千问图像编辑模型Qwen-image-Edit(编辑文字/外观编辑/语义编辑)功能与应用详解
摘要:Qwen-Image-Edit是基于20B Qwen-Image模型训练的图像编辑模型,具备语义与外观双重编辑能力,支持中英精确文本编辑(增删改文字并保留样式)。功能含语义编辑(如IP创建、视角转换)、外观编辑(如增减元素)、文本编辑等。模型分bf16、fp8版,配套模型与Qwen-Image共用。工作流类似基础模型,含基础、局部重绘、双图/多图编辑等,多图编辑需用“图像联结”节点。
Qwen-Image-Edit是Qwen-Image的图像编辑模型,它基于20B的Qwen-Image模型训练而得。Qwen-Image-Edit模型可以实现精确的文本编辑,具备很强的文本渲染与编辑能力。同时,Qwen-Image-Edit模型将输入图像输入到 Qwen2.5-VL(用于视觉语义控制)和 VAE 编码器(用于视觉外观控制),可以实现语义和外观编辑的双重能力。
本节内容所涉及所有模型文末网盘可进行下载,使用前注意将comfyui内核更新至最新版本。
1 主要功能
(1)语义与外观编辑:支持低级视觉外观编辑(如添加、删除或修改元素,要求图像的其他所有区域保持完全不变)和高级视觉语义编辑(如 IP 创建、对象旋转和风格迁移,允许整体像素变化同时保持语义一致性)。
(2)精确文本编辑:支持中英双语文本编辑,允许直接在图像中添加、删除和修改文本,同时保留原始字体、大小和风格。
2 功能演示
Qwen-image-Edit模型的功能十分丰富,为了更加直观的感受模型功能与基础应用能力,官方对Qwen-image-Edit模型的功能作用做了部分展示,这里我们略作整理可以快速对模型功能进行了解。
2.1 语义编辑
语义编辑能力指在保留原始视觉语义的同时修改图像内容。
案例1:主体一致性--制作原创IP编辑

案例2:新颖视图合成--视角转换

案例3:风格迁移--生成虚拟形象

2.2 外观编辑
外观编辑强调在保持图像某些区域完全不变的同时,添加、删除或修改特定元素。
案例1:ai新增

