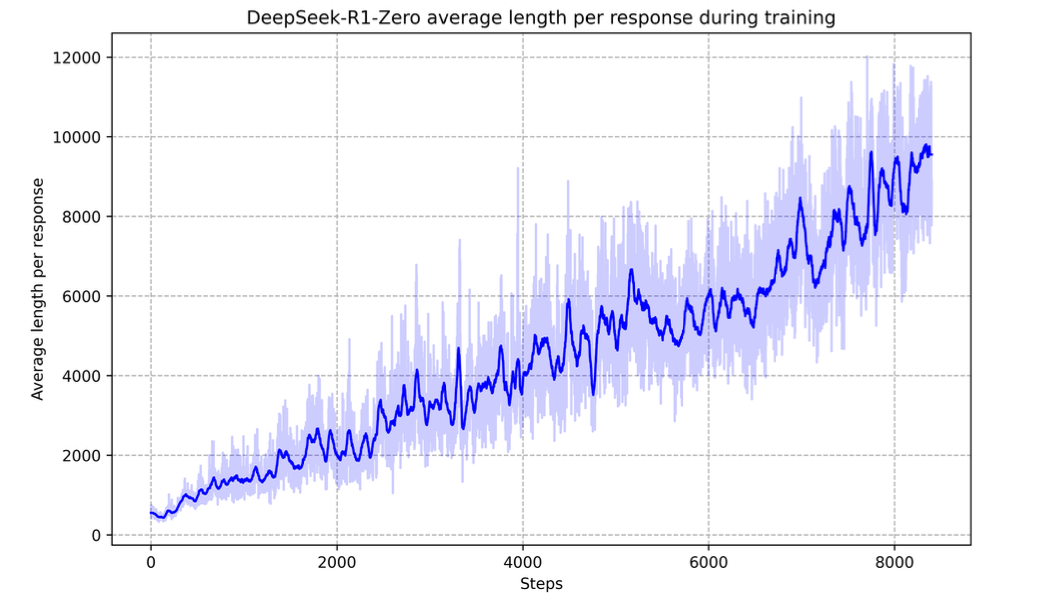
注意整个过程没有使用复杂的监督数据,完全是由模型进行自我进化,随着训练步数的增强,可以观察到模型思考的token数越来越多:
其对推理任务的准确率也越来越高,甚至媲美OpenAI-o1
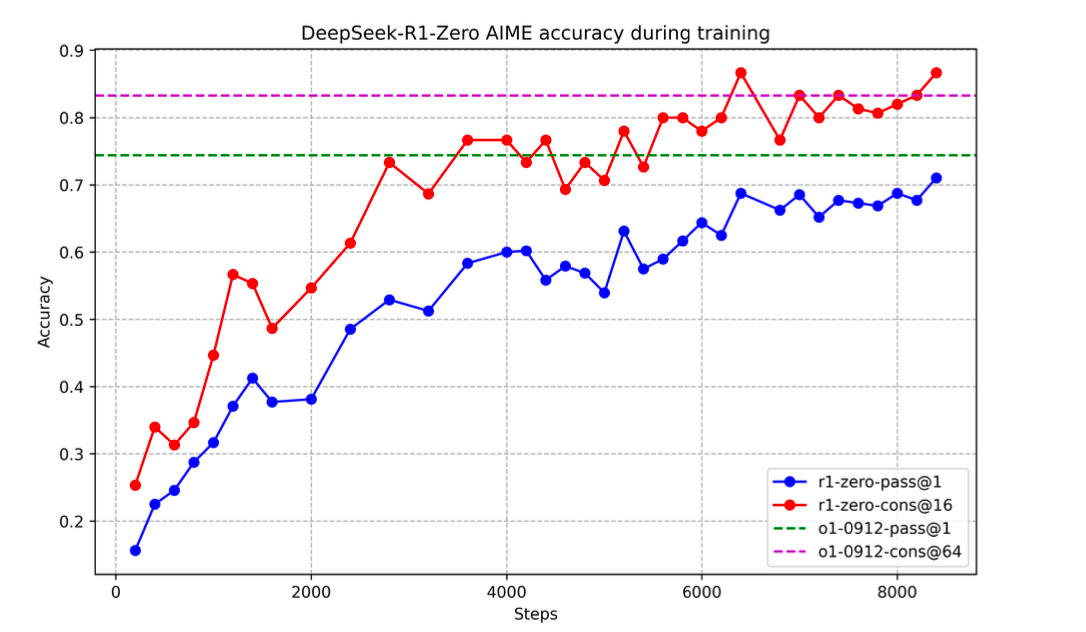
下面是一个具体case:

从这个case中可以显示、清楚的观察到模型究竟是如何自救思考的?比如当前case红色的部分,作者称其为aha moment,其通过重新评估自己的初始方法,来为问题分配更多的思考时间,进行多重验证。
而通过观察这些case也给研究人员带来了全新的认知,感受到了强化学习魅力即:我们不需要明确地教模型如何解决问题,而是简单地为它提供正确的激励(前提是要确实正确),那么它就会自己去探索各种解决问题的策略。而这种自我探索能力也正是强化学习这一流派自诞生以来所肩负的使命。
(2)DeepSeek-R1
仅仅经过强化学习后的R1-Zero已经展现出了强大的推理能力,但其在输出的格式上遇到了一些问题比如可读性差、输出常常混合夹杂着多种语言。这导致对用户的交互很不友好,同时为了进一步提高其推理能力,作者这个时候再次想到了SFT,SFT训练非常高效且效果立竿见意,得利用起来呀!于是乎作者进行了如下pipeline的训练:
- (a)冷启动sft
先用一小部分高质量带有cot的数据(论文中称为冷启动数据,大概数千条)来微调DeepSeek-V3-Base,后续强化学习基于此进行探索学习。这里的微调数据可以通过带有长CoT的样本做few-shot的方式直接让大模型通生成详细答案,并通过人工进行最终标注。
这里微调的好处是从源头就给模型注入易读性的模版具体的为|special_token|<reasoning_process>|special_token|<summary>. 而且通过人工先验知识修复后的数据具有很高的质量,基于这个热启进行RL其性能优于DeepSeek-R1-Zero。
- (b)推理密集型任务的强化学习