案例2:ai消除

案例3:ai重绘

案例4:调整人物背景

案例5:传达模拟

2.3 文本编辑
(1)文字设计--支持中文字体


案例2:海报编辑--文本/元素修改

案例3:定点文字修复

3 模型下载
3.1 Qwen image edit模型
模型下载地址:
https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI/tree/main/split_files/diffusion_models
共有bf16、fp8两个版本,根据电脑显存情况下载安装即可。
模型安装位置:../ComfyUI/models/diffusion_models
3.2 配套模型
VAE、text_encoders、loRA等配套模型与Qwen-image模型工作流共用,如已安装则无需再额外下载。未下载安装的,也可以查看前面Qwen-image模型相关内容。
(1)text_encoders模型下载链接:
https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main/split_files/text_encoders
安装地址:ComfyUI/models/text_encoders
(2)VAE模型下载链接:
https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main/split_files/vae
安装地址:../ComfyUI/models/vae/
(3)lora模型下载地址:Qwen-Image-Lightning-8steps-V1.0.safetensors
安装目录:../ComfyUI/models/loras/
注:启用该lora时,步数设置为8,cfg设置为2.5
4 工作流应用
4.1 基础工作流应用
官方基础工作流示例如下图所示,该基础工作流的搭建逻辑与Qwen image模型基础工作流基本一致,以“图像输入”并通过“VAE编码”为latent来替代“空latent”输入,另在“模型采样算法AuraFlow”后添加一个“CFGNorm”节点。
CFGNorm节点:通过调整 CFG 参数的作用强度,平衡模型对提示词的遵循度与生成内容的自然度,避免因 CFG 过高导致生成图像生硬或细节失真。
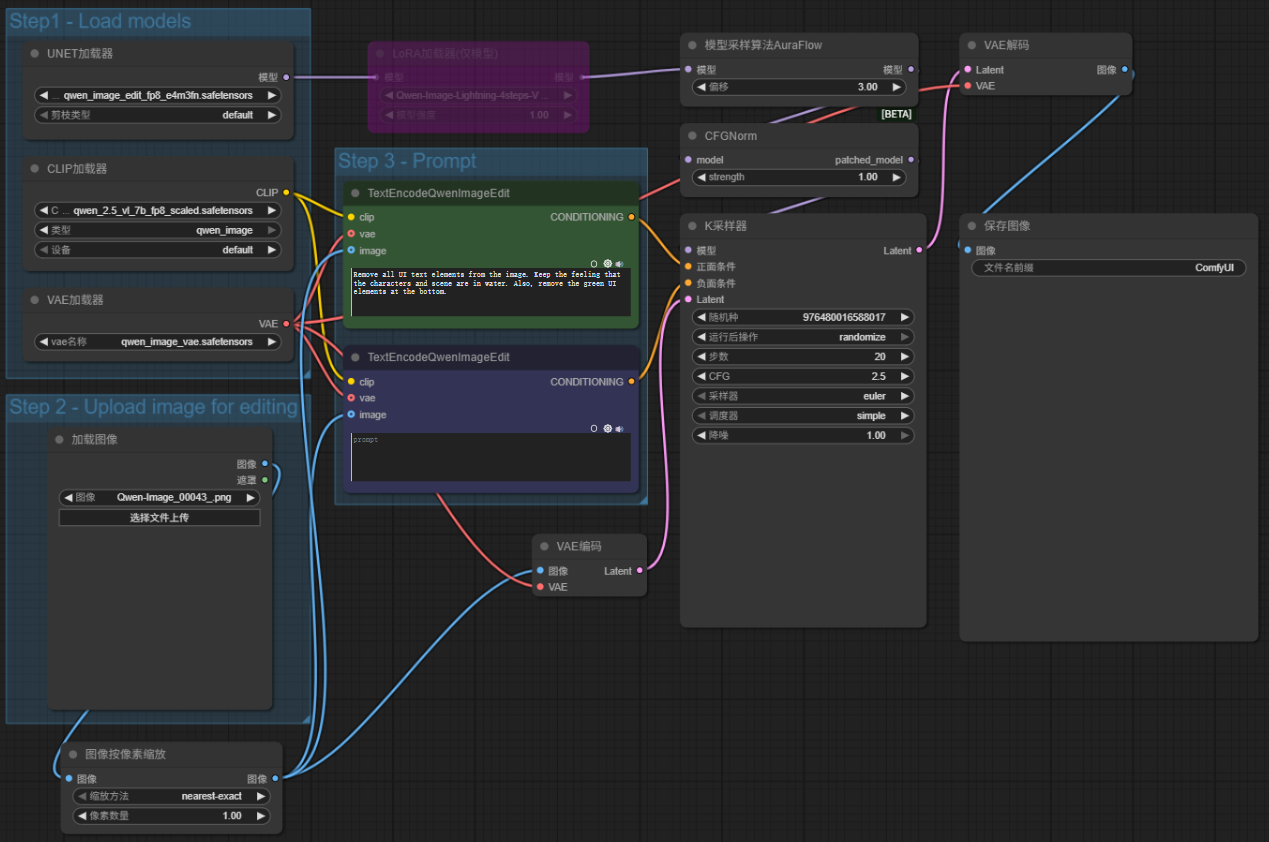
对官方工作流按照逻辑顺序略作梳理获得整理后工作流如下:
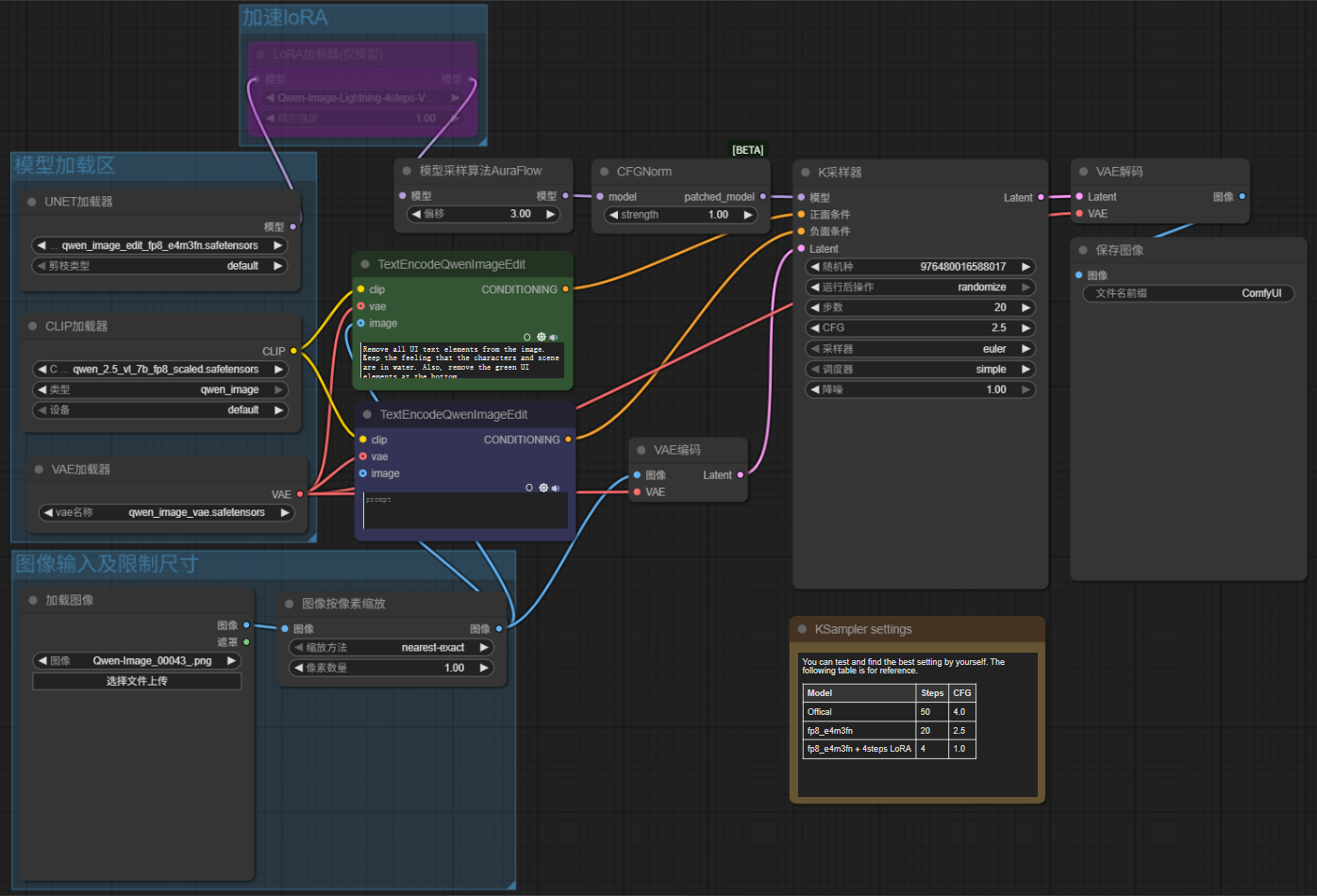
如使用加速loRA,按照loRA说明修改步数及CFG参数即可。
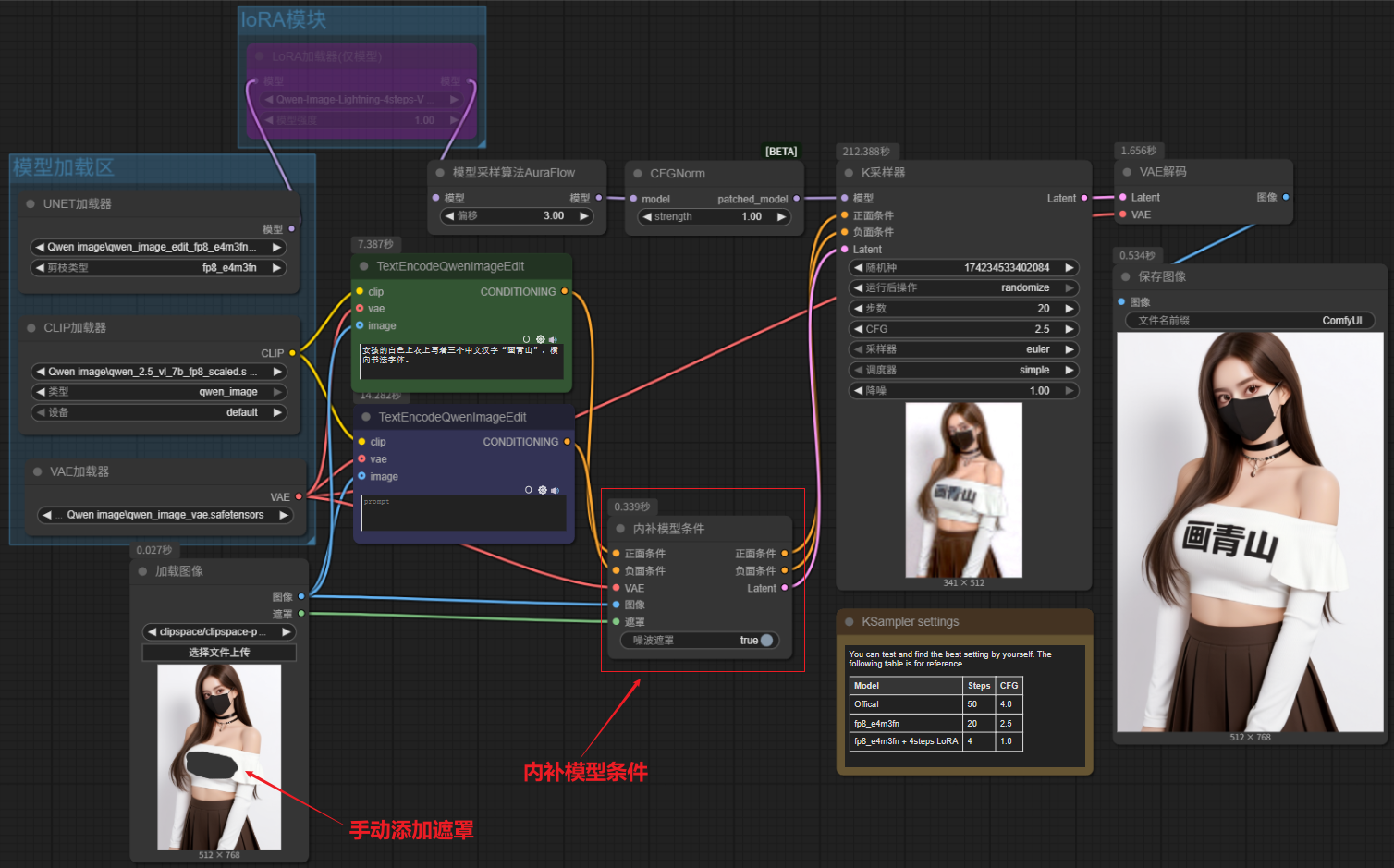
4.2 edit 局部重绘
Qwen-Image-Edit模型局部重绘工作流的搭建逻辑参考XL/FLUX等模型的局部重绘工作流,使用“内补模型条件”节点代替“VAE编码”节点,并输入遮罩节点即可。
下面的案例,使用右键“在遮罩编辑器中打开”手动添加遮罩。
4.3 双图编辑及多图编辑工作流