该步骤是基于上面的模型,在一些推理密集型任务(比如编码、数学、科学、逻辑推理任务,这些任务都有明确的结果且唯一)进行类似R1-Zero的强化学习,旨在提升模型的推理能力。同时由于进行强化学习的时候模型的输出总是混合夹杂着各种语言,这不利于用户阅读,于是用户又加了个语言一致性的rm,具体来说就是看目标语言占整个COT输出的比例,不过作者也强调了说虽然消融实验表明这种对齐会导致模型性能略有下降,但毕竟结果是利于阅读了,这对人类很友好。所以作者最终还是选择将推理任务的准确率和语言一致性的奖励直接相加,得到最终的奖励进行RL。
- (c)收集更加多样性的数据进行SFT
前两步的学习仅仅是在推理任务的上(能基于规则进行评估的数据)进行学习的,而本步的SFT就是要拓展到其他比如写作、角色扮演等领域。那怎么做呢?SFT当然是先收集数据了。
这又分为两大部分,一部分是和推理相关的数据收集具体的就是用上面的模型进行拒绝采样,然后把预测结果和ground-truth送给DeepSeek-V3进行判断,只留下正确的样本,总共最后收集了600k样本。
其次另一部分是非推理样本,具体的是复用了DeepSeek-V3的部分SFT 数据集,另外对于某些非推理任务,会调用 DeepSeek-V3生成潜在的思路链,然后再通过提示回答问题。同时对于更简单的查询,例如“你好”,则不提供 CoT 作为响应。最终这里总共收集了大约 200k个与推理无关的训练样本。
至此共收集了800K的SFT样本,然后用其基于DeepSeek-V3-Base进行2个epoch的训练。
- (d)全场景的强化学习
该步骤一方面旨在提高模型的有用性和无害性,另一方面是为了进一步完善其推理能力。作者使用rm和各种提示分布的组合来训练模型。
比如对于推理数据,还是使用DeepSeek-R1-Zero的方法 ,对于其他一般数据,还是采用奖励模型来捕捉复杂而微妙场景中的人类偏好,其以DeepSeek-V3 流程为基础,采用类似的偏好对和训练提示分布。例如对于有用性,只关注最终回复,能确保评估出reponse对用户的实用性和相关性,同时最大限度地减少对cot过程的干扰。对于无害性则是评估模型的整个响应,识别和减轻生成过程中可能出现的任何潜在风险、偏见或有害内容。
Distillation:强化一些小模型的推理的能力。
作者直接用上述得到的800K sft数据去训练一些小模型(论文中是训练了qwen和llama系列),结果显示都是大大提高了他们的推理能力。
不过作者这里也做了一些实验来回答了另外一个问题:在这些小模型上仅仅使用上诉提到的RL会怎么样呢?这其实也能让我们看到上述方法的迁移性如何?