Qwen_image_edit模型支持双图输入或多图输入的图像编辑,且实测效果在多图编辑效果上较kontext模型似乎可以取得更好的效果。
工作流十分简单,仅在Qwen_image_edit模型基础工作流中通过“图像联结”节点增加输入的图像数量,另外在“图像联结”节点后添加“FluxKontextImageScale”节点用于调整输入图像的尺寸。
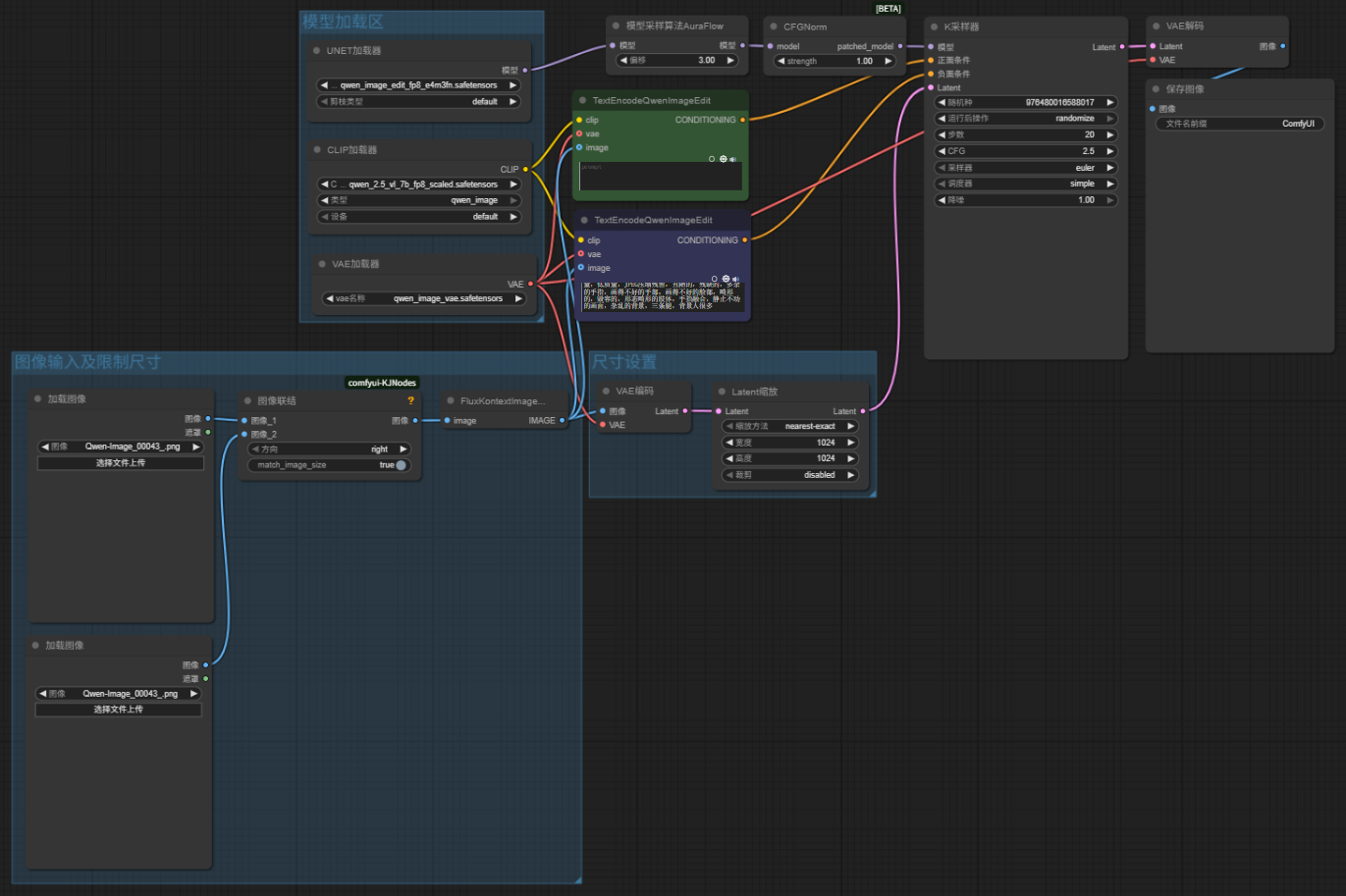
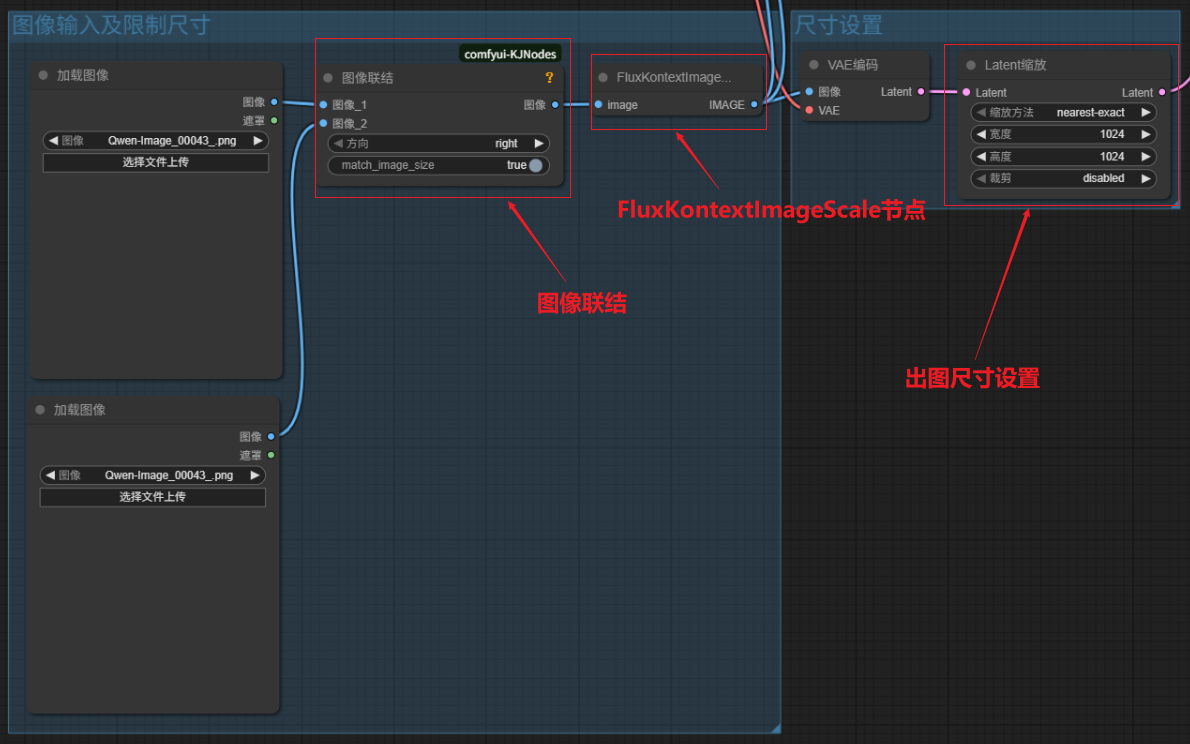
通过在“VAE编码”后添加“latent缩放”节点设置最终图像出图尺寸。
FluxKontextImageScale节点:主要用于调整上下文图像的尺寸,它能根据需求对输入的参考图像进行缩放处理,确保图像尺寸符合 Flux 模型的输入要求或适配生成任务的尺寸设定,帮助优化上下文信息在模型生成过程中的作用,提升图像生成时对参考图的匹配度和协调性。
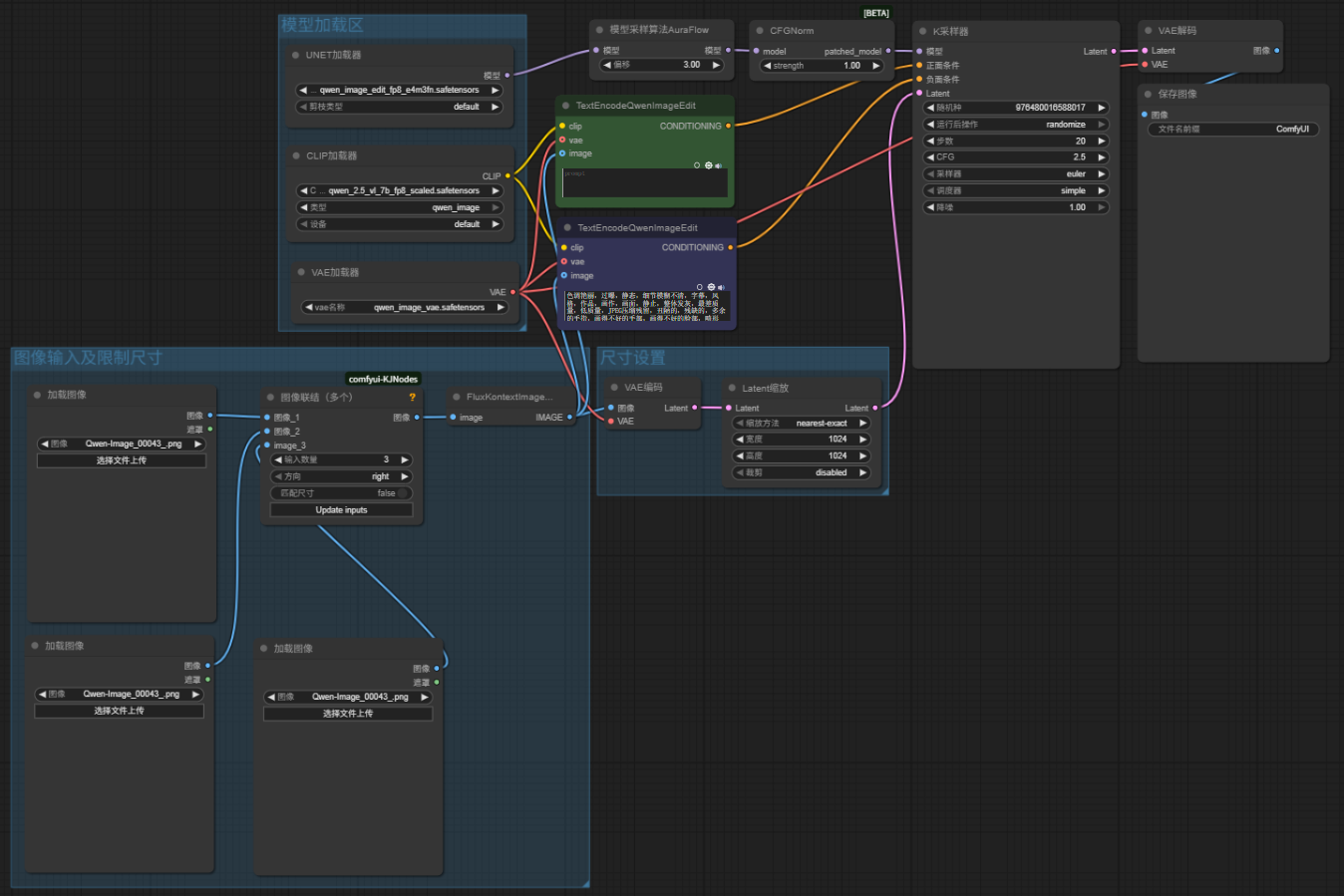
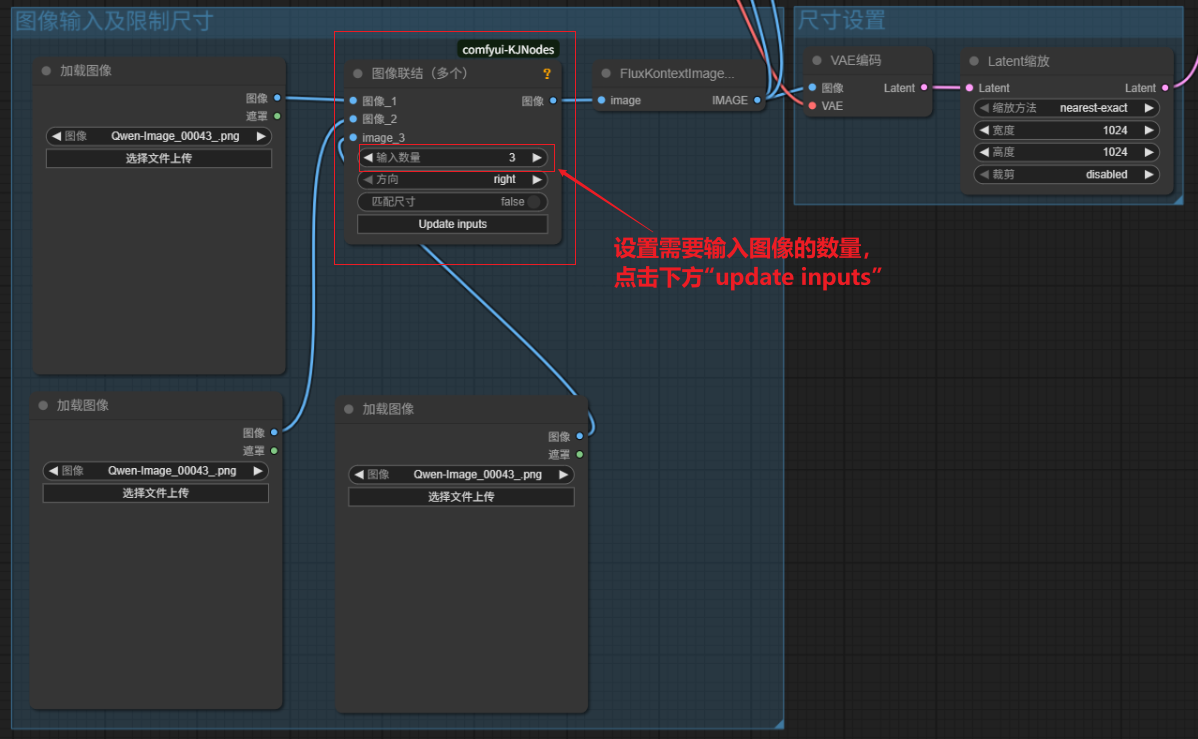
三图等更多图像编辑工作流:将“图像联结”节点调整为“图像联结(多个)”节点,输入需求数量的参考图像并按需设置好提示词即可。
附件:本节内容中的模型已上传至网盘,链接https://pan.quark.cn/s/59567de2bdfc#/list/share
模型文件已进行整理,网盘内包含工作流获取方式,适合不方便科学上网的的小伙伴下载使用。模型文件数量较多且尺寸较大,为避免下载中断等问题,可先转存再下载。
欢迎正在学习comfyui等ai技术的伙伴V加 huaqs123 进入学习小组。在这里大家共同学习comfyui的基础知识、最新模型与工作流、行业前沿信息等,也可以讨论comfyui商业落地的思路与方向。 欢迎感兴趣的小伙伴,群共享资料会分享博主自用的comfyui整合包(已安装超全节点与必备模型)、基础学习资料、高级工作流等资源……
致敬每一位在路上的学习者,你我共勉!Ai技术发展迅速,学习comfyUI是紧跟时代的第一步,促进商业落地并创造价值才是学习的实际目标。

——画青山Ai学习专栏———————————————————————————————
零基础学Webui:
https://blog.csdn.net/vip_zgx888/category_13020854.html
Comfyui基础学习与实操:
https://blog.csdn.net/vip_zgx888/category_13006170.html
comfyui功能精进与探索:
https://blog.csdn.net/vip_zgx888/category_13005478.html
系列专栏持续更新中,欢迎订阅关注,共同学习,共同进步!
—————————————————————————————————————————

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)