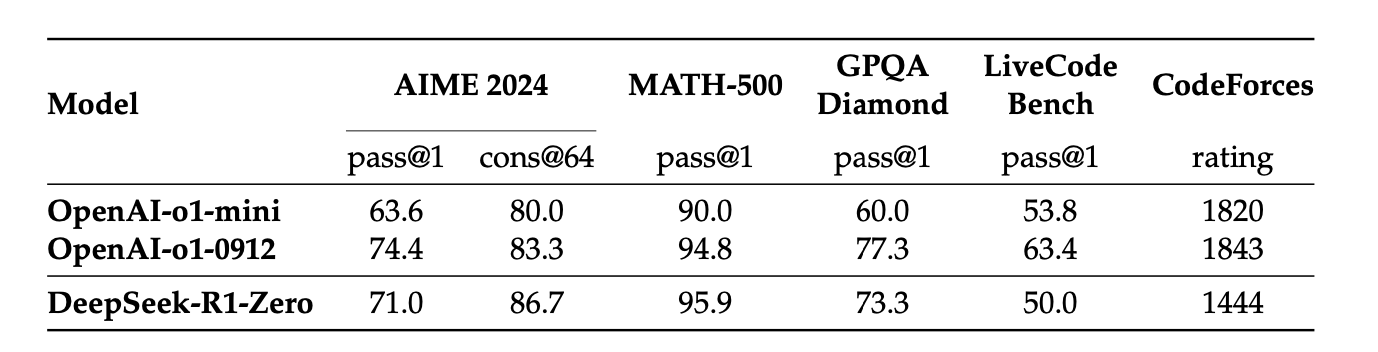
如上图所示,QwQ-32B-Preview是qwen官方的模型结果,DeepSeek-R1-Zero-Qwen-32B是仅仅使用RL得到结果,DeepSeek-R1-Distill-Qwen-32B是使用800K蒸馏的结果。可以看到DeepSeek-R1-Zero-Qwen-32B已经和官方QwQ-32B-Preview效果相当,但是DeepSeek-R1-Distill-Qwen-32B的效果更牛。所以可以得到一些结论,蒸馏在效果上更好一些,而且蒸馏SFT相比于强化学习更高效,所需的资源更少。不过虽然SFT更高效,但是其前提是要先有高质量数据,没有之前的强化学习哪能来SFT的数据呢?所以想要突破效果瓶颈仍然需要更强大的基础模型和更大规模的强化学习。
失败的经验
作者还分享了一些他们早起研发的失败经验比如基于PRM的方法等等,这些都给后续研究人员提供了宝贵的经验。
V系列
论文地址:https://arxiv.org/pdf/2412.19437v1
git项目:https://github.com/deepseek-ai/DeepSeek-V3/tree/main
我们直接看最新的V3版本,其是Moe架构,参数总共671B,每一个token激活。
- (1)算法架构层面
这里涉及到三个大的技术:MLA、DeepSeekMoE with Auxiliary-Loss-Free Load Balancing、Multi-Token Prediction
(a)首先是MLA注意力机制,其是为了提高infer效率而优化的算法,核心是通过类lora的低秩矩阵变化(先做压缩、再做扩展)来减少KV-cache显存占用,从而提升推理性能。这里有一篇很好的科普文章,大家直接看即可:https://zhuanlan.zhihu.com/p/16730036197,
(b) 其次是DeepSeekMoE with Auxiliary-Loss-Free Load Balancing,这是为了高效训练moe架构而研发的算法。在训练moe时常常会面临负载不均衡的问题,比如多个token会倾向路由到同一个专家,那么随着训练步数的增加,经常被路由的专家得到了更多更新的机会,起到的作用越来越大,这种情况会被逐渐恶化放大,进而导致后面的token更倾向于选择这些专家。最后就会导致在具体的训练和推理过程中,MoE的参数是稀疏的,只有部分实际被激活的专家会进行参数的更新或者推理。
为了解决这一问题,deepseek3引入了两个loss来均衡。一个是Auxiliary-Loss-Free:
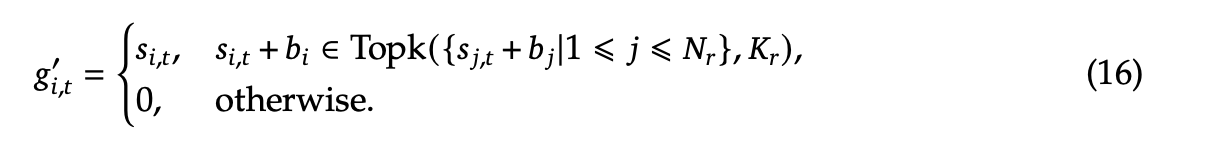
核心思路就是为每一个专家添加一个偏置量 (这个偏置量仅仅用于topk筛选,不加入后续的权重计算)。在每次训练后,如果某个专家过载,则减少其偏置量;如果某个专家负载不足,则增加其偏置量。这样相当于“手动宏观调控贫富差距”
另一个是Sequence-Wise Auxiliary Loss其主要就是怕某单个样本都集中在某几个少数专家训练,本质还是希望多分散一些,于是引入了如下的Bal
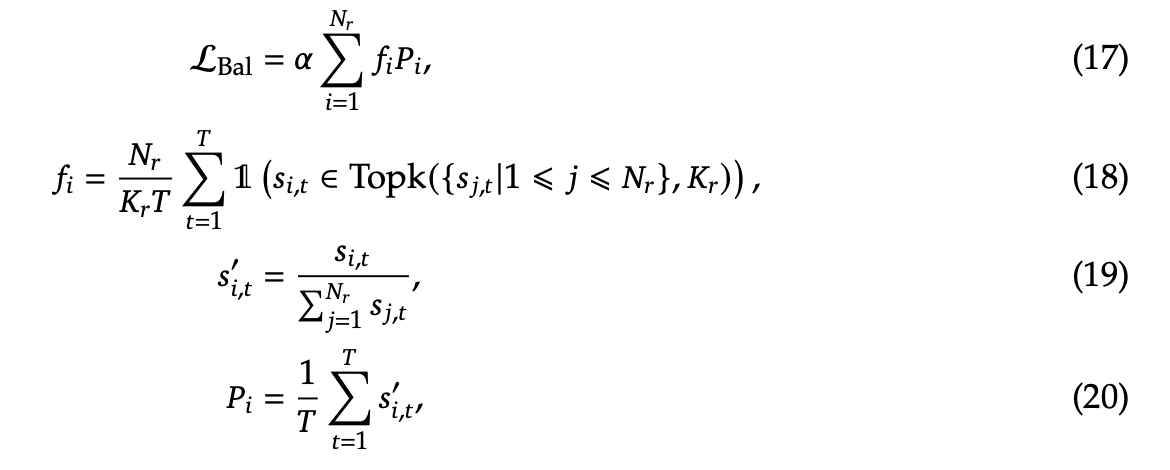
其中f代表当前专家在该样本序列预测过程中被选中频率, p代表当前专家和序列内的每一个token的亲合度均值,代表了该专家和序列的整体亲合度。可以看到当Bal变大时就代表有部分专家在topk中被反复选中,这个时候就要增大惩罚。
(c)Multi-Token Prediction
相比于token-by-token,这里一次性预测多个token,目的就是加强推理效率,而且可以迫使模型训练的时候一次性考虑更多未来的token,加强了效果性能,关于其详细的方法这里也有一篇博客讲解的比较详细,大家可以直接看:
https://zhuanlan.zhihu.com/p/18056041194
- (2)基础设施
该部分讲解了工程方面的一些优化工作包括通信、支持fp8训练等等,这部分对大规模集群训练起到至关重要的作用。由于笔者重点关注模型算法的工作,所以这部分工作大家感兴趣可以自行阅读原paper,顺便提一下支持fp8训练这个对加速训练起到了很大的作用。
- (3)Pre-Training
(a)数据构造
这里重点加大了数学和代码在预训练数据中的比例,同时加了一些其他语种的语料,另外提了一下在代码训练的时候还是沿用了一部分FIM格式的数据。
(b)超参
在这里作者公开了模型所需的具体超参,比如一共61层、moe中设置的是1个共享专家和256个路由专家(每个token激活8个专家)等等
(c)长上下文扩展
通过两阶段渐进性的扩展模型长度,第一次是从4K扩展到32K,第二次是从32K扩展到128K,其中第一次扩展batch是1920,第二次是480。
- (4)Post-Training
这里涉及到推理数据和非推理数据两部分数据的收集。对于推理数据(数学、代码等)主要是使用R1模型的产出,但是其存在过度思考等问题,于是需要混一些常规数据来平衡。
具体来说对于同一个文本有两种数据格式,一个是原始数据<problem, original response>,另外一个是R1的数据 <system prompt, problem, R1 response>。其中system prompt就是系统指令,提示模型去做一些思考等(呼应R1这种输出)。由于同时训练这两种方式的数据(主要是第二种数据),后续在RL阶段,*会去掉system prompt(模型回复相对“简单”了)进行训练,但是因为模型已经学过第二种形式了,所以内部其实同时是有了长COT这个潜力的,所以在没有system prompt下也能把长COT的能力激发出来。这样就确保最终训练数据保留 DeepSeek-R1 的优势,同时产生简洁有效的响应。
- (5)Reinforcement Learning
强化学习这里主要就是rm了,主要是有两个,一个对于数学、代码等这些有明确答案格式的就采用类似R1的规则Rule-Based,这里不再重述。另外一个对于具有自由格式真实答案的问题,就是基于llm的Model-Based,依靠模型来确定响应是否与预期的真实答案相匹配,另外对于没有明确真实答案的问题,例如涉及创意写作的问题,奖励模型的任务是根据问题和相应的答案作为输入提供反馈。这里的rm选用的是DeepSeek-V3 SFT checkpoints。从这里也可以看到其都用的是自己的模型,不依赖外部的模型进行蒸馏,形成了自我闭环。
最后强化学习部分使用的具体算法是GRPO。
总结
(1) R系列最关键的技术其实就是基于规则的rm,那究竟基于了多少规则?具体的例子是咋样的,这些细节我们不得而知,但是是非常重要的,这块后续应该还有很多工作可做,deepseek确实开了个很不错头。另外R1是把强化学习和SFT进行了多次组合进行多阶段学习,这块其实也有很多工作可以探索(比如如果一直无限制的自我拔高的方向迭代向前训练,会怎样呢?)
(2)论文也提到了目前的强化学习主要是验证了在可结构化数据上(数学、代码等)基于规则的rm带来的强大推理能力,因为只有可结构化了,rm才可以规则解析来判断。那其实还有大规模非结构化的数据该怎么rm呢?这里大有可为,作者给出了一个方案:即结合模型反馈和一些额外的规则作为补充可能是一个方向。
关注笔者

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)